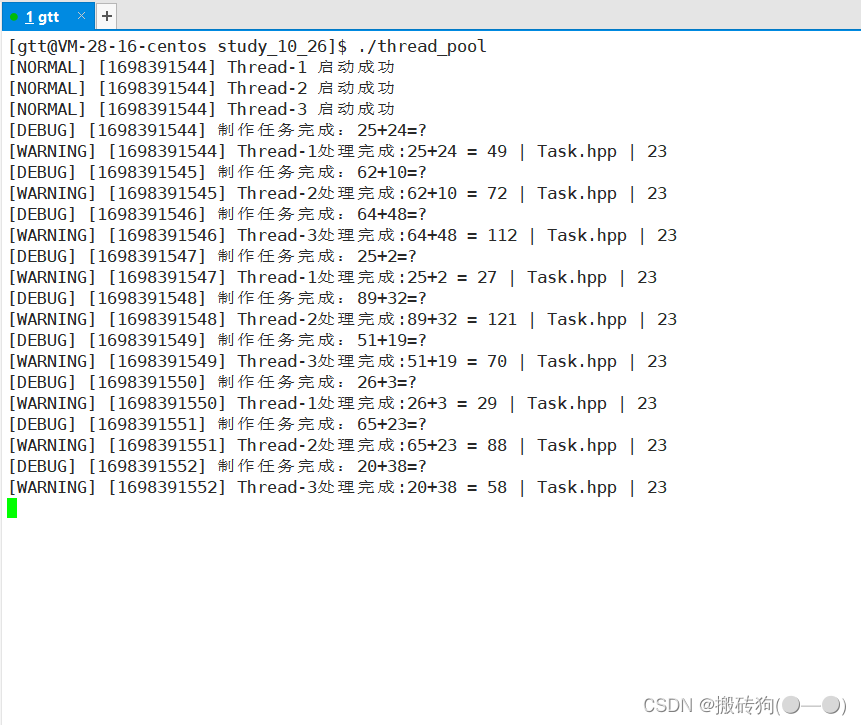
本文记录大模型幻觉问题的相关内容。
参考:Mitigating LLM Hallucinations: a multifaceted approach
地址:https://amatriain.net/blog/hallucinations
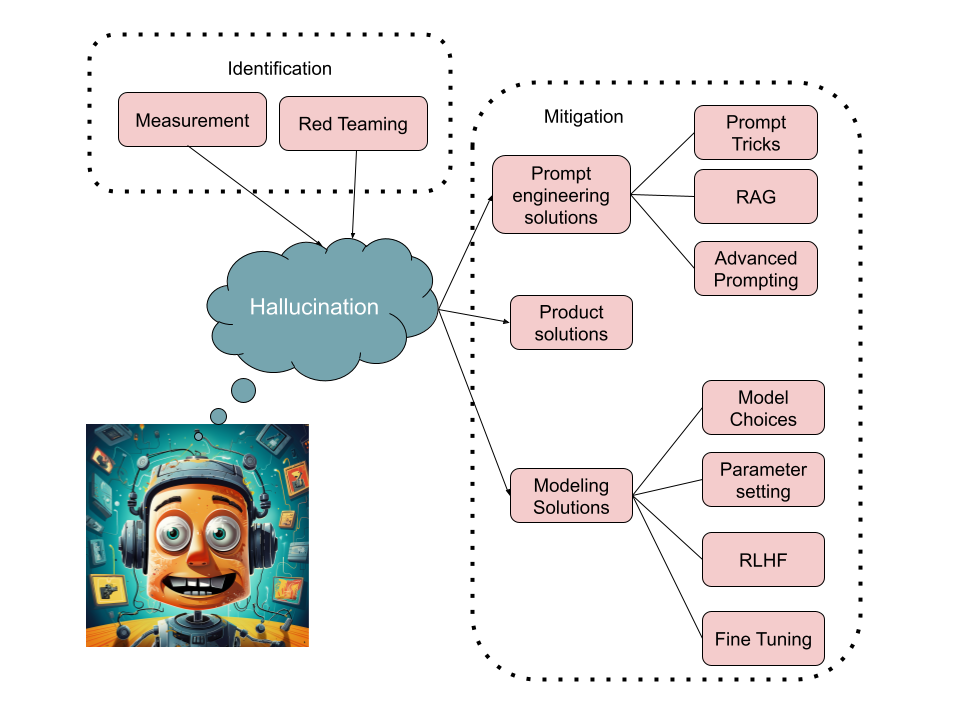
(图:解决大模型幻觉的不同方式)
什么是幻觉?
