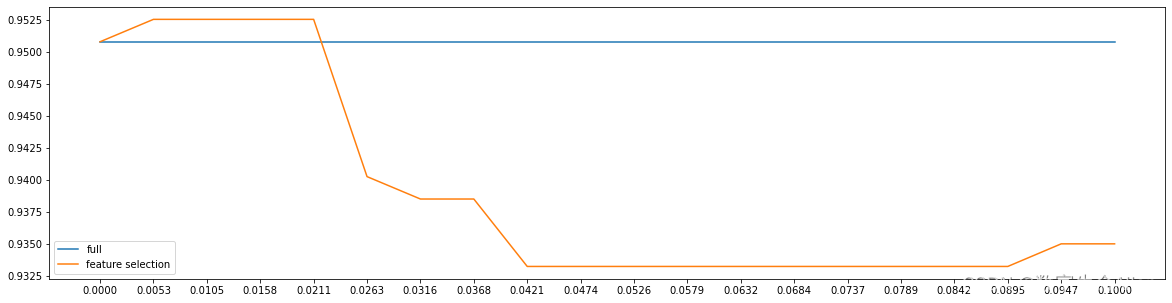
本次主要介绍开源项目wespeaker模型介绍
1. 模型超参数
model_args:
feat_dim: 80
embed_dim: 192
pooling_func: “ASTP”
projection_args:
project_type: “softmax” # add_margin, arc_margin, sphere, softmax
scale: 32.0
easy_margin: False
2. 模型结构
2.1 Layer1: input层
x:(B,F,T) F=80
将原始80维fbank特征进行映射;
x->conv->relu->bn->(B,F’,T) F’=512

进入下面的layer2-4
2.2 Layer2-4:核心空洞卷积层
Layer2和Layer3、Layer4相似,只有两个超参数不同。下面介绍Layer2的结构。
整体结构
x: (B,F,T) F=512
x -> block1~4 -> new_x
return x + new_x
block1
x:(B,F,T) F=512
x->conv->relu->bn->(B,F,T)
block2
x: (B,F,T) F=512
x分为8块->(B,F’,T) F’=64
x1~x7执行:
conv-relu->bn->(B,F’,T)
x8不变
x1~x8合并->(B,F,T) F=512
block3
x:(B,F,T) F=512
x->conv->relu->bn->(B,F,T)
block4
SE block,对F维进行缩放
x:(B,F,T) F=512
x对最后一个维度求mean->(B,F)
(B,F) -> Linear1->Relu->Linear2->(B,F)->sigmoid->unsqueeze->(B,F,1) 得到scale
x * scale ->(B,F,T)
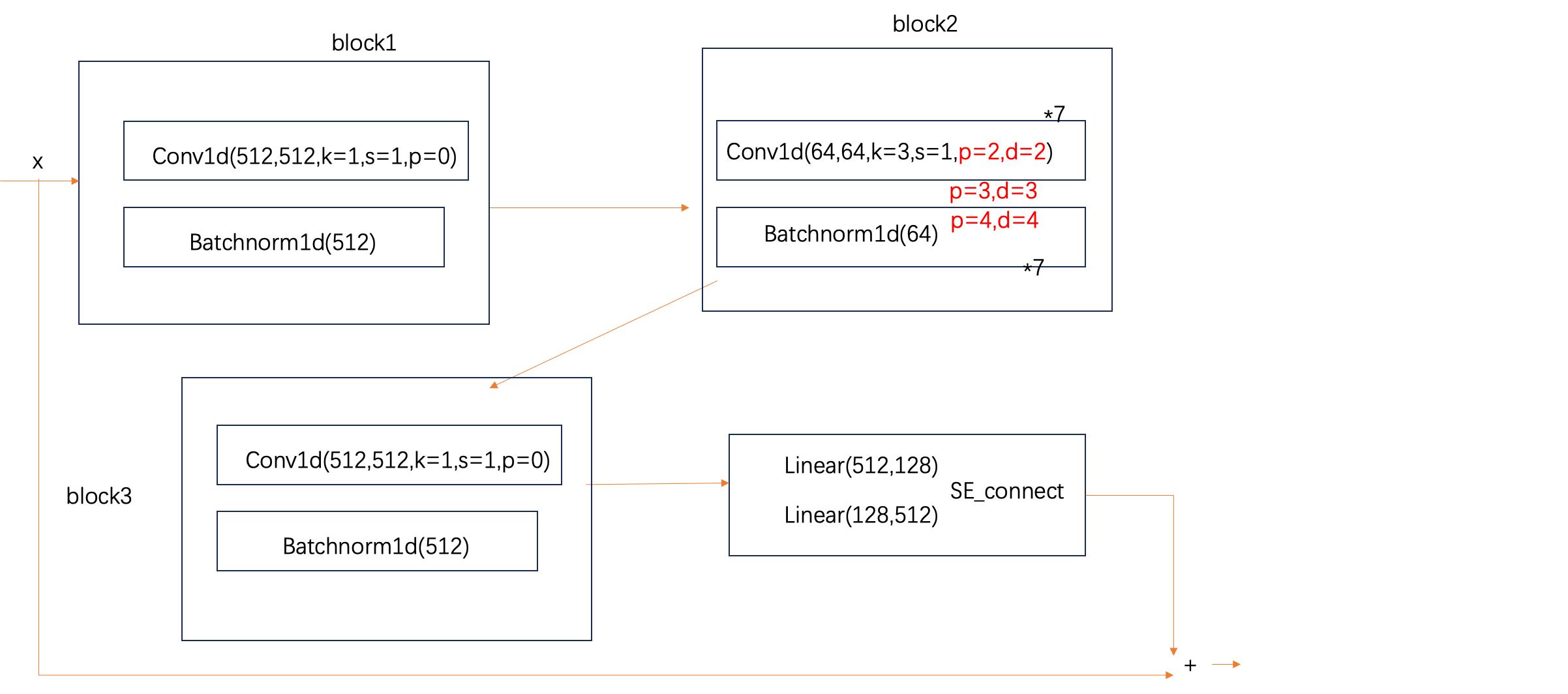
上图中标红的部分分别为layer2/3/4的参数,其他均相同
2.3 pool:池化层
2.3.1前处理
out2、out3、out4按照dim=1进行拼接->(B,3*F,T) (F=512)
按照下图的卷积参数进行卷积->(B,3F,T)
ReLU->(B,3F,T)

然后进行下面的pool
2.3.2Attentive statistics pooling
x : (B,F,T) F=1536
对x在-1维度求mean,扩展为x维度;
对x在-1维度求std,扩展为x维度;
x拼接mean、std为(B,3*F,T) new_x
new_x->下图中的第一个卷积->tanh->下图中第二个卷积->(B,F,T) ->对最后一维度求softmax得到attention
attention * x ,最后一维度sum,得到mean;(B,F)
attention * x_2, 最后一维度sum - mean_2,得到std;(B,F)
拼接mean std->(B,2*F) 返回(B,3072)

2.3.3后处理(embed层)
x: (B,F) F=3072
x->bn-> (B,F) ->embed(下图的Linear)->(B,F’) F’=192

2.4 projection:映射层
根据具体的任务,将embed层映射为实际的分类;
x:(B,F) F=192
x->bn->relu->linear->(B,F’) F’=6