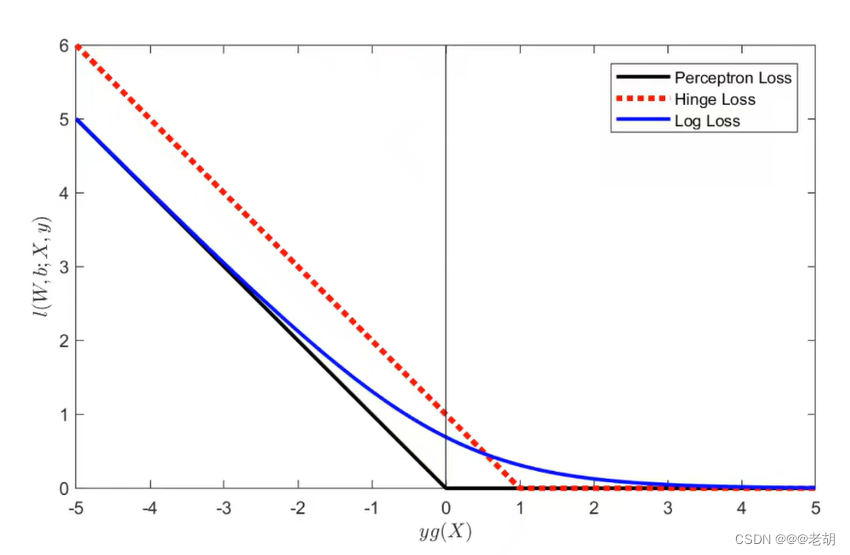
文章目录
- 一、关联式容器与键值对
- 1.1关联式容器(之前学的都是序列容器)
- 1.2键值对pair
- make_pair函数(map在插入的时候会很方便)
- 1.3树形结构的关联式容器
- 二、set
- 2.1set的基本介绍
- 2.1默认构造、迭代器区间构造、拷贝构造(深拷贝)
- 2.2set的迭代器
- 2.3set的插入与删除
- 1.insert(有时候插入会直接改变树的结构)
- 2.find&&erase
- 3.`count`:**返回个数,可以判断一个值是否存在**
- 三、multiset
- 四、map(知识点多)
- 4.1map的模板参数
- 4.2map的构造
- 4.3map的修改([]的完整用法是最难理解的)
- 1.insert插入(make_pair(x,y)别忘了写)
- 2.引入[]之统计次数
- 3.详解[]的使用以及底层原理
- []的三个功能
- []的底层原理
- map[]的总结
- 4.4综合题之map利用字符串流统计出现次数
- 五、multimap
- 六、leetcode真题
- 6.1set之俩个数组的交集
- 6.2map之前K个高频单词
一、关联式容器与键值对
1.1关联式容器(之前学的都是序列容器)
在C++初阶的时候,我们已经接触了 STL 中的部分容器并进行了模拟实现,比如 vector、list、stack、queue 等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身;
同样,关联式容器也是用来存储数据的,但与序列式容器不同的是,关联式容器里面存储的是 <key, value> 结构的键值对,因此**在数据检索时比序列式容器效率更高**。
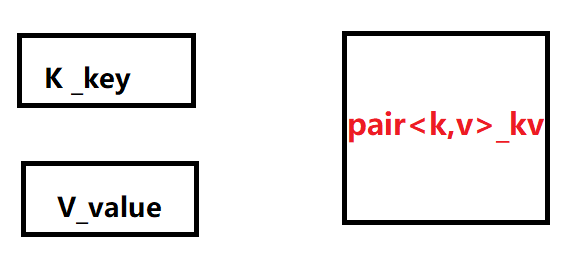
1.2键值对pair
键值对是用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量 – key 和 value;其中 key 代表键值,value 代表与 key 对应的信息。
我们利用英汉互译的字典来理解:该字典中必然有英文单词与其对应的中文含义,而且,英文单词与其中文含义是一一对应的关系,即通过该应该单词,在词典中就可以找到与其对应的中文含义。
template <class T1, class T2>
struct pair
{typedef T1 first_type;typedef T2 second_type;T1 first; //keyT2 second; //valuepair() : first(T1()), second(T2()) //默认构造{}pair(const T1& a, const T2& b) : first(a), second(b){}
};
可以看到,C++ 中的键值对是通过 pair 类来表示的,pair 类中的 first 就是键值 key,second 就是 key 对应的信息 value;那么以后我们在设计 KV 模型的容器时只需要在容器/容器的每一个节点中定义一个 pair 对象即可;
问题:为什么不直接在容器中定义 key 和 value 变量,而是将 key、value 合并到 pair 中整体作为一个类型来使用呢?
