深度学习模型类
- 简介
- 按滑动时间窗口切割数据集
- 模型类
- CNN
- GRU
- LSTM
- MLP
- RNN
- TCN
- Transformer
- Seq2Seq
简介
本文所定义模型类的输入数据的形状shape统一为 [batch_size, time_step,n_features],batch_size为批次大小,time_step为时间步长,n_features为特征数量。另外该模型类同时适用于单特征与多特征
本项目代码统一了训练方式,只需在models文件夹中加入下面模型类,即可使用该模型,而不需要重新写训练模型等的代码,减少了代码的冗余。
代码有注释,不加解释
声明:转载请标明出处
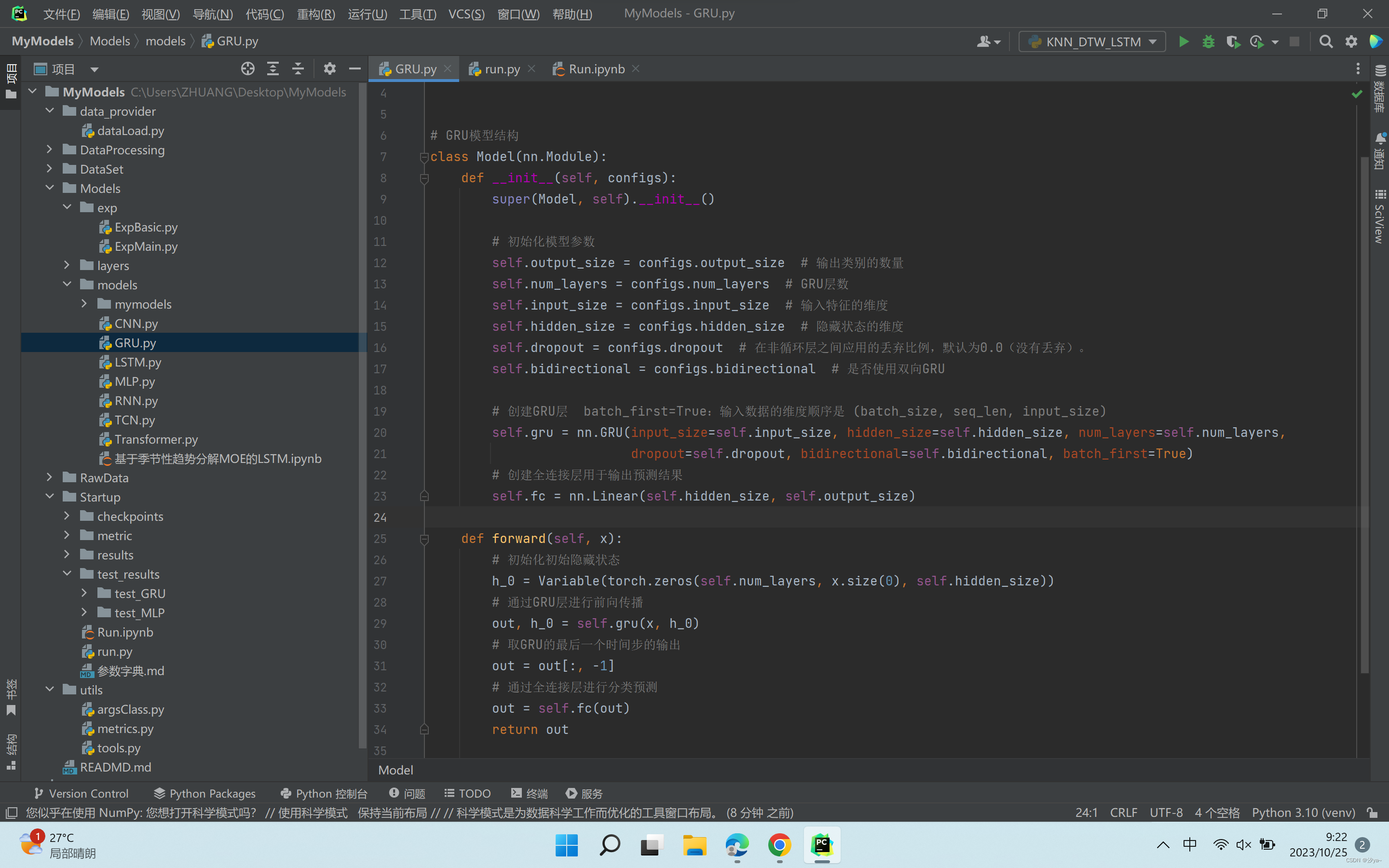
超参数只需通过字典定义传入即可,所有训练方式一样的模型通用
按滑动时间窗口切割数据集
import osimport pandas as pd
import torch
from sklearn.preprocessing import MinMaxScaler
from torch.utils.data import Dataset, DataLoaderclass TimeSeriesDataset(Dataset):"""自定义的时间序列数据集类,用于处理时间序列数据的加载和预处理。目的是将时间序列数据准备成适合机器学习模型训练的格式(按滑动窗口划分)。Args:data (torch.Tensor): 包含时间序列数据的张量,形状为 [1, n_features, data_len]args.time_step (int): 输入数据的时间步。args.skip (int): 输入数据的跳跃步。Returns:tuple: 包含输入数据 x 和目标数据 y 的元组。X: 输入数据的批次,形状为 [time_step, n_features]Y: 目标数据的批次,形状为 [1]"""def __init__(self, data, args):self.data = dataself.time_step = args.time_stepself.skip = args.skipdef __len__(self):n = self.data.shape[-1] - self.time_step + 1 - self.skipreturn ndef __getitem__(self, idx):x = self.data[:, :, idx:idx + self.time_step].permute(2, 1, 0).squeeze(-1)y = self.data[:, :1, idx + self.time_step + self.skip - 1].view(-1)return x, ydef Dataset_Custom(args, if_Batching=True):"""创建自定义时间序列数据集Args:args (Namespace): 包含所有必要参数的命名空间。if_Batching: 是否批次化,类似XGBoost算法不需要Returns:Tuple[TimeSeriesDataset, TimeSeriesDataset, TimeSeriesDataset]: 训练、验证和测试数据集"""# 读取数据data = pd.read_csv(os.path.join(args.root_path, args.data_path))# 检查是否存在 "date" 列,如果存在则删除if 'date' in data.columns:data = data.drop('date', axis=1)# 确保 "load" 列是第一列,如果不是,将其移到第一列if args.target in data.columns:data = data[[args.target] + [col for col in data.columns if col != args.target]]# 定义数据集划分比例(例如,70% 训练集,10% 验证集,20% 测试集)data_len = len(data)num_train = int(data_len * 0.7)num_test = int(data_len * 0.2)num_vali = data_len - num_train - num_testtrain_data = data[:num_train]vali_data = data[num_train:num_train + num_vali]test_data = data[num_train + num_vali:]# 归一化scaler = MinMaxScaler(feature_range=(0, 1))scaler.fit(train_data)train_data = scaler.transform(train_data)vali_data = scaler.transform(vali_data)test_data = scaler.transform(test_data)# 转换为张量并添加维度train_data = torch.from_numpy(train_data).float()vali_data = torch.from_numpy(vali_data).float()test_data = torch.from_numpy(test_data).float()# 将其变为[1, n_features, data_len]train_data = train_data.unsqueeze(0).permute(0, 2, 1)vali_data = vali_data.unsqueeze(0).permute(0, 2, 1)test_data = test_data.unsqueeze(0).permute(0, 2, 1)# 按滑动时间窗口转成机器学习的数据格式training_dataset = TimeSeriesDataset(train_data, args)valiing_dataset = TimeSeriesDataset(vali_data, args)testing_dataset = TimeSeriesDataset(test_data, args)print(f"train:{len(training_dataset)},vali:{len(valiing_dataset)},test:{len(testing_dataset)}")if if_Batching:# 创建数据加载器,用于批量加载数据train_loader = DataLoader(training_dataset, shuffle=True, drop_last=True, batch_size=args.batch_size)vali_loader = DataLoader(valiing_dataset, shuffle=True, drop_last=True, batch_size=args.batch_size)test_loader = DataLoader(testing_dataset, shuffle=False, drop_last=False, batch_size=len(testing_dataset))return train_loader, vali_loader, test_loaderelse:return training_dataset, valiing_dataset, testing_dataset模型类
CNN
import torch
from torch import nnclass Model(nn.Module):def __init__(self, configs):super(Model, self).__init__()self.input_size = configs.input_size # 输入特征的大小self.output_size = configs.output_size # 预测结果的维度self.time_step = configs.time_step # 时间步数self.kernel_size = configs.kernel_size # 卷积核的大小self.relu = nn.ReLU(inplace=True) # ReLU激活函数# 第一个卷积层self.conv1 = nn.Sequential(nn.Conv1d(in_channels=self.input_size, out_channels=64, kernel_size=self.kernel_size),# 输入特征维度为input_size,输出通道数为64,卷积核大小为kernel_sizenn.ReLU(), # ReLU激活函数nn.MaxPool1d(kernel_size=self.kernel_size, stride=1) # 最大池化,池化窗口大小为kernel_size,步长为1)# 第二个卷积层self.conv2 = nn.Sequential(nn.Conv1d(in_channels=64, out_channels=128, kernel_size=2),# 输入通道数为64,输出通道数为128,卷积核大小为2nn.ReLU(), # ReLU激活函数nn.MaxPool1d(kernel_size=self.kernel_size, stride=1) # 最大池化,池化窗口大小为kernel_size,步长为1)# 根据卷积操作后的数据格式和输出大小计算线性层的输入维度conv_output_size = self._calculate_conv_output_size()# 线性层1,输入维度为卷积层输出大小,输出维度为50self.linear1 = nn.Linear(conv_output_size, 50)# 线性层2,输入维度为50,输出维度为预测结果的维度self.linear2 = nn.Linear(50, self.output_size)def forward(self, x):x = x.transpose(1, 2)x = self.conv1(x)x = self.conv2(x)x = x.view(x.size(0), -1)x = self.linear1(x)x = self.relu(x)x = self.linear2(x)x = x.view(x.shape[0], -1)return xdef _calculate_conv_output_size(self):"""自动计算卷积层输出形状,此操作避免手算该参数 参数:input_size( 输入特征维度 )返回值: conv_output_size (卷积层输出的特征维度)"""input_tensor = torch.zeros(1, self.input_size, self.time_step) # 创建输入零张量,维度为(1, input_size, time_step)conv1_output = self.conv1(input_tensor)conv2_output = self.conv2(conv1_output)conv_output_size = conv2_output.view(conv2_output.size(0), -1).size(1)return conv_output_sizeGRU
