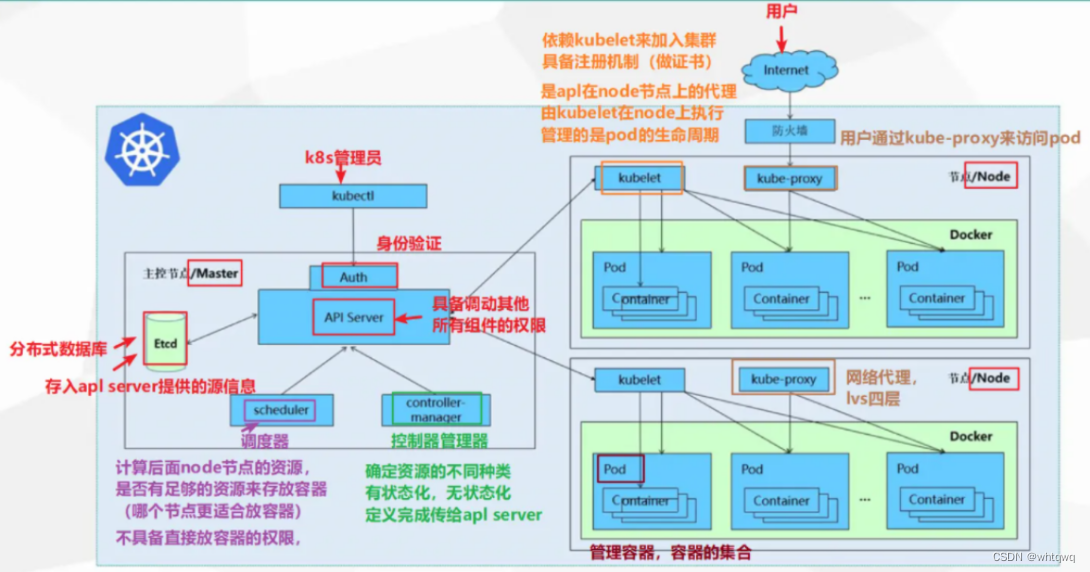
简介
ClickHouse是一个开源列式数据库管理系统(DBMS),用于在线分析处理(OLAP):
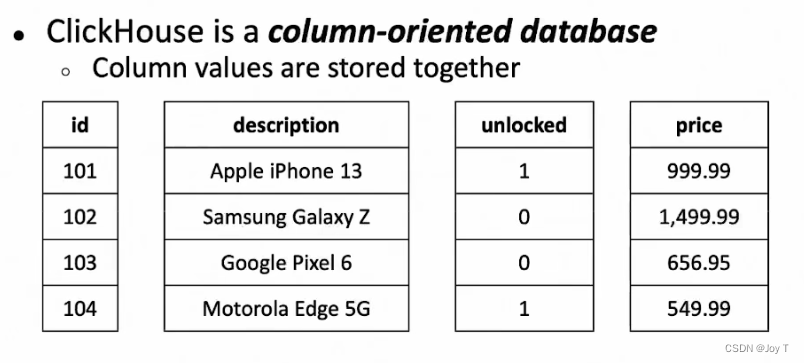
列式存储:与传统的行式数据库不同,ClickHouse以列的形式存储数据,这使得在分析大量数据时能够获得更好的性能和压缩率。
高速查询:ClickHouse为分析大量数据而优化,可以执行复杂的查询,并在极短的时间内提供答案。
分布式处理:ClickHouse可以无缝地在多个节点上部署,提供水平扩展。它支持复制、分片和负载均衡。
数据压缩:由于列式存储的特点,ClickHouse提供了高效的数据压缩,从而节省存储空间并提高查询速度。
SQL支持:ClickHouse使用SQL作为查询语言,并提供了丰富的函数库,包括时间序列、聚合和字符串处理函数等。
实时处理:尽管ClickHouse主要是为OLAP场景设计的,但它还支持近实时数据插入和查询,使其在某些情况下也可用于在线事务处理(OLTP)。
开源与社区:ClickHouse是完全开源的,拥有一个活跃的开发和用户社区。
多种数据格式:ClickHouse支持多种数据格式,如Parquet、JSON、CSV等,这使得从其他系统迁移或导入数据变得非常容易。
与其他技术的集成:ClickHouse可以与多种其他技术(例如Kafka、HDFS等)集成,使其能够在各种环境中高效地工作。

简而言之,CK本质上就是DBMS,起源于mysql。重要特点就是:数据按列存储,适合于OLAP在线分析处理,查询列的速度非常之快,节省大量的IO资源。(其实和hudi有点像,hudi就是行写入、列查询)
同一列保存在同一个数据文件当中,便于数据的压缩存储!