答:这是因为 C++ 一次只能返回一个值,如果我们将 key 和 value 单独定义在容器中,那么我们就无法同时返回 key 和 value;而如果我们将 key、value 定义到另一个类中,那我们就可以直接返回 pair,然后再到 pair 中分别去取 first 和 second 即可
make_pair函数(map在插入的时候会很方便)
由于 pair 是类模板,所以我们通常是以 显式实例化 + 匿名对象 的方式来进行使用,但是由于显式实例化比较麻烦,所以 C++ 还提供了make_pair 函数,其定义如下:
template <class T1, class T2>
pair<T1, T2> make_pair(T1 x, T2 y)
{return (pair<T1, T2>(x, y));
}
如上,make_pair 返回的是一个 pair 的匿名对象,匿名对象会自动调用 pair 的默认构造完成初始化;但由于 make_pair 是一个函数模板,所以模板参数的类型可以根据实参来自动推导完成隐式实例化,这样我们就不用每次都显式指明参数类型了。
小羊注:对于这个返回的是不是匿名对象,我有点不理解。

注:由于 make_pair 使用起来比 pair 方便很多,所以我们一般都是直接使用 make_pair,而不使用 pair
1.3树形结构的关联式容器
根据应用场景的不同,STL 总共实现了两种不同结构的关联式容器
树型结构与哈希结构;树型结构的关联式容器主要有四种:
map、set、multimap、multiset
这四种容器的共同点是使用平衡二叉搜索树作为其底层结构,容器中的元素是一个有序的序列;本文将介绍这四个容器的使用
二、set
2.1set的基本介绍
set 是按照一定次序存储元素的容器,其底层是一棵平衡二叉搜索树 (红黑树),由于二叉搜索树的每个节点的值满足左孩子 < 根 < 右孩子,并且二叉搜索树中没有重复的节点,所以 set 可以用来排序、去重和查找,同时由于这是一棵平衡树,所以 set 查找的时间复杂度为 O(logN),效率非常高
set 从1000个数据找查找某个数据最多找10次,从100万个数据中找某一个数据最多找20次,从10亿个数据中找某一个数据最多找30次;我们中国现在人口总数估计已经大于10亿了,那么如果想查找是不是得费很多次数?并不是,2^31=20亿直接解决问题,所以最多31次可以精确定位到一个人。
同时,set 是一种 K模型 的容器,也就是说,set 中只有键值 key,而没有对应的 value,并且每个 key 都是唯一的 ;set 中的元素也不允许修改,因为这可能会破坏搜索树的结构,但是 set 允许插入和删除。
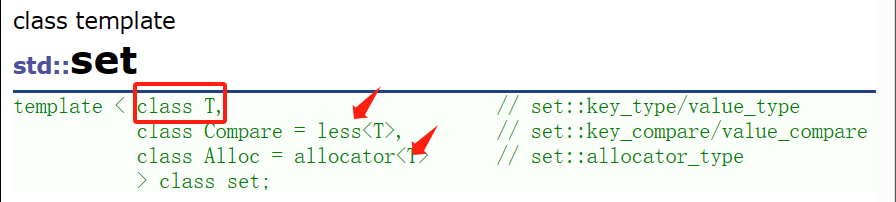
T: set中存放元素的类型,实际在底层存储<value, value>的键值对。
Compare:仿函数,set中元素默认按照小于来比较
Alloc:set中元素空间的管理方式,使用STL提供的空间配置器管理
特点:
- set 是K模型的容器,所以 set 中插入元素时,只需要插入 key 即可,不需要构造键值对
- set中的元素不可以重复,因此可以使用set进行去重(multiset相反)
- 由于 set 底层是搜索树,所以使用 set 的迭代器遍历 set 中的元素,可以得到有序序列,即 set 可以用来排序
- set 默认使用的仿函数为 less,所以 set 中的元素默认按照小于来比较
- 由于 set 底层是平衡树搜索树,所以 set 中查找某个元素,时间复杂度为 O(logN)
- set 中的元素不允许修改,因为这可能破坏搜索树的结构
- set 中的底层使用平衡二叉搜索树 (红黑树) 来实现
set 文档:set - C++ Reference (cplusplus.com)
2.1默认构造、迭代器区间构造、拷贝构造(深拷贝)
void test_set()
{int arr[] = { 1,2,3,4,5 };set<int> s;//默认构造set<int> s1(arr, arr + 5);//区间构造set<int> s2(s1);//拷贝构造for (auto e : s1) cout << e << " "; cout << endl;for (auto e : s2) cout << e << " "; cout << endl;}
2.2set的迭代器
| 函数声明 | 功能介绍 |
|---|---|
| iterator begin()/end() | 返回set中起始位置元素的迭代器返回set中最后一个元素后面的迭代器 |
| const_iterator cbegin() cend() const | 返回set中起始位置元素的const迭代器返回set中最后一个元素后面的const迭代器 |
| reverse_iterator rbegin() rend() | 返回set第一个元素的反向迭代器,即end,返回set最后一个元素下一个位置的反向迭代器,即 rbegin |
| const_reverse_iterator crbegin() ,crend() const | 返回set第一个元素的反向const迭代器,即cend,返回set最后一个元素下一个位置的反向const迭代器, 即crbegin |
我们简单来看一看代码:
void test_set1()
{//输入121345
set<int> s;
s.insert(1);
s.insert(2);
s.insert(1);
s.insert(3);
s.insert(4);
s.insert(5);
//排序+去重
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
set<int>::iterator it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}
cout << endl;
}
2.3set的插入与删除
1.insert(有时候插入会直接改变树的结构)
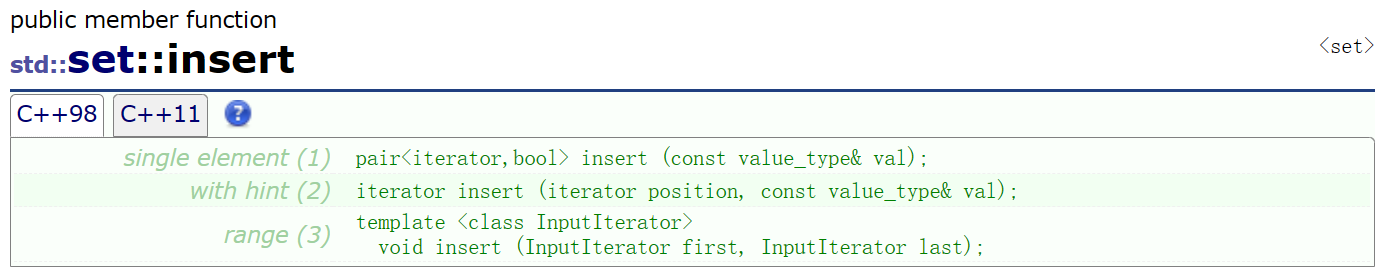

使用起来一定要小心,这个是set不是map,只插入一个值就可以了!