import torch
from torch import nn
from torch.autograd import Variable# GRU模型结构
class Model(nn.Module):def __init__(self, configs):super(Model, self).__init__()# 初始化模型参数self.output_size = configs.output_size # 输出类别的数量self.num_layers = configs.num_layers # GRU层数self.input_size = configs.input_size # 输入特征的维度self.hidden_size = configs.hidden_size # 隐藏状态的维度self.dropout = configs.dropout # 在非循环层之间应用的丢弃比例,默认为0.0(没有丢弃)。self.bidirectional = configs.bidirectional # 是否使用双向GRU# 创建GRU层 batch_first=True:输入数据的维度顺序是 (batch_size, seq_len, input_size)self.gru = nn.GRU(input_size=self.input_size, hidden_size=self.hidden_size, num_layers=self.num_layers,dropout=self.dropout, bidirectional=self.bidirectional, batch_first=True)# 创建全连接层用于输出预测结果self.fc = nn.Linear(self.hidden_size, self.output_size)def forward(self, x):# 初始化初始隐藏状态h_0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size))# 通过GRU层进行前向传播out, h_0 = self.gru(x, h_0)# 取GRU的最后一个时间步的输出out = out[:, -1]# 通过全连接层进行分类预测out = self.fc(out)return outLSTM
import torch
import torch.nn as nn
from torch.autograd import Variableclass Model(nn.Module):def __init__(self, configs):super(Model, self).__init__()self.input_size = configs.input_size # 输入特征的大小。self.hidden_size = configs.hidden_size # LSTM 隐藏状态的维度self.num_layers = configs.num_layers # LSTM 层的堆叠层数self.output_size = configs.output_size # 输出的大小(预测结果的维度)self.dropout = configs.dropout # 在非循环层之间应用的丢弃比例,默认为0.0(没有丢弃)。self.bidirectional = configs.bidirectional # 如果为True,LSTM将是双向的(包括前向和后向),默认为False。self.lstm = nn.LSTM(input_size=configs.input_size, hidden_size=configs.hidden_size,num_layers=configs.num_layers, dropout=self.dropout, bidirectional=self.bidirectional,batch_first=True) # 定义 LSTM 层self.fc = nn.Linear(configs.hidden_size, configs.output_size) # 定义线性层,将 LSTM 输出映射到预测结果的维度def forward(self, x):h_0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size)) # 初始化 LSTM 的隐藏状态c_0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size)) # 初始化 LSTM 的记忆状态ula, (h_out, _) = self.lstm(x, (h_0, c_0)) # 前向传播过程,返回 LSTM 层的输出序列和最后一个时间步的隐藏状态h_out = h_out[-1, :, :].view(-1, self.hidden_size) # 提取最后一个时间步的隐藏状态并进行形状变换''''使用LSTM的最后一个时间步的隐藏状态h_out作为线性层的输入,是因为模型将隐藏状态视为包含了序列信息的高层表示。在许多情况下,使用最后一个时间步的隐藏状态进行预测已经足够。'''out = self.fc(h_out) # 将最后一个时间步的隐藏状态通过线性层进行预测return outMLP
import torch.nn as nn# MLP模型结构
