PyTorch深度学习实战(24)——从零开始实现Mask R-CNN实例分割
- 0. 前言
- 1. Mask R-CNN
- 1.1 网络架构
- 1.2 RoI Align
- 1.3 Mask 检测头
- 2. 使用 Mask R-CNN 实现实例分割
- 2.1 数据集分析
- 2.2 模型构建策略
- 2.3 模型构建与训练
- 3. 多类别实例分割
- 小结
- 系列链接
0. 前言
Mask R-CNN (Mask Region Convolutional Neural Network) 是基于深度学习的图像分割算法,它是在 Faster R-CNN 目标检测框架的基础上进行扩展和改进的。与传统目标检测方法相比,Mask R-CNN 不仅可以准确地检测图像中的对象,还可以为每个对象生成精确的像素级别的分割掩码。这意味着 Mask R-CNN 能够同时提供对象的边界框和具体的像素级别分割结果,从而更细粒度地理解图像中的结构和语义信息。在本节,将介绍 Mask R-CNN 架构的工作原理,并使用 PyTorch 实现 Mask R-CNN 进行实例分割。
1. Mask R-CNN
1.1 网络架构
Mask R-CNN 是一种用于目标检测和实例分割的深度学习算法,它扩展了 Faster R-CNN 算法,并增加了一个用于预测对象掩码 (mask) 的分支。
Mask R-CNN 架构可以用于在图像中识别/显示给定类别的对象实例,能够分割图像中类别相同的多个对象,Mask 表示由 Mask R-CNN 在像素级别完成的分割。掩码用于标注图像中的不同区域,使用图像分割模型可以将图像分成不同的区域,然后为每个区域分配一个掩码值。
Mask R-CNN 架构是对 Faster R-CNN 网络的扩展:
Mask R-CNN架构修改了Faster R-CNN的RoI Pooling层,使用更加准确的RoI Align层- 除了在最终层中预测对象的类别和边界框偏移量外,还增加了一个
mask head,用于预测对象的掩码 - 使用全卷积网络 (
Fully Convolutional Network,FCN) 实现掩码预测。
Mask R-CNN 整体架构如下:

除了用于获取类别和边界框信息的预测头外,在 Mask R-CNN 中还添加了 Mask 预测头 (Mask head) 获取掩码信息:

接下来,我们介绍 Mask R-CNN 架构的基本组件。
1.2 RoI Align
在 Faster R-CNN 中,我们了解了 RoI Pooling 的缺点之一是在执行 RoI Pooling 操作时可能会丢失某些信息。例如,在下图 RoI Pooling 示例中:

在上图中,区域提议形状为 5 x 7,需要将其转换为 2 x 2 的形状,将其转换为 2 x 2 形状时(这一过程也称为量化),由于仅能保留最高值,因此会导致信息丢失,为了解决这一问题,提出了 RoI Align。
接下来,我们通过一个简单示例讲解 RoI Align 的工作原理,尝试将以下区域(以虚线表示)转换为 2 x 2 的形状:

该区域并非均匀分布在特征图中的所有单元格中。为了能够使用 2x2 的形状合理表示该区域,我们需要执行以下步骤。
(1) 首先,将该区域划分为形状相等的 2 x 2 网格:

(2) 在每个单元格中定义四个等距的点:

在上图中,两个连续点之间的距离为 0.75。
(3) 根据每个点到最近已知值的距离计算其加权平均值:

(4) 对单元格中的所有点重复以上加权均值计算过程:

(5) 对单元格中的点执行平均池化,并根据相同步骤计算所有单元格值:

可以看到,通过以上步骤 RoI Align 能够确保不会丢失信息。
1.3 Mask 检测头
使用 RoI Align,我们可以更准确地表示从区域提议网络 (Region Proposal Network, RPN) 获得的区域提议。然后,对于每个区域提议,根据 RoI Align 输出获取分割(掩码)输出。
在目标检测中,需要将 RoI Align 结果输入到展平层,用于预测目标物体的类别和边界框偏移量。在图像分割中,还需要预测包含目标对象的边界框内的像素。因此,除了类别和边界框偏移量外,还需要预测感兴趣区域内的掩码。
将预测的掩码叠加在原始图像上,将 RoI Align 的输出连接到卷积层上,以获得类似图像的结构,如下图所示:

在上图中,使用特征金字塔网络 (feature pyramid network, FPN) 得到形状为 7 x 7 x 2048 的输出,该网络包含 2 个分支:
- 第一个分支在展平
FPN输出后返回目标对象的类别和边界框 - 第二个分支在
FPN的输出后执行卷积运算以获得掩码
形状为 14 x 14 输出对应的真实标签是区域提议对应的调整大小后图像。如果数据集中有 80 个不同的类别,则区域提议的真实标签形状为 80 x 14 x 14,每个像素值都是 1 或 0,表示该像素是否包含对象。因此,在预测像素类别的同时使用二元交叉熵损失函数。
模型训练完成后,可以用于检测区域,获取类别和边界框偏移量,并获取每个区域对应的掩码。在模型推理阶段时,首先检测图像中存在的目标对象并进行边界框校正,然后,将校正后的区域传递给 Mask 检测头,以预测该区域中不同像素对应的掩码。
了解了 Mask R-CNN 架构的工作原理后,我们将使用 PyTorch 实现 Mask R-CNN,以检测图像中的人物实例。
2. 使用 Mask R-CNN 实现实例分割
2.1 数据集分析
为了训练 Mask R-CNN 进行实例分割,我们将使用掩码标注的人物数据集,该数据集是根据 DE20K 数据集的子集创建的,可以在 ADE20K 数据集官方网站中下载该数据集,DE20K 数据集是一个大规模的图像和语义分割数据集,该数据集包含超过 `20,000 张高分辨率图像,覆盖了各种多样的场景和对象类别。本节中,我们只使用包含人物掩码的图像。
2.2 模型构建策略
为了训练 Mask R-CNN 图像分割模型,我们采用以下策略:
- 获取数据集,并据此创建数据集和数据加载器
- 创建符合
PyTorch官方的Mask R-CNN实现所需格式的目标输出 - 下载预训练的
Faster R-CNN模型,并为其附加一个Mask R-CNN预测头 - 训练模型
Mask R-CNN模型 - 首先执行非极大值抑制,然后识别与图像中的人物对应的边界框和掩码
2.3 模型构建与训练
(1) 下载相关的数据集和模型训练工具。
为了训练模型,首先下载图像及掩码标注数据集,下载完成后解压文件。同时,为了快速训练模型,在 PyTorch GitHub 存储库中下载 engine.py、utils.py、transforms.py、coco_eval.py 和 coco_utils.py 文件。最后,使用 pip 安装 cocoapi:
$ pip install -q -U 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
(2) 导入所有必要的库并定义设备:
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection.mask_rcnn import MaskRCNNPredictor
from glob import globfrom engine import train_one_epoch, evaluate
import utils
import transforms as T
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
import cv2
import numpy as np
from matplotlib import pyplot as plt
import random
from PIL import Image
from torch.utils.data import DataLoader, Dataset
(3) 获取包含人物掩码的图片。
遍历 images 和 annotations_instance 文件夹以获取文件名:
all_images = glob('images/training/*.jpg')
all_annots = glob('annotations_instance/training/*.png')
检查原始图像和人物实例的掩码表示:
f = 'ADE_train_00014184'def find(item, original_list):results = []for o_i in original_list:if item in o_i:results.append(o_i)if len(results) == 1:print(results)return results[0]else:return resultsim = cv2.imread(find(f, all_images), 1)
an = cv2.imread(find(f, all_annots), 1).transpose(2,0,1)
r,g,b = an
nzs = np.nonzero(b==4) # 4 stands for person
instances = np.unique(g[nzs])
masks = np.zeros((len(instances), *r.shape))
for ix,_id in enumerate(instances):masks[ix] = g ==_idlength = len(masks)+1
plt.subplot(1, length, 1)
plt.imshow(cv2.cvtColor(im, cv2.COLOR_BGR2RGB))
ix = 2
for m in masks:plt.subplot(1, length, ix)plt.imshow(m, cmap='gray')ix += 1
plt.show()