2.find&&erase
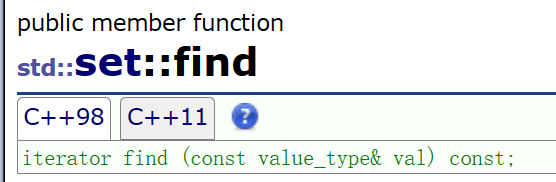
为什么这个库自己写find??别忘了上面讲的算法复杂度,正常的查找都是暴力O(N),set可是妥妥的O(logN)效率相差很大!

在这里erase有一个小细节我想聊聊:
erase的第一个函数是迭代器参数+find函数就可以实现第二个重载的样子
erase的第二个函数有一个小“漏洞”:即使没有这个值,删除也不会报错
(但是我们可以通过接收返回值来判断是否成功删除,这也就是我为什么说:第二个erase有find的能力)
为此,我还去找了vector的erase,毕竟之前想要精确的删除一个值都得加find,而这里有一个独立的直接可以删除值的函数,岂不美哉?!
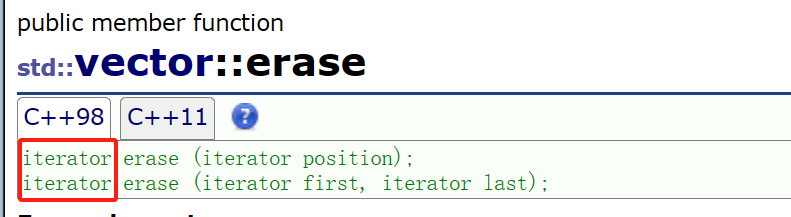
果然,vector的erase返回值并没有size_t这个类型的,毕竟别的序列化容器的find可没有这么优秀的find接口,怎敢被随便调用?
#include<iostream>
#include<set>
using namespace std;
int main()
{set<int> s;s.insert(1); s.insert(2);s.insert(3);for(auto it:s){cout << it << " ";}cout << endl;s.erase(4);for(auto it:s){cout << it << " ";}cout << endl;cout << s.erase(4);return 0;
}
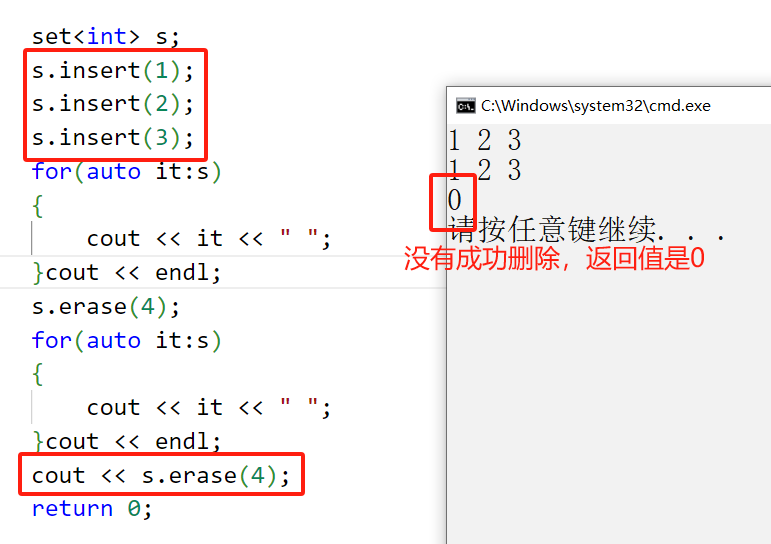
接下来我们来看erase的第一个构造的用法:
void test_set3()
{set<int> s;s.insert(1);s.insert(2);s.insert(3);set<int>::iterator it = s.begin();while (it != s.end()){ cout << *it << " ";++it;}cout << endl;//1 2 3auto pos = s.find(3);//谁用后面这个函数我笑话谁:auto pos = find(s.begin(), s.end(), 3);if (pos != s.end()){s.erase(pos);}for (auto e : s) cout << e << " ";cout << endl;//1 2
}
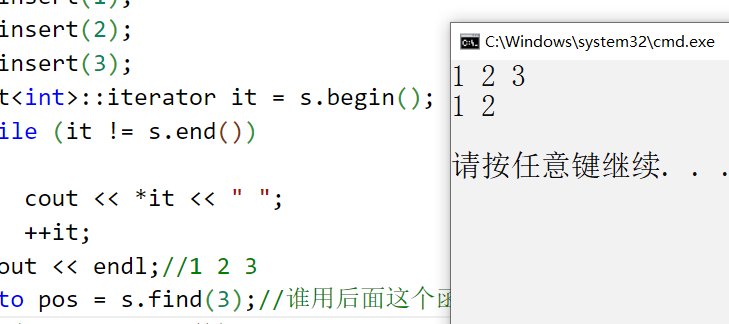
3.count:返回个数,可以判断一个值是否存在

是不是感觉和erase的第二个感觉效果挺像的,只不过不删除数据捏,这个接口和find类似,那么是不是冗余接口捏??
