关于AutoEncoding(AE)和AutoRegressive(AR)
前几天看了Ilya在Simons上做的关于Generative Model的演讲,介绍了OpenAI现在做的一些AutoRegressive的工作,昨天又看到LeCun宣称Auto-Regressive LLMs are doomed。平时看的文章也常常提到自监督学习里的两种范式AutoEncoding和AutoRegressive,之前也只是简单的理解为GPT系列属于AutoRegressive,Bert系列属于AutoEncoding。遂决定写一篇文章详细记录一下这两者的区别和联系
encoder-decoder 架构
在此之前,我们需要了解编码器-解码器架构的发展,因为每种这两种架构类型都与这种思维方式相关。
编码器-解码器体系结构由两个部分组成,编码器和解码器(显然🤣)。
简要的说,编码器的作用是将输入数据转换为潜在表示或特征向量。它接受输入数据,如图像、文本或音频等,然后对其进行处理和编码,最终生成一个固定长度的向量表示。编码器的设计目标是提取输入数据的关键特征,捕捉数据中的重要信息,并将其编码为潜在空间中的表示。这个潜在表示通常具有较高的维度,可以看作是输入数据的抽象表示。编码器的输出可以用于后续任务,如重构、分类、聚类等。
值得一提的是,对于编码过后的向量,实际上我们不能轻易理解他为啥是这样表示的,因为没有涉及语义,这个映射是学习出来的
而解码器的作用是将潜在表示或特征向量转换回原始数据的形式。它接受编码器生成的潜在表示,并将其解码为与输入数据相匹配的形式。解码器的设计目标是通过逆向操作重建原始数据,尽可能地恢复输入数据的细节和结构。解码器在生成过程中可以根据需要与外部信息进行交互,例如生成图像的像素值或语言模型中的下一个词语。解码器的输出通常是重构的数据或生成的数据样本
总的来说,编码器将输入数据转换为高维空间中的潜在表示,而解码器将潜在表示转换回原始数据的形式。相当于一个进行概括然后加密,一个用来解密

如果同时训练编码器和解码器,我们就创建了所谓的sequence2sequence模型。如果我们只训练一个部分,我们会得到一个自回归(AutoRegressive)或一个自动编码(AutoEncoding)模型
sequence2sequence
顺便提一下,Sequence-to-Sequence是一种能够摄取特定类型的序列并输出另一种序列的架构。
Transformer实际上就是一种sequence2sequence模型,下面就是那张非常非常非常有名的Transformer结构图
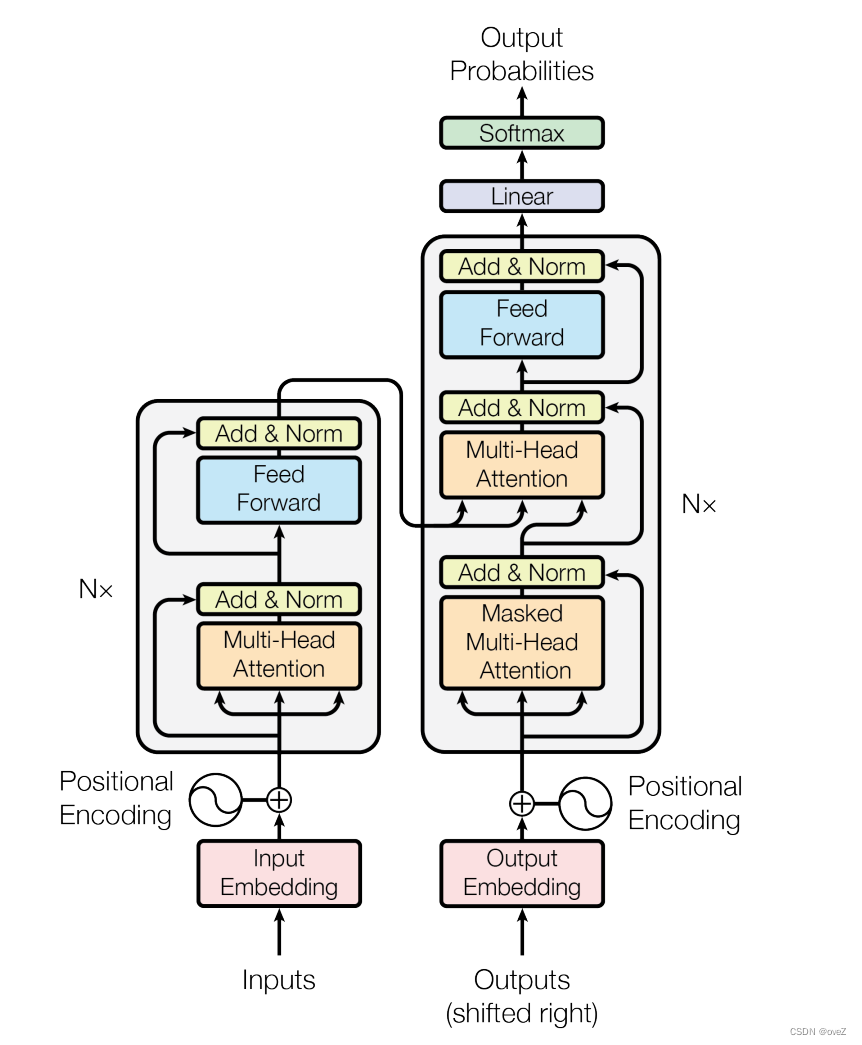
在Transformer中,编码器段确保将输入转换为抽象的高维中间表示。解码器段采用此表示形式,提供有关输入和目标序列的上下文,并确保可以为源语言中的序列预测目标语言中的适当序列
自回归模型
为什么要AR模型
自然语言处理中的任务之一是语言的生成,或者更正式的说是自然语言生成(NLG)。使用sequence2sequence模型生成文本是不太容易的,因为在预测的时候我们通常无法获得完整的目标序列。实际上只是在做基于过去输入的next word prediction。或者换句话说,我们使用的是过去预测的单词来预测现在的单词。
为了解决这些问题,提出了自回归(Autoregressive,AR)架构。在 AR 架构中,生成过程变成了逐个元素的生成,即从左到右生成序列中的每个元素,而不是一次性生成整个序列。这样的架构允许模型在生成过程中根据已生成的部分来动态调整下一个元素的预测,减少累积错误的风险。
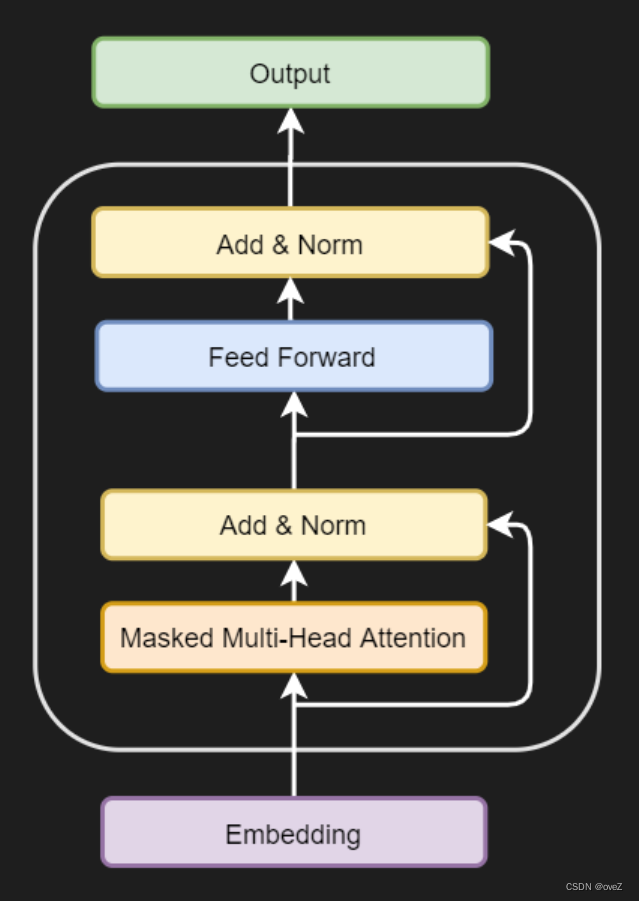
训练AR模型
采用AR方法,就是从左到右逐个生成单词的过程。在这种方法中,生成第i个单词时,只能依赖于它之前的第1到第(i-1)个单词,而不能看到后面的单词。这种逐步生成的方式保持了模型的自回归性质,每个生成的单词都是基于前面已生成的单词的结果。
适用的任务
-
语言建模(主要):AR模型可以用于语言建模,即根据前面的单词或字符预测下一个单词或字符。比如可以聊天的ChatGPT
-
时间序列预测:例如股票价格预测、天气预测、交通流量预测等。通过分析过去的观测值,AR模型可以预测未来的观测值。
-
机器翻译:AR模型可以用于机器翻译任务,将源语言的序列翻译成目标语言的序列。在这种情况下,AR模型可以根据源语言的部分序列来逐步生成目标语言的序列。
自编码模型
为什么用AE模型
自回归模型在进行语言建模(即自然语言生成)时非常有效。然而,并非所有任务都适用于自回归模型,比如自然语言理解。
一个很重要的原因是。自然语言生成任务和自回归模型不一定需要对语言进行深入理解,只要能够成功生成文本即可。
如果想要让模型所谓的理解自然语言输入,然后比较好的泛化到下游任务上,这个时候自编码模型就比较能够发挥作用(这里只是我的个人理解),一个典型的例子就是Bert。因为自动编码器的目的是通过训练网络忽略信号“噪声”来学习一组数据的表示(编码),通常用于降维。相当于与归约侧一起,学习重建侧,其中自动编码器尝试从归约编码生成尽可能接近其原始输入的表示从某种意义上来说就是对于输入的自然语言有了一定程度上的理解。
在Hugging Face上的定义是:自动编码模型是通过以某种方式损坏输入标记并尝试重建原始句子来预训练的。
如何训练AE模型
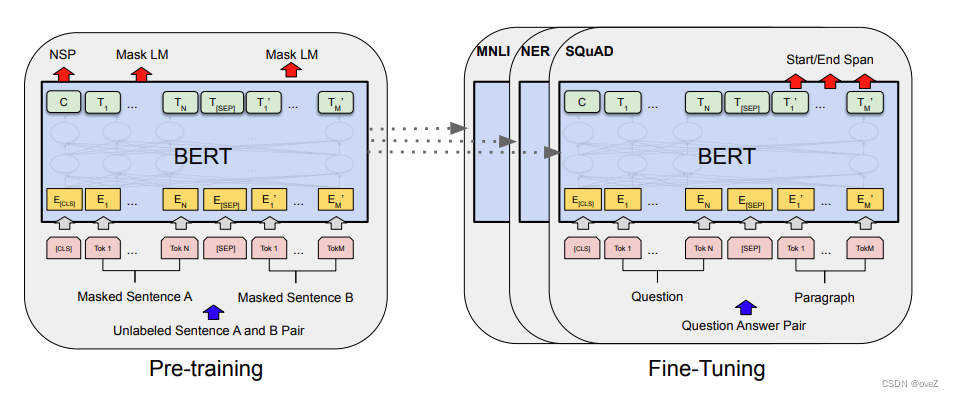
以bert为例,他的整个架构是一个典型的Transformer模型,用于语言模型的预训练阶段采用了自编码器(AE)方法。换句话说,训练的时候在输入句子中,除了被掩码(Mask)的单词外,任意两个未被掩码的单词之间是可见的,但被掩码的单词之间相互独立且不可见。当要预测一个被掩码的单词时,所有其他被掩码的单词不起作用,但未被掩码的所有单词都可以参与当前单词的预测。
适用的任务
-
特征提取:自编码器可以用作特征提取器,将高维输入数据转换为低维表示。这些低维表示可以用于其他机器学习任务,如分类、聚类、降维等。
-
数据去噪:自编码器可以通过学习从损坏或噪声数据中重构原始数据的能力来进行数据去噪。在训练过程中,自编码器被要求将损坏或噪声数据作为输入,并尽可能准确地重构原始数据。