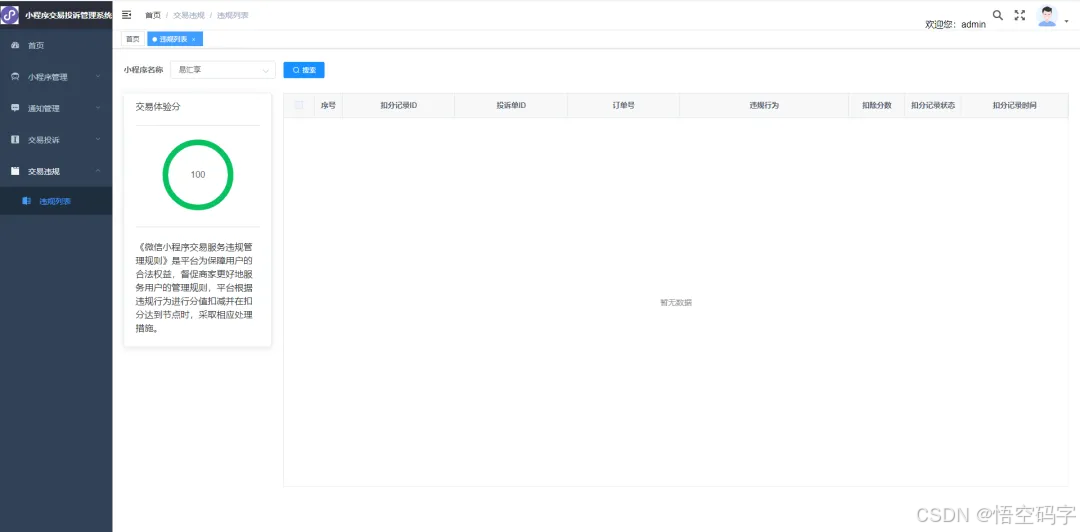
核密度估计(KDE)图,一种可视化技术,提供连续变量概率密度的详细视图。在本文中,我们将使用Iris Dataset和KDE Plot来可视化数据集。
什么是KDE图?
KDE图,全称核密度估计图(Kernel Density Estimation),是一种用于估计数据分布的非参数方法,通常用于可视化和理解数据的分布情况。它通过平滑地估计数据的概率密度函数(PDF)来显示数据的分布特征,尤其在连续变量上非常有用。
核密度估计图通常表现为一条平滑的曲线,描述了数据在特定值附近的密度。这条曲线称为核密度估计。核密度估计是通过将每个数据点视为一个小的概率分布(通常是高斯分布或其他核函数)并将它们叠加而得到的。这样,核密度估计提供了一个对数据分布的连续估计,而不仅仅是一个直方图或散点图。
特点
核密度估计图的主要特点包括:
- 平滑性:KDE图是平滑的,不受特定的数据点的影响。这使得它可以更好地捕捉数据的分布特征。
- 面积为1:KDE图的总面积在整个范围内等于1,因为它是概率密度函数的估计。
- 峰值和谷值:KDE图上的峰值表示数据集中的高密度区域,而谷值表示稀疏区域。
- 帮助比较:使用KDE图,你可以比较不同数据集的分布,或者比较数据在不同条件下的分布。这对于发现数据之间的差异和相似性非常有用。
KDE图直观地表示数据的分布,提供对其形状、集中趋势和分布的深入了解。当处理连续数据或希望探索分布而不对特定参数形式(例如,假设数据服从正态分布)。KDE图通常用于统计软件包和数据可视化库,例如Python中的Seaborn和Matplotlib。
绘制KDE曲线案例
创建单变量Seaborn KDE图
为了开始我们的探索,我们深入研究了单变量Seaborn KDE图的创建,可视化了单个连续属性的概率分布。
我们可以可视化样本对单个连续属性的概率分布。
# importing the required libraries
from sklearn import datasets
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline# Setting up the Data Frame
iris = datasets.load_iris()iris_df = pd.DataFrame(iris.data, columns=['Sepal_Length','Sepal_Width', 'Patal_Length', 'Petal_Width'])iris_df['Target'] = iris.targetiris_df['Target'].replace([0], 'Iris_Setosa', inplace=True)
iris_df['Target'].replace([1], 'Iris_Vercicolor', inplace=True)
iris_df['Target'].replace([2], 'Iris_Virginica', inplace=True)# Plotting the KDE Plot
sns.kdeplot(iris_df.loc[(iris_df['Target']=='Iris_Virginica'),'Sepal_Length'], color='b', shade=True, label='Iris_Virginica')# Setting the X and Y Label
plt.xlabel('Sepal Length')
plt.ylabel('Probability Density')
我们还可以在单个图中可视化多个样本的概率分布。
# Plotting the KDE Plot
sns.kdeplot(iris_df.loc[(iris_df['Target']=='Iris_Setosa'),'Sepal_Length'], color='r', shade=True, label='Iris_Setosa')sns.kdeplot(iris_df.loc[(iris_df['Target']=='Iris_Virginica'), 'Sepal_Length'], color='b', shade=True, label='Iris_Virginica')plt.xlabel('Sepal Length')
plt.ylabel('Probability Density')
双变量情况
超越单变量分析,我们将我们的可视化能力扩展到双变量Seaborn KDE图。这种复杂的技术可以检查样本对多个连续属性的概率分布。
# Setting up the samples
iris_setosa = iris_df.query("Target=='Iris_Setosa'")
iris_virginica = iris_df.query("Target=='Iris_Virginica'")# Plotting the KDE Plot
sns.kdeplot(iris_setosa['Sepal_Length'], iris_setosa['Sepal_Width'],color='r', shade=True, label='Iris_Setosa',cmap="Reds", shade_lowest=False)
我们还可以在单个图中可视化多个样本的概率分布。
sns.kdeplot(iris_setosa['Sepal_Length'],iris_setosa['Sepal_Width'],color='r', shade=True, label='Iris_Setosa',cmap="Reds", shade_lowest=False)sns.kdeplot(iris_virginica['Sepal_Length'], iris_virginica['Sepal_Width'], color='b',shade=True, label='Iris_Virginica',cmap="Blues", shade_lowest=False)plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.title('Bivariate Seaborn KDE Plot')
plt.legend()
plt.show()
总结
总之,KDE图是一种非常有用的可视化工具。它能够可视化各种属性的概率密度,使数据分析师和科学家能够识别隐藏的模式并做出明智的决策。无论是用于单变量还是双变量分析,KDE图都是数据可视化工具包中通用且不可或缺的工具,可以帮助机器学习和深度学习爱好者更好地理解和分析数据。