class Model(nn.Module):def __init__(self, configs):super(Model, self).__init__()self.input_size = configs.input_size # 输入特征的大小,即输入层的维度。self.output_size = configs.output_size # 输出的大小,即预测结果的维度。self.channel_sizes = [int(size) for size in configs.channel_sizes.split(',')] # 因为输入的是字符串,转成列表# 一个整数列表,指定每个隐藏层的单元数量。列表的长度表示隐藏层的层数,每个元素表示对应隐藏层的单元数量。self.time_step = configs.time_steplayers = []input_adjust_size = self.input_size * self.time_step # 将数据展开后的维度为 特征数量*时间步长# 遍历channel_sizes列表for i in range(len(self.channel_sizes)):if i == 0:# 对于第一层,创建一个从input_size到channel_sizes[i]的线性层self.linear = nn.Linear(input_adjust_size, self.channel_sizes[i])self.init_weights() # 初始化线性层的权重layers += [self.linear, nn.ReLU()] # 将线性层和ReLU激活函数添加到layers列表中else:# 对于后续层,创建一个从channel_sizes[i-1]到channel_sizes[i]的线性层self.linear = nn.Linear(self.channel_sizes[i - 1], self.channel_sizes[i])self.init_weights() # 初始化线性层的权重layers += [self.linear, nn.ReLU()] # 将线性层和ReLU激活函数添加到layers列表中# 创建最后一个线性层,从channel_sizes[-1]到output_sizeself.linear = nn.Linear(self.channel_sizes[-1], self.output_size)self.init_weights() # 初始化线性层的权重layers += [self.linear] # 将最后一个线性层添加到layers列表中# 使用layers列表创建一个Sequential网络self.network = nn.Sequential(*layers)def init_weights(self):# 使用均值为0,标准差为0.01的正态分布初始化线性层的权重self.linear.weight.data.normal_(0, 0.01)def forward(self, x):# X输入的shape为 [batch_size, time_step,n_features]# 将输入数据的维度展平,然后传递给线性层。# 无论输入数据的特征数和时间步数如何,都能适应到模型中。这个修改应该可以适用于不同维度的输入数据。x = x.view(x.size(0), -1)return self.network(x)RNN
import torch
import torch.nn as nn
from torch.autograd import Variable# RNN模型结构
class Model(nn.Module):def __init__(self, configs):super(Model, self).__init__()self.input_size = configs.input_size # 输入特征的大小self.hidden_size = configs.hidden_size # 隐藏状态的维度self.num_layers = configs.num_layers # RNN的层数self.output_size = configs.output_size # 输出的大小,即预测结果的维度self.dropout = configs.dropout # 在非循环层之间应用的丢弃比例,默认为0.0(没有丢弃)。self.bidirectional = configs.bidirectional # 如果为True,LSTM将是双向的(包括前向和后向),默认为False。# 定义RNN结构,输入特征大小、隐藏状态维度、层数等参数self.rnn = nn.RNN(input_size=self.input_size, hidden_size=self.hidden_size, dropout=self.dropout,bidirectional=self.bidirectional, num_layers=self.num_layers, batch_first=True)# 将RNN的输出压缩到与输出大小相同的维度self.fc = nn.Linear(self.hidden_size, self.output_size)def forward(self, x):# 创建初始隐藏状态h_0,维度为(num_layers, batch_size, hidden_size)h_0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size))# 通过RNN传播输入数据,获取输出out和最终隐藏状态h_0out, h_0 = self.rnn(x, h_0)# 取RNN最后一个时间步的输出,将其输入到全连接层进行预测out = self.fc(out[:, -1, :])return outTCN
import torch.nn as nn
from torch.nn.utils import weight_norm# TCN模型结构
