前言
我们曾探讨过观测云如何通过将内置视图与查看器相联结,实现更全面的数据关联分析。(参见《内置视图联动查看器,实现数据关联分析》)这里提到的查看器,实际是一个功能全面且强大的数据查看分析工具。其提供多种搜索和筛选方式,并支持以组合的方式搭配使用获取最终数据结果。
本文我们将从实际场景出发,为您讲述如何通过查看器的搜索与筛选功能,帮助您快速、精准地检索数据,定位故障问题。
观测云的查看器可以在基础设施、事件、日志、应用性能监测、用户访问监测、CI 可视化、可用性监测、安全巡检等功能模块内使用。此处,我们以【日志查看器】为场景:
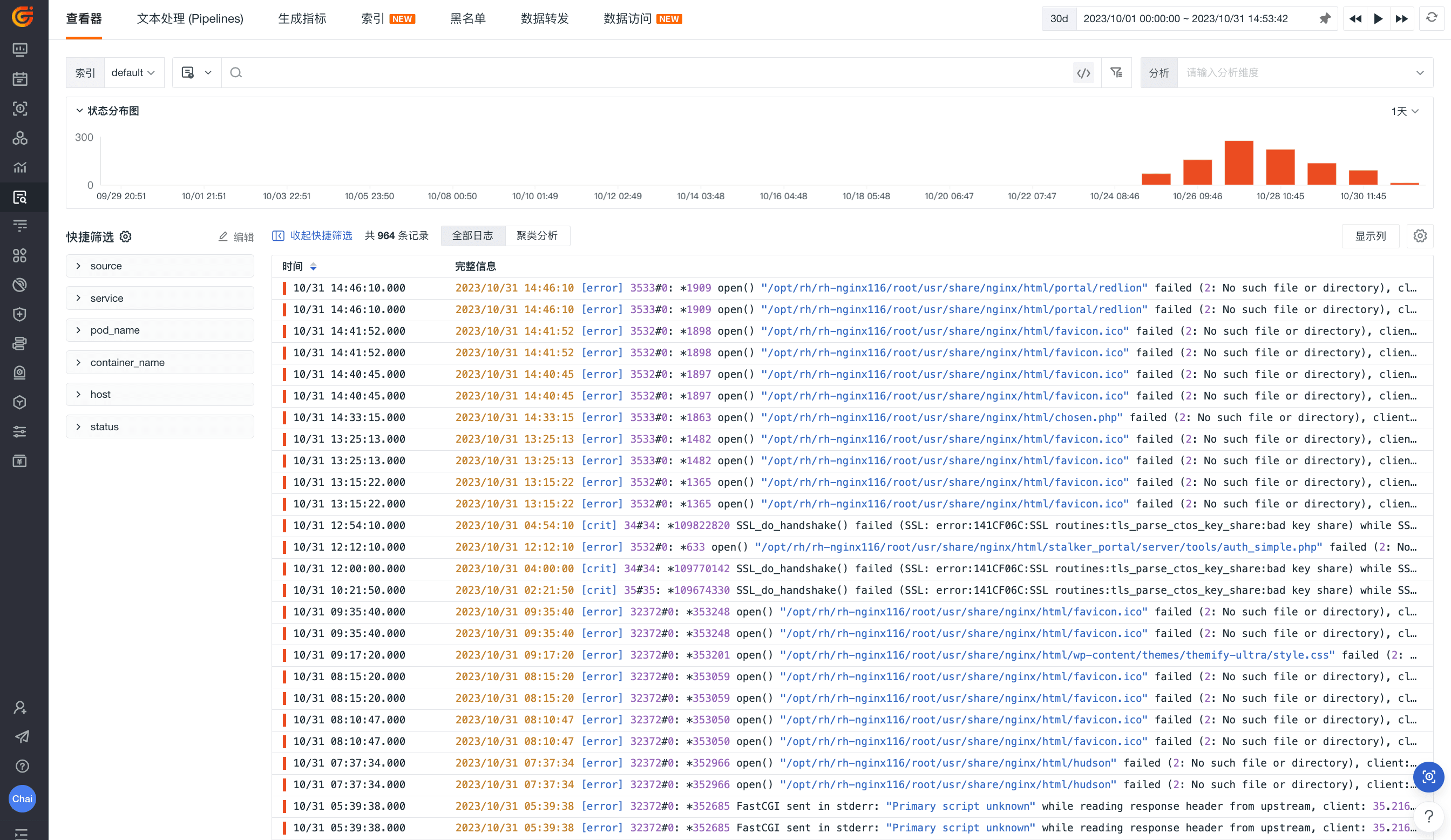
搜索
当我们面对系统采集上来的杂乱的海量数据,在页面上方的搜索栏直接进行搜索是定位到目标数据最快捷迅速的方式之一。在观测云,【搜索】一般由术语(可以是单词或短语)和运算符两部分组成。当我们输入单词或者短语时,叠加通配运算符(? 表示匹配任意字符, * 匹配 0 或多个字符),回车即可实现搜索的动作。
具体的示例说明如下:
# 单词
guance // 精准搜索
guanc[e // 存在特殊字符写法示例(无需添加\转义) # 单词通配符搜索(出于性能考虑,观测云暂不支持前缀 * 写法,若存在通配搜索以下写法均支持)