这一点很好理解,同一列的数据类型(域)是一致的,想想看是各种类型都有的一行数据好压缩,还是一列相同类型的数据好压缩?结果显而易见!
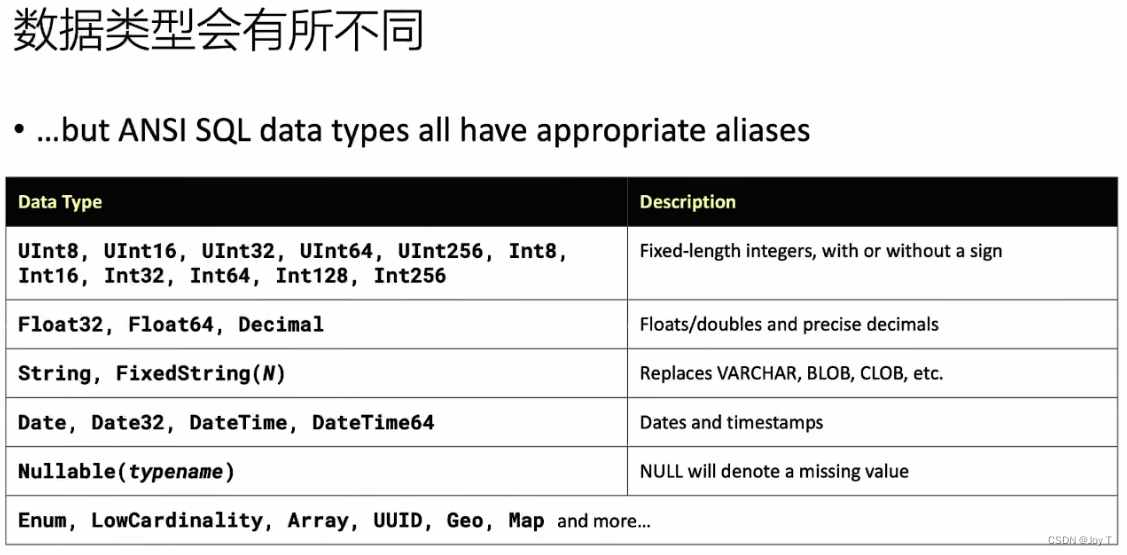
本质上,CK的数据类型和C++相似,因为CK就使用C++写的。
ClickHouse 与表函数
ClickHouse的强大表函数支持增强了其与其他系统的互操作性,为用户提供了更多的灵活性和方便性。涉及到DBMS和大数据框架的整合,使得数据处理和分析变得更加高效和无缝。
表函数 (Table Function)
表函数是一种数据库函数,它返回一个可以像操作常规数据库表那样操作的行集。其主要目的是能够将函数的输出作为一个表来使用。这意味着我们可以使用SQL查询来读取和处理这些函数的输出。
ClickHouse 与表函数
ClickHouse的特点之一是其广泛的表函数支持。这些表函数允许管理员用户从各种数据源(例如文件、URL、外部数据库、大数据框架等)读取数据,并将这些数据作为表来处理。例如,管理员用户可以使用表函数从一个文件或HTTP URL中读取数据,然后直接在ClickHouse中对该数据进行查询,而无需先导入数据。
DBMS 和大数据框架的整合
ClickHouse为了提高灵活性和扩展性,提供了与其他DBMS和大数据框架的整合功能。例如,ClickHouse可以与Kafka、HDFS、MySQL等进行交互。表函数在这方面发挥了关键作用,它们使得从这些系统中读取数据变得异常简单。通过表函数,ClickHouse可以轻松地与其他系统进行交互,从而实现数据的即时查询和分析,而无需事先进行数据迁移或转换。
CK存储引擎及Primary Key
CK使用了一种名为MergeTree的数据结构和存储引擎:

MergeTree存储引擎
数据结构: MergeTree 是由一系列有序的
parts组成。每个part包含了多个按照某种键(通常是 PRIMARY KEY)排序的granules。
Parts 和 Granules
- 在ClickHouse中,数据被分成
parts(部分)。每个part包含多个granules。可以将part看作是granules的集合。随着时间的推移,parts可能会由于合并操作而变大。但不论part的大小如何,它都是由granules组成的。Granule是MergeTree表数据的最小物理单位。每个granule包含一定数量的行。当我们说“块”,这与granule是相似的概念,但granule是ClickHouse的专用术语。- 物理上,每个
granule包含固定数量的行(例如8192行,即8192条记录),但这个数字可能会因配置或其他因素而有所不同。
