一、项目背景
二、项目需求
(1)需求
①各省销售指标,每个省份的销售额统计
②TOP3销售省份中,有多少家店铺日均销售额1000+
③TOP3省份中,各个省份的平均单价
④TOP3省份中,各个省份的支付类型比例
(2)要求
①将需求结果写出到mysql
②将数据写入到Spark On Hive中
三、代码实现
(1)需求1:
# cording:utf8
'''
要求1:各省销售额统计
要求2:TOP3销售省份中,有多少店铺达到过日销售额1000+
要求3:TOP3省份中,各省的平均单单价
要求4:TOP3省份中,各个省份的支付类型比例
'''from pyspark.sql import SparkSession
from pyspark.sql import functions as F
if __name__ == '__main__':spark = SparkSession.builder.appName('SQL_text').\master('local[*]').\config('spark.sql.shuffle.partitions', '2').\config('spark.sql.warehouse.dir', 'hdfs://pyspark01/user/hive/warehouse').\config('hive.metastore.uris', 'thrift://pyspark01:9083').\enableHiveSupport().\getOrCreate()# 1.读取数据# 省份信息,缺失值过滤,同时省份信息中会有‘null’字符串# 订单的金额,数据集中有订单的金额是单笔超过10000的,这些事测试数据# 列值过滤(SparkSQL会自动做这个优化)df = spark.read.format('json').load('../../input/mini.json').\dropna(thresh=1, subset=['storeProvince']).\filter("storeProvince != 'null'").\filter('receivable < 10000').\select('storeProvince', 'storeID', 'receivable', 'dateTS', 'payType')# TODO 1:各省销售额统计province_sale_df = df.groupBy('storeProvince').sum('receivable').\withColumnRenamed('sum(receivable)', 'money').\withColumn('money', F.round('money', 2)).\orderBy('money', ascending=False)province_sale_df.show(truncate=False)# 写出到Mysqlprovince_sale_df.write.mode('overwrite').\format('jdbc').\option('url', 'jdbc:mysql://pyspark01:3306/bigdata?useSSL=False&useUnicode=true&characterEncoding=utf8').\option('dbtable', 'province_sale').\option('user', 'root').\option('password', 'root').\option('encoding', 'utf8').\save()# 写出Hive表 saveAsTable 可以写出表 要求已经配置好spark on hive# 会将表写入到hive的数据仓库中province_sale_df.write.mode('overwrite').saveAsTable('default.province_sale', 'parquet')结果展示:

MySQL数据展示:
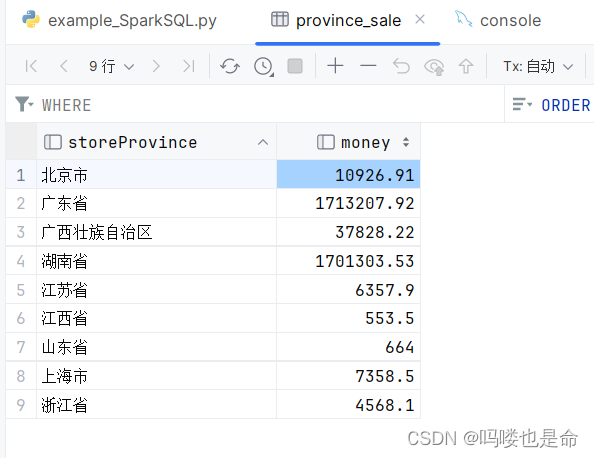
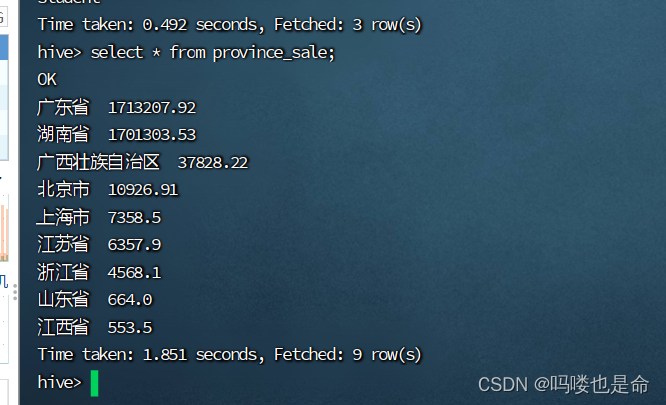
Hive数据展示:

(2)需求2:
# cording:utf8
'''
要求1:各省销售额统计
要求2:TOP3销售省份中,有多少店铺达到过日销售额1000+
要求3:TOP3省份中,各省的平均单单价
要求4:TOP3省份中,各个省份的支付类型比例
'''from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.storagelevel import StorageLevelif __name__ == '__main__':spark = SparkSession.builder.appName('SQL_text').\master('local[*]').\config('spark.sql.shuffle.partitions', '2').\config('spark.sql.warehouse.dir', 'hdfs://pyspark01/user/hive/warehouse').\config('hive.metastore.uris', 'thrift://pyspark01:9083').\enableHiveSupport().