在该数据集中,对象实例以如下方式进行标注,RGB 中的红色通道对应于对象的类别,而绿色通道对应于实例编号(如果图像中有多个相同类别的对象)图像。此外,在数据集中,Person 类别的编码值为 4。
循环遍历标注文件并存储至少包含一个人物的文件:
annots = []
for ann in all_annots:_ann = cv2.imread(ann, 1).transpose(2,0,1)r,g,b = _annif 4 not in np.unique(b):continueannots.append(ann)
读取图像的 R 通道获取掩码,然后遍历掩码并检查掩码中是否至少有一个像素值为 4 (人物类别),如果存在值为 4 的像素,就将该图像的文件名添加到包含人物的文件列表中。
将数据文件拆分为训练和验证数据:
def stems(split):items_new = [item.split('/')[-1] for item in split]items = [item.split('.')[0] for item in items_new]return itemsfrom sklearn.model_selection import train_test_split
_annots = stems(annots)trn_items, val_items = train_test_split(_annots, random_state=2)
(4) 定义图像变换方法:
def get_transform(train):image_transforms = []image_transforms.append(T.PILToTensor())return T.Compose(image_transforms)
(5) 创建数据集类 MasksDataset。
定义 __init__ 方法,将图像名称 (items)、图像变换方法 (transforms) 和所用文件数 (N) 作为输入:
class MasksDataset(Dataset):def __init__(self, items, transforms, N):self.items = itemsself.transforms = transformsself.N = N
定义 get_mask 方法,获取与图像中存在的实例数量相同的多个掩码:
def get_mask(self, path):an = cv2.imread(path, 1).transpose(2,0,1)r,g,b = annzs = np.nonzero(b==4)instances = np.unique(g[nzs])masks = np.zeros((len(instances), *r.shape))for ix,_id in enumerate(instances):masks[ix] = g == _idreturn masks
定义 __getitem__ 方法,获取所需返回的图像和相应的目标值。每个人物(实例)都被视为不同的对象类别,也就是说,每个实例都是一个不同的类别。与 Faster R-CNN 模型类似,目标值以张量字典的形式返回:
def __getitem__(self, ix):_id = self.items[ix]img_path = f'images/training/{_id}.jpg'mask_path = f'annotations_instance/training/{_id}.png'masks = self.get_mask(mask_path)obj_ids = np.arange(1, len(masks)+1)img = Image.open(img_path).convert("RGB")num_objs = len(obj_ids)
除了掩码本身,Mask R-CNN 还需要边界框信息:
boxes = []for i in range(num_objs):obj_pixels = np.where(masks[i])xmin = np.min(obj_pixels[1])xmax = np.max(obj_pixels[1])ymin = np.min(obj_pixels[0])ymax = np.max(obj_pixels[0])if (((xmax-xmin)<=10) | (ymax-ymin)<=10):xmax = xmin+10ymax = ymin+10boxes.append([xmin, ymin, xmax, ymax])
在以上代码中,通过将边界框的 x 和 y 坐标的最小值加上 10 个像素来调整存在可疑标注信息的情况(即 Person 类别的高度或宽度小于 10 像素)。
将目标值转换为张量对象:
boxes = torch.as_tensor(boxes, dtype=torch.float32)labels = torch.ones((num_objs,), dtype=torch.int64)masks = torch.as_tensor(masks, dtype=torch.uint8)area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])iscrowd = torch.zeros((num_objs,), dtype=torch.int64)image_id = torch.tensor([ix])
将目标值存储在字典中:
target = {}target["boxes"] = boxestarget["labels"] = labelstarget["masks"] = maskstarget["image_id"] = image_idtarget["area"] = areatarget["iscrowd"] = iscrowd
指定变换方法并返回图像和目标值:
if self.transforms is not None:img, target = self.transforms(img, target)img = img/255.return img, target
定义 __len__ 方法:
def __len__(self):return self.N
定义选择随机图像的函数:
def choose(self):return self[random.randint(len(self))]
检查输入输出组合:
x = MasksDataset(trn_items, get_transform(train=True), N=100)
im, targ = x[3]length = len(targ['masks'])+1
plt.subplot(1, length, 1)
print(type(im))
plt.imshow(im.permute(1,2,0).detach().cpu())
ix = 2
for m in targ['masks']:plt.subplot(1, length, ix)plt.imshow(m, cmap='gray')ix += 1
plt.show()