幻觉(Hallucination)指生成内容与源数据不一致或无意义,可分为内生幻觉和外在幻觉(参考Paper:Survey of Hallucination in Natural Language Generation)。
- 内在幻觉:生成内容与源数据相矛盾,引入了事实错误或逻辑不一致的情况。
- 外在幻觉:生成内容与源数据没有矛盾,但也并不能根据源数据进行验证,添加了可能被视为推测性或无法证实的元素。
为什么产生幻觉?
LLM通过预训练来预测下一个token,没有正确/错误的概念,仅仅是基于概率来生成文本。虽然这导致了一些意外的推理能力,但这仅仅是这种基于概率的逐标记推理的结果。指令微调和RLHF确实能让模型更偏向事实,但并没有改变LLM的机制及缺陷。
LLM已经在整个互联网、图书、问答和百科等许多数据集上进行了训练。它们在训练集中有正确和错误的知识。模型回答偏向于它们见过最多的内容。比如提问一个医学问题,而且问法跟某个帖子差不多,那可能就会得到跟训练集里那个帖子大致一样的答案。
在一篇最近的题为 Sources of Hallucination by Large Language Models on Inference Tasks 的论文中,作者展示了LLM训练数据集的两个方面导致了幻觉的产生:真实性先验(veracity prior)和相对频率启发式(relative frequency heuristic)。
如何评测是否有幻觉?
幻觉评测的五个步骤
- 准备基准数据:也就是给出大模型生成的参考答案;
- 准备测试集:包括随机通用测试集 + 对抗性攻击样本;
- 提取断言:可以用手动、规则、机器学习等方式;
- 验证:确保大模型生成的东西跟基准数据对齐;
- 评价指标:可以用基准错误率(Grounding Defect Rate)评估,即跟基准答案不一致的数量除以测试集总数量。
幻觉的常用度量标准和方法
包括统计学方法、基于模型的方法、基于规则的方法、人类评价、。