合并Parts
- 在数据写入ClickHouse时,首先写入小的granules,其实也相当于写入
parts。随着时间的推移,ClickHouse会在后台运行合并操作,将小的parts合并成大的parts。这种合并操作可以提高查询性能并节省存储空间。- 合并操作: MergeTree 的命名来源于其后台自动进行的特性,即定期将小的
parts合并为更大的parts。这种合并操作旨在优化数据压缩并提高查询效率,因为数据库可以快速定位数据所在的位置。

PRIMARY KEY in ClickHouse
- 排序: 在ClickHouse中,
PRIMARY KEY定义了数据的物理排序方式。当查询数据时,ClickHouse会使用这个排序信息来跳过那些不相关的数据块。- 不是唯一的: 与MySQL不同,ClickHouse中的
PRIMARY KEY不保证唯一性。它只是一个排序和索引工具。- CK中如果不设定PK,那么创建表时会报错!不设定PK的情况下必须指定ORDER BY才行!所以可以理解为CK必须需要依赖于一种排序方式,而这种排序方式可以是PK,也可以是ORDER BY来提供。
为什么与MySQL中的PRIMARY KEY不同
- 目的不同: MySQL(以及其他传统的关系型数据库)中的
PRIMARY KEY主要用于确保数据的唯一性和引用完整性。而ClickHouse的设计目标是查询速度和分析,所以PRIMARY KEY在ClickHouse中主要用于数据排序和查询优化。- 数据模型: 由于ClickHouse是为OLAP场景设计的,它的数据模型与为在线事务处理(OLTP)设计的MySQL有所不同。在OLAP场景中,大量的数据聚合和分析比数据的唯一性更为重要。
CK的 PRIMARY KEY 和 稀疏索引
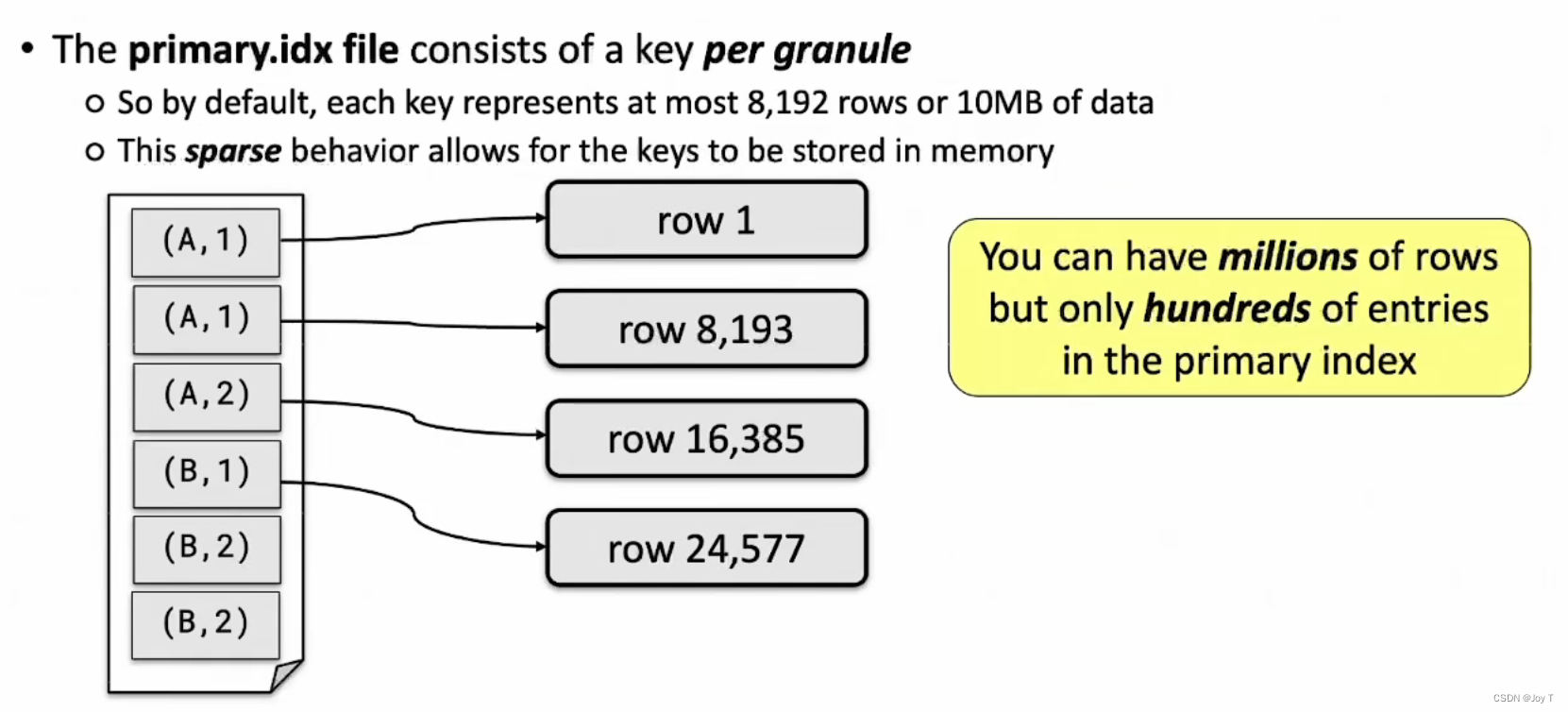
- 在ClickHouse中,
PRIMARY KEY被用作稀疏索引。这意味着不是为每一行数据都保存索引项,而是为每个granule保存一个索引项。这就是为什么一个PRIMARY KEY对应多个行。
- 图中:左侧为pk,右侧为其对应的入口,其实通常来说同时也会存储row8192/16384/24576这样的最大值,这种设计选择为ClickHouse提供了查询性能的优势。由于它的目标是为OLAP和大数据分析优化,所以它偏好于范围查询而不是单行查询。为每个
granule而不是每行保存索引项,使得索引更小、更快,而且更适合这种用途。
让我们通过CK中的块,进一步了解CK的主键:
块之间的顺序:
- 在ClickHouse中,每个
