目录:
- 为什么要使用Python做数据开发
- Python在数据开发领域的优势
- 为什么要学习Pandas
- 其他常用Python库介绍
- 主要内容介绍
- Anaconda安装
- Anaconda的虚拟环境管理
- 虚拟环境的作用
- 可以通过Anaconda界面创建虚拟环境
- 通过命令行创建虚拟环境
- 通过Anaconda管理界面安装包
- 也可以通过anaconda3提供的CMD终端工具进行python包的安装
- 启动 Jupyter Notebook
- 可以通过Anaconda启动 Jupyter Notebook
- 推荐通过终端启动 Jupyter Notebook
- Jupyter notebook的功能扩展
- Jupyter Notebook的界面
- Jupyter Notebook常用快捷键
- Jupyter Notebook中使用Markdown
- 切换JupyterNotebook启动路径
- Jupyter Notebook快捷键
- 对比中日两国的GDP变化曲线
- 对比中美日三国GDP变化曲线
- 解决中文不能在图表中正常显示的问题
- 总结
- 项目地址
1.为什么要使用Python做数据开发
- 易学易用:Python的语法清晰简洁,易于理解,使得开发者能够快速上手并快速开发出原型。Python还提供了大量的第三方库,使得开发过程更加便捷。
- 高效的数据处理能力:Python具有强大的数据处理能力,特别是利用numpy、pandas等库进行科学计算和数据处理。这些库使得Python在数据开发领域具有很大的优势。
- 广泛的社区支持:Python有一个庞大的开发者社区,可以为开发者提供丰富的资源和支持。例如,有许多开源的数据分析库和框架(如numpy、pandas、scipy、matplotlib等)都是用Python编写的,这使得Python在数据开发领域具有很高的灵活性。
- 跨平台性:Python可以在多种操作系统(如Windows、Linux、Mac OS等)上运行,使得开发过程更加便捷。
- 可扩展性:Python可以轻松地与其他语言(如C++、Java等)进行集成,使得开发过程更加灵活。
- 应用广泛:Python在数据科学、机器学习、自然语言处理等领域都有广泛的应用,使得Python在数据开发领域具有很高的价值。
- 丰富的数据处理工具:Python提供了丰富的数据处理工具,如Jupyter Notebook、matplotlib等,可以帮助开发者更好地理解和分析数据。
2.Python在数据开发领域的优势
- Python作为当下最为流行的编程语言之一,可以独立完成数据开发的各种任务:
-
语言本身就简单易学,书写代码简单快速
-
同时在数据分析以及大数据领域里有海量的功能强大的开源库,并持续更新
-
Pandas - 数据清洗、数据处理、数据分析
-
Sklearn - 机器学习、统计分析
-
PySpark - Spark使用Python
-
PyFlink - Flink使用Python
-
Matplotlib、Seaborn、Pyecharts - 出图表
-
-
3.为什么要学习Pandas
Python在数据处理上独步天下:代码灵活、开发快速;尤其是Python的Pandas包,无论是在数据分析领域、还是大数据开发场景中都具有显著的优势:
-
Pandas是Python的一个第三方包,也是商业和工程领域最流行的结构化数据工具集,用于数据清洗、处理以及分析
-
Pandas和Spark中很多功能都类似,甚至使用方法都是相同的;当我们学会Pandas之后,再学习Spark就更加简单快速
-
Pandas在整个数据开发的流程中的应用场景
-
在大数据场景下,数据在流转的过程中,Python Pandas丰富的API能够更加灵活、快速的对数据进行清洗和处理
-
-
Pandas在数据处理上具有独特的优势:
-
底层是基于Numpy构建的,所以运行速度特别的快
-
有专门的处理缺失数据的API
-
强大而灵活的分组、聚合、转换功能
-