\getOrCreate()# 1.读取数据# 省份信息,缺失值过滤,同时省份信息中会有‘null’字符串# 订单的金额,数据集中有订单的金额是单笔超过10000的,这些事测试数据# 列值过滤(SparkSQL会自动做这个优化)df = spark.read.format('json').load('../../input/mini.json').\dropna(thresh=1, subset=['storeProvince']).\filter("storeProvince != 'null'").\filter('receivable < 10000').\select('storeProvince', 'storeID', 'receivable', 'dateTS', 'payType')# TODO 1:各省销售额统计province_sale_df = df.groupBy('storeProvince').sum('receivable').\withColumnRenamed('sum(receivable)', 'money').\withColumn('money', F.round('money', 2)).\orderBy('money', ascending=False)# # 写出到Mysql# province_sale_df.write.mode('overwrite').\# format('jdbc').\# option('url', 'jdbc:mysql://pyspark01:3306/bigdata?useSSL=False&useUnicode=true&characterEncoding=utf8').\# option('dbtable', 'province_sale').\# option('user', 'root').\# option('password', 'root').\# option('encoding', 'utf8').\# save()## # 写出Hive表 saveAsTable 可以写出表 要求已经配置好spark on hive# # 会将表写入到hive的数据仓库中# province_sale_df.write.mode('overwrite').saveAsTable('default.province_sale', 'parquet')# TODO 需求2:TOP3销售省份中,有多少店铺达到过日销售额1000+# 2.1 找到TOP3的销售省份top3_province_df = province_sale_df.limit(3).select('storeProvince').\withColumnRenamed('storeProvince', 'top3_province') # 对列名进行重命名,防止与province_sale_df的storeProvince冲突# 2.2 和原始的DF进行内关联,数据关联后,得到TOP3省份的销售数据top3_province_df_joined = df.join(top3_province_df, on=df['storeProvince'] == top3_province_df['top3_province'])# 因为需要多次使用到TOP3省份数据,所有对其进行持久化缓存top3_province_df_joined.persist(StorageLevel.MEMORY_AND_DISK)# from_unixtime将秒级的日期数据转换为年月日数据# from_unixtime的精度是秒级,数据的精度是毫秒级,需要对数据进行进度的裁剪province_hot_store_count_df = top3_province_df_joined.groupBy("storeProvince", "storeID",F.from_unixtime(df['dateTS'].substr(0, 10), "yyyy-mm-dd").alias('day')).\sum('receivable').withColumnRenamed('sum(receivable)', 'money').\filter('money > 1000 ').\dropDuplicates(subset=['storeID']).\groupBy('storeProvince').count()province_hot_store_count_df.show()# 写出到Mysqlprovince_sale_df.write.mode('overwrite'). \format('jdbc'). \option('url', 'jdbc:mysql://pyspark01:3306/bigdata?useSSL=False&useUnicode=true&characterEncoding=utf8'). \option('dbtable', 'province_hot_store_count'). \option('user', 'root'). \option('password', 'root'). \option('encoding', 'utf8'). \save()# 写出Hive表 saveAsTable 可以写出表 要求已经配置好spark on hive# 会将表写入到hive的数据仓库中province_sale_df.write.mode('overwrite').saveAsTable('default.province_hot_store_count', 'parquet')top3_province_df_joined.unpersist()结果展示:

MySQL结果展示:
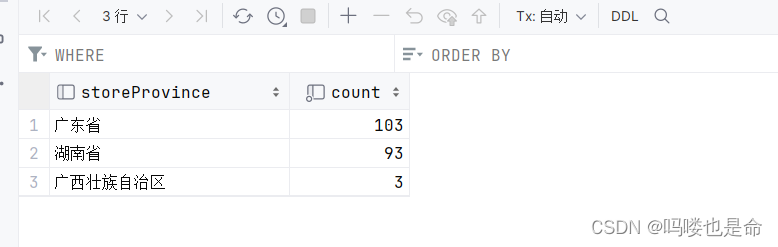
Hive结果展示:

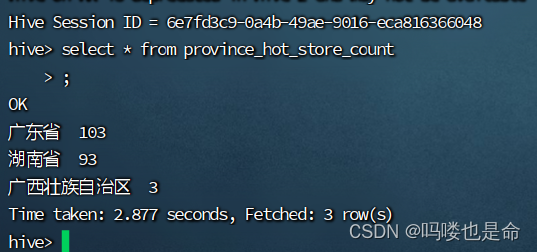
(3)需求3:
# cording:utf8
'''
要求1:各省销售额统计
要求2:TOP3销售省份中,有多少店铺达到过日销售额1000+
要求3:TOP3省份中,各省的平均单单价
要求4:TOP3省份中,各个省份的支付类型比例
'''from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.storagelevel import StorageLevelif __name__ == '__main__':spark = SparkSession.builder.appName('SQL_text').\master('local[*]').\config('spark.sql.shuffle.partitions', '2').\config('spark.sql.warehouse.dir', 'hdfs://pyspark01/user/hive/warehouse').\config('hive.metastore.uris', 'thrift://pyspark01:9083').\enableHiveSupport().\getOrCreate()# 1.读取数据# 省份信息,缺失值过滤,同时省份信息中会有‘null’字符串# 订单的金额,数据集中有订单的金额是单笔超过10000的,这些事测试数据# 列值过滤(SparkSQL会自动做这个优化)df = spark.read.format('json').load('../../input/mini.json').\dropna(thresh=1, subset=['storeProvince']).\filter("storeProvince != 'null'").\filter('receivable < 10000').\select('storeProvince', 'storeID', 'receivable', 'dateTS', 'payType')# TODO 1:各省销售额统计province_sale_df = df.groupBy('storeProvince').sum('receivable').\withColumnRenamed('sum(receivable)', 'money').\withColumn('money', F.round('money', 2)).\orderBy('money', ascending=False)# # 写出到Mysql# province_sale_df.write.mode('overwrite').\# format('jdbc').\# option('url', 'jdbc:mysql://pyspark01:3306/bigdata?useSSL=False&useUnicode=true&characterEncoding=utf8').\# option('dbtable', 'province_sale').\# option('user', 'root').\# option('password', 'root').\# option('encoding', 'utf8').\# save()## # 写出Hive表 saveAsTable 可以写出表 要求已经配置好spark on hive# # 会将表写入到hive的数据仓库中# province_sale_df.write.mode('overwrite').saveAsTable('default.province_sale', 'parquet')# TODO 需求2:TOP3销售省份中,有多少店铺达到过日销售额1000+# 2.1 找到TOP3的销售省份top3_province_df = province_sale_df.limit(3).select('storeProvince').\withColumnRenamed('storeProvince', 'top3_province') # 对列名进行重命名,防止与province_sale_df的storeProvince冲突# 2.2 和原始的DF进行内关联,数据关联后,得到TOP3省份的销售数据top3_province_df_joined = df.join(top3_province_df, on=df['storeProvince'] == top3_province_df['top3_province'])# 因为需要多次使用到TOP3省份数据,所有对其进行持久化缓存top3_province_df_joined.persist(StorageLevel.MEMORY_AND_DISK)# from_unixtime将秒级的日期数据转换为年月日数据# from_unixtime的精度是秒级,数据的精度是毫秒级,需要对数据进行进度的裁剪province_hot_store_count_df = top3_province_df_joined.groupBy("storeProvince", "storeID",F.from_unixtime(df['dateTS'].substr(0, 10), "yyyy-mm-dd").alias('day')).