在以上输出中,可以看到掩码的形状为 4 x 512 x 683,表示图像中有 4 个人物。
在 __getitem__ 方法中,对于图像中存在的每个对象(实例),都有相应的掩码和边界框。此外,由于我们只有两个类别(背景类别和人类类别),因此我们将人类类别指定为 1。
总体而言,在目标输出字典中包括对象类别、边界框、掩码、掩码的面积以及蒙版是否对应于人物,这些信息都可以在目标输出词典中找到。为了使用损失函数,需要将数据标准化为 torchvision.models.detection.maskrcnn_resnet50_fpn 类所要求的格式。
(5) 定义实例分割模型 (get_model_instance_segmentation),使用预训练模型,仅重新初始化检测头来预测对象类别(背景类别和人物类别)。
首先,初始化预训练模型并替换 box_predictor 和 mask_predictor 检测头,以便学习最佳权重:
def get_model_instance_segmentation(num_classes):# 加载在COCO上预先训练的实例分割模型 model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)in_features = model.roi_heads.box_predictor.cls_score.in_featuresmodel.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)# 获取掩码分类器的输入特征数in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channelshidden_layer = 256# 掩码预测器model.roi_heads.mask_predictor = MaskRCNNPredictor(in_features_mask,hidden_layer,num_classes)return model
FastRCNNPredictor 需要两个输入——in_features (输入通道数)和 num_classes (类别数)。根据要预测的类别数,计算边界框预测数
MaskRCNNPredictor 需要三个输入——in_features_mask (输入通道数)、hidden_layer (输出通道数)和 num_classes (要预测的类别数)
获取模型的详细信息:
model = get_model_instance_segmentation(2).to(device)
print(model)
Faster R-CNN 网络和 Mask R-CNN 模型之间的主要区别在于 roi_heads 模块,该模块包含多个子模块:
box_head:对齐从FPN网络获取的输入并创建两个张量box_predictor:使用box_head的输出预测每个RoI的类别和边界框偏移量mask_roi_pool:对齐来自FPN网络的输出mask_head:将mask_roi_pool的输出转换为可用于预测掩码的特征图mask_predictor:从mask_head获取输出并预测最终的掩码
(6) 获取与训练和验证图像对应的数据集和数据加载器:
dataset = MasksDataset(trn_items, get_transform(train=True), N=len(trn_items))
dataset_test = MasksDataset(val_items, get_transform(train=False), N=len(val_items))# 定义训练、测试数据管道
data_loader = torch.utils.data.DataLoader(dataset, batch_size=2, shuffle=True, num_workers=0,collate_fn=utils.collate_fn)data_loader_test = torch.utils.data.DataLoader(dataset_test, batch_size=1, shuffle=False, num_workers=0,collate_fn=utils.collate_fn)
(7) 定义模型、超参数和优化器:
num_classes = 2
model = get_model_instance_segmentation(num_classes).to(device)
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005,momentum=0.9, weight_decay=0.0005)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=3,gamma=0.1)
模型将图像和目标字典作为输入,可以通过以下命令查看模型输出示例:
model.eval()
pred = model(dataset[0][0][None].to(device))
输出字典包含边界框 (BOXES)、与边界框相对应的类别 (LABELS)、与类别预测相对应的置信度分数 (SCORES) 以及掩码实例的位置 (MASKS)。该模型返回 100 个预测结果,因为通常图像中的对象数不超过 100 个。
获取检测到的实例数量:
print(pred[0]['masks'].shape)
一张图像通过以上模型最多可以获取 100 个掩码实例(非背景类别)。对于这 100 个实例,返回相应的边界框、类别标签和相应的置信度值。
(8) 训练模型:
trn_history = []
for epoch in range(num_epochs):# 模型训练res = train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10)trn_history.append(res)# 调整学习率lr_scheduler.step()
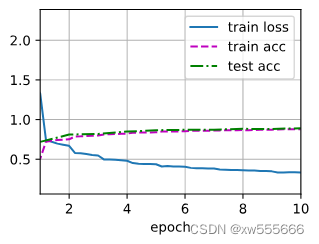
使用训练后的模型,就可以预测图像中的人物实例掩码。记录训练损失随时间的变化情况:
import matplotlib.pyplot as plt
plt.title('Training Loss')
losses = [np.mean(list(trn_history[i].meters['loss'].deque)) for i in range(len(trn_history))]
plt.plot(losses)
plt.show()

(9) 使用训练后的模型预测测试图像:
model.eval()
k=1
im = dataset_test[k][0]
plt.imshow(im.permute(1,2,0))
plt.show()
with torch.no_grad():prediction = model([im.to(device)])for i in range(len(prediction[0]['masks'])):plt.imshow(Image.fromarray(prediction[0]['masks'][i, 0].mul(255).byte().cpu().numpy()), cmap='gray')plt.title('Class: '+str(prediction[0]['labels'][i].cpu().numpy())+' Score:'+str(prediction[0]['scores'][i].cpu().numpy()))plt.show()

