Docker Swarm Mode
Docker Swarm 集群搭建
Docker Swarm 节点维护
Docker Service 创建
1.角色转换
Swarm 集群中节点的角色只有 manager 与 worker,所以其角色也只是在 manager 与worker 间的转换。即 worker 升级为 manager,或 manager 降级为 worker。
1.1 worker 升级为 manager
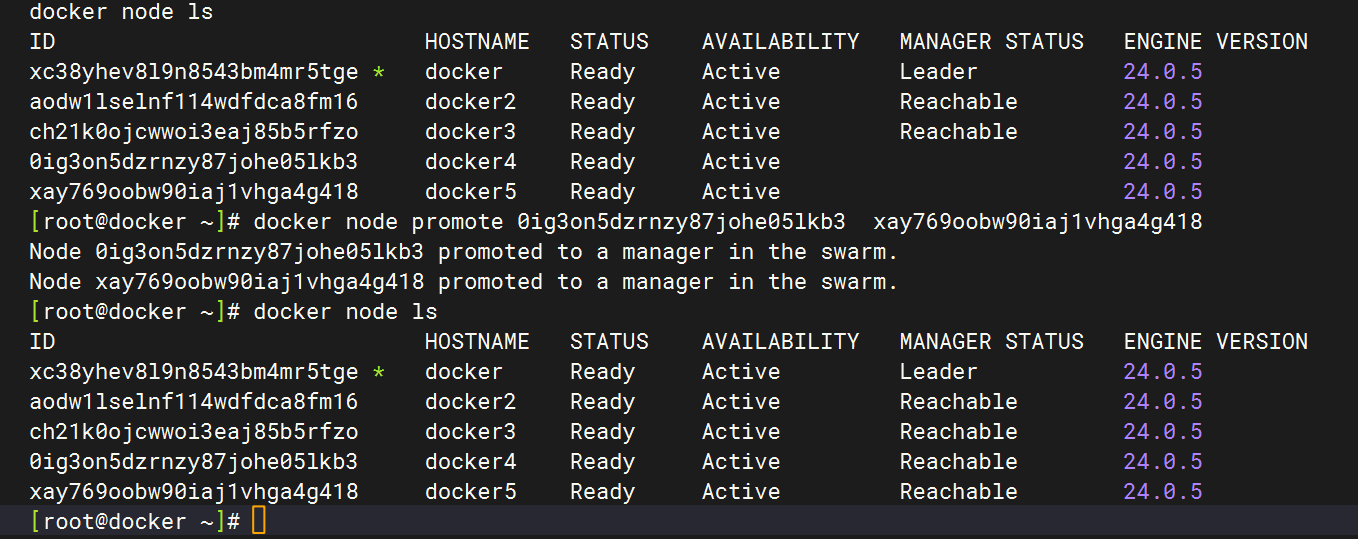
在manager节点通过 docker node promote 命令可以将 worker 升级为 manager。例如,下面的命令是将docker4 与 docker5 两个节点升级为了 manager,即当前集群中全部为 manager。
1.2 manager 降级为 worker
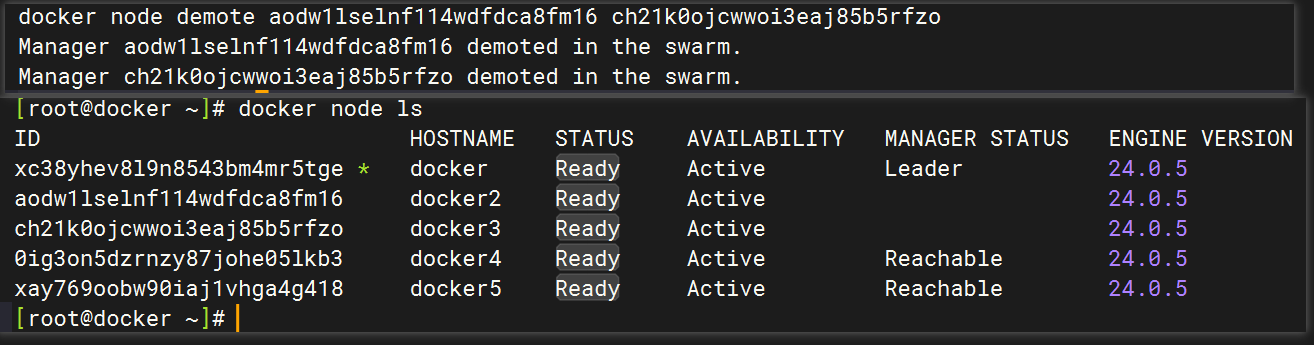
在manager节点通过 docker node demote 命令可以将 manager 降级为 worker。例如,下面将docker2 与 docker3 两个节点降级为了 worker。