guance*
gua?ce*
gua*ce# 短语(双引号括起来的内容我们统称为短语,此写法下双引号的内容会作为一个整体发起匹配搜索)
"guance test" // 查询全文索引字段中,存在 "guance test" 内容的匹配结果
"guance 127.0.0.1" // 存在特殊字符时写法示例
实际效果如下:

除了我们以上谈到的搜索方式,观测云还支持您在日志查看器使用 JSON 搜索。这种搜索方式默认对日志查看器内 message 的内容进行精确检索,同时要求 message 是 JSON 格式,其他格式的日志内容不支持该检索方式。比如我们可以在搜索栏以 @key:value 的格式输入搜索内容。若为多层级 JSON 可用 “.” 承接,即 @key1.key2:value。
需要注意的是,这种搜索方式目前仅支持日志查看器,且仅支持 中国区 1(杭州)、中国区 3(张家口)以及 中国区 4(广州) 这三个站点,并且工作空间需要在 2022年6月23日 后创建。
具体的示例说明如下:
message 信息如下:
{__namespace:tracing,cluster_name_k8s:k8s-demo,meta:{ service:ruoyi-mysql-k8s,name:mysql.query,resource:select dict_code, dict_sort, dict_label, dict_value, dict_type, css_class, list_class, is_default, status, create_by, create_time, remark from sys_dict_data}
}# 查询 cluster_name_k8s = k8s-demo
@cluster_name_k8s:k8s-demo // 精准匹配
@cluster_name_k8s:k?s* // 模糊匹配# 查询 meta 下 service = ruoyi-mysql-k8s
@meta.service:ruoyi-mysql-k8s // 精准匹配
@meta.service:ruoyi?mysql* // 模糊匹配
筛选
除了上文提到的搜索,在搜索栏输入筛选条件也是一个快捷的查询方式。我们可以针对 标签/属性 的格式进行筛选,按照 字段 运算符 值 顺序拼接可得。
字段
字段是筛选条件成立的前提。当我们根据实际需求添加字段时,您可以选择观测云默认会列出当前时间范围内的字段的列表,如未找到您可以自定义添加字段。