granule的创建是基于插入的数据批次的。当一批数据被插入时,它们会首先按照PRIMARY KEY进行排序。排序后,数据会被划分为大小适中的granules。每个granule内部的数据都是有序的,因此,granules之间也存在一个顺序。但这并不意味着所有granules之间都有全局的严格排序,因为新的插入操作可能会引入新的granules。- 当执行一个批量数据插入操作时,数据首先被缓存并按照PRIMARY KEY排序。一旦数据达到了一定的大小或时间阈值,它就会被刷入磁盘形成新的
granules,并进一步形成新的parts。这种批量处理方式优化了磁盘I/O操作,提高了数据插入的吞吐量和整体性能。
块合并:
1. ClickHouse的合并操作基于
MergeTree家族中特定的表引擎策略。通常,合并操作考虑part的大小、年龄、数据的修改历史等因素。合并也有助于清除数据的过时版本,因为ClickHouse支持数据的版本控制。2. 当新数据被写入ClickHouse时,它的granule形式会被立即组成一个新的
part。这是一个非常快速的操作,因为新写入的数据本质上已经形成了一个独立的part。所以,它本身就已经是一个part,并不需要额外的时间来将块转换为part。3. 然而,后台的合并操作(将多个小
parts合并为一个更大的part)确实需要时间,因为这涉及到读取、合并和写入数据。这种合并操作是为了提高存储效率、查询性能和数据压缩。但对于新写入的数据,它们已经直接形成了新的part,不需要等待。如图,part不是无限合并的,有150GB大小的限制。
MySQL的聚集索引与ClickHouse的PRIMARY KEY:
- MySQL中的聚集索引确实按照
PRIMARY KEY来存储数据。但ClickHouse和MySQL的设计目标和使用场景有所不同。ClickHouse是为大数据分析优化的,而MySQL则更倾向于在线事务处理。- 在MySQL中,
PRIMARY KEY确保了唯一性,这对于事务性操作是很有价值的,因为你经常需要基于唯一键来更新或删除特定的记录。而在ClickHouse中,数据通常是以批次写入并追加的方式插入的,而不是单行的插入、更新或删除。- ClickHouse中改变
PRIMARY KEY的意义,是为了更好地服务于它的主要用例:大数据分析。其PRIMARY KEY更多地作为一个优化查询性能的工具,而不是作为一个确保数据完整性的约束。
再理解二者PK的区别:
MySQL的PRIMARY KEY(聚集索引)和ClickHouse的PRIMARY KEY都能实现数据跳过和减少存储需求的效果,但它们是为了不同的工作负载而优化的。