- 统计学方法:ROUGE、BLUE 计算文本相似性;PARENT、PARENT-T、Knowledge F1 评测结构化数据。局限性:主要关注内在幻觉,无法捕捉句法和语义的细微差异。
- 基于模型的方法:用IE模型抽“主体-关系-对象” 然后做验证。
- QA-based Metrics:认为对于同一个问题,如果上下文与训练数据一致,就会生成类似答案。因此计算生成内容和训练集的一致性。(参见:Evaluating Factual Consistency in Knowledge-Grounded Dialogues via Question Generation and Question Answering)
- NLI-based Metrics:用自然语言推理(NLI)数据集训模型,计算生成的“假设”在给定的“前提”下是真、假、不确定。(参见:Evaluating Groundedness in Dialogue Systems: The BEGIN Benchmark)
- Faithfulness Classification Metrics:用针对特定任务的数据集训个忠诚度分类的模型,来改进NLI模型的性能。(参见:Rome was built in 1776: A Case Study on Factual Correctness in Knowledge-Grounded Response Generation)
- 人工评价方法:一是对幻觉程度打分;二是对比生成答案和参考答案哪个好。(人工评价很重要,但同时也要找红队攻击模型,参考:“Red Teaming Language Models with Language Models”)
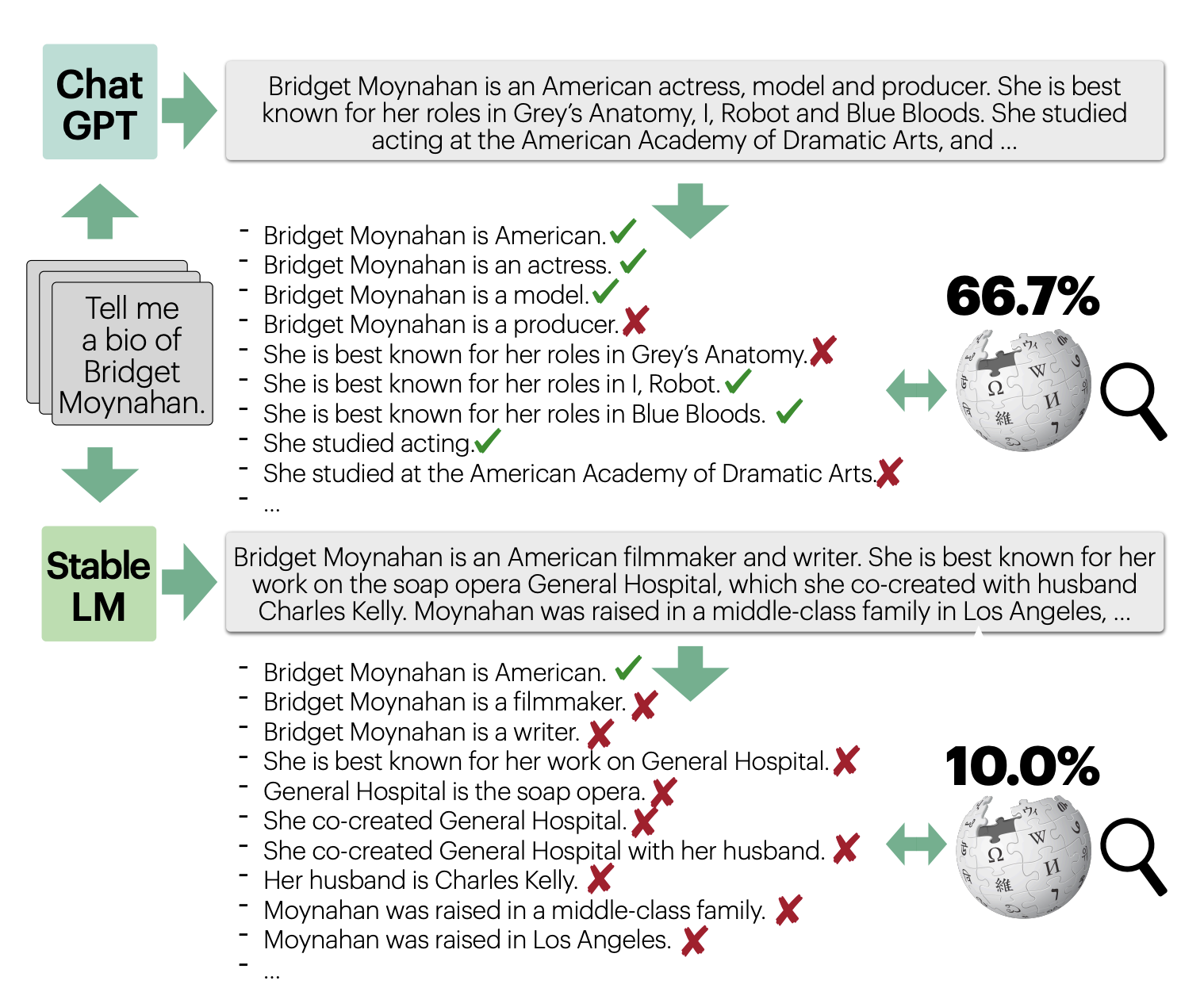
- FActScore:可用于人工+模型的评估。该指标将LLM生成结果分解为“原子事实(atomic facts)”。最终得分是每个原子事实准确性的总和,每个原子事实都被赋予相等的权重。准确性是一个二进制数字,简单地表示原子事实是否由来源支持。作者实施了不同的自动化策略,利用LLM来估计这个指标。
如何缓解大模型幻觉?
