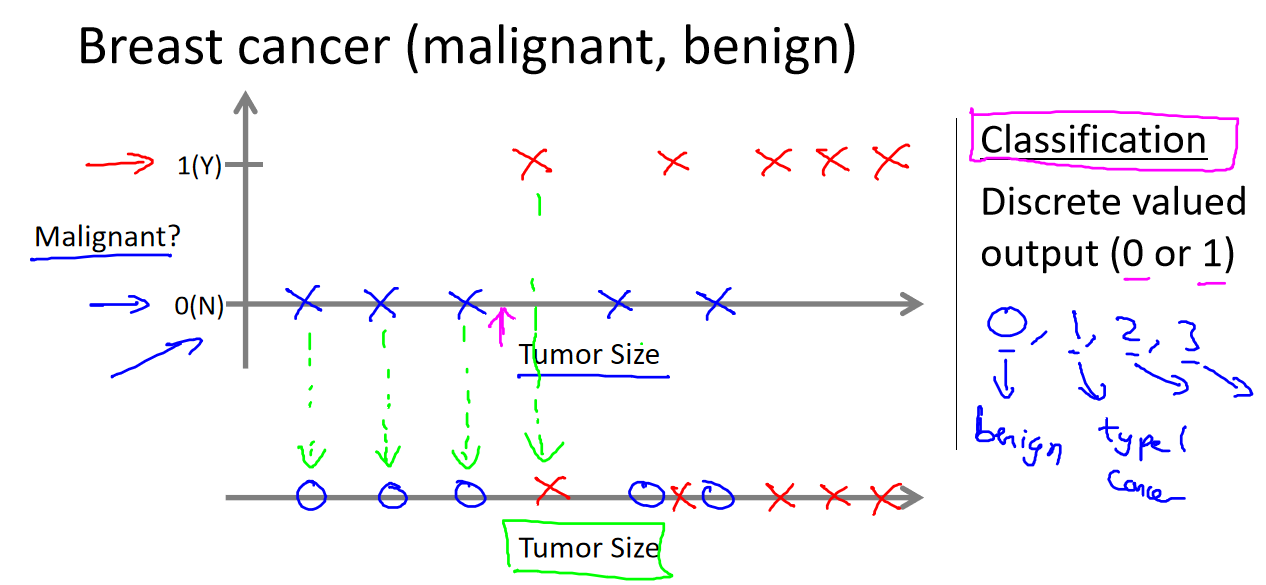
数据操作
机器学习包括的核心组件有:
- 可以用来学习的数据(data);
- 如何转换数据的模型(model);
- 一个目标函数(objective function),用来量化模型的有效性;
- 调整模型参数以优化目标函数的算法(algorithm)。
我们要从数据中提取出特征,机器学习、深度学习通过特征来进一步计算得到模型。因此下面主要介绍的是对数据要做哪些操作。
基本操作
深度学习里最多操作的数据结构是N维的数组。
0维:一个数,一个标量,比如1.
1维:比如一个一维数组,他的数据是一个一维的向量(特征向量)。
2维:比如二维数组(特征矩阵)。
当然还有更多维度,比如视频的长,宽,时间,批量大小,通道……
如果我们想创建这样一个数组,需要明确的因素:
- 数组结构,比如3*4.
- 数组数据类型,浮点?整形?
- 具体每个元素的值。
访问元素的方式:
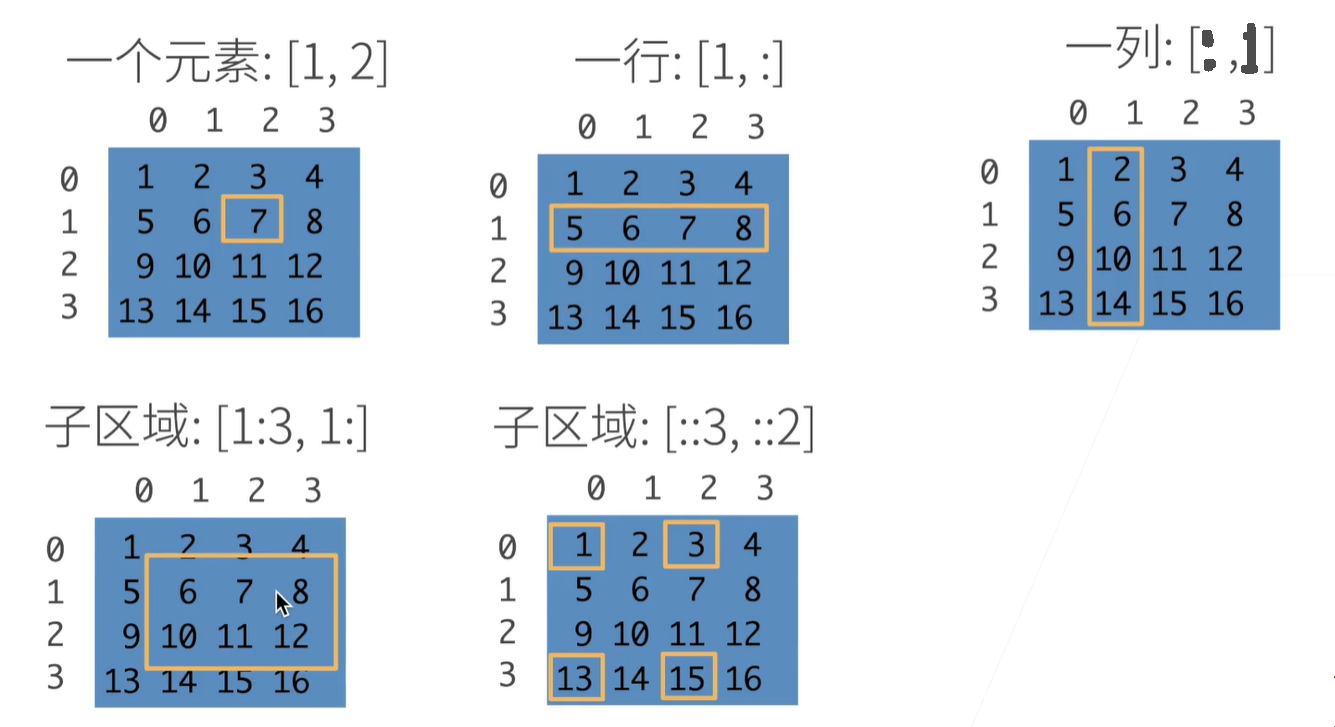
1:3 是左闭右开,表示不包含第3行。
双冒号是跳着访问,后跟步长。比如 ::3 表示从第0行开始访问,每3行访问一次。
明白了这些,那接下来我们就创建一个数组。在机器学习中这种数据的容器一般被称作张量.
创建张量
这部分代码在 jupyter/pytorch/chapter_preliminaries/ndarray.ipynb 里。
在其中可以运行尝试代码部分,创建一维张量:
import torch
X = torch.arange(12) # 自动创建 0-11 的一维张量。输入 X 查看 X 内元素数据,输出:
# tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
X.shape # 查看向量形状。输出 torch.Size([12]),指长12的一维向量
X.numel() # 只获取长度,输出12
X = X.reshape(3, 4) # 重新改成了3行4列形状。变成了0123 4567 891011
torch.zeros((2, 3, 4)) # 创建了一个形状为(2,3,4)的全0张量
# tensor([[[0., 0., 0., 0.],
# [0., 0., 0., 0.],
# [0., 0., 0., 0.]],
#
# [[0., 0., 0., 0.],
# [0., 0., 0., 0.],
# [0., 0., 0., 0.]]])
# torch.ones 同理,是全1的
# torch.randn 是取随机数,随机数是均值=0,方差=1的一个高斯分布中取
torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]]) # 给定值创建
torch.exp(X) # 求e^x中每个元素值得到的新张量
reshape 很有意思,它不是复制原数组后重新开辟了一片空间,而是还是对原数组元素的操作(只不过原来是连续12个数,现在我们把他们视作4个一行的3行元素。存储空间都是连续的)。因此如果我们对 reshape 后的数组赋值,原数组值也会改变。
算术运算
对于两个相同形状的向量可以进行+ - * / **(求幂运算)运算。
x = torch.tensor([1.0, 2, 4, 8]) # 1.0 为了让这个数组变成浮点数组
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x * y, x / y, x ** y # **运算符是求幂运算
# Output:
(tensor([ 3., 4., 6., 10.]),tensor([-1., 0., 2., 6.]),tensor([ 2., 4., 8., 16.]),tensor([0.5000, 1.0000, 2.0000, 4.0000]),tensor([ 1., 4., 16., 64.]))
x==y # 每一项分别判断是否相等。我试了一下,数据类型不影响。2.0==2
x.sum() # 所有元素求和
张量连接
X = torch.arange(12, dtype=torch.float32).reshape((3,4)) # 创建 float32 位的张量
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1) # 行和列两个维度的拼接
# Output:
(tensor([[ 0., 1., 2., 3.],[ 4., 5., 6., 7.],[ 8., 9., 10., 11.],[ 2., 1., 4., 3.],[ 1., 2., 3., 4.],[ 4., 3., 2., 1.]]),tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],[ 4., 5., 6., 7., 1., 2., 3., 4.],[ 8., 9., 10., 11., 4., 3., 2., 1.]]))
# 这里我看到弹幕前辈的讲解,感觉很受用。行是样例,列是特征属性,这个类似 MySQL 的关系数据库理解
广播机制
即使两个张量形状不同,也有可能通过广播机制进行按元素操作。
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
a, b
# Output:
(tensor([[0],[1],[2]]),tensor([[0, 1]]))a + b # 把a按列复制2份,b按行复制3份,都变成3*2的张量进行操作
# Output:
tensor([[0, 1],[1, 2],[2, 3]])
索引
X[-1], X[1:3] # 这里和前面介绍的概念一样。-1 是倒数第一个元素(一个n-1维度张量),1:3 是第2,第3个元素不包括第4个元素。
# Output:
(tensor([ 8., 9., 10., 11.]),tensor([[ 4., 5., 6., 7.],[ 8., 9., 10., 11.]]))
X[1,2]=9 # 写入
X[0:2, :] = 12 # 批量写入,给0-1行,所有列写成12
X
# Output:
tensor([[12., 12., 12., 12.],[12., 12., 12., 12.],[ 8., 9., 10., 11.]])
节省内存
有一些操作会分配新内存。比如 Y=Y+X,并不是直接在 Y 的原地址上加了X,而是在新地址上计算得到 Y+X,让 Y 指向新地址。
可以通过 id(X) 函数来查看地址。
Y[:]=Y+X 或者 Y+=X 会在原地执行计算,Y 地址不变。
类型转换
转换为 numpy 张量:A=X.numpy()
张量转换为标量:
a=torch.tensor([3.5])
a.item() # 3.5
float(a) # 3.5
int(a) # 3
数据预处理
实际处理数据的时候我们并不是从张量数据类型开始的,我们可能得到一个 excel 文件,自己把它转换成 python 张量。以及在转换之前,我们可能对数据进行预处理,比如把其中的空值统一赋值为0之类的操作。以下是转换步骤。
首先我们创建一个 csv 文件作为原始数据集。
import osos.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:f.write('NumRooms,Alley,Price\n') # 列名f.write('NA,Pave,127500\n') # 每行表示一个数据样本f.write('2,NA,106000\n')f.write('4,NA,178100\n')f.write('NA,NA,140000\n')
三个属性分别是 room 数量,走廊状态(比如铺了地板),价格。
然后我们把这个数据读入 python,加载原始数据集。
# 如果没有安装pandas,只需取消对以下行的注释来安装pandas
# !pip install pandas
import pandas as pddata = pd.read_csv(data_file)
这个数据集里还是有很多 NaN 项的,我们要对其进行修改替换。数值类典型处理方式是插值和删除。
首先最后一列数据是完整不需要修改的,那么我们只要处理前两列,我们把前两列数据单独拿出来做完处理最后进行张量拼接。
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
然后我们把 NumEooms 中的 NaN 值用均值替代,
inputs = inputs.fillna(inputs.mean(numeric_only=True))
print(inputs)
# Output:NumRooms Alley
0 3.0 Pave
1 2.0 NaN
2 4.0 NaN
3 3.0 NaN
对于 Alley 列,只有两种状态:NaN 和 Pave。我们用 pandas 的方法,把 NaN 也视作一个类,自动拆成两列设置值。
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)
# Output:NumRooms Alley_Pave Alley_nan
0 3.0 1 0
1 2.0 0 1
2 4.0 0 1
3 3.0 0 1
最后,我们将前两列处理后得到的结果与最后一列转换为张量后进行拼接。
import torchX = torch.tensor(inputs.to_numpy(dtype=float))
y = torch.tensor(outputs.to_numpy(dtype=float))
y=y.reshape(4,1)
torch.cat((X,y),dim=1)
# Output:
tensor([[3.0000e+00, 1.0000e+00, 0.0000e+00, 1.2750e+05],[2.0000e+00, 0.0000e+00, 1.0000e+00, 1.0600e+05],[4.0000e+00, 0.0000e+00, 1.0000e+00, 1.7810e+05],[3.0000e+00, 0.0000e+00, 1.0000e+00, 1.4000e+05]], dtype=torch.float64)