这篇博客是之前文章:
- Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (一)
- Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (二)
-
Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (三)
的续篇。在这篇文章中,我们将学习如何把从 Elasticsearch 搜索到的结果传递到大数据模型以得到更好的结果。

如果你还没有创建好自己的环境,请参考第一篇文章进行详细地安装。
创建应用并展示
安装包
#!pip3 install langchain导入包
from dotenv import load_dotenv
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import ElasticsearchStore
from langchain.text_splitter import CharacterTextSplitter
from langchain.prompts import ChatPromptTemplate
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.runnable import RunnableLambda
from langchain.schema import HumanMessage
from urllib.request import urlopen
import os, jsonload_dotenv()openai_api_key=os.getenv('OPENAI_API_KEY')
elastic_user=os.getenv('ES_USER')
elastic_password=os.getenv('ES_PASSWORD')
elastic_endpoint=os.getenv("ES_ENDPOINT")
elastic_index_name='langchain-rag'添加文档并将文档分成段落
with open('workplace-docs.json') as f:workplace_docs = json.load(f)print(f"Successfully loaded {len(workplace_docs)} documents")
metadata = []
content = []for doc in workplace_docs:content.append(doc["content"])metadata.append({"name": doc["name"],"summary": doc["summary"],"rolePermissions":doc["rolePermissions"]})text_splitter = CharacterTextSplitter(chunk_size=50, chunk_overlap=0)