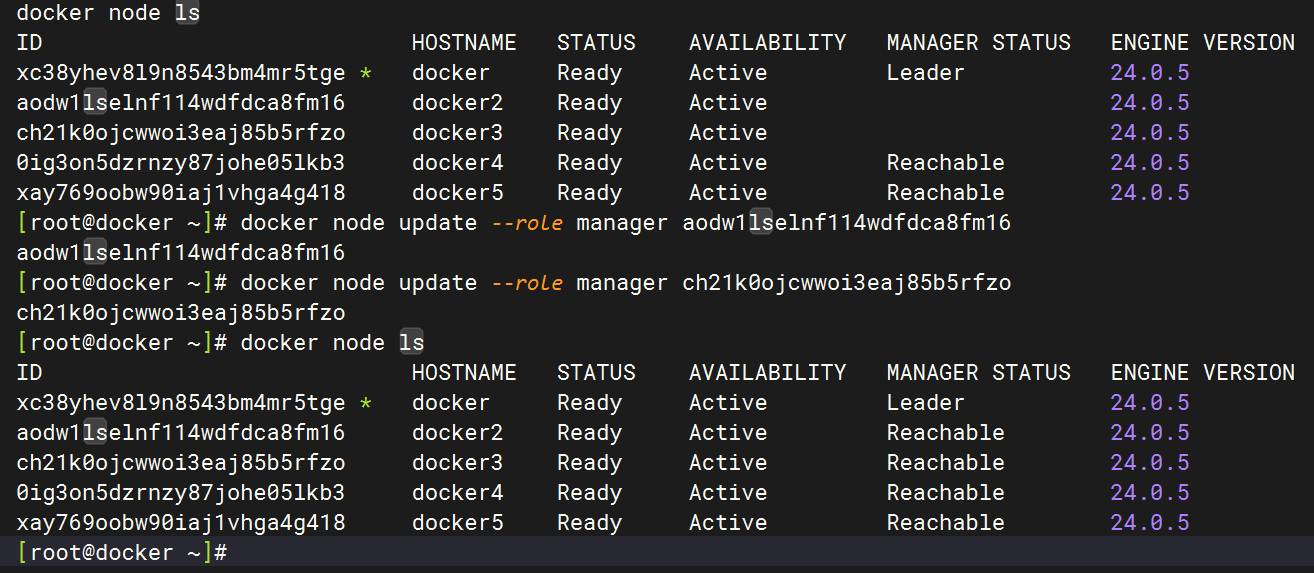
1.3 docker node update 变更角色
除了通过 docker node demote|promote 可以变更节点角色外,通过 docker node update --role [manager|worker] [node]也可变更指定节点的角色。
再将 docker2 与 docker3 两个节点变为 manager。
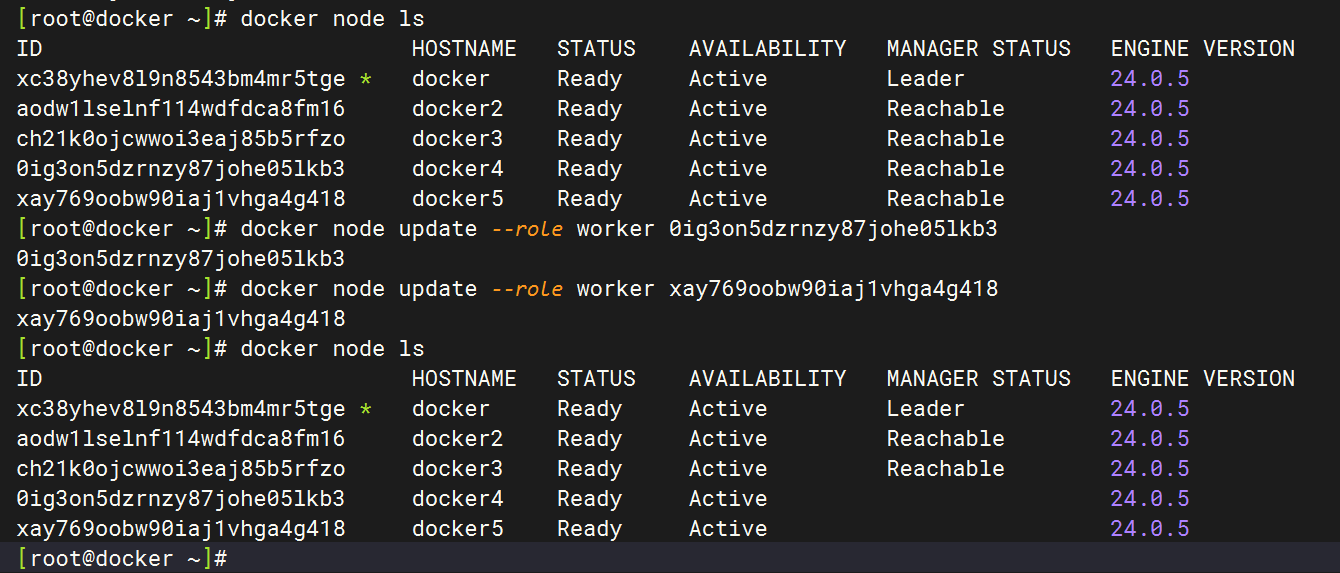
将 docker4 与 docker5 两个节点变为 worker。
2. 节点标签
swarm 可以通过命令为其节点添加描述性标签,方便运维人员去了解该节点的更多信息。
2.1 添加/修改节点标签
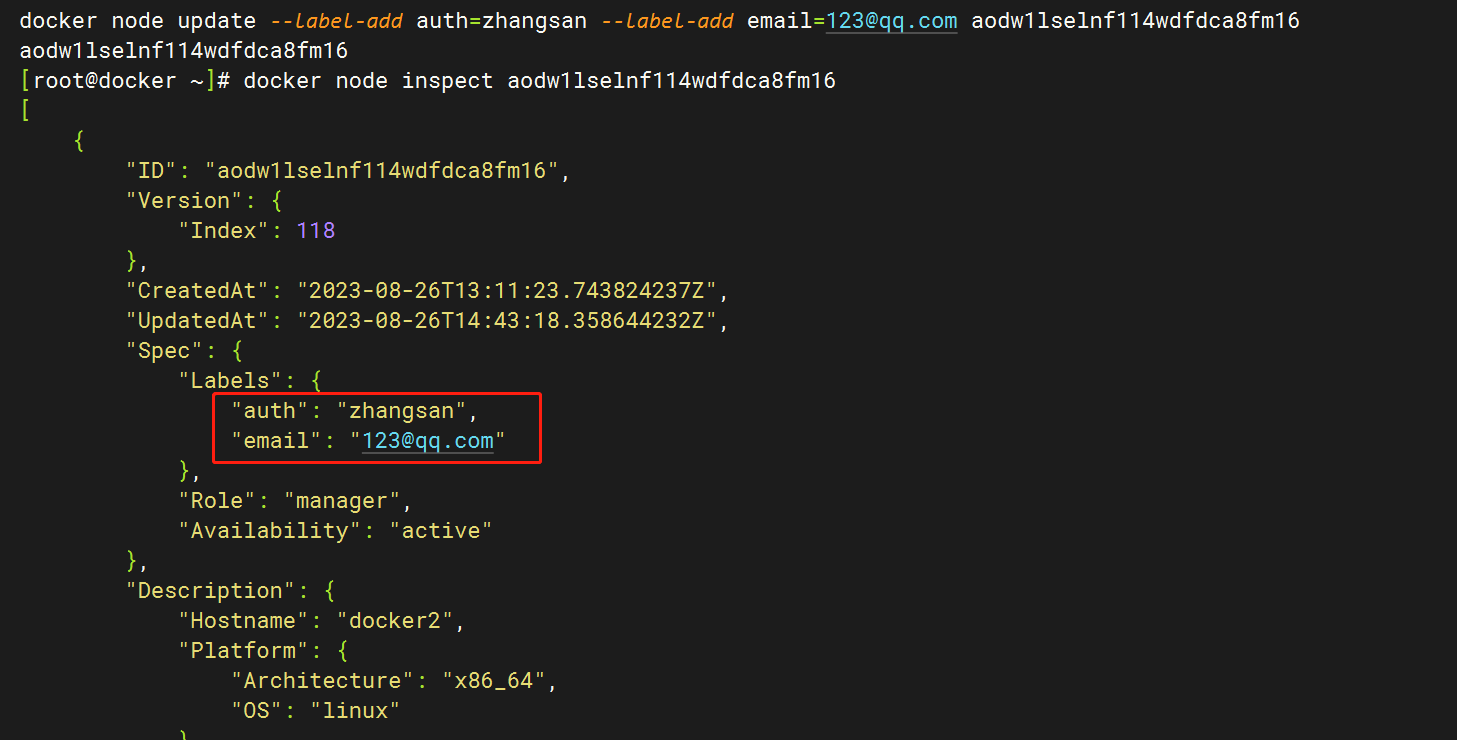