本节探讨各种幻觉缓解策略。
产品侧
产品设计的时候去避免大模型生成幻觉内容,比如在生成书面内容时关注观点类文章,而不是事实类文章,有助于降低幻觉。
- 用户编辑:让用户编辑大模型生成的内容
- 用户责任:告诉用户对生成内容负责
- 引文参考:给用户展示引用的内容
- 可选模式:比如精准模式(以计算成本为代价)等
- 用户反馈:收集用户反馈(赞踩)用于迭代模型
- 限制输出和轮数:更长更复杂的输出更容易幻觉
- 结构化输入输出:预置一些结构化模版
数据侧
维护一个动态数据库专门记录各种幻觉,用于回归测试。而且要注意数据隐私安全。
模型侧
- 换模型:更大参数量的模型更不容易幻觉
- 调参数:temperature越小,模型更加接近高概率的token,越不容易幻觉
- RLHF:能降低尤其是领域微调过的模型的幻觉
- 指令微调:针对需求的任务数据做微调
Prompt Engineering
通过 Meta prompt 引导大模型 “不该做什么” 有助于降低幻觉。
控制幻觉的一般思路
- 简化复杂任务,将任务分解并描述清楚
- 内置一些 meta prompt,比如“不要捏造事实”等话术
- Few-Shot Learning,添加几个例子
- 对模型生成结果进行后处理
调整 MetaPrompts
- 强调的语气:把需要强调的内容全大写或者突出强调
- 更多上下文:提供更多背景知识
- 细化输出:重新评估初始输出结果并调整
- 引用:让模型证实自己的观点
- 转化任务:让模型做摘要总结而不是做问答
- 选择性处理任务:有些任务必须强依赖事实回答
- 反复强调关键点:prompt的最后多强调几遍关键点
- 回顾输入内容:要求模型回顾重要的输入细节