'''
Chomp1d模块:用于从卷积层的输出中移除无效的时间步。
'''class Chomp1d(nn.Module):def __init__(self, chomp_size):super(Chomp1d, self).__init__()self.chomp_size = chomp_sizedef forward(self, x):# Chomp1d模块的作用是从卷积层的输出中移除无效的时间步,即通过切片操作去掉最后的self.chomp_size个时间步。# 由于切片操作可能导致存储不连续,因此在返回结果之前,需要使用contiguous()方法确保存储连续性。return x[:, :, :-self.chomp_size].contiguous()'''
TemporalBlock模块:包含两个卷积层和相应的正则化、激活函数和dropout操作。
第一个卷积层使用权重归一化,通过Chomp1d组件移除无效的时间步,然后经过ReLU激活函数和dropout操作。
第二个卷积层也经过相同的处理流程。通过残差连接将第二个卷积层的输出和输入进行相加,并通过ReLU激活函数得到最终的输出。
'''class TemporalBlock(nn.Module):def __init__(self, n_inputs, n_outputs, kernel_size, stride, dilation, padding, dropout=0.2):super(TemporalBlock, self).__init__()# 第一次卷积self.conv1 = weight_norm(nn.Conv1d(n_inputs, 3096, kernel_size,stride=stride, padding=padding, dilation=dilation))self.chomp1 = Chomp1d(padding)self.relu1 = nn.ReLU()# 随机失活(dropout)。随机失活是一种常用的正则化技术,用于减少过拟合self.dropout1 = nn.Dropout(dropout)# 第二次卷积self.conv2 = weight_norm(nn.Conv1d(3096, n_outputs, kernel_size,stride=stride, padding=padding, dilation=dilation))self.chomp2 = Chomp1d(padding)self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(dropout)# 将两次卷积层按顺序组合成一个网络self.net = nn.Sequential(self.conv1, self.chomp1, self.relu1, self.dropout1,self.conv2, self.chomp2, self.relu2, self.dropout2,)# 如果输入通道数和输出通道数不相同,则需要进行下采样self.downsample = nn.Conv1d(n_inputs, n_outputs, 1) if n_inputs != n_outputs else Noneself.relu = nn.ReLU()# 初始化权重self.init_weights()def init_weights(self):# 使用均值为0,标准差为0.01的正态分布初始化权重self.conv1.weight.data.normal_(0, 0.01)self.conv2.weight.data.normal_(0, 0.01)if self.downsample is not None:self.downsample.weight.data.normal_(0, 0.01)def forward(self, x):# 前向传播out = self.net(x) # 通过两个卷积层res = x if self.downsample is None else self.downsample(x) # 下采样return self.relu(out + res) # 残差连接# 残差连接(Residual connection)是一种在神经网络中引入跨层连接的技术。它的目的是解决深层神经网络训练中的梯度消失或梯度爆炸问题,并促进信息在网络中的流动。# 在TCN模型中,残差连接被用于将每个TemporalBlock的输出与输入进行相加。这种设计使得信息可以直接通过跨层连接流动,有助于梯度的传播和模型的训练。# 具体地,在TemporalBlock的forward方法中,首先通过两个卷积层进行特征提取和建模,然后将第二个卷积层的输出和输入进行相加。这个相加的操作实现了残差连接。最终,通过ReLU激活函数对相加的结果进行非线性变换。# 残差连接的好处是,即使在网络较深的情况下,梯度可以通过跨层连接直接传播到前面的层次,减少了梯度消失的问题。同时,它也提供了一种捕捉输入与输出之间的细微差异和变化的机制,有助于提高模型的性能。'''
TemporalConvNet模块是 TCN 模型的核心,由多个TemporalBlock组成的网络层次结构。
根据num_channels列表的长度,确定网络层次的深度。
每个层次上的TemporalBlock的参数根据当前层次的位置和前一层的输出通道数进行确定。
通过层次化的结构,模型可以捕捉序列中的长期依赖关系。
