面向过程和面向对象的区别
面向过程:在解决问题时,特别自定义函数编写一步一步的步骤解决问题。
面向对象:其特点就是 继承,多态,继承,在解决问题时,不再注重函数的编写,而在于注重函数间的调用,主要是描述解决问题时的各个行为,所以易维护,易扩展,易复用,减少代码的耦合度。
八种基础类型和其对应的包装类

类不同于基础类型所有的对象类型都是引用类型,所以在使用是需要为其初始化,如果不进行初始化,Java会主动识别并报错。 
在基础类型创建时,系统会给基础空间,在基础类型相互复制时就当当的将空间中的数据进行复制。而对象在创建时系统只会分配引用空间,所以在对象的相互复制时本质就是在复制引用地址,此时其中一个对象中属性发生改变时另一个对象的属性也会发生改变。(数组也是引用对象,所以其效果也是一样的)
boolean类型在java虚拟机中没有自己的类型指令,在Java虚拟机中使用int来表示boolean。
instanceof关键字的使用
其作用就是:判断某个对象是否是某个类的实例对象。
代码格式:
boolean result I instanceof object其中i不能为基础类型必须为引用类型 ,如果是基础类型则会报错。
如果当前i为null时,则instanceof的结果永远为false。
java自动装箱和拆箱
在Java5之前是不支持自动装箱的,其代码格式为下:
Integer integer = new Integer(number);
在java5之后,的编写格式为下:
Integer integer = number装箱使用Integer.value(),拆箱使用Integer.intValue()。
特殊情况1
public class Main {public static void main(String[] args) {//Integer的valueOf方法//valueOf(100)时Integer i1 = 100;Integer i2 = 100;System.out.println("valueOf(100)时:" + (i1 == i2));//valueOf(200)时Integer i3 = 200;Integer i4 = 200;System.out.println("valueOf(200)时:" + (i3 == i4));//valueOf(-127)时Integer i5 = -127;Integer i6 = -127;System.out.println("valueOf(-127)时:" + (i5 == i6));//valueOf(-200)时Integer i7 = -200;Integer i8 = -200;System.out.println("valueOf(-200)时:" + (i7 == i8));Integer.valueOf()}
}结果为下:

在valueOf方法的设计就是:当i的值是[-128, 127]区间的整数时,会在返回在IntegerCache.cache数组中对应的数值的Integer(存在缓存数组)。而当i不在区间时,则会直接返回一个新的Integer。

特殊情况2
public class Main {public static void main(String[] args) {Double i1 = 100.0;Double i2 = 100.0;System.out.println("i1==i2" + (i1 == i2));Double i3 = 200.0;Double i4 = 200.0;System.out.println("i3==i4" + (i3 == i4));}
}结果为下:
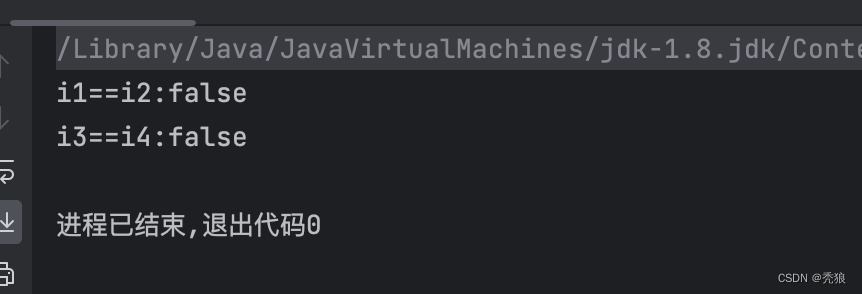
因为在浮点数在某个区间的个数是无限的,所以在Double.value方法的设计就是直接返回一个新的Double。
重载和重写的区别
重写总结:
1.发生在父子类之间,两个方法的返回类型和名字必须相同
2.重写后的方法的作用域必须到于被重写方法的作用域。
3.重写后的方法不能抛出新的异常。
重载总结:
1.俩个方法的名字必须相同,一般存在于同一个类中。
2.两个方法的返回类型可以不同。
3.重载是一种多态的表现,不能通过返回类型来判断俩个方法是否为重载方法。
equal和==的区别
==:比较的是判断符两边的对象的地址是否相同,判断两个对象是否是同一个对象。
如果两边变量的值为阿拉伯数字时,结果就是true(int a=10 double b = 10d , a==b result =true)
因为两者的都指向的是 阿拉伯数字的栈。
equal:判断的是两个数的值是否相同,因为所有的对象的父类是Object,所以在没有对equal方法重写时,对象的equal就是Object中的equal,而Object的equal方法的返回值就是 ==的返回值。
在使用equal时,如果存在常量的比较时,我们通常会将常数写在前面(const.equal(object)),如果将object放在前面,可能会出现空指针异常,因为object可能是null。