-
数据量大到excel严重卡顿,且又都是单机数据的时候,我们使用pandas
-
在大数据ETL数据仓库中,对数据进行清洗及处理的环节使用pandas
4.其他常用Python库介绍
在数据分析、数据开发领域,除了Pandas还有其他常用的一些库,如下
-
NumPy(Numerical Python) :是 Python 语言的一个扩展程序库;运行速度非常快,主要用于数组计算
-
Matplotlib 是一个功能强大的数据可视化开源Python库
-
Seaborn 是一个Python数据可视化开源库;建立在matplotlib之上,并集成了pandas的数据结构
-
Pyecharts 是基于百度的echarts的Python开源库,有完整丰富的中文文档及示例
-
Sklearn,即scikit-learn 是基于 Python 语言的机器学习工具,经常用于统计分析计算
-
PySpark 是 Spark 为 Python 开发者提供的 API,具有Spark全部的API功能
5.主要内容介绍
-
Pandas基础知识
-
pandas数据结构
-
索引与列名的操作
-
增删改dataframe中的数据
-
查询dataframe中的数据
-
pandas中常用计算函数
-
-
数据清洗与处理
-
dataframe缺失值处理
-
pandas中数据类型详解
-
dataframe分组与分箱
-
dataframe合并与变形
-
-
保存数据与数据可视化
-
dataframe的读取与保存
-
图表可视化
-
6.Anaconda安装
-
Anaconda是什么?
-
Anaconda 是最流行的数据分析平台,全球两千多万人在使用
-
Anaconda 附带了一大批常用数据科学包,不光自带Python还集成150 多个科学包及其依赖项(默认的base环境)
-
Anaconda 是在 Conda(一个包管理器和环境管理器)上发展出来的
-
Conda可以帮助你在计算机上安装和管理数据分析相关包
-
Anaconda的仓库中包含了7000多个数据科学相关的开源库
-
-
Anaconda 包含了虚拟环境管理工具,通过虚拟环境可以使不同的Python或者开源库的版本同时存在
-
Anaconda 可用于多个平台( Windows、Mac OS X 和 Linux)
-
-
Jupyter Notebook是什么?
-
我们平时使用Anaconda 自带的jupyter notebook来进行开发,Anaconda 是工具管理器,jupyter notebook是代码编辑器(类似于pycharm,但jupyter notebook是基于html网页运行的)
-
7.Anaconda的虚拟环境管理
-
不同的python项目,可能使用了各自不同的python的包、模块;
-
不同的python项目,可能使用了相同的python的包、模块,但版本不同;
-
不同的python项目,甚至使用的Python的版本都是不同;
为了让避免项目所使用的Python及包模块版本冲突,所以需要代码运行的依赖环境彼此分开,业内有各种各样的成熟解决方案,但原理都是一样的:不同项目代码的运行,使用保存在不同路径下的python和各自的包模块;不同位置的python解释器和包模块就称之为虚拟环境,具体关系图如下:

虚拟环境的本质,就是在你电脑里安装了多个Python解释器(可执行程序),每个Python解释器又关联了很多个包、模块;项目代码在运行时,是使用特定路径下的那个Python解释器来执行
8.虚拟环境的作用
-
很多开源库版本升级后API有变化,老版本的代码不能在新版本中运行
-
将不同Python版本/相同开源库的不同版本隔离
-
不同版本的代码在不同的虚拟环境中运行
9.可以通过Anaconda界面创建虚拟环境

10.通过命令行创建虚拟环境
- 在anaconda管理界面打开cmd命令行终端
- 命令行终端对虚拟环境的操作命令如下
conda create -n 虚拟环境名字 python=3.8 #创建虚拟环境 python=3.8 指定python版本
conda activate 虚拟环境名字 #进入虚拟环境
conda deactivate #退出虚拟环境
conda remove -n 虚拟环境名字 --all #删除虚拟环境,不要在当前的虚拟环境中删除当前的虚拟环境,会报错
conda env list #查看虚拟环境11.通过Anaconda管理界面安装包
- 点击Environment选项卡,进入到环境管理界面,通过当前管理界面安装python的包模块

12.也可以通过anaconda3提供的CMD终端工具进行python包的安装
-
在anaconda管理界面打开cmd命令行终端

- 可以通过conda install 安装【不推荐】
- conda install 包名字
- 但更推荐使用pip命令来安装python的第三方包【推荐】
- pip install 包名字
- 安装其他包速度慢可以指定国内镜像
# 阿里云:https://mirrors.aliyun.com/pypi/simple/
# 豆瓣:https://pypi.douban.com/simple/
# 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/
# 中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/pip install 包名 -i https://mirrors.aliyun.com/pypi/simple/ #通过阿里云镜像安装13.启动 Jupyter Notebook
- 推荐使用命令行终端打开Jupyter Notebook
14.可以通过Anaconda启动 Jupyter Notebook