从上图中可以看出,模型成功识别出图中的人物实例。此外,模型还预测图像中的多个置信度较低的其他分割实例。
3. 多类别实例分割
在上一小节中,我们学习了如何分割 Person 类别的多个实例。在本节中,我们将调整上一节中构建的模型,一次性分割图像中多个对象类别的多个实例。
(1) 获取包含感兴趣类别的图像,类别 ID 4、ID 5、ID 6 和 ID 6:
classes_list = [4,5,6,7]
annots = []
for ann in all_annots[:3000]:_ann = cv2.imread(ann, 1).transpose(2,0,1)r,g,b = _annif np.array([num in np.unique(b) for num in classes_list]).sum()==0:continueannots.append(ann)def stems(split):items_new = [item.split('/')[-1] for item in split]items = [item.split('.')[0] for item in items_new]return itemsfrom sklearn.model_selection import train_test_split
_annots = stems(annots)trn_items, val_items = train_test_split(_annots, random_state=2)
在以上代码中,获取至少包含一个感兴趣的类别 (classes_list) 的图像。
(2) 修改 MasksDataset 类中的 get_mask 方法,使其返回两个掩码以及与每个掩码对应的类别:
def get_mask(self,path):an = cv2.imread(path, 1).transpose(2,0,1)r,g,b = ancls = list(set(np.unique(b)).intersection({4,5,6,7}))masks = []labels = []for _cls in cls:nzs = np.nonzero(b==_cls)instances = np.unique(g[nzs])for ix, _id in enumerate(instances):masks.append(g==_id)labels.append(classes_list.index(_cls)+1)return np.array(masks), np.array(labels)
在以上代码中,获取图像中感兴趣的类别,并存储在 cls 中,然后,循环遍历每个已识别的类别 (cls),并将红色通道值对应于类别 (cls) 的位置存储在 nzs 中。接下来,获取这些位置上的实例 ID (instances)。此外,在返回掩码 masks 和标签 lables 数组之前,将实例 instances 追加到掩码数组中,并将实例对应的类别追加到标签数组中。
(3) 修改 __getitem__ 方法中的标签 (labels) 对象,使其包含从 get_mask 方法获得的标签:
def __getitem__(self, ix):_id = self.items[ix]img_path = f'images/training/{_id}.jpg'mask_path = f'annotations_instance/training/{_id}.png'masks, labels = self.get_mask(mask_path)obj_ids = np.arange(1, len(masks)+1)img = Image.open(img_path).convert("RGB")num_objs = len(obj_ids)boxes = []for i in range(num_objs):obj_pixels = np.where(masks[i])xmin = np.min(obj_pixels[1])xmax = np.max(obj_pixels[1])ymin = np.min(obj_pixels[0])ymax = np.max(obj_pixels[0])if (((xmax-xmin)<=10) | (ymax-ymin)<=10):xmax = xmin+10ymax = ymin+10boxes.append([xmin, ymin, xmax, ymax])boxes = torch.as_tensor(boxes, dtype=torch.float32)labels = torch.as_tensor(labels, dtype=torch.int64)masks = torch.as_tensor(masks, dtype=torch.uint8)area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])iscrowd = torch.zeros((num_objs,), dtype=torch.int64)image_id = torch.tensor([ix])target = {}target["boxes"] = boxestarget["labels"] = labelstarget["masks"] = maskstarget["image_id"] = image_idtarget["area"] = areatarget["iscrowd"] = iscrowdif self.transforms is not None:img, target = self.transforms(img, target)img = img/255.return img, target
4.定义模型时,指定 4 个类别:
num_classes = 5
model = get_model_instance_segmentation(num_classes).to(device)
绘制模型训练期间,训练损失随时间增加的变化情况:

使用训练后的模型预测包含目标对象的样本图像:

小结
Mask R-CNN 是一种在目标检测任务中引入了语义分割的强大框架,通过在 Faster R-CNN 基础上进行扩展,添加了额外的分支网络,不仅可以准确地检测对象的位置和类别,还可以生成每个实例的精确像素级别的语义分割掩码。其模块化的设计可以轻松地应用于不同的任务和数据集,并且可以通过添加更多的分支进行功能扩展,如实例关键点检测等。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习
PyTorch深度学习实战(16)——面部关键点检测
PyTorch深度学习实战(17)——多任务学习
PyTorch深度学习实战(18)——目标检测基础
PyTorch深度学习实战(19)——从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)——从零开始实现Fast R-CNN目标检测
PyTorch深度学习实战(21)——从零开始实现Faster R-CNN目标检测
PyTorch深度学习实战(22)——从零开始实现YOLO目标检测
PyTorch深度学习实战(23)——使用U-Net架构进行图像分割