count不是为此设计的!是为了和
multiset容器保持接口的一致性。
三、multiset
multiset是按照特定顺序存储元素的容器,其中元素是可以
重复的。在multiset中,元素的value也会识别它(因为multiset中本身存储的就是<value, value>组成的键值对,因此value本身就是key,key就是value,类型为T). multiset元素的值不能在容器中进行修改(因为元素总是const的),但可以从容器中插入或删除。
在内部,multiset中的元素总是按照其内部比较规则(类型比较)所指示的特定严格弱排序准则进行排序。
multiset容器通过key访问单个元素的速度通常比unordered_multiset容器慢,但当使用迭代器遍历时会得到一个有序序列。
multiset底层结构为
二叉搜索树(红黑树)
上面说了这么多的内容,其实就是与set的区别是👉:multiset中的元素可以重复,set是中value是唯一的
void test_multiset()
{int arr[] = {1,2,3,1,1,6,8};multiset<int> s(arr, arr + sizeof(arr) / sizeof(int));for (auto& e : s){cout << e << " ";} cout << endl;
}

另外,如果有多个值相同,find返回的值是中序的第一个:
void multiset_test2()
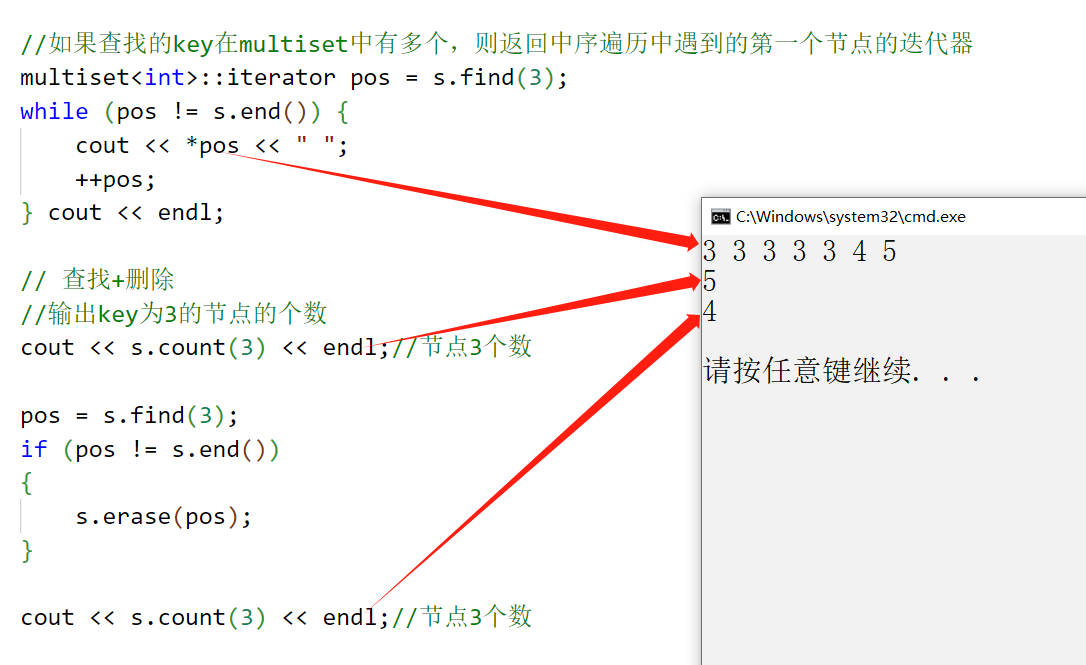
{// 用数组array中的元素构造multisetint array[] = {1,2,3,3,3,5,1,2,3,4,3};multiset<int> s(array, array + sizeof(array) / sizeof(array[0]));//如果查找的key在multiset中有多个,则返回中序遍历中遇到的第一个节点的迭代器multiset<int>::iterator pos = s.find(3);while (pos != s.end()) {cout << *pos << " ";++pos;} cout << endl;// 查找+删除//输出key为3的节点的个数cout << s.count(3) << endl;//节点3个数pos = s.find(3);if (pos != s.end()){s.erase(pos);}cout << s.count(3) << endl;//节点3个数
}
四、map(知识点多)
- map是
关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素。- 在map中,键值key通常用于
排序和唯一地标识元素,而值value中存储与此键值key关联的内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型value_type绑定在一起,为其取别名称为pair:typedef pair value_type;- 在内部,map中的元素总是按照键值
key进行比较排序的。- map中通过键值访问单个元素的速度通常比unordered_map容器慢,但map允许根据顺序对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)。
- map
支持下标访问符,即在[]中放入key,就可以找到与key对应的value。- map通常被实现为二叉搜索树(更准确的说:平衡
