本例中,利用 requests 库和正则表达式来抓取猫眼电影 TOP100 的相关内容。
1.目标
提取出猫眼电影 TOP100 的电影名称、时间、评分、图片等信息,提取的站点 URL 为 http://maoyan.com/board/4,提取的结果会以文件形式保存下来。
2.抓取分析
抓取页面如下:

页面中显示的有效信息有影片名称、主演、上映时间、上映地区、评分、图片等信息。
将网页滚动到最下方,可以发现有分页的列表。直接点击第 2 页,观察页面的 URL 和内容发生了怎样的变化。
第一页url:https://www.maoyan.com/board/4?offset=0
第二页url:https://www.maoyan.com/board/4?offset=10
可以发现offset从0变成了10,而每一页都显示了十部电影,由此可以总结出规律,offset 代表偏移量值。如果想获取 TOP100 电影,只需要分开请求 10 次,而 10 次的 offset 参数分别设置为 0、10、20…90 即可,这样获取不同的页面之后,再用正则表达式提取出相关信息,就可以得到 TOP100 的所有电影信息了。
3.抓取首页
首先抓取第一页的内容。实现 get_one_page 方法,并给它传入 url 参数。然后将抓取的页面结果返回。初步代码实现如下:
import requests
import redef get_one_page(url):headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'}response=requests.get(url,headers=headers)if response.status_code==200:return response.textreturn Nonedef main():html=get_one_page('https://www.maoyan.com/board/4?offset=0')print(html)main()
4.正则提取
回到网页看一下页面的真实源码。在开发者模式下的 Network 监听组件中查看源代码。、
注意,这里不要在 Elements 选项卡中直接查看源码,因为那里的源码可能经过 JavaScript 操作而与原始请求不同,而是需要从 Network 选项卡部分查看原始请求得到的源码。
其中一个条目的源代码如下:
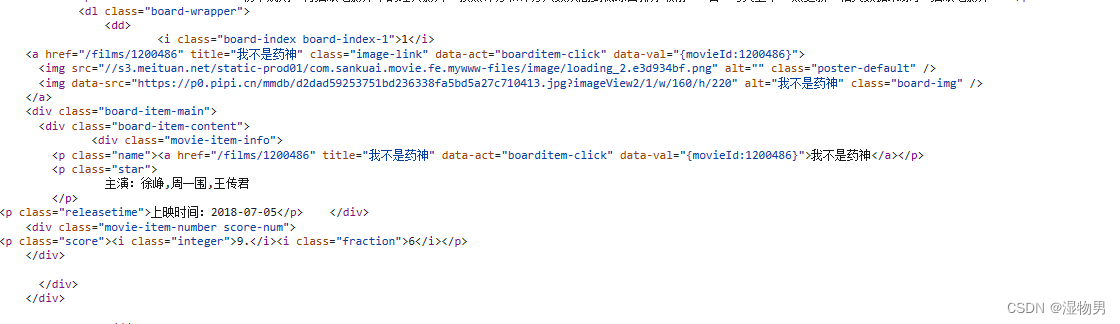
可以看到,一部电影信息对应的源代码是一个 dd 节点,我们用正则表达式来提取这里面的一些电影信息。首先,需要提取它的排名信息。而它的排名信息是在 class 为 board-index 的 i 节点内,这里利用非贪婪匹配来提取 i 节点内的信息,正则表达式写为:
result_ranking=re.findall('<dd>.*?board-index.*?>(.*?)</i>',html,re.S)
随后需要提取电影的图片。
result_img=re.findall('<img\sdata-src="(.*?)"',html,re.S)
再往后,需要提取电影的名称.