\sum('receivable').withColumnRenamed('sum(receivable)', 'money').\filter('money > 1000 ').\dropDuplicates(subset=['storeID']).\groupBy('storeProvince').count()province_hot_store_count_df.show()# # 写出到Mysql# province_hot_store_count_df.write.mode('overwrite'). \# format('jdbc'). \# option('url', 'jdbc:mysql://pyspark01:3306/bigdata?useSSL=False&useUnicode=true&characterEncoding=utf8'). \# option('dbtable', 'province_hot_store_count'). \# option('user', 'root'). \# option('password', 'root'). \# option('encoding', 'utf8'). \# save()## # 写出Hive表 saveAsTable 可以写出表 要求已经配置好spark on hive# # 会将表写入到hive的数据仓库中# province_hot_store_count_df.write.mode('overwrite').saveAsTable('default.province_hot_store_count', 'parquet')# TODO 3:TOP3省份中,各省的平均单单价top3_province_order_avg_df = top3_province_df_joined.groupBy("storeProvince").\avg("receivable").\withColumnRenamed("avg(receivable)", "money").\withColumn("money", F.round("money", 2)).\orderBy("money", ascending=False)top3_province_order_avg_df.show(truncate=False)# 写出到Mysqltop3_province_order_avg_df.write.mode('overwrite'). \format('jdbc'). \option('url', 'jdbc:mysql://pyspark01:3306/bigdata?useSSL=False&useUnicode=true&characterEncoding=utf8'). \option('dbtable', 'top3_province_order_avg'). \option('user', 'root'). \option('password', 'root'). \option('encoding', 'utf8'). \save()# 写出Hive表 saveAsTable 可以写出表 要求已经配置好spark on hive# 会将表写入到hive的数据仓库中top3_province_order_avg_df.write.mode('overwrite').saveAsTable('default.top3_province_order_avg', 'parquet')top3_province_df_joined.unpersist()结果展示

MySQL与Hive结果展示:

(4)需求4:
# cording:utf8
'''
要求1:各省销售额统计
要求2:TOP3销售省份中,有多少店铺达到过日销售额1000+
要求3:TOP3省份中,各省的平均单单价
要求4:TOP3省份中,各个省份的支付类型比例
'''from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.storagelevel import StorageLevel
from pyspark.sql.types import StringType