15.推荐通过终端启动 Jupyter Notebook
- 这种方式先启动cmd,通过切换虚拟环境和磁盘位置,再启动Jupyter notebook
-
在启动anaconda提供的CMD启动后,输入命令如下
# 可选操作,切换虚拟环境,使用不同的python解释器和包
conda activate 虚拟环境名字 # 切换磁盘位置,可选操作
cd d:/
d:# 启动jupyter notebook
jupyter notebook-
上述操作如下图所示

-
此时浏览器会自动打开jupyter notebook

16.Jupyter notebook的功能扩展
- 在启动anaconda提供的CMD启动后,安装jupyter_contrib_nbextensions库,在CMD中输入下列命令
#进入到虚拟环境中
conda activate 虚拟环境名字
#安装 jupyter_contrib_nbextensions
pip install jupyter_contrib_nbextensions
#jupyter notebook安装插件
jupyter contrib nbextension install --user --skip-running-check- 安装结束后启动jupyter notebook

- 配置扩展功能,在原来的基础上勾选: “Table of Contents” 以及 “Hinterland”

17.Jupyter Notebook的界面
- 新建notebook文档
- 注意:Jupyter Notebook 文档的扩展名为
.ipynb,与我们正常熟知的.py后缀不同

- 新建文件之后会打开Notebook界面

- 菜单栏中相关按钮功能介绍:
- Jupyter Notebook的代码的输入框和输出显示的结果都称之为cell,cell行号前的 * ,表示代码正在运行

18.Jupyter Notebook常用快捷键
Jupyter Notebook中分为两种模式:命令模式和编辑模式
-
两种模式通用快捷键
-
Shift+Enter,执行本单元代码,并跳转到下一单元 -
Ctrl+Enter,执行本单元代码,留在本单元
-
-
按ESC进入命令模式

-
Y,cell切换到Code模式 -
M,cell切换到Markdown模式 -
A,在当前cell的上面添加cell -
B,在当前cell的下面添加cell -
双击D:删除当前cell - 编辑模式:按Enter进入,或鼠标点击代码编辑框体的输入区域

-
回退:
Ctrl+Z(Mac:CMD+Z) -
重做:
Ctrl+Y(Mac:CMD+Y) -
补全代码:变量、方法后跟
Tab键 -
为一行或多行代码添加/取消注释:
Ctrl+/(Mac:CMD+/)
19.Jupyter Notebook中使用Markdown
-
在命令模式中,按M即可进入到Markdown编辑模式
-
使用Markdown语法可以在代码间穿插格式化的文本作为说明文字或笔记
-
Markdown基本语法:标题和缩进

-
效果如下图所示

-
可以查看文件中的目录(大纲)

20.切换JupyterNotebook启动路径
-
JupyterNotebook启动之后默认路径是在C盘的根路径,但很多时候我们想在别的路径创建或操作ipynb文件:打开Anaconda提供的CMD终端并切换路径,此时再启动jupyter notebook即可;比如此时我们想切换到D盘下的某个路径再启动
(base) C:\Users\windows10>D:
(base) D:\>cd D:\数据分析课程v1.6\05-新版3天版Pandas\代码
(base) D:\数据分析课程v1.6\05-新版3天版Pandas\代码>jupyter notebook-
此时就会自动在浏览器中打开JupyterNotebook编辑器
21.Jupyter Notebook快捷键