数据跳过:MySQL的聚集索引确实允许它快速查找特定的行。但在大规模数据分析中,你经常需要处理大范围的数据,而不是单独的行。Mysql数据跳过过程请见文章Mysql底层执行过程及基于PK的“数据跳跃”-CSDN博客,ClickHouse的
PRIMARY KEY是为了这种查询模式设计的,它可以让系统判断哪些数据块是与查询条件无关的,从而跳过大量数据。减少存储需求:虽然MySQL的聚集索引也按
PRIMARY KEY排序存储数据,但由于它的行式存储模式,压缩效果不及ClickHouse。ClickHouse的列式存储结合数据排序可以实现更高效的数据压缩。
可以这么理解:MySQL的PRIMARY KEY是全能型设计,旨在优化随机访问和事务性查询。而ClickHouse的PRIMARY KEY是专攻型设计,特别优化了大数据分析的工作负载。
ClickHouse中数据写入和存储的过程
数据写入与排序:当新的一批数据写入ClickHouse时,它会首先按照
PRIMARY KEY进行排序。形成granules:排序后的数据会被分割为大小适中的
granules,通常每个granule包含8192条记录(或其他预设的行数)。列式存储:每个
granule内的数据会按列进行存储。也就是说,同一个granule里,一列的所有数据都连续存放在一起,这对于压缩和查询效率都很有帮助。例如,如果有一个表有三列:A,B, 和C,则granule内的所有行的列A的数据都存储在一起,紧接着是列B的数据,然后是列C的数据。
granule索引:对于每个
granule,ClickHouse存储与PRIMARY KEY列关联的最小和最大值。这些值表示了granule内数据的范围,并被用作稀疏索引,以帮助加速范围查询。当执行查询时,通过检查每个granule的最小和最大值,ClickHouse可以迅速确定哪些granules可能包含查询结果。存储与压缩:
granules会被压缩后存储在磁盘上,以节省存储空间。当新数据被写入ClickHouse时,它的granule形式会被立即组成一个新的
part,然后将多个小parts合并为一个更大的part。
总结
ClickHouse是一个高性能的分析数据库,适合实时或近实时的大数据查询。如果我们的目标是进行高速分析和查询,而不仅仅是数据存储和同步,那么使用ClickHouse可能会有帮助。我们可以将数据从数据库同步到ClickHouse,并使用ClickHouse的强大查询能力进行分析。
然而,如果只需要数据存储和简单的查询功能,直接使用Mysql / Hudi可能更加简洁和高效。只有需要高速、复杂的实时查询时,考虑使用ClickHouse。