1.字符编码与解码.
(1). 字符编码 : 将字符,字符串,字符数组------> 字节,字节数组.
(2). 字节,字节数组------>字符,字符串,字符数组.
如果希望程序在读取文件时(也就是解码)不会发生字符乱码的问题,需要保证解码时使用的字符集与编码时使用的字符集一致.
这就需要用到转换流.
2.转换流.
(1). 作用 : 实现字节与字符之间的转换.
(2). 常见API :
InputStreamReader : 将一个输入型字节流转换为输入型字符流.
OutputStreamWriter : 将一个输出型字符流转换为输出型字节流.
(3). 例 :
@Testpublic void test9() {InputStreamReader isr = null;try {File file = new File("src/hello.txt");FileInputStream fis = new FileInputStream(file);isr = new InputStreamReader(fis);char[] cbuffer = new char[5];int len;while((len = isr.read(cbuffer)) != -1) {for (int i = 0; i < len; i++) {System.out.print(cbuffer[i]);}}} catch (IOException e) {throw new RuntimeException(e);} finally {try {isr.close();} catch (IOException e) {throw new RuntimeException(e);}}}
控制台
abc123
hexua
你是个大**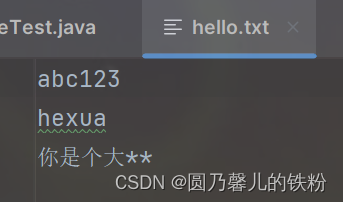
注 :
isr = new InputStreamReader(fis);
此处默认的是使用的是"utf-8"字符集.
按住Ctrl+p可以查看参数列表.
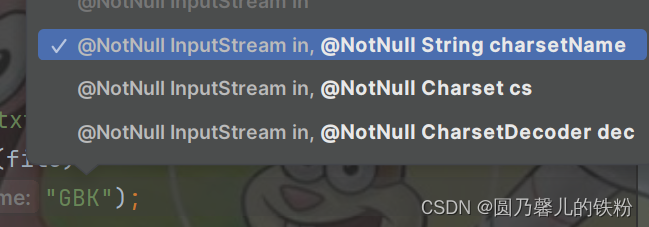
说明我们可以在此处传入字符集.比如 :
isr = new InputStreamReader(fis, "GBK");
如果我们此时使用的是如上输入型字符流.运行代码可以看到乱码.
abc123
hexua
浣犳槸涓ぇ**那么为什么会发生乱码呢?很明显,编码集默认用的"utf-8",而此时解码集用的"GBK"不一致.而我们可以看到,英文字符与数字并没有发生乱码的现象,反而中文出现了乱码.为什么呢?也很简单,因为utf-8与gbk都向下兼容了ASCII码,都使用一个字符存的,所以没有发生乱码.而中文却发生乱码.因为一个中文字符在gbk中占两个字符,而在utf8中占3个字符.
3.字符集
(1). 在文件中存储的字符集
- ASCII : 主要用来存储a,b,c等英文字符及数字和特殊符号.
- gbk : 用来存储中文简体繁体,并向下兼容ASCII,意味着英文字母等仍然占一个字节.而中文字符使用两个字符.
- utf-8 : 可以用来存储世界范围内主要的语言的所有字符.使用1-4个不等的字节表示一个字符.中文字符使用3个字节存储.同时又向下兼容ASCII.
(2). 在内存中存储的字符
- 在内存中的字符都以两个字节存储.'a'也用两个字节存储,只是只使用了一半的空间.




![[SystemVerilog]常见设计模式/实践](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fsystemverilog.dev%2Fimages%2F04%2Fwishbone_diagram.svg&pos_id=HJ7nmITM)