hashCode的作用
它根据对象的地址换算出hashCode。(该值用于定位数据存放的物理位置)
在set结合的插入时,我们需要保证插入不从复的数据,而使用循环equal判断的话,在数据量庞大时,效率非常低。
所以通过对插入数据使用hashCode方法,一下子就能定位到该数据该存放的物理位置,如果在该物理位置上没有数据则就直接插入。如果存在数据则使用equal方法进行判断一下,如果值相同则就结束插入,如果值不同则就散列储存到其他地址上。
String,StringBuilder,StringBuffer的区别
String是只读字符串,本质上就是一个不可变的char数组。
private final char value[];在我们对String进行修改时,本质上就是new 一个和原字符串值相同的StringBuilder通过append等方法对字符串进行拼接。
StringBuilder和StringBuffer都继承了abstractStringBuilder类
在abstractStringBuilder本质就是char数组。
/**
* The value is used for character storage.
*/
char[] value;StringBuilder和StringBuffer本质都是可变char数组,通常使用两者对字符串进行修改,而在StringBuffer在方法中添加了同步锁所以是线程安全的,StringBuilder没有对方法添加同步锁,所以是非线程安全的。
ArrayList和LinkedList的区别
ArrayList
优点:ArrayList本质上就是一个可以扩容的数组。它是基于动态数组的数据结构,它存储的数据的地址是连续的,所以查询的效率比较高。
缺点:因为地址是连续的,所以在数据的插入和删除的效率上比较低,因为可能删除和插入会涉及到大量的数据移动。
LinkedList
优点:ListedList本质就是一个双向链表。LinkedList是基于链表结构的数据结构,其数据的地址不是连续的,在开辟内存空间的时候无需连续,所以在对于数据的修改和插入的效率比较高的。
缺点:因为其是List结构,需要通过遍历指针域来确定查询数据的位置,所以在查询效率上比较低。
在一般情况下:
1.ArrayList在数据的查找上效率更高,因为只需要通过索引查询对应的数据,而LinkedList需要遍历查找到对应的数据。
2.LinedList在数据的插入和删除上效率更高。LinkedList只需要遍历查找到数据位置,创建节点并修改节点的引用关系,而ArrayList在插入和删除上需要大量移动数据,效率大大降低。
用过ArrayList吗?说说它的特点吧。
优点:其是基于动态数组的数据结构,其存储数据的地址是连续的,在查询效率比较高。
缺点:正是因为数据的地址是连续的问题,导致在数据的插入和删除时需要移动大量的数据,所以插入和删除的效率比较低。
ArrayList是一种存储数据相同的集合,其实可以变长的集合,ArrayList是基于固定长度的数组实现的,当插入的数据到达一定值的时候就会进行自动扩容。
ArrayList的底层实现
ArrayList的底层使用数组实现的,插入方法中
add(Object)方法:其主要用在插入位置为尾部的情况,当插入的数据量过大时应该是使用ensureCapacity方法,该方法会预先设置的ArrayList的大小,大大提高初始化的效率。
add(index, Object):其主要使用在插入位置不是尾部的情况,此时插入数据可能会导致大量的数据移动,并且可能触发自动扩容机制。
在高并发且线程不安全的情况下,多个线程同时操作ArrayList,可能会引起不可预期的错误和异常。(fail-fast事件)
ArrayList实现了Cloneable接口,说明它可以被复制,但是它的Clone方法是浅拷贝,也就是对对象引用的复制。
有了数组为什么还要搞个ArryList出来呢?说说你的看法。
在插入数据不确定的情况下:
数组就很尴尬,数组需要设置固定的长度,但我们又不能确定数组的长度。
而ArrayList在开始的时候设置初始化的长度,在数据到达一定的数量后就会进行自动扩容,就不会遇到像数组那样尴尬的情况。
与ArrayList相比,LinkedList的增加和删除的操作效率一定比较高吗?有没有特殊情况
1.在删除和插入操作中,linkedLIst需要遍历查找数据的位置时间复杂度为O(n),ArrayList则需要移动数据平均的时间复杂度为O(n),所以在一定情况下ArrayList的效率更高。举个例子:修改一个集合的最后一个数据,这时LinkedList的时间复杂度为O(n),而ArrayList的时间复杂度为O(1)。
2.在大规划的数据操作时,LinkedList需要创建节点并设置节点的引用关系,这样会格外的产生对象的创建和内存的分配,而ArrayList只是数据的移动。(选答)
说说什么是fail-fast?