二叉搜索树(红黑树))
4.1map的模板参数

key: 键值对中key的类型
T:键值对中value的类型
Compare: 比较器的类型,map中的元素是按照key来比较的,缺省情况下按照小于来比较,一般情况下(内置类型元素)该参数不需要传递,如果无法比较时(自定义类型),需要用户自己显式传递比较规则(一般情况下按照函数指针或者仿函数来传递)
Alloc:通过空间配置器来申请底层空间,不需要用户传递,除非用户不想使用标准库提供的空间配置器
4.2map的构造

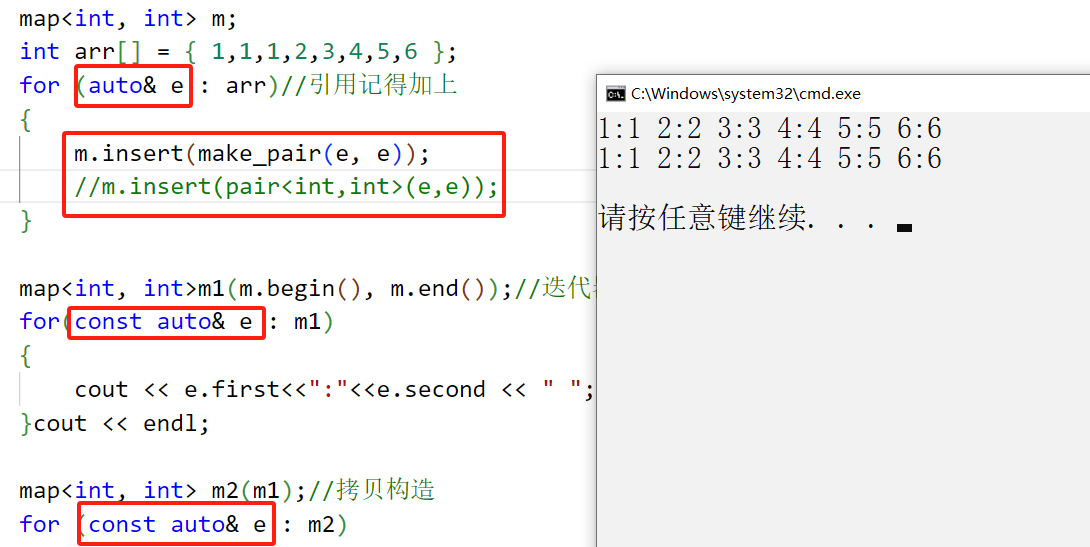
这一块是用范围for最得注意的一部分,由于其数据的庞大性,所以我们的**auto后面常常需要增加引用**,如果输出的话,加上const更好
void test_map()
{map<int, int> m;int arr[] = { 1,1,1,2,3,4,5,6 };for (auto& e : arr)//引用记得加上{m.insert(make_pair(e, e));//m.insert(pair<int,int>(e,e));}map<int, int>m1(m.begin(), m.end());//迭代器区间构造for(const auto& e : m1){cout << e.first<<":"<<e.second << " "; }cout << endl;map<int, int> m2(m1);//拷贝构造for (const auto& e : m2){cout << e.first << ":" << e.second << " ";}cout << endl;
}
4.3map的修改([]的完整用法是最难理解的)
1.insert插入(make_pair(x,y)别忘了写)
void test_map1()
{map<string, string> dict;dict.insert(pair<string, string>("排序", "sort"));dict.insert(pair<string, string>("左边", "left"));dict.insert(pair<string, string>("右边","right"));//make_pair()dict.insert(make_pair("字符串", "string"));//输出查看结果map<string, string>::iterator it = dict.begin();while (it != dict.end()){cout << it->first<<":"<<it->second << endl;//访问元素这么访问,一定要注意了++it;}cout << endl;
}
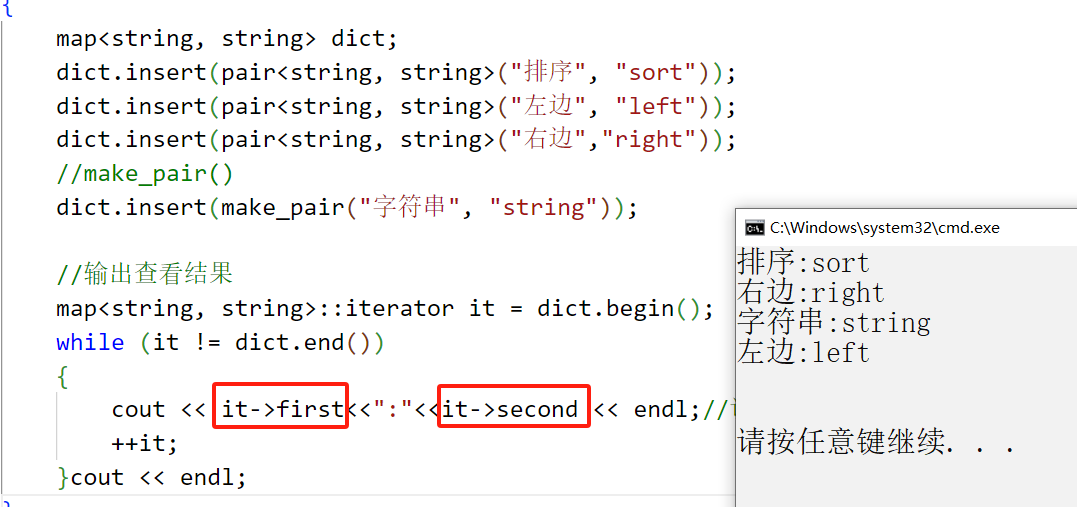
make_pair:函数模板,不需要像pair一样显示声明类型,而是通过传参自动推导,相比于typedef更好用一些

2.引入[]之统计次数
统计不同水果出现的个数
第一种方法:迭代器
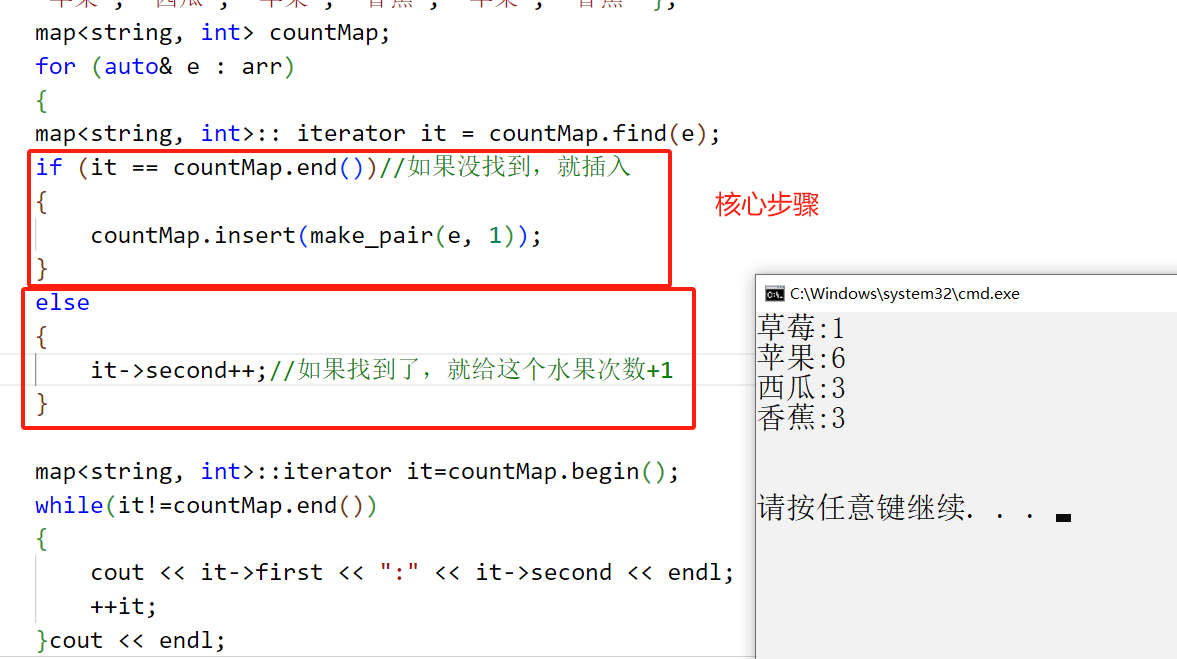
void test_map_total()
{