if __name__ == '__main__':spark = SparkSession.builder.appName('SQL_text').\master('local[*]').\config('spark.sql.shuffle.partitions', '2').\config('spark.sql.warehouse.dir', 'hdfs://pyspark01/user/hive/warehouse').\config('hive.metastore.uris', 'thrift://pyspark01:9083').\enableHiveSupport().\getOrCreate()# 1.读取数据# 省份信息,缺失值过滤,同时省份信息中会有‘null’字符串# 订单的金额,数据集中有订单的金额是单笔超过10000的,这些事测试数据# 列值过滤(SparkSQL会自动做这个优化)df = spark.read.format('json').load('../../input/mini.json').\dropna(thresh=1, subset=['storeProvince']).\filter("storeProvince != 'null'").\filter('receivable < 10000').\select('storeProvince', 'storeID', 'receivable', 'dateTS', 'payType')# TODO 1:各省销售额统计province_sale_df = df.groupBy('storeProvince').sum('receivable').\withColumnRenamed('sum(receivable)', 'money').\withColumn('money', F.round('money', 2)).\orderBy('money', ascending=False)# # 写出到Mysql# province_sale_df.write.mode('overwrite').\# format('jdbc').\# option('url', 'jdbc:mysql://pyspark01:3306/bigdata?useSSL=False&useUnicode=true&characterEncoding=utf8').\# option('dbtable', 'province_sale').\# option('user', 'root').\# option('password', 'root').\# option('encoding', 'utf8').\# save()## # 写出Hive表 saveAsTable 可以写出表 要求已经配置好spark on hive# # 会将表写入到hive的数据仓库中# province_sale_df.write.mode('overwrite').saveAsTable('default.province_sale', 'parquet')# TODO 需求2:TOP3销售省份中,有多少店铺达到过日销售额1000+# 2.1 找到TOP3的销售省份top3_province_df = province_sale_df.limit(3).select('storeProvince').\withColumnRenamed('storeProvince', 'top3_province') # 对列名进行重命名,防止与province_sale_df的storeProvince冲突# 2.2 和原始的DF进行内关联,数据关联后,得到TOP3省份的销售数据top3_province_df_joined = df.join(top3_province_df, on=df['storeProvince'] == top3_province_df['top3_province'])# 因为需要多次使用到TOP3省份数据,所有对其进行持久化缓存top3_province_df_joined.persist(StorageLevel.MEMORY_AND_DISK)# from_unixtime将秒级的日期数据转换为年月日数据# from_unixtime的精度是秒级,数据的精度是毫秒级,需要对数据进行进度的裁剪province_hot_store_count_df = top3_province_df_joined.groupBy("storeProvince", "storeID",F.from_unixtime(df['dateTS'].substr(0, 10), "yyyy-mm-dd").alias('day')).\sum('receivable').withColumnRenamed('sum(receivable)', 'money').\filter('money > 1000 ').\dropDuplicates(subset=['storeID']).\groupBy('storeProvince').count()province_hot_store_count_df.show()# # 写出到Mysql# province_hot_store_count_df.write.mode('overwrite'). \# format('jdbc'). \# option('url', 'jdbc:mysql://pyspark01:3306/bigdata?useSSL=False&useUnicode=true&characterEncoding=utf8'). \# option('dbtable', 'province_hot_store_count'). \# option('user', 'root'). \# option('password', 'root'). \# option('encoding', 'utf8'). \# save()## # 写出Hive表 saveAsTable 可以写出表 要求已经配置好spark on hive# # 会将表写入到hive的数据仓库中# province_hot_store_count_df.write.mode('overwrite').saveAsTable('default.province_hot_store_count', 'parquet')# TODO 3:TOP3省份中,各省的平均单单价top3_province_order_avg_df = top3_province_df_joined.groupBy("storeProvince").