'''class TemporalConvNet(nn.Module):def __init__(self, num_inputs, num_channels, kernel_size=2, dropout=0.2):super(TemporalConvNet, self).__init__()layers = []self.relu = nn.ReLU()num_levels = len(num_channels)for i in range(num_levels):dilation_size = 2 ** iin_channels = num_inputs if i == 0 else num_channels[i - 1]out_channels = num_channels[i]# 每个层次添加一个TemporalBlocklayers += [TemporalBlock(in_channels, out_channels, kernel_size, stride=1, dilation=dilation_size,padding=(kernel_size - 1) * dilation_size, dropout=dropout)]# 将所有的TemporalBlock按顺序组合成一个网络self.network = nn.Sequential(*layers)def forward(self, x):return self.relu(self.network(x) + x[:, 0, :].unsqueeze(1))'''
TCN模块:TCN模型的主体部分。
它包括一个TemporalConvNet,一个线性层和一个下采样层。
输入数据首先经过TemporalConvNet进行序列建模和特征提取,然后通过ReLU激活函数和残差连接进行处理。
最后,通过线性层进行预测,并通过下采样层将输入数据的通道数降低到与TemporalBlock的输出通道数相同,以便在残差连接中使用。
'''class Model(nn.Module):def __init__(self,configs): # input_size 输入的不同的时间序列数目super(Model, self).__init__()self.input_size = configs.input_size # 输入特征的大小self.output_size = configs.output_size # 预测结果的维度self.num_channels = [configs.nhid] * configs.levels # 卷积层通道数的列表,用于定义TemporalConvNet的深度self.kernel_size = configs.kernel_size # 卷积核的大小self.dropout = configs.dropout # 随机丢弃率# TemporalConvNet层self.tcn = TemporalConvNet(self.input_size, self.num_channels, kernel_size=self.kernel_size, dropout=self.dropout)# 线性层,用于预测self.linear = nn.Linear(self.num_channels[-1], self.output_size)# 下采样层,用于通道数降低self.downsample = nn.Conv1d(self.input_size, self.num_channels[0], 1)self.relu = nn.ReLU()# 初始化权重self.init_weights()def init_weights(self):self.linear.weight.data.normal_(0, 0.01)self.downsample.weight.data.normal_(0, 0.01)def forward(self, x):# 前向传播x = x.transpose(1, 2)# 通过TemporalConvNet进行序列建模和特征提取y1 = self.relu(self.tcn(x) + x[:, 0, :].unsqueeze(1))# 线性层进行预测return self.linear(y1[:, :, -1])Transformer
import torch
import torch.nn as nnfrom Models.layers.Transformer.decoder import Decoder
from Models.layers.Transformer.encoder import Encoder
from Models.layers.Transformer.utils import generate_original_PE, generate_regular_PEclass Model(nn.Module):"""基于Attention is All You Need的Transformer模型。适用于顺序数据的经典Transformer模型。嵌入(Embedding)已被替换为全连接层,最后一层softmax函数替换为sigmoid函数。属性----------layers_encoding: :py:class:`list` of :class:`Encoder.Encoder`编码器层的堆叠。layers_decoding: :py:class:`list` of :class:`Decoder.Decoder`解码器层的堆叠。参数----------d_input:模型输入的维度。d_model:输入向量的维度。d_output:模型输出的维度。q:查询和键的维度。v:值的维度。h:头数。N:要堆叠的编码器和解码器层数量。attention_size:应用注意力机制的反向元素数量。如果为 ``None``,则不激活。默认为 ``None``。dropout:每个多头自注意力(MHA)或前馈全连接(PFF)块之后的dropout概率。