result_name=re.findall('class="name".*?data-val.*?>(.*?)</a>',html,re.S)
再提取主演、发布时间、评分等内容时,都是同样的原理。最后,正则表达式写为:
result_star=re.findall('class="star".*?>(.*?)</p>',html,re.S)
result_star = [star.strip() for star in result_star]
result_time=re.findall('class="releasetime".*?>(.*?)</p>',html,re.S)
result_score=re.findall('class="score".*?integer.*?>(.*?)</i>.*?fraction">(.*?)</i>',html,re.S)
由于这里的主演前后带有空格和换行符,使用strip去除。
到这里我们就可以将一部电影的6个数据提取出来,但这样还不够,数据比较杂乱,我们再将匹配结果处理一下,生成字典,如下:
index=0
result={'ranking':result_ranking[index],'img':result_img[index],'name':result_name[index],'star':result_star[index],'time':result_time[index],'score':result_score[index]}
5.写入文件
随后,我们将提取的结果写入文件,这里直接写入到一个文本文件中。这里通过 JSON 库的 dumps 方法实现字典的序列化,并指定 ensure_ascii 参数为 False,这样可以保证输出结果是中文形式而不是 Unicode 编码。代码如下:
import json
def write_to_file(content): with open('result.txt', 'a', encoding='utf-8') as f: print(type(json.dumps(content))) f.write(json.dumps(content, ensure_ascii=False)+'\n')
6.整合代码分页爬取
因为我们需要抓取的是 TOP100 的电影,所以还需要遍历一下,给这个链接传入 offset 参数,实现其他 90 部电影的爬取,此时添加如下调用即可:
import time
for i in range(10):url='https://www.maoyan.com/board/4?offset='+str(i*10)time.sleep(0.5)html=get_one_page(url)result_ranking=re.findall('<dd>.*?board-index.*?>(.*?)</i>',html,re.S)result_img=re.findall('<img\sdata-src="(.*?)"',html,re.S)result_name=re.findall('class="name".*?data-val.*?>(.*?)</a>',html,re.S)result_star=re.findall('class="star".*?>(.*?)</p>',html,re.S)result_star = [star.strip() for star in result_star]result_time=re.findall('class="releasetime".*?>(.*?)</p>',html,re.S)result_score=re.findall('class="score".*?integer.*?>(.*?)</i>.*?fraction">(.*?)</i>',html,re.S)for index in range(10):result={'ranking':result_ranking[index],'img':result_img[index],'title':result_name[index],'star':result_star[index],'reaease_time':result_time[index],'score':result_score[index]}write_to_file(result)
注意每次请求页面后加入暂停时间,否则会被反爬机制阻止,需要更换新的user-agent和cookie。
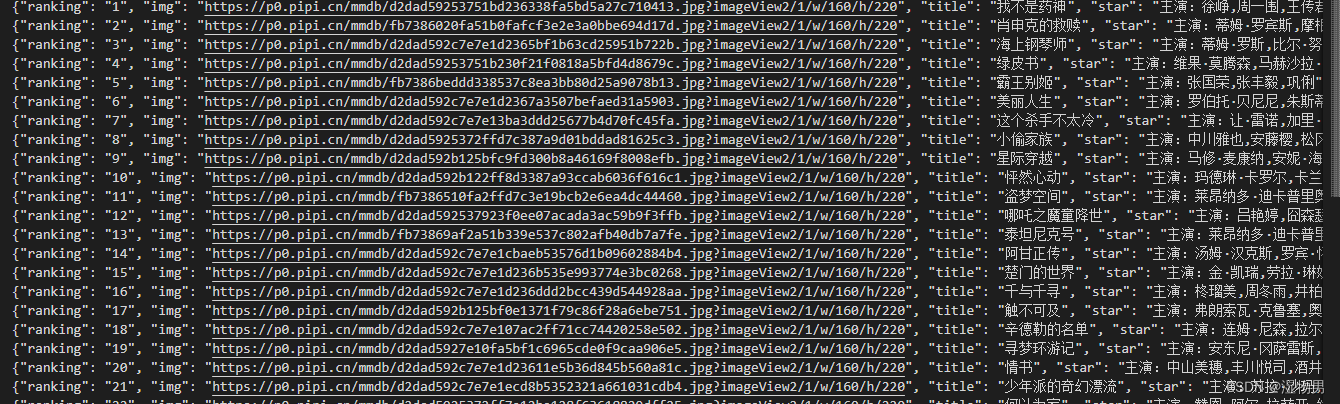
爬取结果如下:
番外:使用正则表达式对象改写
在上面的正则提取中我们为每一条要提取的信息都编写了一个正则表达式进行提取,可以利用compile方法编写正则表达式对象一次将六条信息全部提取出来,下面进行简化,我们将要提取的信息用一条正则表达式描述,使用group逐个提取出来。
可以看到,一部电影信息对应的源代码是一个 dd 节点,我们用正则表达式来提取这里面的一些电影信息。首先,需要提取它的排名信息。而它的排名信息是在 class 为 board-index 的 i 节点内,这里利用非贪婪匹配来提取 i 节点内的信息,正则表达式写为:
<dd>.*?board-index.*?>(.*?)</i>
随后需要提取电影的图片。可以看到,后面有 a 节点,其内部有两个 img 节点。经过检查后发现,第二个 img 节点的 data-src 属性是图片的链接。这里提取第二个 img 节点的 data-src 属性,在原有正则表达式基础可以改写如下:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)"
再往后,需要提取电影的名称,它在后面的 p 节点内,class 为 name。所以,可以用 name 做一个标志位,然后进一步提取到其内 a 节点的正文内容,此时正则表达式改写如下:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>
再提取主演、发布时间、评分等内容时,都是同样的原理。最后,正则表达式写为:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>
接下来,通过调用 findall 方法提取出所有的内容。
pattern = re.compile('<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>',re.S)items = re.findall(pattern, html)
输出结果如下:
[('1', 'http://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c', ' 霸王别姬 ', '\n 主演:张国荣,张丰毅,巩俐 \n ', ' 上映时间:1993-01-01(中国香港)', '9.', '6'), ('2', 'http://p0.meituan.net/movie/__40191813__4767047.jpg@160w_220h_1e_1c', ' 肖申克的救赎 ', '\n 主演:蒂姆・罗宾斯,摩根・弗里曼,鲍勃・冈顿 \n ', ' 上映时间:1994-10-14(美国)', '9.', '5'), ('3', 'http://p0.meituan.net/movie/fc9d78dd2ce84d20e53b6d1ae2eea4fb1515304.jpg@160w_220h_1e_1c', ' 这个杀手不太冷 ', '\n 主演:让・雷诺,加里・奥德曼,娜塔莉・波特曼 \n ', ' 上映时间:1994-09-14(法国)', '9.', '5'), ('4', 'http://p0.meituan.net/movie/23/6009725.jpg@160w_220h_1e_1c', ' 罗马假日 ', '\n 主演:格利高利・派克,奥黛丽・赫本,埃迪・艾伯特 \n ', ' 上映时间:1953-09-02(美国)', '9.', '1'), ('5', 'http://p0.meituan.net/movie/53/1541925.jpg@160w_220h_1e_1c', ' 阿甘正传 ', '\n 主演:汤姆・汉克斯,罗宾・怀特,加里・西尼斯 \n ', ' 上映时间:1994-07-06(美国)', '9.', '4'), ('6', 'http://p0.meituan.net/movie/11/324629.jpg@160w_220h_1e_1c', ' 泰坦尼克号 ', '\n 主演:莱昂纳多・迪卡普里奥,凯特・温丝莱特,比利・赞恩 \n ', ' 上映时间:1998-04-03', '9.', '5'), ('7', 'http://p0.meituan.net/movie/99/678407.jpg@160w_220h_1e_1c', ' 龙猫 ', '\n 主演:日高法子,坂本千夏,糸井重里 \n ', ' 上映时间:1988-04-16(日本)', '9.', '2'), ('8', 'http://p0.meituan.net/movie/92/8212889.jpg@160w_220h_1e_1c', ' 教父 ', '\n 主演:马龙・白兰度,阿尔・帕西诺,詹姆斯・凯恩 \n ', ' 上映时间:1972-03-24(美国)', '9.', '3'), ('9', 'http://p0.meituan.net/movie/62/109878.jpg@160w_220h_1e_1c', ' 唐伯虎点秋香 ', '\n 主演:周星驰,巩俐,郑佩佩 \n ', ' 上映时间:1993-07-01(中国香港)', '9.', '2'), ('10', 'http://p0.meituan.net/movie/9bf7d7b81001a9cf8adbac5a7cf7d766132425.jpg@160w_220h_1e_1c', ' 千与千寻 ', '\n 主演:柊瑠美,入野自由,夏木真理 \n ', ' 上映时间:2001-07-20(日本)', '9.', '3')]