由于一个集合同时被多个线程操作就可能出现fail-事件。
fail-fast产生的原因
线程A在对当前的集合进行遍历,此过程中线程B对集合进行修改操作,当在此过程中线程A再次访问集合是就会报ConcurrentModifactionException异常,产生fail-fast事件。
解决fail-fast的方法
尽量使用java.util.concurrent包中的类,减少使用java.util中的类。
fail-fast的底层实现的概述
在当前线程进行遍历时,会创建modCount和exceptModCount,modCout用于记录在遍历前数据的修改次数,exceptModCount用于记录遍历后数据的修改次数,将这两个值进行比较,如果两个值不等的话就报ConcourrentModifactionException异常。(具体实现不太清楚,底层的思想就是比较前后的修改次数进行判断是否产生fail-fast事件)
HashMap和HashTable的区别
1.父类的不同:HashMap的父类是AbstractMap,HashTable的父类是Dictionary类,当它们都实现了 map, cloneable(可复制的), serializable(序列化)接口。
2.两者的方法有所不同:以为HashTable的父类是Dictionary,它有方法HashMap没有的方法,分别是: elements(获取value的枚举),contains(判断某值在HashTable的value中十是否存在)
3.对null支持的不同:HashTable的key和value不能为null(在底层它会对value值进行判空,而key会调用hashCode方法,如果key为空也会直接报空指针异常), 而HashMap的key和value都可以为null,但为了key的唯一性,key为null只能存在一个。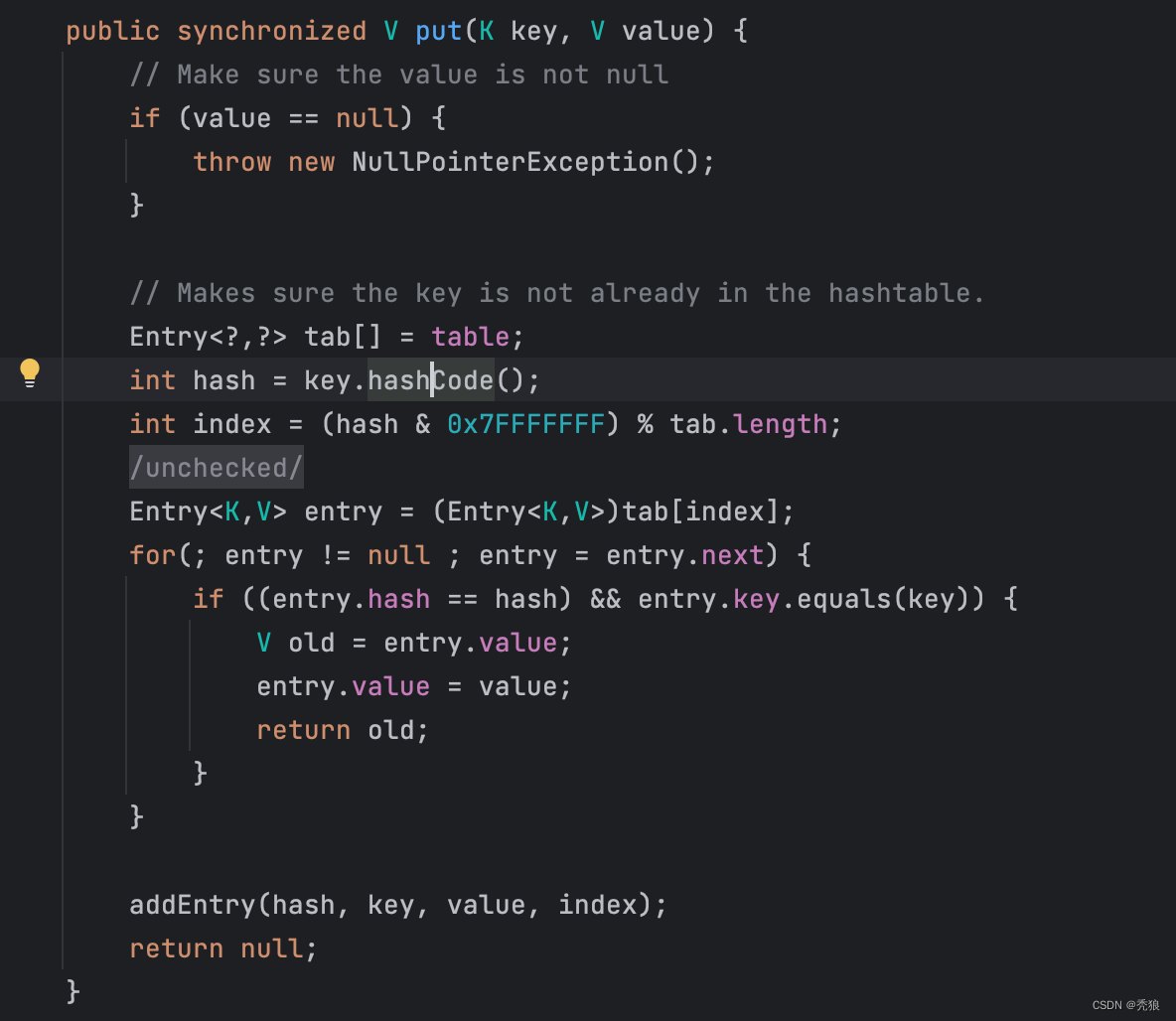
4.线程安全不安全: HashMap是线程不安全的,所以可能会出现死锁的情况。(在数据量庞大的时候,hashMap会进行扩容,在这个扩容的过程就会出现死锁)
HashTable是线程安全的,它会在每个public方法上添加锁关键字(synchronized),一次效率上会比HashMap低。
当在多线程操作时,我们可以使用ConcurrentHashMap,Concurrent不仅线程安全,而且效率比HashTable高,其采用的是分布式锁。(在线程安全的情况下还要考虑性能,这时候有什么解决方案呢?使用ConcurrentHashMap,目前我只知道其底层用到了分布式锁)
5.它们的初始容量和扩容的大小不一样。hashTable的初始长度为11,在扩容的长度为2n + 1,而hashMap的初始长度为16,扩容后的长度为2n
6.它们计算hash值的方法不一样。hashTable直接使用对象的hash值,对象的hash值是根据对象的地址或字符串或数据计算出的值进行除留余数法最终算出的值,因为除法计算十分耗时,所以效率非常的低,hashMap为了提高效率,将容量设置为2的幂次方,这样在取模时,不需要再使用除法,而是使用位运算,效率比hashTable高很多。
7.hashTable和hashMap都使用Iterator,由于历史的原因,hashTable还使用了Enumeration的方式。
在HashMap中的key我们可以使用任意的类作为key吗?
在平常我们一般使用String作为key,当我们需要使用自定义类的时候需要注意以下情况:
1.当类的equals方法被重写时,类的hashCode方法也要被重写。
2.类所属的实例需要遵循与equals和hashCode相关的原则。
3.如果一个类没有使用equals方法时,在hashCode方法中也不能使用equals方法。
4.自定义类的最佳实践就是使之为不可变的,这样hashCode的才会被缓存起来,从而提高性能,不可变的类确保了类的equals和hashCode在未来不会改变,也解决了与可变相关的问题。
HashMap的长度为什么是2的N次方?
为了提高性能。在取模的时候,也就是hash % length时,当除数是2的N次方时,其等价于与除数-1并做 & 位运算,也就是 hash % length == hash & (length - 1),仅当除数为 2 的 N 次方时成立,又因为位运算的效率比除法高很多,所以长度需要设置为2 的 N 次方。
说说HashMap和ConCurrentHashMap的异同?
1.两者都是通过键值对存储数据。
2.HashMap是线程不安全的,而ConcurrentHashMap则是线程安全的。
3.HashMap在JDK1.8之前底层是使用数组 + 链表实现的,在JDK1.8之后就是使用数组 + 链表 + 红黑树实现的,当在HashMap中的某个节点的链表长度大于等于8时就会将链表转换为红黑树。
此时链表的查询速度没有红黑树快。
3.HashMap的初始化长度为16,其装载因子为 0.75,当数据到达长度的75%,就会进行扩容,扩容后的长度就是原来的两倍。
4.ConcurrentHashMap在JDK1.8之前是使用分段锁来实现的segment + HashEntry,segment的数组默认大小为16,2 的 N 次方;在JDK1.8之后,采用 Node + CAS + Synchronized来保证并发安全,从而进行实现的。
为什么HashMap中会使用红黑树?红黑树有什么特点?
如果继续使用链表进行查询和删除的话气时间复杂度为O(N),而红黑树的时间复杂度为O(logN),在效率上明显高于链表。
红黑树的特点
1.每个结点要么是黑色要么是红色。
2.根结点为黑色。
3.叶子结点都是黑色结点,其中红黑树中的叶子结点就是指本身为null的结点。
4.红色结点的父结点和子结点都为黑色,且从根结点到叶子结点的所有路径中不能出现两个连续的红色结点。
5.从任意结点到叶子结点的路径中的黑色结点的数量相同。 
那为什么不使用二叉搜索树呢?
二叉搜索树的时间时间复杂度虽然为O(logN),但是在特殊情况下其的时间复杂度为O(N),就是插入的数据为递增或递减,这样会导致数据要么全部偏左或偏右。最终变成为一个了链表。为了解决这个问题所以使用红黑树。
Collection类和Collections类的区别
Collection是集合类的上级接口,其子接口包括: List,set,ArrayList,LinkedList等等。而Collections类不可以被实例化,该类中多态和静态的方法,这些方法的作用就是对集合的操作,Collections更像是Collection类的帮助类。
Java的四种引用(强弱软虚)
强引用:平时我们最常用的引用,不会被JVM回收。(就比如new String)
String str = new String("Str");软引用:在内存空间不足的时候JVM会将其回收。(softRefernce类)
// 注意:wrf这个引用也是强引用,它是指向SoftReference这个对象的,
// 这里的软引用指的是指向new String("str")的引用,也就是SoftReference类中T
SoftReference<String> wrf = new SoftReference<String>(new String("str"));应用: 在创建缓存的时候,创建的对象会存放到缓存中,在空间不足的时候JVM进行回收。
弱引用:JVM在发现它的时候会将其进行回收。(WeakReference类),一但我们不需要的时候,JVM就会自动回收。
WeakReference<String> wrf = new WeakReference<String>(str);
虚引用:和弱引用相似,但是它在被回收之前先进入ReferenceQueue中,而其他的引用则是先进行回收再进入ReferenceQueue中。也因为此机制虚引用大多用于销毁前的工作。(PhantomReference类)
PhantomReference<String> prf = new PhantomReference<String>(new String("str"),
new ReferenceQueue<>());泛型的特点
我们可以定义一个集合在该集合中我们可以存放各种类型的数据,因为我们把底层的储存设置了
object,因此我们可以通过规则按照自己的想法控制储存的类型。
java提供了几种创建对象方式
1.通过new创建对象。
2.通过反射机制创建对象。
3.通过clone机制创建对象。(浅拷贝)
4.通过反序列化机制创建对象。(调用 ObjectInputStream 类的 readObject() 方法)
我们反序列化一个对象,JVM 会给我们创建一个单独的对象。JVM 创建对象并不会调用任何构造函数。一个对象实现了 Serializable 接口,就可以把对象写入到文件中,并通过读取文件来创建对象。
有没有可能两个对象的HashCode值相同,如果有我们可以怎么解决
有,单两个对象的Hash值相同冲突的时候就会出现HashCode相同的情况。
解决方案
1.拉链法:在每个哈希表的节点上都有next指针,每一个被分配到对应索引上的数据通过单向链表储存起来。
2.开放定址法:当数据相冲突时,就去查找空的散列地址,只要散列表足够大,就可以找到空的散列地址,将数据进行存储。
3.再哈希法(双哈希法):有多个哈希函数,当发生冲突的时候就使用第二个hash函数计算地址, 如果还是冲突就使用三个hash函数计算地址,直到不发生冲突。
深拷贝和浅拷贝的区别
浅拷贝:被复制的对象都含有原来对象相同的值,而在对象的引用上则是进行引用的传递,也就是指向原来的对象,当原来的对象的数据发生改变时会影响到该新的对象。 (只是增加了一个指针指向已存在的内存地址,也就是指向原来的对象内存地址)
深拷贝:被复制的对象都包含原来对象的相同的值,而在对象的引用上则是创建一个新的对象进行引用(其中数据也是相同的),在修改就是对象的数据时不会影响该新的对象。(增加一个指针和申请一块新的内存,使新增的指针指向该内存,在该内存中存储与原来对象相同的值)
final哪些用法
1.被final修饰的类不可以被继承。
2.被final修饰的方法不可以被重写。
3.被final修饰的变量不可以被修改。当被所修饰的变量为引用地址时,引用地址不可以改变,而引用地址指向的内容可以改变。
4.被final修饰的方法会被JVM进行内联操作,从而提高效率。
5.被final修饰的常量会在编译阶段被存入常量池中。
static有哪些用法
1.static可以用于创建静态变量和静态方法,也就是对变量和方法添加static关键字。
2.static可以用于创建静态块,静态块通常用于进行初始化。
public calss PreCache{
//静态块static{//执行相关操作}
}3.static可以用于创建静态内部类,在内部类上添加关键字。
4.static可以用于引入静态资源,想法就比如import static .... ,这是JDK1.5后的新特性。
import static java.lang.Math.*;
public class Test{public static void main(String[] args){//System.out.println(Math.sin(20));传统做法//直接调用方法即可System.out.println(sin(20));}
}0.1 * 3 == 3的值是多少,为什么
值为: false,因为浮点数无法完全精准的表示(0.1可能代表 0.100001)
a += b和a = a + b的区别
a+=b会隐式的做类型类型转化,也就是将右边结果的类型自动转化为左边的类型。而 a=a+b
则不会自动类型转化,所以如果左右边的类型不同时就会报错。
byte a = 127;
byte b = 127;//因为byte的值就只能在[-128, 127],如果值超过这个区间的话就会自动转化为int// byte = int 就会直接报错
a = a + b;//byte = byte 隐式的自动类型转化
a += b;
总的来说就是 +=会隐式的自动进行类型转化,而普通的+则不会。
try catch finally, try中有return还会执行finally吗?说说你对finally的理解。
在try有return时finally中的方法是会执行的, 且会在return 语句执行完之前执行。
1.不管在try中有没有异常都会执行finally。
2.当try中有return时还是会执行finally的。
3.finally会在return 语句中的表达式执行完以后执行,此时会将表达式执行后的值先保存起来,在finally执行完以后在通过return 返回表达式执行后的值。
4.在finally中最好不要有return,会程序导致提前退出,且返回的值不是try中的值,而是finally中的值。
Exception和Erorr包结构
1.运行时异常:java编译器是不会检查它的,如果没有通过try/catch和throw的话,编译是可以通过的。常见的就是 ClassCastException(类转换异常),IndexOutOfBoundException(数组越界异常),
NullPointerException(空指针异常)等异常。
2.被检查异常:Exception类本身,Exception子类(不包括运行时异常的子类),要通过 throw抛出或 try/catch捕获异常,否则编译是无法通过的。常见的就是 IOExceprion(io流异常),FileNotFoundException(文件未找到异常),SQLException(sql语句异常)
3.错误:Error类和子类,和运行时异常一样,编译器无法对错误进行检查。当资源不足时,或其他程序无法进行运行的条件发生时,就会产生错误,程序本身无法修复这种错误,常见的就是 OutOfMemoryError(内存溢出异常),ThreadDeath(线程死亡异常)
简述线程、程序、进程的基本概念。以及他们之间关系是什么?
线程:线程与进程类似,但线程是一个比进程是一个更小的单位,一个进程在执行过程中 会产生多个线程。与进程不同的是,同类的线程是共用一个存储空间和同个系统资源。
程序:是含有指令和数据的文件,也就是说程序是静态的代码。
进程:是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。
线程和进程最大的不同点在于:基本上进程之间是相互独立的互不影响,而在一个进程中的各个线程极有可能会相互影响。
OOM你遇到过哪些情况,SOF你遇到过哪些情况
OOM:OutOfMemoryException:异常通常出现在内存不足的情况下。
Java Heap溢出(堆溢出):这种情况通常是因为创建的对象数量达到堆的最大值,从而出现内存溢出异常。
虚拟机栈和本地方法栈溢出(栈溢出):
虚拟机栈扩张栈时无法申请到足够的空间,导致内存溢出。
方法栈溢出:方法栈中的class没有被及时回收或者class信息占用的空间到大于内存空间导致方法栈溢出。
SOF:StackOverFlowError:此异常通常出现的原因是因为:递归调用,循环次数过多或死循环,全局变量过多,数组,list,map的值过多导致的。
Java序列化中如果有变量不想要序列化,该怎么办?
不想要序列化可以使用transient修饰变量。
transient关键字的作用:阻止被该关键字修饰的变量的序列化,当对象反序列化时,被该关键字修饰的变量不会被持久化和恢复(也就是获取不到该变量的值),transient只能修饰变量,无法修饰方法和类。
Java IO和NIO的区别
NIO就是:New IO,这个库是在JDK1.4后引入的,其作用和IO相同,但在实现方法上是不相同的,
NIO主要通过块实现的,所以NIO和效率比IO的效率高很多,在java api中提供了两个NIO,一个是针对标准的NIO,一个是针对网络编程的NIO。
java反射的作用和原理
定义
反射机制在运行时,我们可以获取到类的所有属性和方法的信息,对于任意个对象,我们可以调用其任意的方法,在给定类名的情况下,我们可以通过反射获取到该类的所有信息。
jdbc就是最典型的反射
Class.forName('com.mysql.jdbc.Driver.class');//加载MySQL的驱动类反射的实现方式
1.通过Class.getName("对应类路径")
2.通过类.Class
3.通过实例对象.getClass()
4.包装类通过获取属性type来获取该包装类的Class
实现java反射类
1.Class:表示正在运行的Java应用程序的类和接口信息。
2.Field:表示类和接口的属性信息和其访问权限。
3.Constructor:表示类和接口单个构造方法及其访问权限。
4.Method:表示类和接口中某个方法对应的信息。
反射的优缺点
优点:能够在运行时动态获取类的实例,提高灵活性。
缺点:
1.反射性能较低,需要解析字节码,将内存中的对象进行解析。(解决方案:1.提高setAccessible(true)方法关闭JDK的安全校验,从而提高效率。2.多次创建一个类的实例时,有缓存会快很多)
2.相对不安全,破坏了封装性。(通过反射可以获取到private 类型的属性,不符合封装性)
说说List,set,map三者的区别
List(用于解决数据顺序的问题):List用于储存一组不唯一的数据,该组数据中的值可以引用相同的对象,且List是有序对象。
set(用于解决数据不重复的问题):set是不允许重复的集合,在数据中不能存在引用相同对象的数据。
map(用key来搜索数据):以键值对的方式储存数据,key必须唯一,而value可以使用相同对象的引用。经典的key就是String类型。
Object有哪些常用的方法?大致说一下每个方法的含义。

Clone方法
其为保护方法,实现对象的浅拷贝,在使用浅拷贝前我们需要实现Cloneable接口,否则会报CloneNotSupportedException异常。在实现深拷贝的时候也需要实现Cloneable接口,其成员变量为引用类型,所以也需要实现Cloneable接口,然后重写Clone方法。
finalize方法
次方法和垃圾回收器有关,在判断一个对象是否需要被回收的最后一步就是判断该方法是否被重写。
equals方法
该方法使用的频率很高,一般equals方法和==的效果是有区别的,但是在Object中的equals方法的实现方法就是==,一般子类都会重写equals方法。
hashCode方法
该方法用于做hash查找,其一般会和equals方法一起被重写。
一般必须满足: obj1.equlas(obj2) = true,obj1.hashCode(obj2)=true,但是两个hashCode相同的对象不一定相等。
hashCode方法在 JDK 1.6,1.7的时候是返回随机数,在JDK1.8后返回和当前线程有关的随机数和加上三个确定值最终构成的随机数。
wait方法
wait方法是配合synchronized方法使用的,就是获取该对象的锁,此时需要保证线程是该对象的拥有者,也就是线程拥有该对象的锁,wait方法一直等待状态,直到回去锁或被中断,wait方法中可以设置timeout,设置超时时间,当等待时间超过超时时间就直接返回。
以下情况线程会被唤醒
1.其他线程调用了该对象的notify方法。
2.其他线程调用了该对象的notifyAll方法。
3.时间超过超时时间。
4.其他线程调用了interrupt中断该线程,并且会报异常interruptedException。
notify方法
配合synchronized使用,唤醒在该对象上的等待队列中的某一个线程。
notify方法
配合synchronized使用,唤醒在该对象的等待队列中的所有线程。
说说你平时是怎么处理java异常的?有使用过自定义异常吗?
try-catch-finally
try模块用于监控可能出现异常的代码。
catch模块捕获可能出现的异常,并进行处理。
finally模块有没有异常都会执行,用于做收尾操作。
整个处理流程为下:
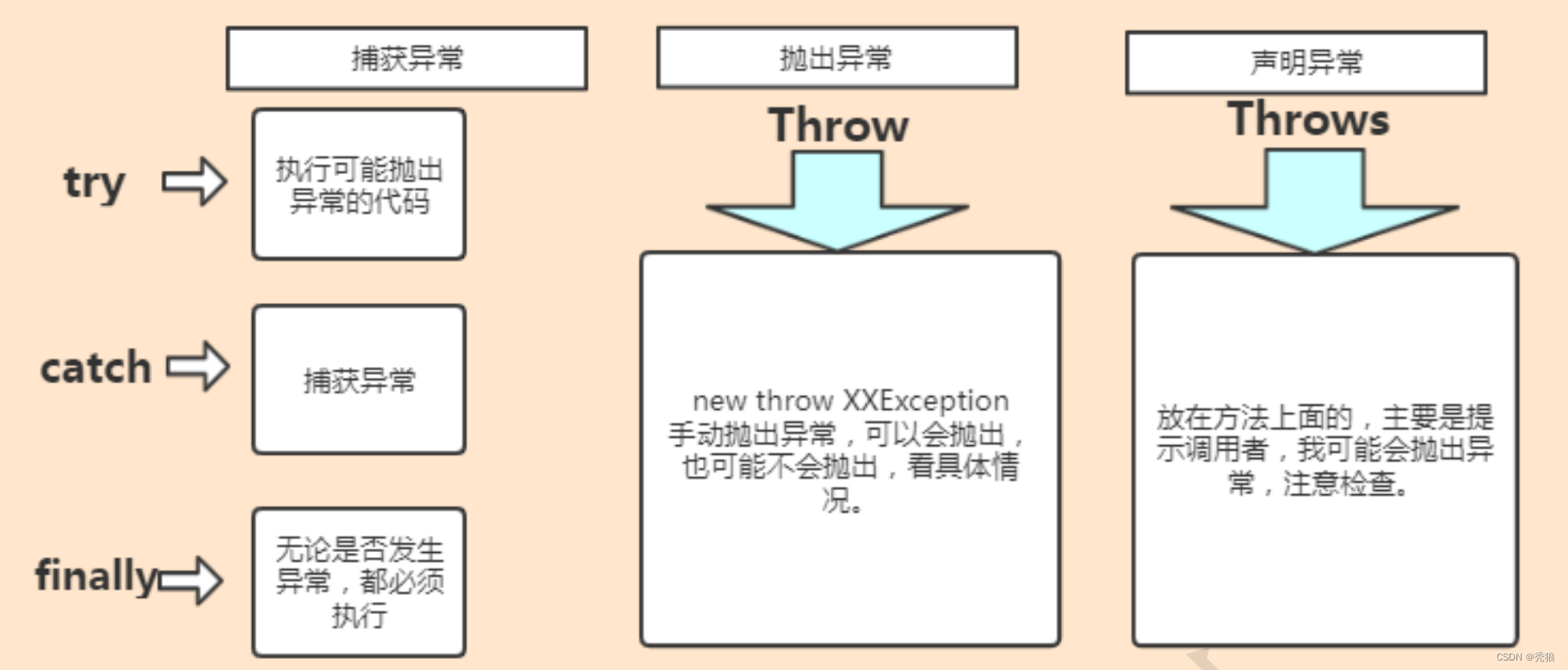
情况1:抛出异常-成功捕获异常-处理异常-程序继续运行。
情况2:抛出异常-异常类型不匹配,捕获异常失败-程序终止。
自定义异常
通常我们自定义异常是去继承Exception类,如果需要的RunTime的异常就去继承RuntimeException类,当然在继承类后需要我们去实现一个无参的构造方法,还需要实现一个参数为字符串的构造方法。

![[UDS] --- ECUReset 0x11](https://img-blog.csdnimg.cn/05d167aee7054ab88ff565354ccda07a.png)