//统计水果出现的次数string arr[] = { "苹果", "西瓜", "香蕉", "草莓", "苹果", "西瓜", "苹果","苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;for (auto& e : arr){map<string, int>:: iterator it = countMap.find(e);if (it == countMap.end())//如果没找到,就插入{countMap.insert(make_pair(e, 1));}else{it->second++;//如果找到了,就给这个水果次数+1}
}map<string, int>::iterator it=countMap.begin();while(it!=countMap.end()){cout << it->first << ":" << it->second << endl;++it;}cout << endl;
}
第二种方法:map[]的使用:
void test_map_total2()
{//统计水果出现的次数string arr[] = { "苹果", "西瓜", "香蕉", "草莓", "苹果", "西瓜", "苹果","苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;for (auto& e : arr){countMap[e]++;//如果找不到就插入,找到就给第二个值++}for (const auto& kv : countMap){cout << kv.first << ":" << kv.second << endl;}
}
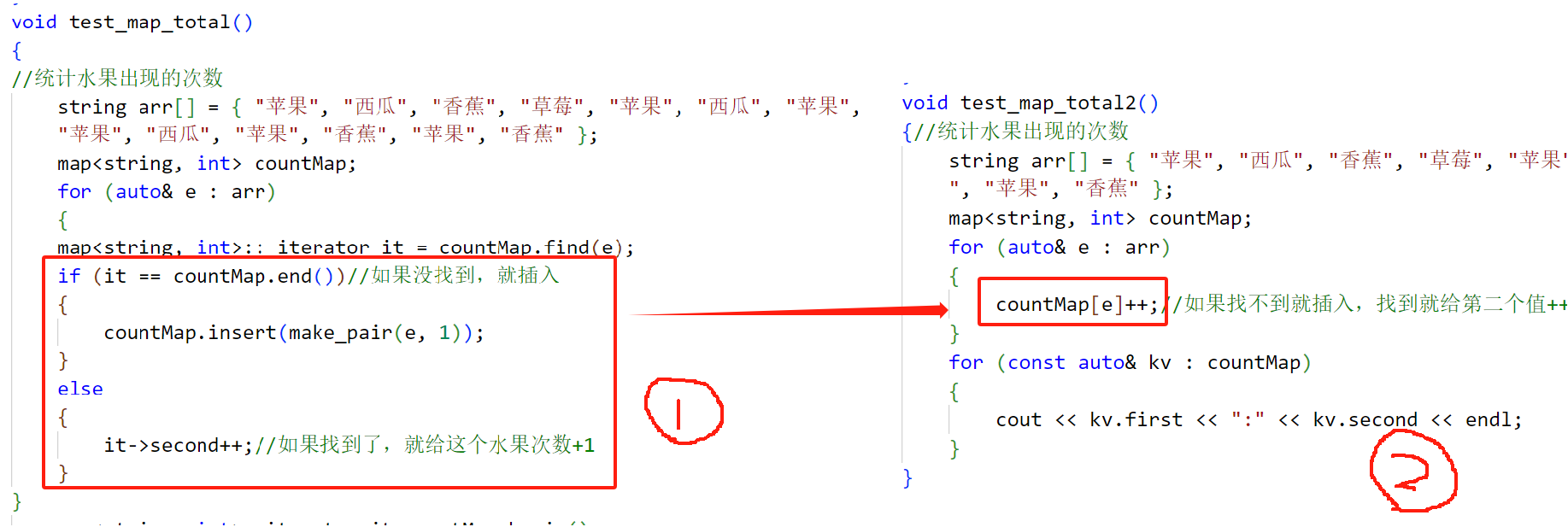
map的[]支持随机访问这个可以理解,但是为什么++就可以实现我们的任务呢??
3.详解[]的使用以及底层原理
[]的三个功能
- 插入(本质上operator中用了insert函数)
- 修改(本质是返回值是对象的second的引用)
- 查找(本质上是insert的第二个pair参数)
一句话解释清楚:给一个key,可以查找在不在,如果不在则可以插入,在的话either可以查找or可以进行修改value
代码解释:
void test_insert_change_find()
{map<string, string> dict;dict.insert(make_pair("上", "up"));dict.insert(make_pair("下", "down"));dict.insert(make_pair("左", "left"));dict.insert(make_pair("右", "right"));//插入(前提是key不在)dict["迭代器"];//修改dict["迭代器"]= "iterator";//查找(前提是得key在,key要是不在可就成了插入了)cout << dict["上"] << endl; cout << endl;cout << endl;cout << "输出map中的值" << endl;map<string, string>::iterator it=dict.begin();while (it != dict.end()){cout << it->first<<":"<<it->second << endl;++it;//老忘了写}cout << endl;
}
map在输出的时候,好像里面的key值也是从小到大排序的

注意:[]用的时候要小心,不在的话会偷偷给你插入
[]的底层原理
operator[]函数原型如下:
mapped_type& operator[] (const key_type& k);