- 使用算法过滤:筛选和优先考虑相关的信息
思维链(Chain of Thought)
思维链由 “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models” 提出,因为LLM用来预测下一个token的概率而不是推理,所以指定模型生成推理步骤可以让模型更接近推理。

RAG:检索增强的生成(Retrieval-Augmented Generation)
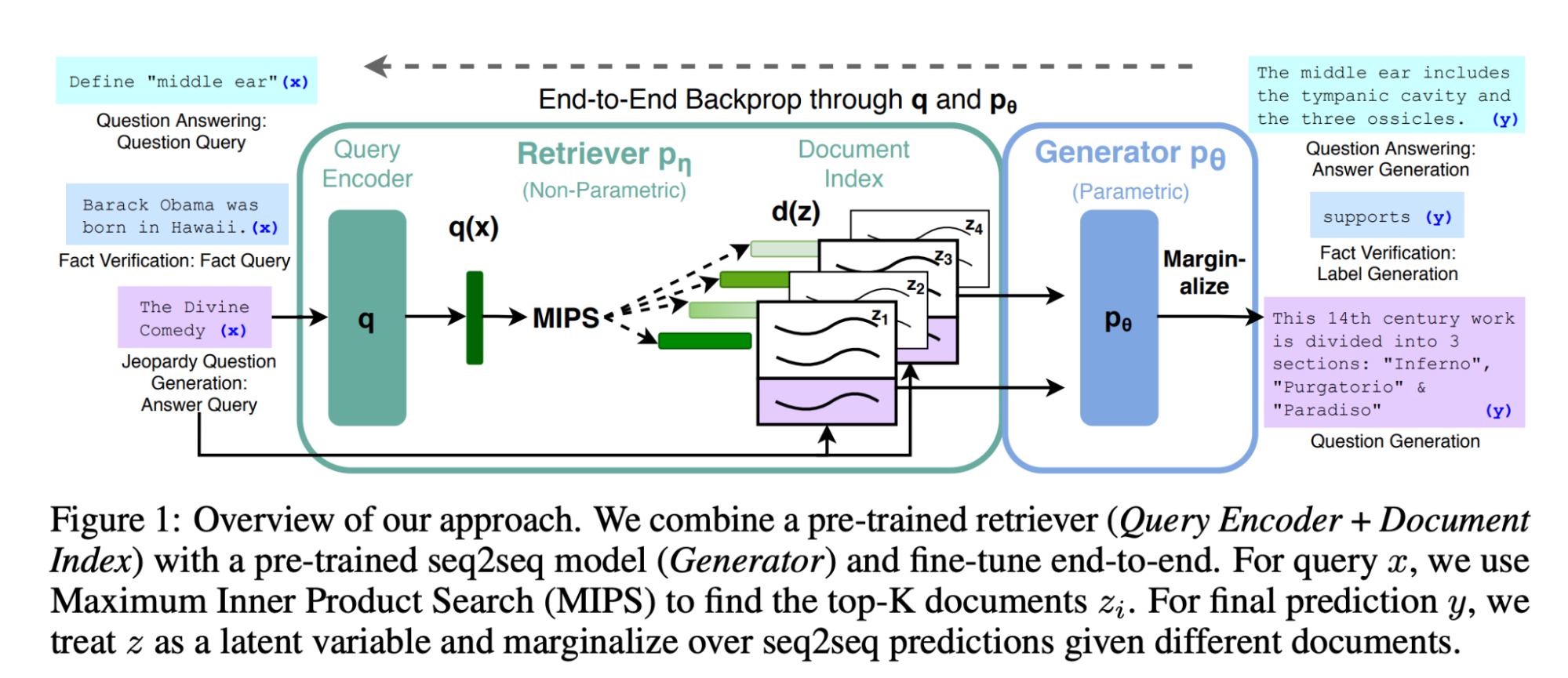
先检索,后生成。但RAG会过度依赖空或错误的检索结果导致幻觉,因此注意事项:
- 空结果:对于空结果可以回复 “很抱歉,我们没有关于此主题的足够信息。你能换个说法吗?” 或者重新检索;
- 模棱两可的结果:比如问“李华是谁” 这种可能有多重结果的问题时,可以引导用户进一步描述想问干嘛的李华;
- 错误结果:作为外部知识模型很难鉴别,需要提高检索组件的准确性。
高级 Prompt Engineering 方法
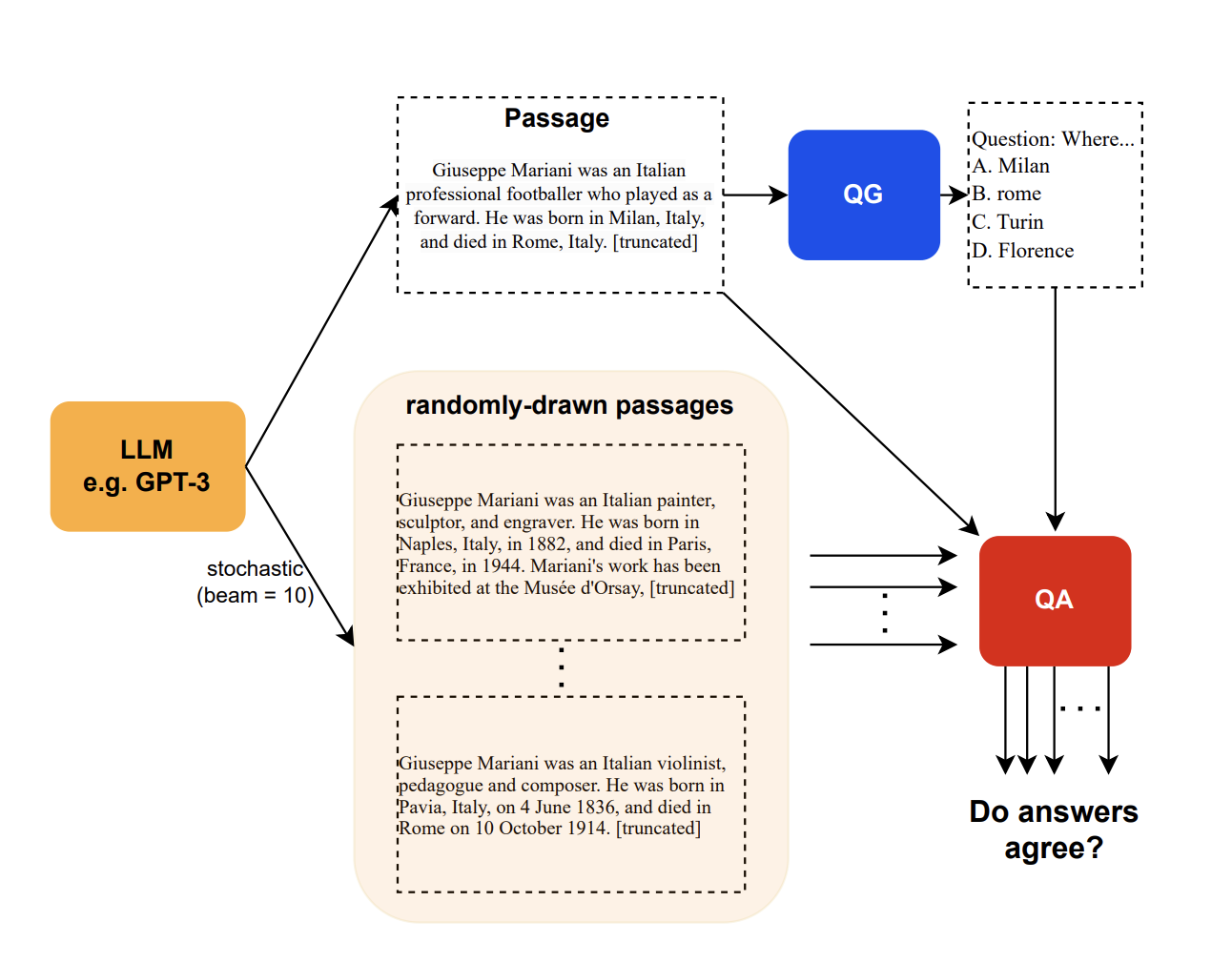
- Self-consistency:来自论文 “SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models”,思想是让模型针对同一 prompt 生成多个回答,然后用大模型本身去判断这些回答是否一致,或者结合 BERT-Score、N-gram 等计算。