参见 字段管理 - 观测云文档
运算符
运算符用于连接字段与值的关系。我们可以针对【字符串】或者【数值】类型字段做筛选过滤。
- 字符串字段运算符:
=≠wildcardnot wildcardexistnot exist; - 数值字段运算符:
=≠>>=<<=[xx TO xx]existnot exist。
不同运算符的说明如下:
| 运算符 | 描述 |
|---|---|
| = | 等于,示例:key:value ,= ≠ 可以叠加下面其他运算符组合使用。 |
| ≠ | 不等于,示例:-key:value,= ≠ 可以叠加下面其他运算符组合使用。 |
| wildcard | 模糊匹配,示例:key:value*,反向筛选则通过叠加 ≠ 实现。 |
| exist | 存在,筛选过滤所有存在当前 key 的数据结果返回,示例:key:*。反向筛选则通过叠加 ≠ 实现。 |
| > | 大于,示例:key:>value。反向筛选则通过叠加 ≠ 实现。 |
| >= | 大于等于,示例:key:>=value。反向筛选则通过叠加 ≠ 实现。 |
| < | 小于,示例:key:<value。反向筛选则通过叠加 ≠ 实现。 |
| <= | 小于等于,示例:key:<=value。反向筛选则通过叠加 ≠ 实现。 |
| [xx - xx] | 区间,示例:key:[1 - 100]。反向筛选则通过叠加 ≠ 实现。 |
值
值是筛选条件内期望达成的目标值。我们可以将其与 【AND】 或 【OR】 运算符组合查询。
具体的示例说明如下:
精确值
key:(value1 AND value2 OR value3)# 包含模糊匹配
key:(value1 OR test* OR value3)# 包含 * 存在
key:(value1 OR * OR value3) // 等同于 key:*
key:(value1 AND *) // 等同于 key:value1
key:(value1 AND * OR value3) // 等同于 key:(value1 OR value3)
我们在此处用到的 AND/OR/NOT 这一形式在专业术语上称之为布尔运算符。我们可以将这类运算符与上文所提到的搜索与筛选条件进一步组合关联搜索与筛选。
不同运算符的说明如下:
| 逻辑关系 | 描述 | 备注 |
|---|---|---|
| a AND b | 取前后查询结果交集 | 搜索、筛选条件间默认使用 AND 做连接。其中 AND 可以用 空格,即 a AND b = a b。 |