默认为 ``0.3``。chunk_mode:切块模式,可以是 ``'chunk'``、``'window'`` 或 ``None`` 之一。默认为 ``'chunk'``。pe:要添加的位置编码类型,可以是 ``'original'``、``'regular'`` 或 ``None`` 之一。默认为 ``None``。pe_period:如果使用 ``'regular'`` 位置编码,则可以定义周期。默认为 ``None``。"""def __init__(self, configs):"""根据Encoder和Decoder块创建Transformer结构。"""super(Model, self).__init__()d_input = configs.d_inputd_model = configs.d_modeld_output = configs.d_outputq = configs.qv = configs.vh = configs.hN = configs.Nattention_size = configs.attention_sizedropout = configs.dropoutchunk_mode = configs.chunk_modepe = configs.pepe_period = configs.pe_periodself._d_model = d_modelself.layers_encoding = nn.ModuleList([Encoder(d_model,q,v,h,attention_size=attention_size,dropout=dropout,chunk_mode=chunk_mode) for _ in range(N)])self.layers_decoding = nn.ModuleList([Decoder(d_model,q,v,h,attention_size=attention_size,dropout=dropout,chunk_mode=chunk_mode) for _ in range(N)])self._embedding = nn.Linear(d_input, d_model)self._linear = nn.Linear(d_model, d_output)pe_functions = {'original': generate_original_PE,'regular': generate_regular_PE,}if pe in pe_functions.keys():self._generate_PE = pe_functions[pe]self._pe_period = pe_periodelif pe is None:self._generate_PE = Noneelse:raise NameError(f'未知的位置编码(PE)"{pe}"。必须为 {", ".join(pe_functions.keys())} 或 None。')self.name = 'transformer'def forward(self, x: torch.Tensor) -> torch.Tensor:"""通过Transformer进行输入传播。通过嵌入模块、编码器和解码器堆叠以及输出模块进行输入传播。参数----------x:形状为 (batch_size, K, d_input) 的 torch.Tensor。返回-------形状为 (batch_size, K, d_output) 的输出张量。"""K = x.shape[1]# 嵌入模块encoding = self._embedding(x)# 添加位置编码if self._generate_PE is not None:pe_params = {'period': self._pe_period} if self._pe_period else {}positional_encoding = self._generate_PE(K, self._d_model, **pe_params)positional_encoding = positional_encoding.to(encoding.device)encoding.add_(positional_encoding)# 编码器堆叠for layer in self.layers_encoding:encoding = layer(encoding)# 解码器堆叠decoding = encoding# 添加位置编码if self._generate_PE is not None:positional_encoding = self._generate_PE(K, self._d_model)positional_encoding = positional_encoding.to(decoding.device)decoding.add_(positional_encoding)for layer in self.layers_decoding:decoding = layer(decoding, encoding)# 输出模块output = self._linear(decoding)output = torch.sigmoid(output)return output[:, -1, :]Seq2Seq
import torch
import torch.nn as nn# Seq2Seq 主类
