推荐稳定扩散AI自动纹理工具:DreamTexture.js自动纹理化开发包
1、稳定扩散介绍
通过将图像形成过程分解为去噪自动编码器的顺序应用,扩散模型 (DM) 在图像数据及其他数据上实现了最先进的合成结果。此外,它们的配方允许将它们应用于图像修改任务,例如直接修复,而无需重新训练。然而,由于这些模型通常直接在像素空间中运行,因此优化强大的 DM 通常需要花费数百个 GPU 天,并且由于顺序评估,推理成本很高。为了在有限的计算资源上实现 DM 训练,同时保持其质量和灵活性,我们将它们应用于强大的预训练自动编码器的潜在空间。与以前的工作相比,在这种表示上训练扩散模型首次允许在复杂性降低和空间下采样之间达到接近最佳点,从而大大提高了视觉保真度。通过在模型架构中引入交叉注意力层,我们将扩散模型转化为强大而灵活的生成器,用于一般条件输入,如文本或边界框,并以卷积方式实现高分辨率合成。与基于像素的 DM 相比,我们的潜在扩散模型 (LDM) 在各种任务上都实现了极具竞争力的性能,包括无条件图像生成、修复和超分辨率,同时显注降低了计算要求。
2、基于稳定扩散的进一步研究

图1.通过减少激进的下采样,提高可实现的质量上限。由于扩散模型为空间数据提供了出色的归纳偏差,因此我们不需要在潜在空间中对相关生成模型进行大量空间下采样,但仍然可以通过合适的自编码模型大大降低数据的维数,参见第 3 节。图像来自 DIV2K [1] 验证集,评估值为 5122 像素。我们用 f 表示空间下采样因子。重建FIDs[26]和PSNR在ImageNet-val上计算。[11]

图2.说明感知和语义压缩:数字图像的大多数位对应于难以察觉的细节。虽然 DM 允许通过最小化负责任的损失项来抑制这种语义上无意义的信息,但梯度(在训练期间)和神经网络主干(训练和推理)仍然需要在所有像素上进行评估,从而导致多余的计算和不必要的昂贵优化和推理。我们提出了潜在扩散模型(LDM)作为有效的生成模型和一个单独的轻度压缩阶段,仅消除难以察觉的细节。
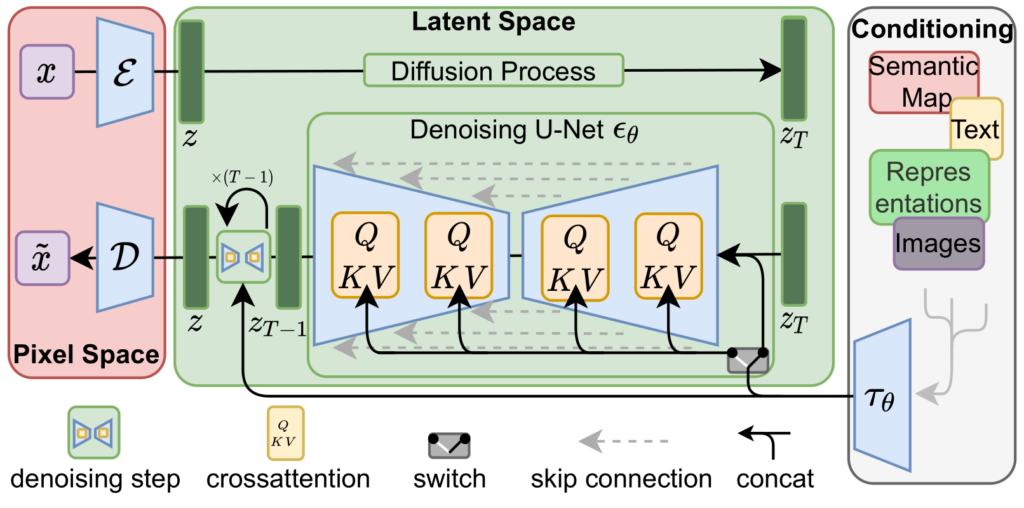
图3.我们通过串联或更通用的交叉注意力机制来调节 LDM。