- Reason and act (ReAct):Google 在 “ReAct: Synergizing Reasoning and Acting in Language Models” 提出的用于缓解 CoT 幻觉的方法,一步步生成 Thought 和 Action,有点像 Agent。

- Reflection(反思):直接问大模型对之前回答的内容是否笃定。还可以把反思过程作为长期记忆存起来强化反思过程。
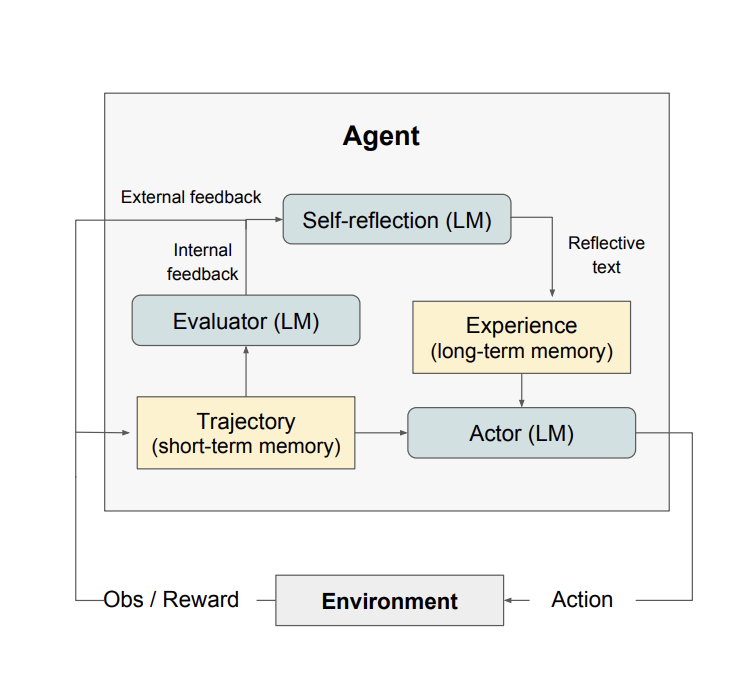
- Dialog-Enabled Resolving Agents (DERA):Decider生成答案,让Researcher跟Decider这个Agent一起讨论这个答案,然后让Decider根据他俩的讨论结果调整答案。

- Chain-of-Verification (COVE):Meta最近提出的利用LLM生成多个回复并进行自我验证的变体。如下图所示,模型首先(i)起草一个初始回复;然后(ii)生成验证问题;(iii)独立回答这些验证问题,以避免答案受到其他回复的影响;(iv)生成最终经过验证的回复。

总结
减轻幻觉需要多种手段综合应用,但完全消除难度非常大。Yann Lecun 认为,如果不完全重新设计底层模型,就无法解决这个问题(然而 OpenAI 首席科学家 Ilya Sutskever 并不同意)
参考资料:
[1] Mitigating LLM Hallucinations: a multifaceted approach:本文主体内容。
[2] 如何解决LLM大语言模型的幻觉问题?- 知乎:收集模型回答错误的问题,然后训模型的拒答能力。
[3] 大模型幻觉评估方法——忠实性(Faithfulness)与事实性(Factuality)