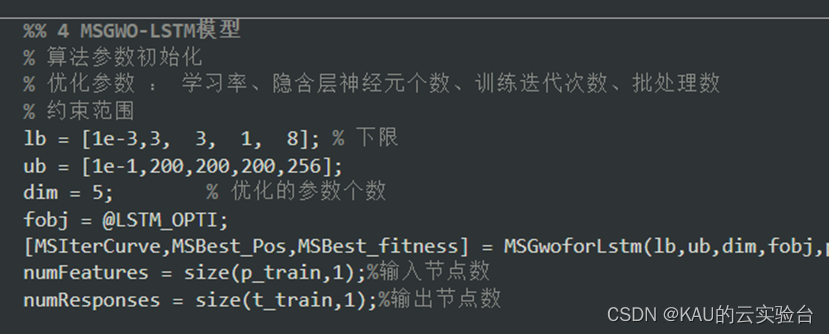
22.对比中日两国的GDP变化曲线
# 导包并加载数据
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('../datas/data_set/1960-2019全球GDP数据.csv', encoding='gbk')
# 显示全部数据
print(df)# 查询中国的GDP
china_gdp = df[df.country=='中国'] # df.country 选中列名为country的列
# 显示前10条数据,默认查看前5条数据
print(china_gdp.head(10))# 将year年份设为索引
china_gdp = china_gdp.set_index('year')
# 默认显示前5条
print(china_gdp.head())# 画出GDP逐年变化的曲线图
china_gdp.GDP.plot()
plt.show()# 使用同样的方法画出日本的GDP变化曲线,和中国的GDP变化曲线进行对比
jp_gdp = df[df.country=='日本'].set_index('year') # 按条件选取数据后,重设索引
jp_gdp.GDP.plot()
china_gdp.GDP.plot()
plt.show()23.对比中美日三国GDP变化曲线
# 分别查询中国、美国、日本三国的GDP数据,并绘制GDP变化曲线、进行对比
import pandas as pd
import matplotlib.pyplot as pltdf = pd.read_csv('../datas/data_set/1960-2019全球GDP数据.csv', encoding='gbk')china_gdp = df[df.country == '中国'].set_index('year')
us_gdp = df[df.country == '美国'].set_index('year')
jp_gdp = df[df.country == '日本'].set_index('year')
jp_gdp.GDP.plot()
china_gdp.GDP.plot()
us_gdp.GDP.plot()
plt.show()# 设置图例
# 按条件选取数据
china_gdp = df[df.country=='中国'].set_index('year')
us_gdp = df[df.country=='美国'].set_index('year')
jp_gdp = df[df.country=='日本'].set_index('year')
# 出图并添加图例
jp_gdp.GDP.plot(legend=True)
china_gdp.GDP.plot(legend=True)
us_gdp.GDP.plot(legend=True)
plt.show()# 修改列名使图例显示为各国名称
# 按条件选取数据
china_gdp = df[df.country=='中国'].set_index('year')
us_gdp = df[df.country=='美国'].set_index('year')
jp_gdp = df[df.country=='日本'].set_index('year')
# 对指定的列修改列名
jp_gdp.rename(columns={'GDP':'japan'}, inplace=True)
china_gdp.rename(columns={'GDP':'china'}, inplace=True)
us_gdp.rename(columns={'GDP':'usa'}, inplace=True)
# 画图
jp_gdp.japan.plot(legend=True)
china_gdp.china.plot(legend=True)
us_gdp.usa.plot(legend=True)
plt.show()24.解决中文不能在图表中正常显示的问题
# 按条件选取数据
china_gdp = df[df.country=='中国'].set_index('year')
us_gdp = df[df.country=='美国'].set_index('year')
jp_gdp = df[df.country=='日本'].set_index('year')
# 对指定的列修改列名
jp_gdp.rename(columns={'GDP':'日本'}, inplace=True)
china_gdp.rename(columns={'GDP':'中国'}, inplace=True)
us_gdp.rename(columns={'GDP':'美国'}, inplace=True)
# 画图
jp_gdp['日本'].plot(legend=True)
china_gdp['中国'].plot(legend=True)
us_gdp['美国'].plot(legend=True)# 解决中文显示问题,下面的代码只需运行一次即可
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 如果没有黑体字体可以换个字体 楷体:KaiTi
mpl.rcParams['font.serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 解决负号不显示问题25.总结
-
Python Pandas的作用:清洗、处理、分析数据
-
Pandas环境搭建:
-
安装Anaconda,默认自带Python以及其他相关三方包
-
使用默认的base虚拟环境启动
Jupyter Notebook
-
26.项目地址
Python: 66666666666666 - Gitee.com