//mapped_type: pair中第二个参数,即second
//key_type: pair中第一个参数,即first
operator[]函数定义如下:
mapped_type& operator[] (const key_type& k)
{(*((this->insert(make_pair(k, mapped_type()))).first)).second;
}
拆分operator[]函数定义:(这个是核心)
V& operator[] (const K& k)//返回值是引用,所以外面可以修改eg:m[i]++
{pair<iterator, bool> ret = insert(make_pair(k, V()));//make_pair里面是匿名对象//return *(ret.first)->second;return ret.first->second;
}
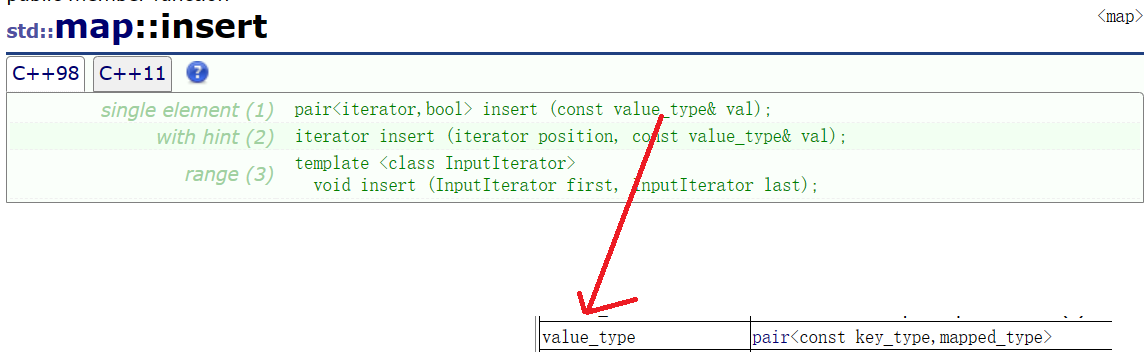
insert函数定义如下:
pair<iterator,bool> insert (const value_type& val)
{//可以看到,insert的返回值是pair,pair的第一个参数是迭代器//bool:插入成功.....1,插入失败.....0
}
insert函数的返回值:(因为operator[]函数中的ret参数接受insert返回值)

用我“高超”的英语功底翻译之后,我们可得知:
- 若 key 相等:返回 key 位置迭代器+false
- 若 key 不相等:返回 key 新插入位置迭代器+true
接着我们目光转移到拆分的[]函数当中:
operator[] 会取出 pair 中的迭代器 (也就是ret.first),然后对迭代器进行解引用得到一个 pair<k, v> 对象(但是这里编译器进行优化了,这个*不写也是可以的),最后再返回 pair 对象中的 second 的引用,即 key 对应的 value 的引用;所以我们可以在函数外部直接修改 key 对应的 value 的值(如果不返回引用的话,那么一定是不可能++就改变值大小的)
map[]的总结

4.4综合题之map利用字符串流统计出现次数
//一个经典的期末考试题目
#include<iostream>
#include<map>
#include<string>
#include<sstream>
using namespace std;
int main()
{string s="1 2 3 4 5 6 7 8 9 1 2 1 2 3 4 5 6 4 2 3 4";//注意,这里一定是得有空格的,为了和之后的string stream对应map<int,int>m;stringstream is(s);//把字符串构造了is字符串流类对象while(is.eof()!=true) //如果到了文件尾部 则自动返回true 如果没到 则返回false{int num;//num << is; is >> num ;//is的值流向num 此时num有1 因为后面有空格 无法接收更多的值m[num]++;//小心 不是m[num++];!!!!!!!//经典的统计数字的方法 如果没有就插入 如果有就将第二个值++ 而且还可以返回第二个值的大小 //V& operator(const key& k)}cout << m[2] << endl;//(*((this->insert(make_pair(k,mapped_type()))).first)).second 返回的是数字2的统计次数return 0;