\avg("receivable").\withColumnRenamed("avg(receivable)", "money").\withColumn("money", F.round("money", 2)).\orderBy("money", ascending=False)top3_province_order_avg_df.show(truncate=False)# # 写出到Mysql# top3_province_order_avg_df.write.mode('overwrite'). \# format('jdbc'). \# option('url', 'jdbc:mysql://pyspark01:3306/bigdata?useSSL=False&useUnicode=true&characterEncoding=utf8'). \# option('dbtable', 'top3_province_order_avg'). \# option('user', 'root'). \# option('password', 'root'). \# option('encoding', 'utf8'). \# save()## # 写出Hive表 saveAsTable 可以写出表 要求已经配置好spark on hive# # 会将表写入到hive的数据仓库中# top3_province_order_avg_df.write.mode('overwrite').saveAsTable('default.top3_province_order_avg', 'parquet')# TODO 4:TOP3省份中,各个省份的支付类型比例top3_province_df_joined.createTempView("province_pay")# 自定义UDFdef udf_func(percent):return str(round(percent * 100)) + "%"# 注册UDFmy_udf = F.udf(udf_func, StringType())pay_type_df = spark.sql('''SELECT storeProvince, payType, (count(payType) / total) AS percent FROM (SELECT storeProvince, payType, count(1) OVER(PARTITION BY storeProvince) AS total FROM province_pay) AS subGROUP BY storeProvince, payType, total''').withColumn('percent', my_udf("percent"))pay_type_df.show()# 写出到Mysqlpay_type_df.write.mode('overwrite'). \format('jdbc'). \option('url', 'jdbc:mysql://pyspark01:3306/bigdata?useSSL=False&useUnicode=true&characterEncoding=utf8'). \option('dbtable', 'pay_type'). \option('user', 'root'). \option('password', 'root'). \option('encoding', 'utf8'). \save()# 写出Hive表 saveAsTable 可以写出表 要求已经配置好spark on hive# 会将表写入到hive的数据仓库中top3_province_order_avg_df.write.mode('overwrite').saveAsTable('default.pay_type', 'parquet')top3_province_df_joined.unpersist()结果展示:

MySQL结果展示:

Hive结果展示:
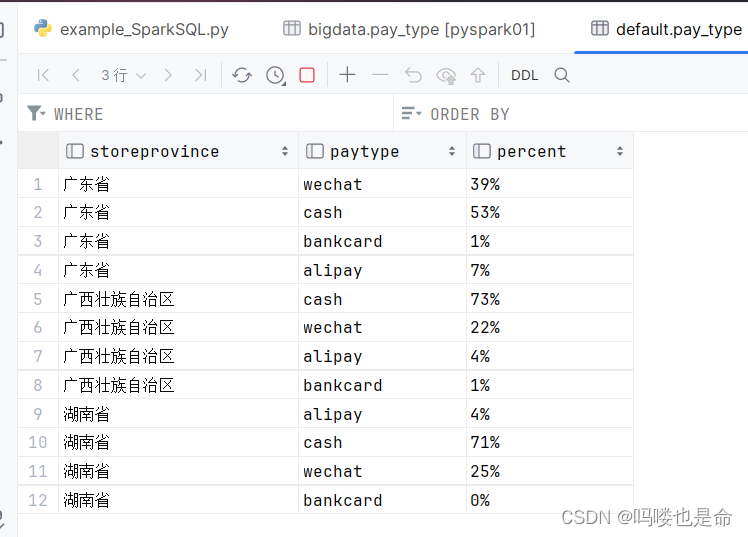
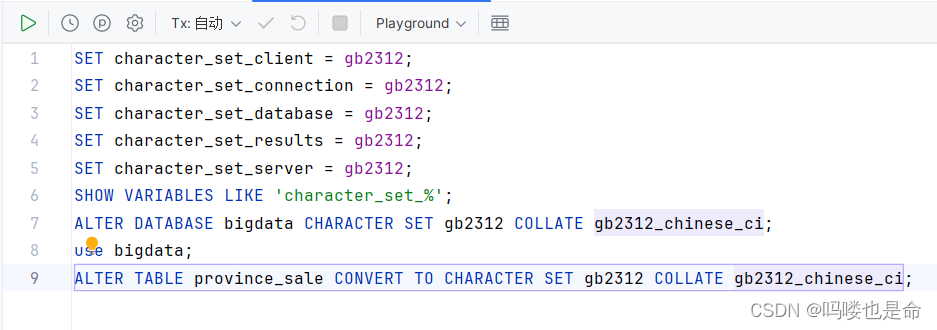
四、项目运行问题及解决方法
报错:java.sql.BatchUpdateException: Incorrect string value: '\xE6\xB1\x9F\xE8\xA5\xBF...' for column 'storeProvince' atrow1
原因:MySQL的UTF-8只支持3个字节的unicode字符,无法支持四个字节的Unicode字符
解决办法:在MySQL控制台执行下列代码修改编码格式