本文整理一下结构体的相关知识,记录是为了更好地加深理解。
1. 结构体声明
下面两个声明语句:
struct {int a;char b;float c;
} x;struct {int a;char b;float c;
} y[20], *z;
这两个声明被编译器当作两种截然不同的类型,即使它们的成员列表完全相同。因此,变量y和z的类型和x的类型不同,所以下面这条语句是非法的。
z=&x;
为了能让上面的表达式不报错,我们需要这样书写:
struct SIMPLE {int a;char b;float c;
};
这个声明把标签SIMPLE和这个成员列表联系在一起。该声明并没有提供变量列表,所以它并未创建任何变量。
标签标识了一种模式,用于声明未来的变量,但无论是标签还是模式本身都不是变量。
struct SIMPLE x;
struct SIMPLE y[20], *z;
这些声明使用标签来创建变量。它们创建和最初两个例子一样的变量,但存在一个重要的区别——现在x、y和z都是同一种类型的结构变量。
声明结构时可以使用的另一种良好技巧是用typedef创建一种新的类型,如下面的例子所示。
typedef struct {int a;char b;float c;
} SIMPLE ;
这个技巧和声明一个结构标签的效果几乎相同。区别在于Simple现在是个类型名而不是个结构标签,所以后续的声明可能像下面这个样子:
Simple x;
Simple y[20], *z;
如果你想在多个源文件中使用同一种类型的结构,你应该把标签声明或typedef形式的声明放在一个头文件中。当源文件需要这个声明时可以使用#include指令把那个头文件包含进来。
2. 结构体成员
一个结构体的成员的名字可以和其他结构的成员的名字相同:
struct COMPLEX {float f;int a[20];long *lp;struct SIMPLE s;struct SIMPLE sa[10];struct SIMPLE *sp;
};
一个结构体的成员的名字可以和其他结构体的成员的名字相同,所以这个结构体的成员a并不会与struct SIMPLE s的成员a冲突。
访问结构体成员可以用.(操作对象是结构体)和->(操作对象是结构体指针)。
struct COMPLEX comp;
comp.f
comp.a
comp.sstruct COMPLEX *cp;
cp->f
cp->a
cp->s
3. 结构体的自引用
struct SELF_REF1{int a;struct SELF_REF1 b;int c;
};
这种类型的自引用是非法的,因为成员b是另一个完整的结构,其内部还将包含它自己的成员b。这第2个成员又是另一个完整的结构,它还将包括它自己的成员b。这样重复下去永无止境。这有点像永远不会终止的递归程序。但下面这个声明却是合法的,你能看出其中的区别吗?
struct SELF_REF2{int a;struct SELF_REF2 *b;int c;
};
这个声明和前面那个声明的区别在于b现在是一个指针而不是结构体。编译器在结构的长度确定之前就已经知道指针的长度,所以这种类型的自引用是合法的。更加高级的数据结构体,如链表和树,都是用这种技巧实现的。每个结构体指向链表的下一个元素或树的下一个分枝。
警惕下面这个陷阱:
typedef struct {int a;SELF_REF3 *b;int c;
} SELF_REF3;
这个声明的目的是为这个结构体创建类型名SELF_REF3。但是,它失败了。类型名直到声明的末尾才定义,所以在结构声明的内部它尚未定义。解决方案是定义一个结构标签来声明b,如下所示:
typedef struct SELF_REF3_TAG {int a;struct SELF_REF3_TAG *b;int c;
} SELF_REF3;
4. 结构体不完整声明
有这样一种情况:有多个结构体,其中一个结构包含了另一个结构的一个或多个成员。和自引用结构一样,至少有一个结构必须在另一个结构内部以指针的形式存在。问题在于声明部分:如果每个结构都引用了其他结构的标签,哪个结构应该首先声明呢?
这个问题的解决方案是使用不完整声明,它声明一个作为结构标签的标识符。然后,我们可以把这个标签用在不需要知道这个结构的长度的声明中,如声明指向这个结构的指针。接下来的声明把这个标签与成员列表联系在一起。
考虑下面这个例子,两个不同类型的结构内部都有一个指向另一个结构的指针。
struct B;
struct A {struct B *partner;
};
struct B {struct A *partner;
};
在A的成员列表中需要标签B的不完整的声明。一旦A被声明之后,B的成员列表也可以被声明。
5. 结构体的初始化
结构的初始化方式和数组的初始化很相似。一个位于一对花括号内部、由逗号分隔的初始值列表可用于结构各个成员的初始化。这些值根据结构成员列表的顺序写出。如果初始列表的值不够,剩余的结构成员将使用缺省值进行初始化。
结构中如果包含数组或结构成员,其初始化方式类似于多维数组的初始化。一个完整的聚合类型成员的初始值列表可以嵌套于结构的初始值列表内部。这里有一个例子:
struct INIT_EX {int a;short b[10];Simple c;
} x = {10,{1,2,3,4,5},{25,'x',1.9}
};
6. 结构体和指针
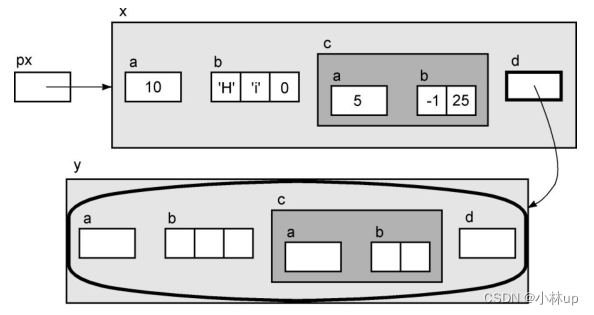
这里举了一个例子,我们先定义一个复杂的结构体
typedef struct {int a;short b[2];
} Ex2;
typedef struct EX {int a;char b[3];Ex2 c;struct Ex *d;
} Ex;
Ex的结构可以这样表示:
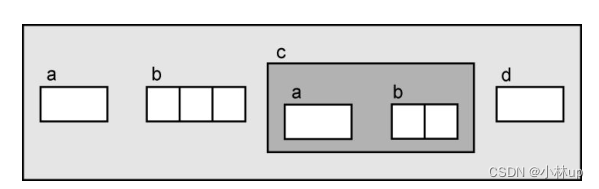
初始化:
Ex x = { 10, "Hi", { 5, { -1, 25 } }, 0 };
Ex *px = &x;
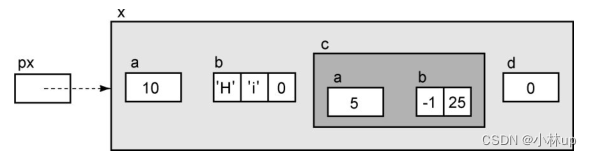
int *pi = &px->a;
->的优先级要高于&,所以下面对结构体内部的f取地址不用加括号:
int *pi = &px->a;
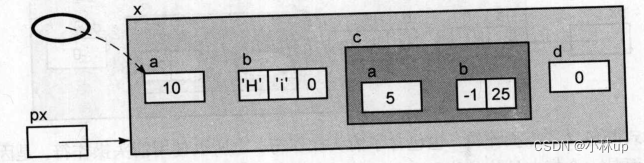
px->b
下面的表达式的值是一个指针常量,因为b是一个数组。这个表达式不是一个合法的左值。它的右值是有意义的:
px->b
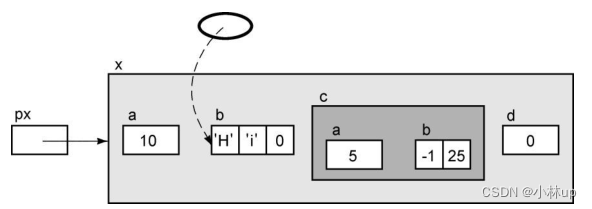
px->b[1]
如果我们对这个表达式执行间接访问操作,它将访问数组的第1个元素。使用下标引用或指针运算,我们还可以访问数组的其他元素。下面的表达式访问数组的第2个元素:
px->b[1]
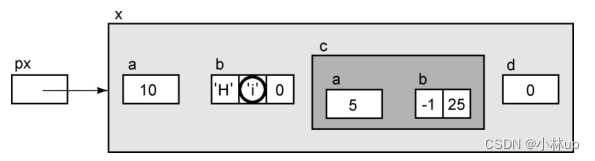
px->c
为了访问本身也是结构的成员c,我们可以使用下面的表达式。它的左值是整个结构:
px->c
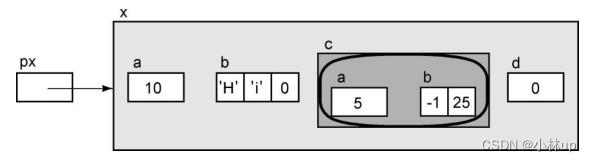
px->c.a
这个表达式可以使用点操作符访问c的特定成员。例如下面表达式的右值是有意义的,这个表达式既包含了点操作符,也包含了箭头操作符。之所以使用箭头操作符,是因为px并不是一个结构体,而是一个指向结构体的指针。接下来之所以要使用点操作符是因为px->s的结果并不是一个指针,而是一个结构体。
px->c.a
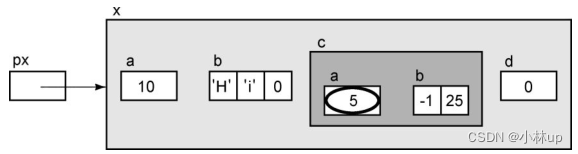
*px->c.b
这里有一个更为复杂的表达式:
*px->c.b
它有三个操作符,首先执行的是箭头操作符。px->c的结果是结构c。在表达式中增加.b访问结构c的成员b。b是一个数组,所以px->b.c的结果是一个(常量)指针,它指向数组的第1个元素。最后对这个指针执行间接访问,所以表达式的最终结果是数组的第1个元素。(*的优先级是最后的)这个表达式可以图解如下:
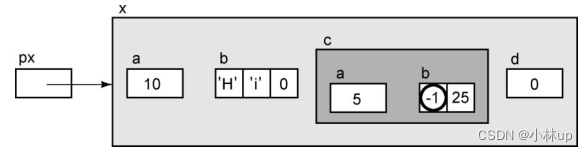
px->d
来看这样一个表达式:
px->d
表达式的结果正如你所料——它的右值是0,它的左值是它本身的内存位置。
*px->d
如果对上面的式子进行解引用呢?
`*px->d`
这里间接访问操作符作用于成员d所存储的指针值。但d包含了一个NULL指针,所以它不指向任何东西。对一个NULL指针进行解引用操作是个错误,但正如我们以前讨论的那样,有些环境不会在运行时捕捉到这个错误。在这些机器上,程序将访问内存位置零的内容,把它也当作是结构体成员之一,如果系统未发现错误,它还将高高兴兴地继续下去。这个例子说明了对指针进行解引用操作之前检查一下它是否有效是非常重要的。
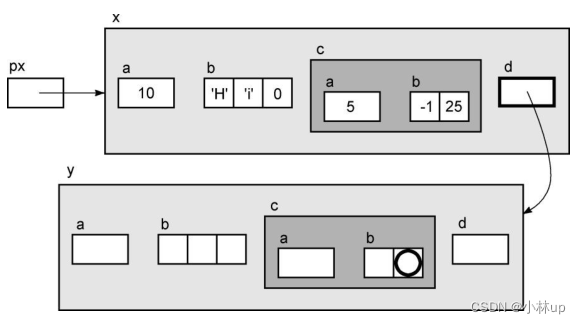
我们创建另一个结构,并把x.d设置为指向它。
Ex y;
x.d = &y;
现在我们可以对表达式*px->d求值。成员d指向一个结构,所以对它执行间接访问操作的结果是整个结构。这个新的结构并没有显式地初始化,所以在图中并没有显示它的成员的值。
正如你可能预料的那样,这个新结构的成员可以通过在表达式中增加更多的操作符进行访问。我们使用箭头操作符,因为d是一个指向结构的指针。下面这些表达式是执行什么任务的呢?
px->d->c.b[1]
px->d->c.b[1]
7. 结构体的存储
编译器按照成员列表的顺序一个接一个地给每个成员分配内存。只有当存储成员时需要满足正确的边界对齐要求时,成员之间才可能出现用于填充的额外内存空间。为了说明这一点,考虑下面这个结构:
struct ALIGN {char a;int b;char c;
};
如果某个机器的整型值长度为4个字节,并且它的起始存储位置必须能够被4整除,那么这一个结构体在内存中的存储将如下所示:

系统禁止编译器在一个结构体的起始位置跳过几个字节来满足边界对齐要求,因此所有结构体的起始存储位置必须是结构体中边界要求最严格的数据类型所要求的位置。因此,成员a(最左边的那个方框)必须存储于一个能够被4整除的地址。结构体的下一个成员是一个整型值,所以它必须跳过3个字节(用灰色显示)到达合适的边界才能存储。在整型值之后是最后一个字符。
如果声明了相同类型的第2个变量,它的起始存储位置也必须满足4这个边界,所以第1个结构的后面还要再跳过3个字节才能存储第2个结构。因此,每个结构体将占据12个字节的内存空间但实际只使用其中的6个,这个利用率可不是很出色。
可以在声明中对结构的成员列表重新排列,让那些对边界要求最严格的成员首先出现,对边界要求最弱的成员最后出现。这种做法可以最大限度地减少因边界对齐而带来的空间损失。例如,下面这个结构体
struct ALIGN2 {int b;char a;char c;
};
所包含的成员和前面那个结构一样,但它只占用8个字节的空间,节省了33%。两个字符可以紧挨着存储,所以只有结构最后面需要跳过的两个字节才被浪费。
当程序将创建几百个甚至几千个结构时,减少内存浪费的要求就比程序的可读性更为急迫。在这种情况下,在声明中增加注释可能避免可读性方面的损失。
sizeof操作符能够得出一个结构的整体长度,包括因边界对齐而跳过的那些字节。如果你必须确定结构某个成员的实际位置,应该考虑边界对齐因素,可以使用offsetof宏(定义于stddef.h)。它的使用格式是:
offsetof( type, member )
type就是结构体的类型,member就是你需要的那个成员名。表达式的结果是一个size_t值,表示这个指定成员开始存储的位置距离结构开始存储的位置偏移几个字节。例如,对前面那个声明而言,
offsetof( struct ALIGN, b )
它的值是4。
8. 作为函数参数的结构体
我们可以给函数传递结构体:
typedef struct {char product [PRODUCT_SIZE];int quantity;float unit_price;float total_amount;
} Transaction;
我们可以将整个结构体作为参数传递:
void print_receipt(Transaction trans)
{printf("%s\n", trans.product);printf("%d @ %.2f total %.2f\n", trans.quantity, trans.unit_price, trans.total_amount);
}
如果current_trans是一个Transaction结构,我们可以像下面这样调用函数:
print_receipt( current_trans );
这个方法能够产生正确的结果,但它的效率很低,因为C语言的参数传值调用方式要求把参数的一份拷贝传递给函数。如果PRODUCT_SIZE为20,而且在我们使用的机器上整型和浮点型都占4个字节,那么这个结构将占据32个字节的空间。要想把它作为参数进行传递,我们必须把32个字节复制到堆栈中,以后再丢弃。
把前面那个函数和下面这个进行比较:
void print_receipt(Transaction *trans)
{printf("%s\n", trans->product);printf("%d @ %.2f total %.2f\n", trans->quantity, trans->unit_price, trans->total_amount);
}
这个函数可以像下面这样进行调用:
print_receipt( ¤t_trans );
这次传递给函数的是一个指向结构的指针。指针比整个结构要小得多,所以把它压到堆栈上效率能提高很多。传递指针另外需要付出的代价是我们必须在函数中使用间接访问来访问结构的成员。结构越大,把指向它的指针传递给函数的效率就越高。
可以把参数声明为寄存器变量,从而进一步提高指针传递方案的效率。在有些机器上,这种声明在函数的起始部分还需要一条额外的指令,用于把堆栈中的参数(参数先传递给堆栈)复制到寄存器,供函数使用。但是,如果函数对这个指针的间接访问次数超过两三次,那么使用这种方法所节省的时间将远远高于一条额外指令所花费的时
间。
向函数传递指针的缺陷在于函数现在可以对调用程序的结构变量进行修改。如果我们不希望如此,可以在函数中使用const关键字来防止这类修改。经过这两个修改之后,函数的原型写作:
void print_receipt( register Transaction const *trans );
参考:
- 《C和指针》