通过 docker node update --label-add 命令可以为指定 node 添加指定的 key=value 的标签。若该标签的 key 已经存在,则会使用新的 value 替换掉该 key 的原 value。不过需要注意的是,若要添加或修改多个标签,则需要通过多个--label-add 选项指定。
docker node update --label-add auth=zhangsan --label-add email=123@qq.com aodw1lselnf114wdfdca8fm16
# 通过 docker node inspect 在查看该节点详情时可看到添加的标签
docker node inspect aodw1lselnf114wdfdca8fm16
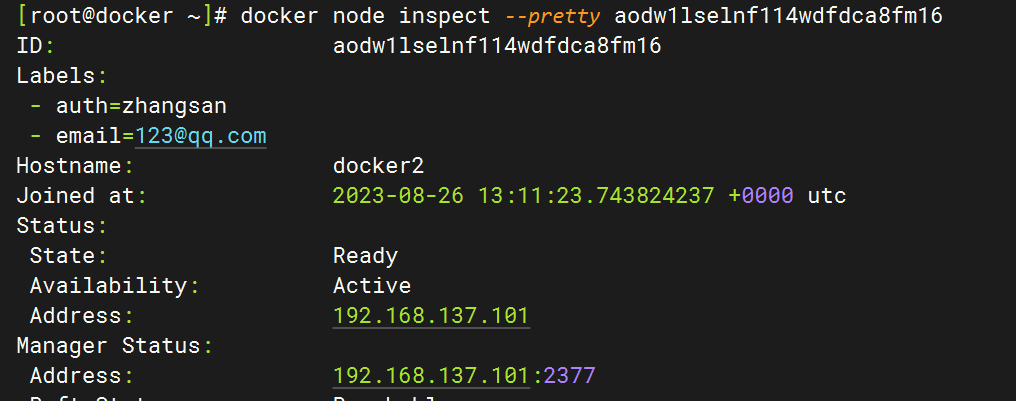
docker node inspect --pretty <node> 可以 key:value 的形式显示信息。
2.2 删除节点标签
通过 docker node update --label-rm 命令可以为指定的 node 删除指定 key 的标签。同样,若要删除多个标签,则需要通过多个--label-rm 选项指定要删除 key 的标签。