}
五、multimap
和 set 与 multiset 的关系一样,multimap 存在的意义是允许 map 中存在 key 值相同的节点,multimap 与map 的区别和 multiset 与 set 的区别一样 – find 返回中序遍历中遇到的第一个节点的迭代器,count 返回和 key 值相等的节点的个数:


需要注意的是,multimap 中并没有重载 [] 运算符,因为 multimap 中的元素是可以重复的,如果使用 [] 运算符,会导致多个元素的 key 值相同,无法确定具体访问哪一个元素
六、leetcode真题
6.1set之俩个数组的交集
两个数组的交集(双指针,而且出现一大一小,必须是小元素先++;出现相同就一起++)

给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序。
利用set的排序+去重特性,然后去进行比对,找出两个数组之间的交集:
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {//排序+去重set<int> s1(nums1.begin(),nums1.end());set<int> s2(nums2.begin(),nums2.end());//比对算法逻辑auto it1 = s1.begin();auto it2 = s2.begin();vector<int> ret;while(it1!=s1.end()&&it2!=s2.end()){if(*it1==*it2){ret.push_back(*it1);it1++;it2++;}else if(*it1>*it2){it2++;}else{it1++;}}return ret;}
};
6.2map之前K个高频单词
前K个高频单词(与sort的稳定性以及pair的大小比较规则有关,较难)

给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
class Solution {
public:class greater{public:bool operator()(const pair<string,int>&l,const pair<string,int>& r){return l.second>r.second||(l.second==r.second&&l.first<r.first);}};vector<string> topKFrequent(vector<string>& words, int k) {unordered_map<string,int> countMap;for(auto&e:words) countMap[e]++;priority_queue<pair<string,int>,vector<pair<string,int>>,greater> pq;for(auto it = countMap.begin();it!=countMap.end();it++){pq.push(*it);if(pq.size()>k)pq.pop();}vector<string> ret;ret.resize(k);for(int i = k-1;i>=0;i--){ret[i] = pq.top().first;pq.pop();}return ret;}
};
希望给大家带来帮助!!!