| a OR b | 取前后查询结果并集 | 返回结果需包含 a 或者 b 的任意一个关键字。示例:a OR b:value |
| NOT c | 排除当前查询结果 | NOT 多用于搜索写法,筛选处排除逻辑使用 ≠ 代替。 |
实际效果如下:

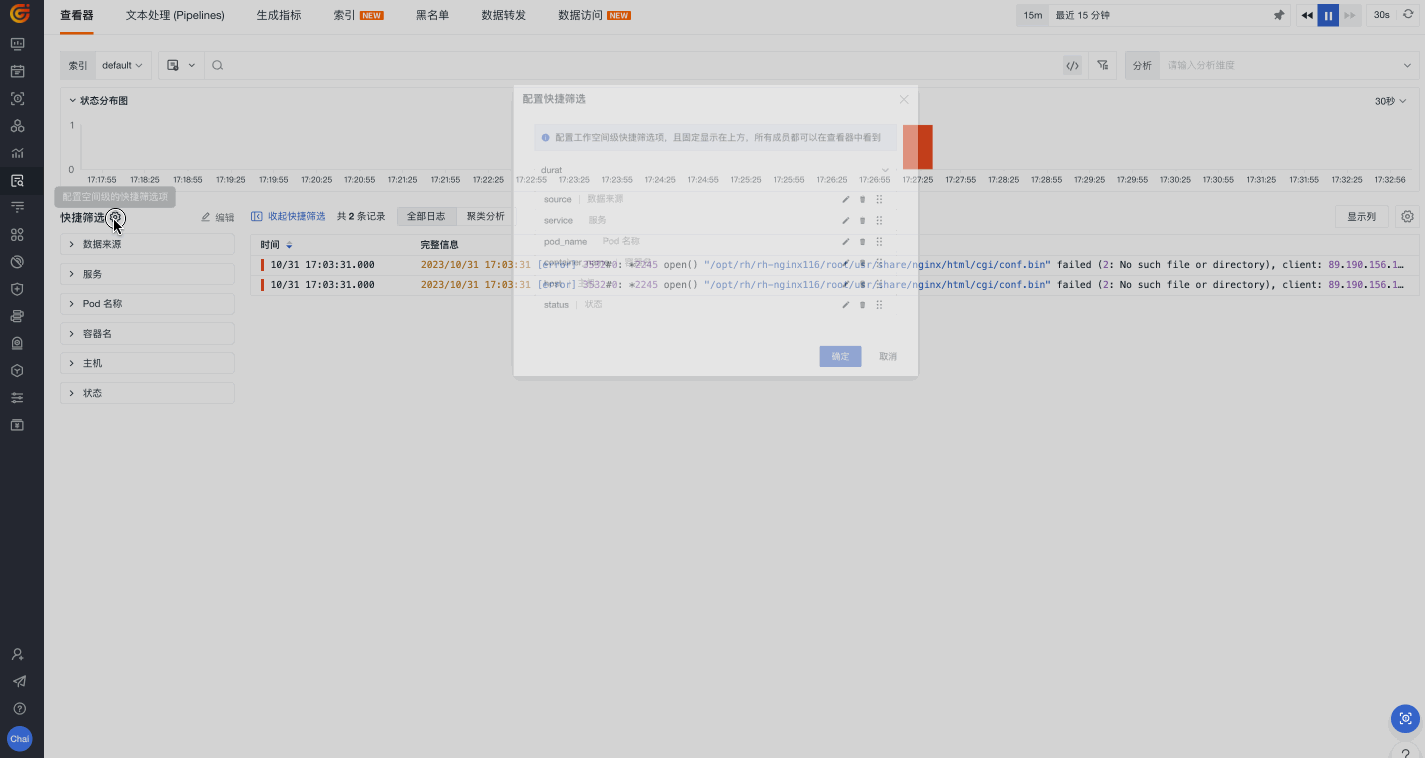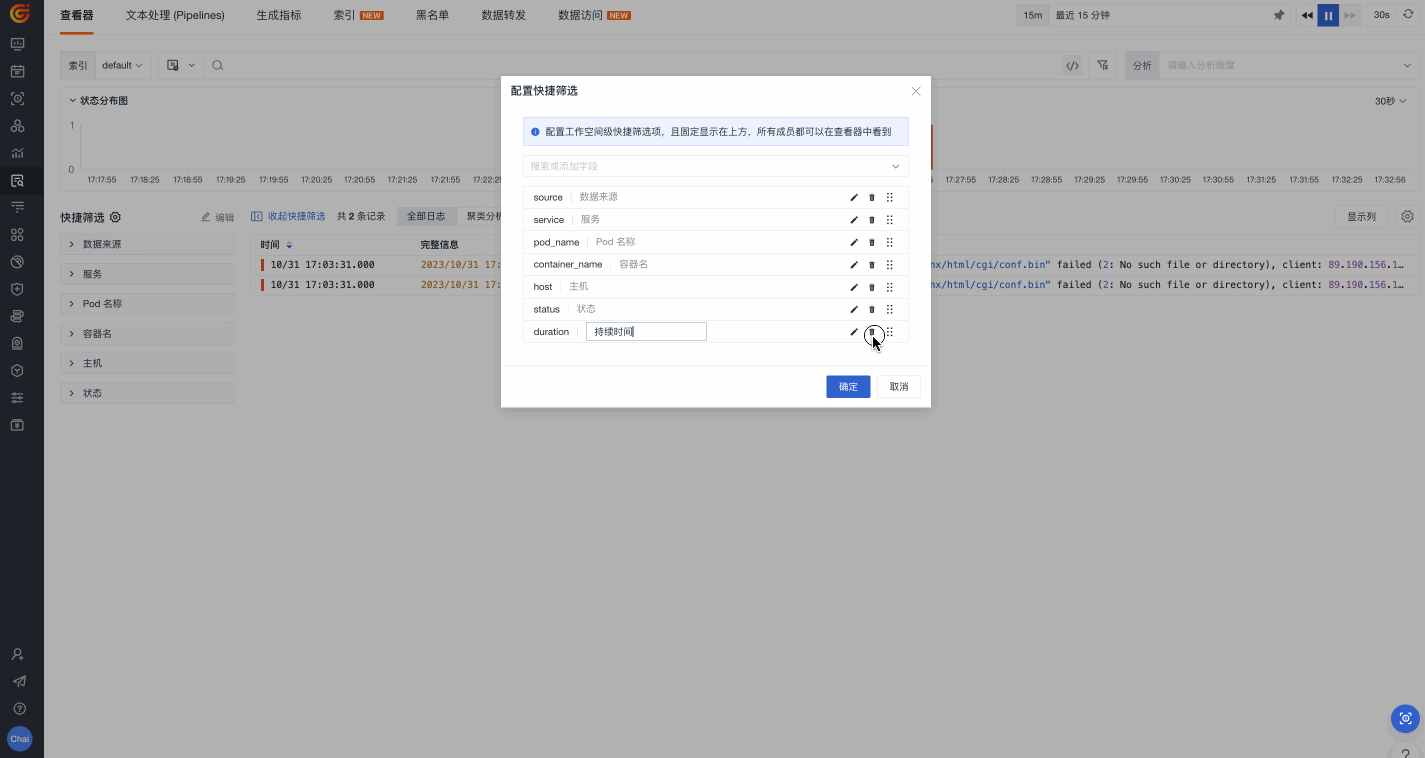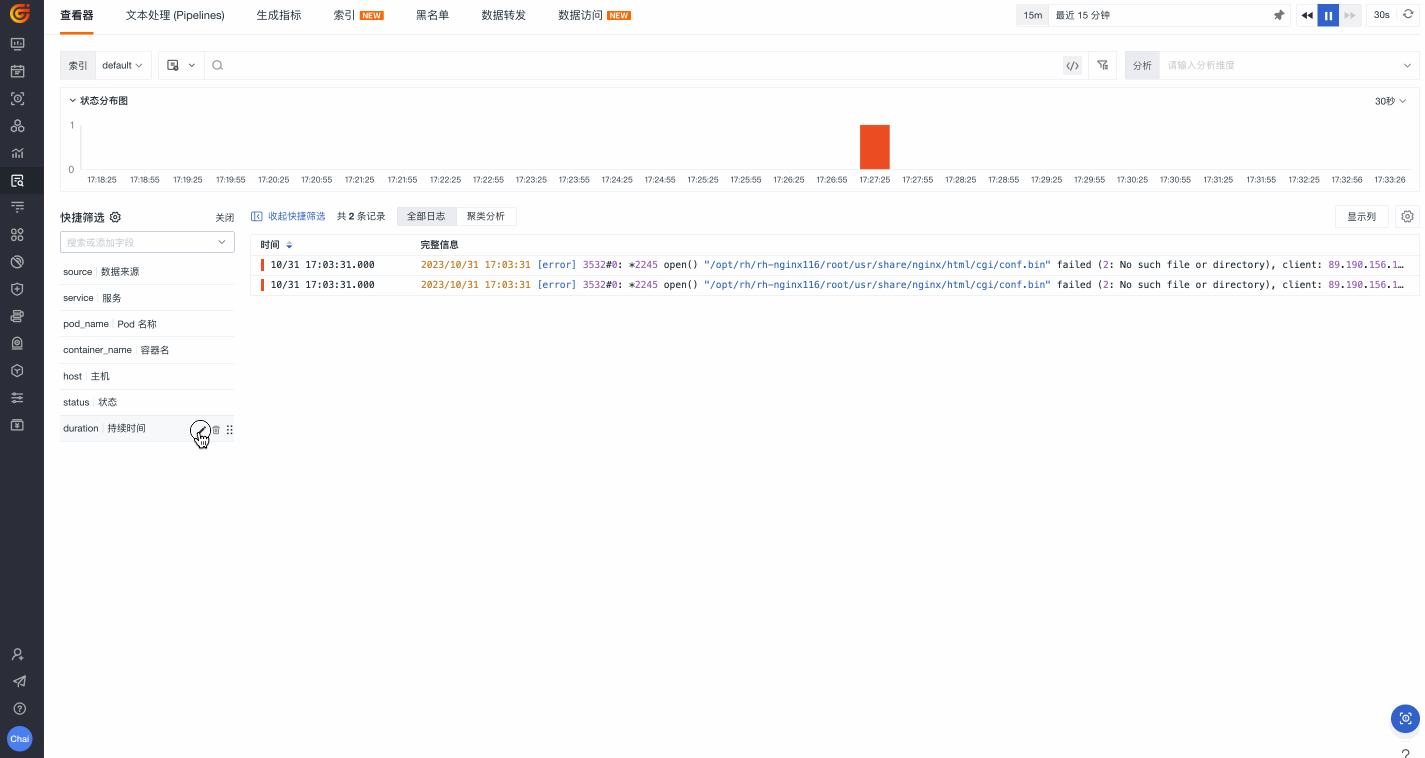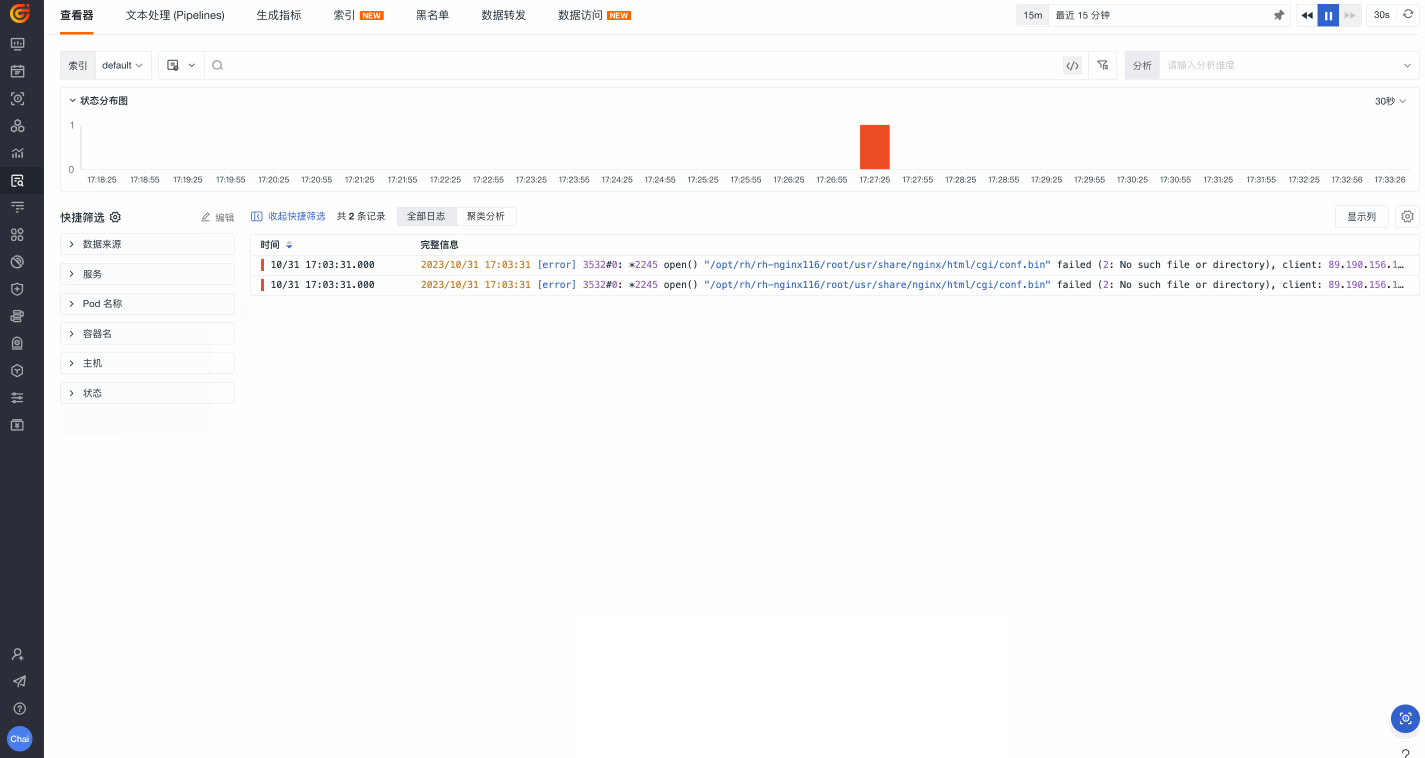
快捷筛选
除了在搜索栏输入筛选条件,我们还可以直接使用观测云 > 快捷筛选这一功能。在这里,我们可以基于一系列字段进行正选&反选、字段值搜索、添加显示列、查询值 TOP 5 等操作,从而定位至我们需要的目标数据。
有关更多相关操作说明,参见 查看器的强大之处 - 观测云文档
结论
数据的杂乱和海量性是业务数据管理面临的巨大挑战。当面对我们的系统采集并保存的大量数据,若是能借助精准有效的搜索或筛选方式进行数据的过滤查询,将使我们的数据处理效率事半功倍。未来,观测云也会探索更多查看器相关的查询分析功能,敬请期待!