docker node update --label-rm auth --label-rm email aodw1lselnf114wdfdca8fm16
查看节点详情,两个标签已经消失。
3. 节点删除
manager 节点通过 docker node rm 命令可以删除一个 Down 状态的、指定的 worker 节点。
注意,该命令只能删除 worker 节点,不能删除 manager 节点。
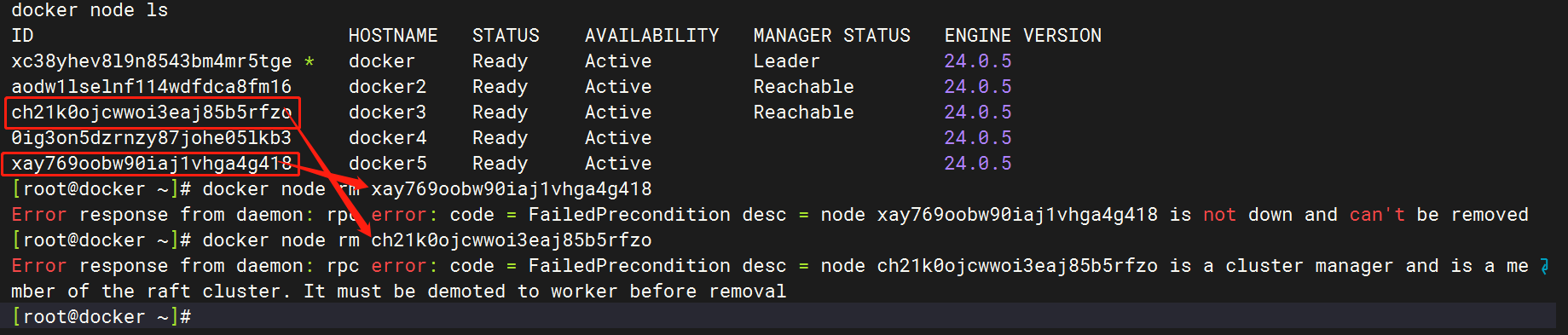
3.1 有问题的删除
验证:对于 Ready 状态的 worker 节点是无法直接删除的。对于 manager 节点也是无法删除的。
3.2 正确的删除
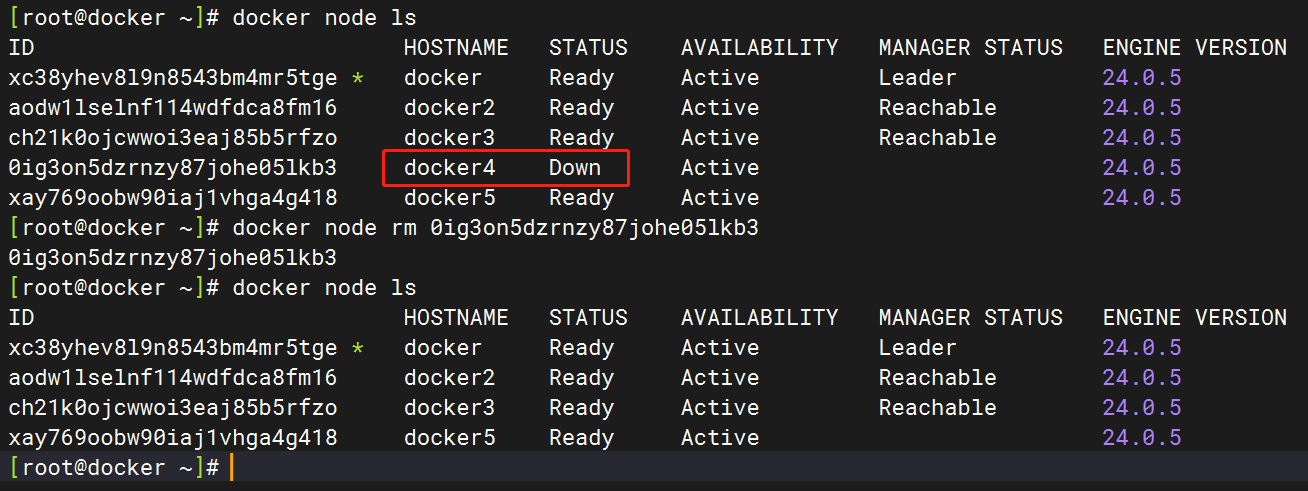
若要删除一个 worker 节点,首先要将该节点的 Docker 关闭,使该节点变为 Down 状态,然后再进行删除。
停止docker4中的docker
systemctl stop docker
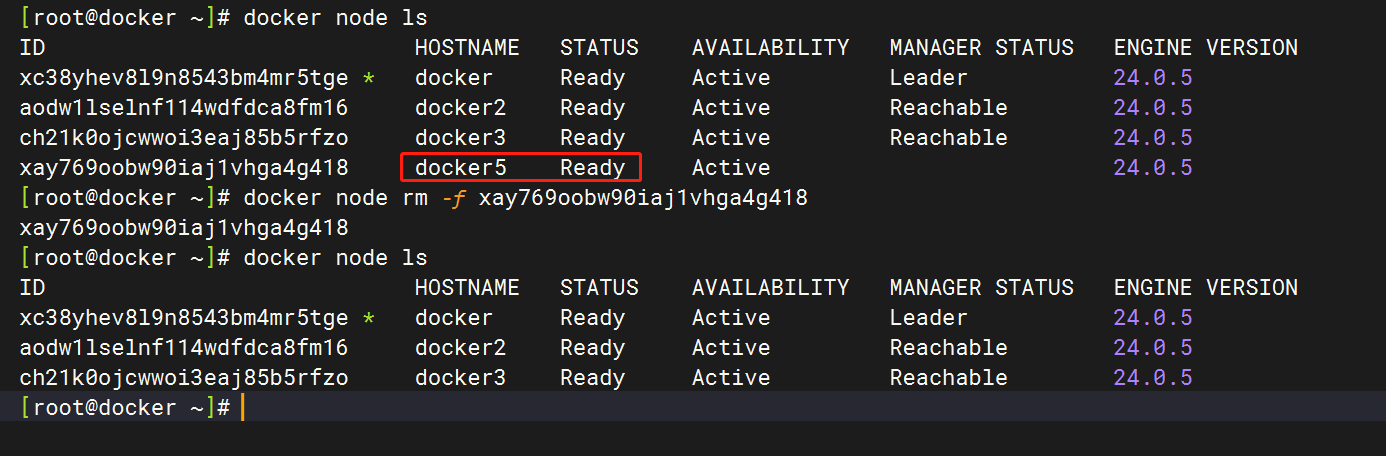