图4.在CelebAHQ [35]、FFHQ [37]、LSUN-Churches [95]、LSUN-Bedrooms [95]和类条件ImageNet [11]上训练的LDM样本,每个样本的分辨率为256×256。
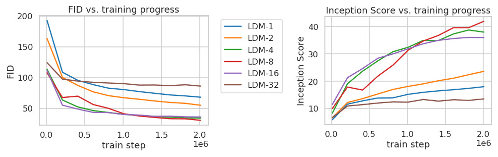
图5.在ImageNet数据集上分析具有不同下采样因子的类条件LDM的训练,超过2M个训练步。与具有较大下采样因子 (LDM–1) 的模型相比,基于像素的 LDM-12 需要更长的训练时间。LDM-32 中过多的感知压缩会限制整体样品质量。所有模型均在具有相同计算预算的单个 NVIDIA A100 上进行训练。使用100个DDIM步骤[79]和κ = 0获得的结果。
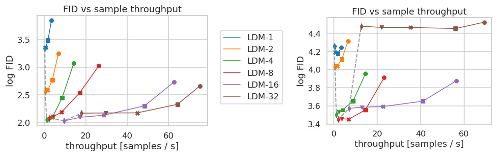
图6.推理速度与样本质量:在 CelebA-HQ(左)和 ImageNet(右)数据集上比较具有不同压缩量的 LDM。不同的标记表示 DDIM 采样器的 200 个采样步骤,沿每条线从右到左计数。虚线显示了 200 步的 FID 分数,表示与具有不同压缩比的模型相比,LDM-4 具有更强的性能。对 5000 个样本评估的 FID 分数。所有模型均在 A500 上进行了 2k (CelebA) / 100M (ImageNet) 步长的训练。

图7.上图:我们的LDM样本,用于在COCO上进行布局到图像合成[4]。补充中的定量评估。底部:来自文本到图像 LDM 的示例,用于用户定义的文本提示。我们的模型在LAION [73]数据库上进行了预训练,并在Conceptual Captions [74]数据集上进行了微调。

图8.在 2562 分辨率上训练的 LDM 可以泛化为更大的分辨率(此处:512×1024),用于空间条件任务,例如景观图像的语义合成。参见第 4.3.2 节。

图 9.LDM-BSR 泛化为任意输入,可用作通用上采样器,从类条件 LDM 中放大样本(图 cf .图4)至10242分辨率。相反,使用固定的降解过程(见第 4.4 节)会阻碍泛化。

图 10.ImageNet-Val 上的 ImageNet 64→256 超分辨率。LDM-SR 在渲染逼真的纹理方面具有优势,但 SR3 可以合成更连贯的精细结构。有关其他样本和裁剪,请参阅附录。SR3 的结果来自 [67]。

图 11.图像修复的定性结果如表6所示。

Figure 12. Qualitative results on object removal with our big, w/ ft inpainting model. For more results, see Fig. 22.

图 13.来自语义景观模型的卷积样本,如第 4.3.2 节,对 5122 张图像进行了微调。

图 14.在景观上,使用无条件模型的卷积采样会导致均匀和不连贯的全局结构(见第 2 列)。使用低分辨率图像的 L2 引导有助于重建连贯的全局结构。

图 15.这里说明了潜在空间重新缩放对卷积采样的影响,这里用于景观的语义图像合成。参见第 4.3.2 节和第 C.1 节。

图 16.来自我们用于布局到图像合成的最佳模型 LDM-4 的更多样本,该模型在 OpenImages 数据集上进行了训练,并在 COCO 数据集上进行了微调。使用 100 个 DDIM 步骤生成的样本,η = 0。布局来自 COCO 验证集。