class Model(nn.Module):def __init__(self,configs ):super().__init__()self.input_size = configs.input_size # 输入特征的大小self.output_size = configs.output_size # 输出的大小(预测结果的维度)self.Encoder = Encoder(configs.input_size, configs.hidden_size, configs.num_layers, configs.batch_size)self.Decoder = Decoder(configs.input_size, configs.hidden_size, configs.num_layers, configs.output_size, configs.batch_size)def forward(self, input_seq):target_len = self.output_size # 预测步长batch_size, seq_len, _ = input_seq.shape[0], input_seq.shape[1], input_seq.shape[2]h, c = self.Encoder(input_seq)outputs = torch.zeros(batch_size, self.input_size, self.output_size)decoder_input = input_seq[:, -1, :] # 获取解码器的初始输入for t in range(target_len):decoder_output, h, c = self.Decoder(decoder_input, h, c) # 解码器的前向传播outputs[:, :, t] = decoder_outputdecoder_input = decoder_output # 将解码器的输出作为下一个时间步的输入return outputs[:, 0, :] # 返回预测输出class Encoder(nn.Module):def __init__(self, input_size, hidden_size, num_layers, batch_size):super().__init__()self.input_size = input_size # 输入特征的大小self.hidden_size = hidden_size # LSTM 隐藏状态的维度self.num_layers = num_layers # LSTM 层的堆叠层数self.num_directions = 1self.batch_size = batch_size# 定义编码器的LSTM层,接受输入序列self.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True, bidirectional=False)def forward(self, input_seq):batch_size, seq_len = input_seq.shape[0], input_seq.shape[1]h_0 = torch.randn(self.num_directions * self.num_layers, batch_size, self.hidden_size) # 初始化 LSTM 的隐藏状态c_0 = torch.randn(self.num_directions * self.num_layers, batch_size, self.hidden_size) # 初始化 LSTM 的记忆状态output, (h, c) = self.lstm(input_seq, (h_0, c_0)) # 前向传播过程,返回 LSTM 层的输出序列和最后一个时间步的隐藏状态return h, cclass Decoder(nn.Module):def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size, *args, **kwargs):super().__init__(*args, **kwargs)self.input_size = input_size # 输入特征的大小self.hidden_size = hidden_size # LSTM 隐藏状态的维度self.num_layers = num_layers # LSTM 层的堆叠层数self.output_size = output_size # 输出的大小(预测结果的维度)self.num_directions = 1self.batch_size = batch_size# 定义解码器的LSTM层和线性层self.lstm = nn.LSTM(input_size, self.hidden_size, self.num_layers, batch_first=True, bidirectional=False)self.linear = nn.Linear(self.hidden_size, self.input_size) # 线性层,将 LSTM 输出映射到预测结果的维度def forward(self, input_seq, h, c):# input_seq(batch_size, input_size)input_seq = input_seq.unsqueeze(1) # 在输入序列中添加一个时间步的维度output, (h, c) = self.lstm(input_seq, (h, c)) # 前向传播过程,返回 LSTM 层的输出序列和最后一个时间步的隐藏状态pred = self.linear(output.squeeze(1)) # 使用线性层进行预测,pred(batch_size, 1, output_size)return pred, h, c