docs = text_splitter.create_documents(content, metadatas=metadata)
Index Documents using ELSER - SparseVectorRetrievalStrategy()
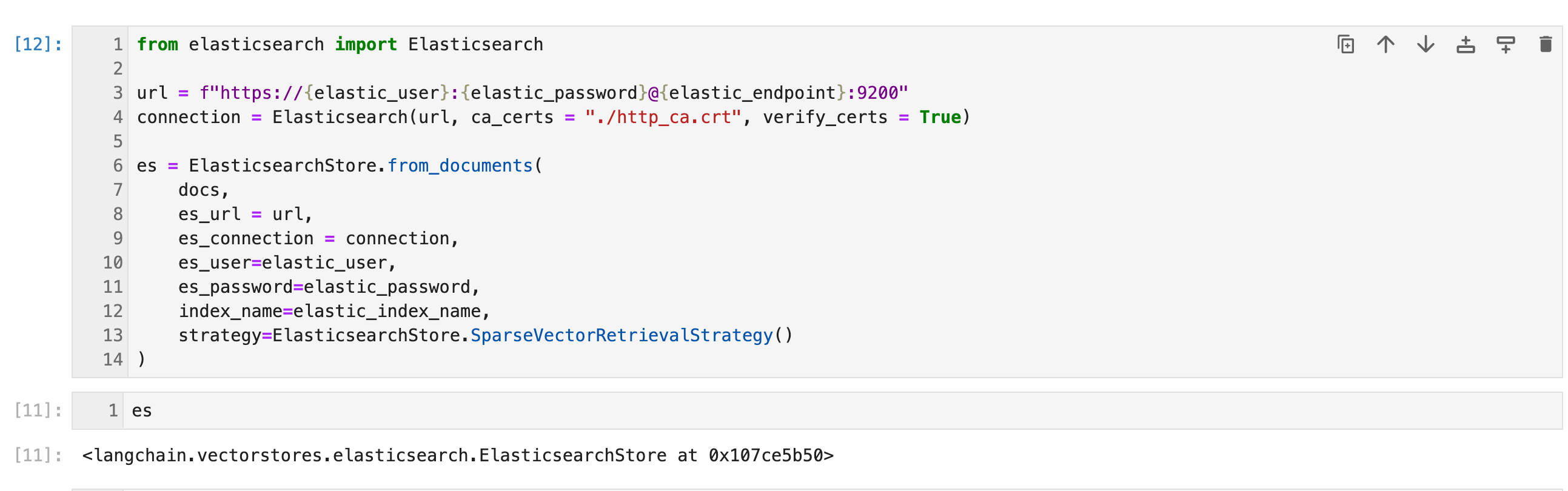
from elasticsearch import Elasticsearchurl = f"https://{elastic_user}:{elastic_password}@{elastic_endpoint}:9200"
connection = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)es = ElasticsearchStore.from_documents(docs,es_url = url,es_connection = connection,es_user=elastic_user,es_password=elastic_password,index_name=elastic_index_name,strategy=ElasticsearchStore.SparseVectorRetrievalStrategy()
)
如果你还没有配置好自己的 ELSER,请参考之前的文章 “ Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (三)”。
在执行完上面的命令后,我们可以在 Kibana 中进行查看:
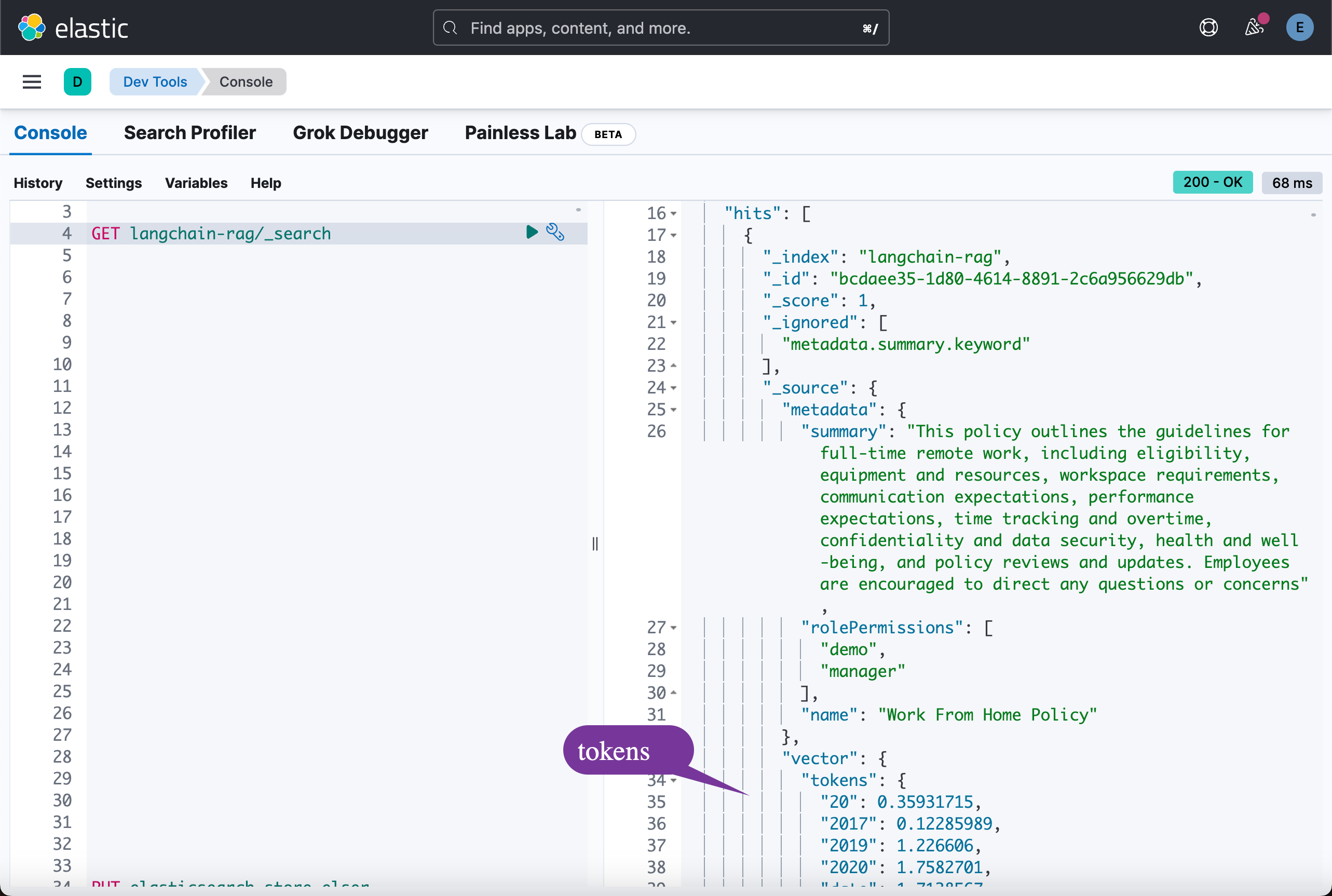
展示结果
def showResults(output):print("Total results: ", len(output))for index in range(len(output)):print(output[index])Search
r = es.similarity_search("work from home policy")
showResults(r)
RAG with Elasticsearch - Method 1 (Using Retriever)
retriever = es.as_retriever(search_kwargs={"k": 4})template = """Answer the question based only on the following context:
{context}Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)chain = ({"context": retriever, "question": RunnablePassthrough()} | prompt | ChatOpenAI() | StrOutputParser()
)chain.invoke("vacation policy")
RAG with Elasticsearch - Method 2 (Without Retriever)
Add Context
def add_context(question: str):r = es.similarity_search(question)context = "\n".join(x.page_content for x in r)return contextChain
template = """Answer the question based only on the following context:
{context}Question: {question}
"""prompt = ChatPromptTemplate.from_template(template)chain = ({"context": RunnableLambda(add_context), "question": RunnablePassthrough()}| prompt| ChatOpenAI()| StrOutputParser()
)chain.invoke("canada employees guidelines")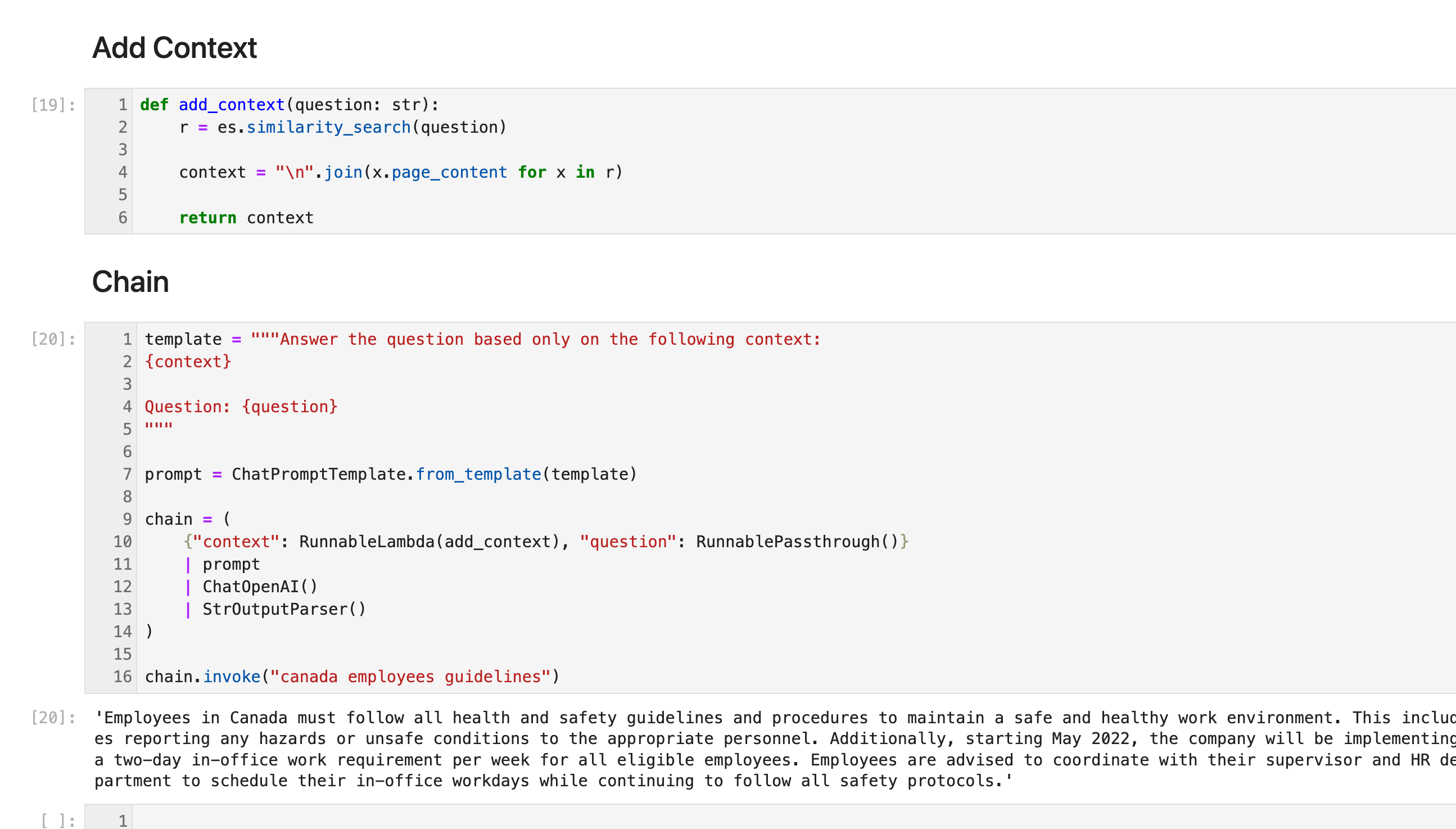
Compare with RAG and without RAG
q = input("Ask Question: ")## Question to OpenAIchat = ChatOpenAI()messages = [HumanMessage(content=q)
]gpt_res = chat(messages)# Question with RAGgpt_rag_res = chain.invoke(q)# Responsess = f"""
ChatGPT Response:{gpt_res}ChatGPT with RAG Response:{gpt_rag_res}
"""print(s)

上面的 jupyter notebook 的代码可以在地址 https://github.com/liu-xiao-guo/semantic_search_es/blob/main/RAG-langchain-elasticsearch.ipynb 下载。