图 17.来自我们最好的文本到图像合成模型 LDM-4 的用户定义文本提示的更多示例,该模型在 LAION 数据库上进行了训练,并在 Conceptual Captions 数据集上进行了微调。使用 100 个 DDIM 步骤生成的样本,η = 0。
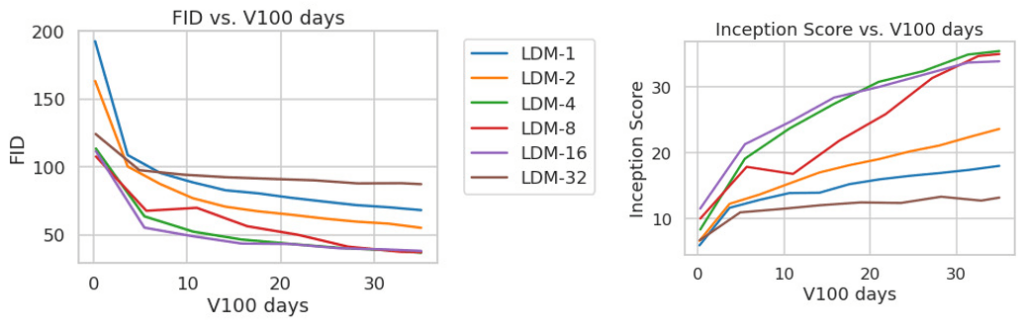
图 18.为了完整起见,我们还报告了 ImageNet 数据集上类条件 LDM 的训练进度,固定数量为 35 V100 天。使用100个DDIM步骤[79]和κ = 0获得的结果。出于效率原因,在 5000 个样本上计算了 FID。

图 19.LDM-BSR 泛化为任意输入,可用作通用上采样器,将 LSUNCows 数据集中的样本放大到 10242 分辨率。

图 20.Pixelspace 中 LDM-SR 和基线扩散模型之间两个随机样本的定性超分辨率比较。在相同数量的训练步骤后在 imagenet validation-set 上进行评估。

图 21.图像修复的更多定性结果如图 11 所示。

Figure 22. More qualitative results on object removal as in Fig. 12.

Figure 23. Convolutional samples from the semantic landscapes model as in Sec. 4.3.2, finetuned on 5122 images.

Figure 24. A LDM trained on 2562 resolution can generalize to larger resolution for spatially conditioned tasks such as semantic synthesis of landscape images. See Sec. 4.3.2.

图 25.当提供语义图作为条件反射时,我们的 LDM 泛化到比训练期间看到的分辨率大得多的分辨率。尽管此模型是在大小为 256² 的输入上训练的,但它可用于创建高分辨率样本,如下所示,分辨率为 1024×384。

图 26.来自 ImageNet 数据集上 LDM-8-G 的随机样本。使用分类器尺度 [14] 50 和 100 DDIM 步长进行采样,η = 1。(FID 8.5)。

图 27.来自 ImageNet 数据集上 LDM-8-G 的随机样本。使用分类器尺度 [14] 50 和 100 DDIM 步长进行采样,η = 1。(FID 8.5)。

图 28.来自 ImageNet 数据集上 LDM-8-G 的随机样本。使用分类器尺度 [14] 50 和 100 DDIM 步长进行采样,η = 1。(FID 8.5)。

图 29.我们在 CelebA-HQ 数据集上表现最佳的模型 LDM-4 的随机样本。使用 500 个 DDIM 步长采样,η = 0 (FID = 5.15)。

图 30.我们在 FFHQ 数据集上表现最佳的模型 LDM-4 的随机样本。使用 200 个 DDIM 步长进行采样,η = 1 (FID = 4.98)。

图31。LSUN Churches数据集上我们性能最好的LDM-8模型的随机样本。用200个DDIM步骤取样,η=0(FID=4.48)。

图32。LSUN Bedrooms数据集上性能最好的LDM-4模型的随机样本。用200个DDIM步骤取样,η=1(FID=2.95)。

图 33.我们最好的CelebA-HQ模型的最近邻,在VGG-16的特征空间中计算[75]。最左边的样本来自我们的模型。每行中的剩余样本是其 10 个最近邻。

图 34.我们最好的FFHQ模型的最近邻,在VGG-16的特征空间中计算[75]。最左边的样本来自我们的模型。每行中的剩余样本是其 10 个最近邻。

图 35.我们最好的LSUN-Churches模型的最近邻,在VGG-16的特征空间中计算[75]。最左边的样本来自我们的模型。每行中的剩余样本是其 10 个最近邻。
转载:稳定扩散的高分辨率图像合成 (mvrlink.com)