3.3 强制删除
上面的删除方式有些麻烦,其实也可以通过添加-f 选项来实现强制删除。
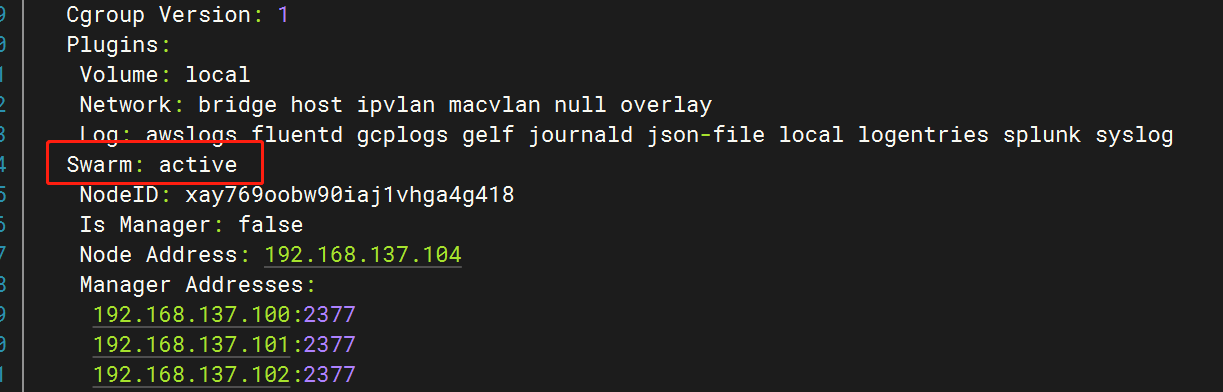
此时去docker5中查看docker状态发现:swarm: active
但对于 manager 节点,强制删除也不能删除。(可以通过先降级为worker,再强制删除)
docker node rm –f 命令会使一个节点强制退群,而 docker swarm leave 命令是使当前的docker 主机关闭 swarm 模式。
4. manager 集群容灾
4.1 热备容灾
Swarm 的 manager 节点集群采用的是热备方式来提升集群的容灾能力。即在 manager集群中只有一个处于 leader 状态,用于完成 swarm 节点的管理,其余 manager 处于热备状态。当 manager leader 宕机,其余 manager 就会自动发起 leader 选举,重新选举产生一个新的 manager leader。
4.2 容灾能力
manager 集群的 leader 选举采用的是 Raft 算法。Raft 算法是一种比较复杂的一致性算法,其选举 leader 的简单思路是,所有可用的 manager 全部具有选举权与被选举权。最终获得过半选票的 manager 当选新的 leader。为了保证一次性可以选举出新的leader,官方推荐使用奇数个manager。但并不是说偶数个manager就无法选举出leader。
4.3 容灾模拟
目前是 docker、docker2、docker3 三个 manager,其中 docker 为 leader。

现在关闭 docker 主机的 docker daemon,模拟其宕机。
systemctl stop docker
然后在 docker2 或 docker3 主机上查看当前的节点情况,可以看到 docker2 或 docker3已经成为了新的 leader。

此时如果再使某个 manager 宕机,例如使 docker2 的 docker daemon 关闭,那么整个swarm 就会瘫痪。因为剩下的 manager 已经无法达成过半的选票,无法选举出新的 leader。
停掉docker2后,整个集群瘫痪: