哪些环节会造成消息丢失?

首先说说哪些环节会丢消息
- 消息生产者:
(1)acks=0: 表示producer不需要等待任何broker确认收到消息的回复,就可以继续发送下一条消息。性能最高,但是最容易丢消 息。大数据统计报表场景,对性能要求很高,对数据丢失不敏感的情况可以用这种。
(2)acks=1: 至少要等待leader已经成功将数据写入本地log,但是不需要等待所有follower是否成功写入。就可以继续发送下一条消 息。这种情况下,如果follower没有成功备份数据,而此时leader又挂掉,则消息会丢失。
(3)acks=-1或all: 这意味着leader需要等待所有备份(min.insync.replicas配置的备份个数)都成功写入日志,这种策略会保证只要有一 个备份存活就不会丢失数据。这是最强的数据保证。一般除非是金融级别,或跟钱打交道的场景才会使用这种配置。当然如果 min.insync.replicas配置的是1则也可能丢消息,跟acks=1情况类似。
- 消息消费端:
如果消费这边配置的是自动提交,万一消费到数据还没处理完,就自动提交offset了,但是此时你consumer直接宕机了,未处理完的数据 丢失了,下次也消费不到了。
怎么保证消息不丢失?

生产端:消息发送+回调
伪代码
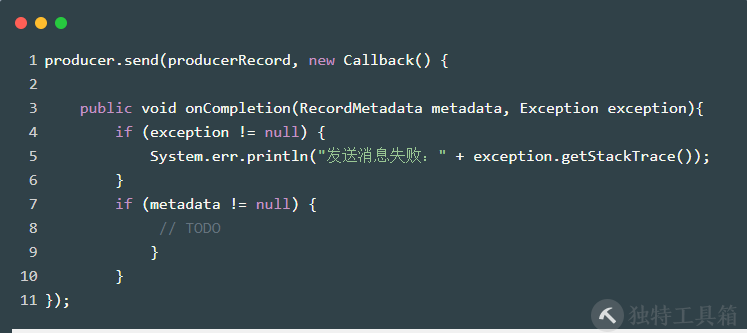
消费端:业务处理完后手动提交
消息重复消费
消息发送端:
发送消息如果配置了重试机制,比如网络抖动时间过长导致发送端发送超时,实际broker可能已经接收到消息,但发送方会重新发送消息。因为发送端重试导致的消息重复发送问题,kafka的幂等性可以保证重复发送的消息只接收一次,只需在生产者加 上参数 props.put(“enable.idempotence”, true) 即可,默认是false不开启。
消息消费端:
如果消费这边配置的是自动提交,刚拉取了一批数据处理了一部分,但还没来得及提交,服务挂了,下次重启又会拉取相同的一批数据重 复处理
一般消费端都是要做消费幂等处理的。 比如分布式锁、全局唯一id
at most once(消费者最多收到一次消息,0-1次):acks = 0 可以实现。
at least once(消费者至少收到一次消息,1-多次):ack = all 可以实现。
exactly once(消费者刚好收到一次消息):at least once 加上消费者幂等性可以实现,还可以用kafka生产者的幂等性来实
现。
消息顺序
如果发送端配置了重试机制,kafka不会等之前那条消息完全发送成功才去发送下一条消息,这样可能会出现,发送了1,2,3条消息,第 一条超时了,后面两条发送成功,再重试发送第1条消息,这时消息在broker端的顺序就是2,3,1了 所以,是否一定要配置重试要根据业务情况而定。也可以用同步发送的模式去发消息,当然acks不能设置为0,这样也能保证消息从发送 端到消费端全链路有序。
kafka保证全链路消息顺序消费,需要从发送端开始,将所有有序消息发送到同一个分区,然后用一个消费者去消费,但是这种性能比较 低,可以在消费者端接收到消息后将需要保证顺序消费的几条消费发到内存队列(可以搞多个),一个内存队列开启一个线程顺序处理消 息。
消息积压
1)线上有时因为发送方发送消息速度过快,或者消费方处理消息过慢,可能会导致broker积压大量未消费消息。 此种情况如果积压了上百万未消费消息需要紧急处理,可以修改消费端程序,让其将收到的消息快速转发到其他topic(可以设置很多分 区),然后再启动多个消费者同时消费新主题的不同分区。
2)由于消息数据格式变动或消费者程序有bug,导致消费者一直消费不成功,也可能导致broker积压大量未消费消息。 此种情况可以将这些消费不成功的消息转发到其它队列里去(类似死信队列),后面再慢慢分析死信队列里的消息处理问题。
kafka高性能原因
-
磁盘顺序读写:kafka消息不能修改以及不会从文件中间删除保证了磁盘顺序读,kafka的消息写入文件都是追加在文件末尾, 不会写入文件中的某个位置(随机写)保证了磁盘顺序写。
-
数据传输的零拷贝
-
读写数据的批量batch处理以及压缩传输

传统文件复制方式: 需要对文件在内存中进行四次拷贝。

零拷贝: 有两种方式, mmap和transfile

Java当中对零拷贝进行了封装, Mmap方式通过MappedByteBuffer对象进行操作,而transfile通过FileChannel来进行操作。
Mmap 适合比较小的文件,通常文件大小不要超过1.5G ~2G 之间。
Transfile没有文件大小限制
在kafka当中,他的index日志文件也是通过mmap的方式来读写的。在其他日志文件当中,并没有使用零拷贝的方式。
kafka使用transfile方式将硬盘数据加载到网卡。
延时队列
延时队列存储的对象是延时消息。所谓的“延时消息”是指消息被发送以后,并不想让消费者立刻获取,而是等待特定的时间后,消费者
才能获取这个消息进行消费,延时队列的使用场景有很多, 比如 :
1)在订单系统中, 一个用户下单之后通常有 30 分钟的时间进行支付,如果 30 分钟之内没有支付成功,那么这个订单将进行异常处理,
这时就可以使用延时队列来处理这些订单了。
2)订单完成1小时后通知用户进行评价。
发送延时消息时先把消息按照不同的延迟时间段发送到指定的队列中(topic_1s,topic_5s,topic_10s,…,这个一般不能支持任意时间段的延时),然后通过定时器进行轮训消费这些topic,查看消息是否到期,如果到期就把这个消息发送到具体业务处理的topic中,队列中消息越靠前的到期时间越早,具体来说就是定时器在一次消费过程中,对消息的发送时间做判断,看下是否延迟到对 应时间了,如果到了就转发,如果还没到这一次定时任务就可以提前结束了。
生产者参数:
Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.65.60:9092,192.168.65.60:9093,192.168.65.60:9094");/*发出消息持久化机制参数(1)acks=0: 表示producer不需要等待任何broker确认收到消息的回复,就可以继续发送下一条消息。性能最高,但是最容易丢消息。(2)acks=1: 至少要等待leader已经成功将数据写入本地log,但是不需要等待所有follower是否成功写入。就可以继续发送下一条消息。这种情况下,如果follower没有成功备份数据,而此时leader又挂掉,则消息会丢失。(3)acks=-1或all: 需要等待 min.insync.replicas(默认为1,推荐配置大于等于2) 这个参数配置的副本个数都成功写入日志,这种策略会保证只要有一个备份存活就不会丢失数据。这是最强的数据保证。一般除非是金融级别,或跟钱打交道的场景才会使用这种配置。*/props.put(ProducerConfig.ACKS_CONFIG, "1");/*发送失败会重试,默认重试间隔100ms,重试能保证消息发送的可靠性,但是也可能造成消息重复发送,比如网络抖动,所以需要在接收者那边做好消息接收的幂等性处理*/props.put(ProducerConfig.RETRIES_CONFIG, 3);//重试间隔设置props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300);//设置发送消息的本地缓冲区,如果设置了该缓冲区,消息会先发送到本地缓冲区,可以提高消息发送性能,默认值是33554432,即32MBprops.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);/*kafka本地线程会从缓冲区取数据,批量发送到broker,设置批量发送消息的大小,默认值是16384,即16kb,就是说一个batch满了16kb就发送出去*/props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);/*默认值是0,意思就是消息必须立即被发送,但这样会影响性能一般设置10毫秒左右,就是说这个消息发送完后会进入本地的一个batch,如果10毫秒内,这个batch满了16kb就会随batch一起被发送出去如果10毫秒内,batch没满,那么也必须把消息发送出去,不能让消息的发送延迟时间太长*/props.put(ProducerConfig.LINGER_MS_CONFIG, 10);//把发送的key从字符串序列化为字节数组props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());//把发送消息value从字符串序列化为字节数组props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());Producer<String, String> producer = new KafkaProducer<String, String>(props);int msgNum = 5;final CountDownLatch countDownLatch = new CountDownLatch(msgNum);for (int i = 1; i <= msgNum; i++) {Order order = new Order(i, 100 + i, 1, 1000.00);//指定发送分区/*ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>(TOPIC_NAME, 0, order.getOrderId().toString(), JSON.toJSONString(order));*///未指定发送分区,具体发送的分区计算公式:hash(key)%partitionNumProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>(TOPIC_NAME, order.getOrderId().toString(), JSON.toJSONString(order));//等待消息发送成功的同步阻塞方法RecordMetadata metadata = producer.send(producerRecord).get();System.out.println("同步方式发送消息结果:" + "topic-" + metadata.topic() + "|partition-"+ metadata.partition() + "|offset-" + metadata.offset());//异步回调方式发送消息/*producer.send(producerRecord, new Callback() {public void onCompletion(RecordMetadata metadata, Exception exception) {if (exception != null) {System.err.println("发送消息失败:" + exception.getStackTrace());}if (metadata != null) {System.out.println("异步方式发送消息结果:" + "topic-" + metadata.topic() + "|partition-"+ metadata.partition() + "|offset-" + metadata.offset());}countDownLatch.countDown();}});*///送积分 TODO}
消费者参数:
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, “192.168.65.60:9092,192.168.65.60:9093,192.168.65.60:9094”);
// 消费分组名
props.put(ConsumerConfig.GROUP_ID_CONFIG, CONSUMER_GROUP_NAME);
// 是否自动提交offset,默认就是true
/props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, “true”);
// 自动提交offset的间隔时间
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, “1000”);/
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, “false”);
/*
当消费主题的是一个新的消费组,或者指定offset的消费方式,offset不存在,那么应该如何消费
latest(默认) :只消费自己启动之后发送到主题的消息
earliest:第一次从头开始消费,以后按照消费offset记录继续消费,这个需要区别于consumer.seekToBeginning(每次都从头开始消费)
/
//props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, “earliest”);
/
consumer给broker发送心跳的间隔时间,broker接收到心跳如果此时有rebalance发生会通过心跳响应将
rebalance方案下发给consumer,这个时间可以稍微短一点
/
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 1000);
/
服务端broker多久感知不到一个consumer心跳就认为他故障了,会将其踢出消费组,
对应的Partition也会被重新分配给其他consumer,默认是10秒
*/
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10 * 1000);
//一次poll最大拉取消息的条数,如果消费者处理速度很快,可以设置大点,如果处理速度一般,可以设置小点props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 50);/*如果两次poll操作间隔超过了这个时间,broker就会认为这个consumer处理能力太弱,会将其踢出消费组,将分区分配给别的consumer消费*/props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 30 * 1000);props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);consumer.subscribe(Arrays.asList(TOPIC_NAME));// 消费指定分区//consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));//消息回溯消费/*consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));consumer.seekToBeginning(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));*///指定offset消费/*consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));consumer.seek(new TopicPartition(TOPIC_NAME, 0), 10);*///从指定时间点开始消费/*List<PartitionInfo> topicPartitions = consumer.partitionsFor(TOPIC_NAME);//从1小时前开始消费long fetchDataTime = new Date().getTime() - 1000 * 60 * 60;Map<TopicPartition, Long> map = new HashMap<>();for (PartitionInfo par : topicPartitions) {map.put(new TopicPartition(TOPIC_NAME, par.partition()), fetchDataTime);}Map<TopicPartition, OffsetAndTimestamp> parMap = consumer.offsetsForTimes(map);for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry : parMap.entrySet()) {TopicPartition key = entry.getKey();OffsetAndTimestamp value = entry.getValue();if (key == null || value == null) continue;Long offset = value.offset();System.out.println("partition-" + key.partition() + "|offset-" + offset);System.out.println();//根据消费里的timestamp确定offsetif (value != null) {consumer.assign(Arrays.asList(key));consumer.seek(key, offset);}}*/while (true) {/** poll() API 是拉取消息的长轮询*/ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.printf("收到消息:partition = %d,offset = %d, key = %s, value = %s%n", record.partition(),record.offset(), record.key(), record.value());}if (records.count() > 0) {// 手动同步提交offset,当前线程会阻塞直到offset提交成功// 一般使用同步提交,因为提交之后一般也没有什么逻辑代码了//consumer.commitSync();// 手动异步提交offset,当前线程提交offset不会阻塞,可以继续处理后面的程序逻辑/*consumer.commitAsync(new OffsetCommitCallback() {@Overridepublic void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {if (exception != null) {System.err.println("Commit failed for " + offsets);System.err.println("Commit failed exception: " + exception.getStackTrace());}}});*/}





![[SpringCloud] Feign 与 Gateway 简介](https://img-blog.csdnimg.cn/032ba859f0e24db0bd966cf218e136ab.png)