Explaining and harnessing adversarial examples----《解释和利用对抗样本》
背景: 早期的研究工作认为神经网络容易受到对抗样本误导是由于其非线性特征和过拟合。
创新点: 该论文作者认为神经网络易受对抗性扰动影响的主要原因是它的线性本质,并提出了快速梯度符号法FGSM。
摘要
包括神经网络在内的一些机器学习模型始终会被对抗样本误导,这些对抗样本通过注入小但故意破坏的扰动而形成,这样的对抗样本会导致模型以高置信度输出错误答案。早期的工作尝试用非线性特征和过拟合去解释这种现象。相反,我们认为神经网络易受对抗性扰动影响的主要原因是它们的线性本质。基于这个假设,我们提出了简单快速的生成对抗样本的方法即快速梯度符号法(Fast Gradient Sign Method),使用这种方法为对抗训练提供示例,并减少了在MNIST数据集上训练的模型的测试集误差。
引言
Szegedy 等人 (2014b) 得到了一个有趣的发现:包括最先进的神经网络在内的几种机器学习模型很容易受到对抗样本的影响。也就是说,这些机器学习模型对对抗性示例进行了错误分类,这些示例与从数据分布中提取的正确分类示例仅略有不同。在许多情况下,在训练数据的不同子集上训练的具有不同架构的各种各样的模型对相同的对抗性示例进行了错误分类。这表明对抗性示例暴露了我们训练算法中的基本盲点。
这些对抗性例子的原因是一个谜,推测性的解释表明这是由于深度神经网络的极端非线性,可能与模型平均不足和纯监督学习问题的正则化不足相结合。作者证明了这些推测性的假设是不必要的。高维空间中的线性行为足以引起对抗性例子。这种观点使作者能够设计一种快速生成对抗性示例的方法,使得对抗训练变得切实可行。我们发现对抗训练可以提供比单独使用dropout (Srivastava et al., 2014)更大的正则化益处。通用正则化策略(例如 dropout、预训练和模型平均)不会显着降低模型对对抗性示例的脆弱性,但更改为非线性模型系列(例如 RBF 网络)可以做到这一点。
我们的解释表明,在设计由于线性而易于训练的模型和设计使用非线性效应来应对对抗样本的模型之间存在着一种基本的张力。从长远来看,通过设计更强大的优化方法来成功地训练更多的非线性模型,有可能避免这种权衡。
相关工作
Szegedy等人(2014b)演示了神经网络和相关模型的各种有趣特性。与本文件最相关的包括:
- Box-constrained L-BFGS可以可靠地找到对抗样本。
- 在一些数据集上,如ImageNet (Deng et al., 2009),对抗例子与原始例子非常接近,以至于人眼无法分辨出差异。
- 同一对抗实例经常被具有不同架构的各种分类器或者在训练集的不同子集上训练的分类器错误分类。
- 浅的softmax回归模型也容易受到敌对例子的影响。
- 在对抗样本上进行训练可以正则化模型——然而,这在当时是不实际的,因为需要在内部循环中进行昂贵的约束优化。
这些结果表明,即使是那些基于现代机器学习技术并在测试集上获得优异性能的分类器,也没有学习到真正的底层概念,这些概念决定了正确的输出标签。相反,这些算法建立了一个Potemkin village以很好地处理自然发生的数据,但当访问点在数据分布中不具有高概率时,就会暴露为假数据。这尤其令人失望,因为计算机视觉中一个流行的方法是使用卷积网络特征作为一个空间,其中欧几里德距离接近感知距离。如果图像的感知距离非常小,而它们对应的是网络中完全不同的类别,那么这种相似性显然是有缺陷的。
这些结果经常被解释为深层网络的缺陷,特别是,即使线性分类器也有同样的问题。我们把对这个缺陷的了解看作是一个修正它的机会。事实上,Gu & Rigazio(2014)和Chalupka等人(2014)已经开始了设计对抗扰动模型的第一步,尽管目前还没有一个模型能够成功做到这一点,同时还能保持干净输入数据上的最高准确性。
对抗样本的线性解释
首先解释线性模型中对抗性例子的存在。

这也说明了当一个简单的线性模型的输入具有足够的维度时,也会有对抗样本。
非线性模型的线性扰动

线性模型的对抗训练
对抗训练是将对抗样本加入训练集中,增强模型鲁棒性。

深度网络的对抗训练
比于线性模型,深度网络至少可以在训练网络过程中来抵御对抗扰动攻击。文章给一种利用FGSM进行对抗训练的方法:
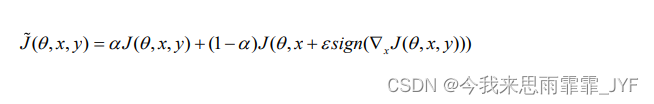
这种对抗训练的方法意味着在训练过程中不断更新对抗样本,从而使得当前模型可以抵御对抗样本。利用该方法训练一个同样使用dropout正则化的maxout网络,我们能够将错误率从没有进行对抗训练的0.94%降低到进行对抗训练的0.84%。
我们观察到,我们在训练集上的对抗性示例上并未达到零错误率。我们通过进行两项更改解决了这个问题。首先,我们使模型变得更大,每层使用 1600 个单元,而不是解决此问题的原始 maxout 网络使用的 240 个单元。如果没有对抗性训练,这会导致模型轻微过拟合,在测试集上的错误率为 1.14%。通过对抗性训练,我们发现验证集误差随着时间的推移趋于平稳,并且进展非常缓慢。原始的maxout结果使用了早期停止,并在验证集错误率100个epoch没有下降后终止学习。我们发现,虽然验证集的误差非常平缓,但对抗验证集的误差却不是这样。因此,我们在对抗验证集错误时使用早期停止。使用这个标准来选择要训练的epoch的数量,然后我们对所有60000个示例进行重新训练。使用随机数生成器的不同种子进行五次不同的训练运行,随机数生成器用于选择小批量训练示例、初始化模型权重并生成 dropout mask,结果是四项试验的测试集错误率为 0.77%,一项试验的错误率为 0.77%。错误率为0.83%。平均值为0.782%是MNIST置换不变版本报告的最佳结果,尽管与使用dropout微调DBMs (Srivastava et al., 2014)获得的结果在统计学上没有区别(0.79%)。
该模型也对对抗性例子产生了一定的抵抗力。回想一下,在没有对抗训练的情况下,基于快速梯度符号方法的同类模型在对抗样本上的错误率为 89.4%。通过对抗性训练,错误率降至 17.9%。对抗性示例可以在两个模型之间转移,但经过对抗性训练的模型表现出更大的鲁棒性。通过原始模型生成的对抗性示例在经过对抗性训练的模型上产生的错误率为 19.6%,而通过新模型生成的对抗性示例在原始模型上产生的错误率为 40.9%。当对抗性训练的模型确实对对抗性示例进行错误分类时,不幸的是,它的预测仍然高度可信。错误分类示例的平均置信度为 81.4%。我们还发现,学习模型的权重发生了显着变化,对抗训练模型的权重明显更加本地化和可解释(见图 3)。

当数据受到对手干扰时,对抗性训练过程可以被视为最小化最坏情况的错误。这可以解释为学习玩对抗性游戏,或者最小化噪声样本的预期成本上限,并将来自 U(−e, e) 的噪声添加到输入中。对抗性训练也可以被视为主动学习的一种形式,其中模型能够请求新点上的标签。在这种情况下,人工贴标机被替换为启发式贴标机,该贴标机从附近的点复制标签。
我们还可以通过对 e 最大范数框内的所有点进行训练,或对该框内的许多点进行采样,将模型正则化,使其对其小于 e 精度的特征变化不敏感。这对应于在训练期间添加具有最大范数的噪声。然而,零均值和零协方差的噪声在防止对抗性示例方面效率非常低。任何参考向量与此类噪声向量之间的预期点积为零。这意味着在许多情况下,噪声基本上不会产生任何影响,而不是产生更困难的输入。
事实上,在许多情况下,噪声实际上会导致目标函数值降低。我们可以将对抗性训练视为在一组噪声输入中进行困难示例挖掘,以便通过仅考虑那些强烈抵制分类的噪声点来更有效地进行训练。
由于符号函数的导数在任何地方都为零或未定义,因此基于快速梯度符号方法的对抗目标函数的梯度下降不允许模型预测对手对参数变化的反应。如果我们使用基于小旋转或添加缩放梯度的对抗性示例,那么扰动过程本身是可微的,并且学习可以考虑对手的反应。然而,我们并没有从这个过程中发现几乎同样强大的正则化结果,也许是因为这些类型的对抗性例子并不那么难以解决。
一个自然的问题是扰动输入层或隐藏层或两者是否更好。这里的结果是不一致的。Szegedy等人(2014b)报道了当应用于隐藏层时,对抗扰动产生最佳正则化。这一结果是在一个s形网络上得到的。在我们使用快速梯度符号法进行的实验中,我们发现具有激活无界的隐藏单元的网络简单地通过使其隐藏单元激活非常大来响应,因此通常只对原始输入进行扰动会更好。在 Rust 模型等饱和模型上,我们发现输入的扰动与隐藏层的扰动表现相当。基于旋转隐藏层的扰动解决了无界激活增长的问题,使相加扰动相比之下更小。我们能够通过隐藏层的旋转扰动成功训练 maxout 网络。然而,这并没有产生几乎像输入层的附加扰动那样强的正则化效应。我们对对抗性训练的看法是,只有当模型有能力学习抵抗对抗性例子时,它才明显有用。只有当通用逼近定理适用时,情况才是清楚的。因为神经网络的最后一层,linear-sigmoid或linear-softmax层,并不是最后一层隐层函数的通用近似器,这表明当对最后一层隐层应用对抗扰动时,很可能会遇到欠拟合的问题。我们确实发现了这种效应。我们使用隐藏层的扰动进行训练的最佳结果从不涉及最终隐藏层的扰动。
对抗样本泛化原因
我们都知道很多论文都表明,对抗样本具有Transferability。具体来说,在一个特定模型上产生的对抗样本通常也容易被其他模型误分类,即使这些模型的结构不同或者模型在不同的训练集上训练。甚至,不同的模型对对抗样本误分类的结果相同!作者表明,非线性或者过拟合的假设不能解释上述的现象,即, 为什么拥有无限能力的极度非线性模型会以相同的方式标注分布外点?
在本文提出的线性解释下,作者认为对抗样本在广泛的子空间存在。图 4 演示了这种现象,在不同的e下,可以看到FGSM可以在一维的连续子空间内产生对抗样本,而不是特定的区域。这就解释了为什么对抗样本特别多,以及对抗样本transferability存在的原因。
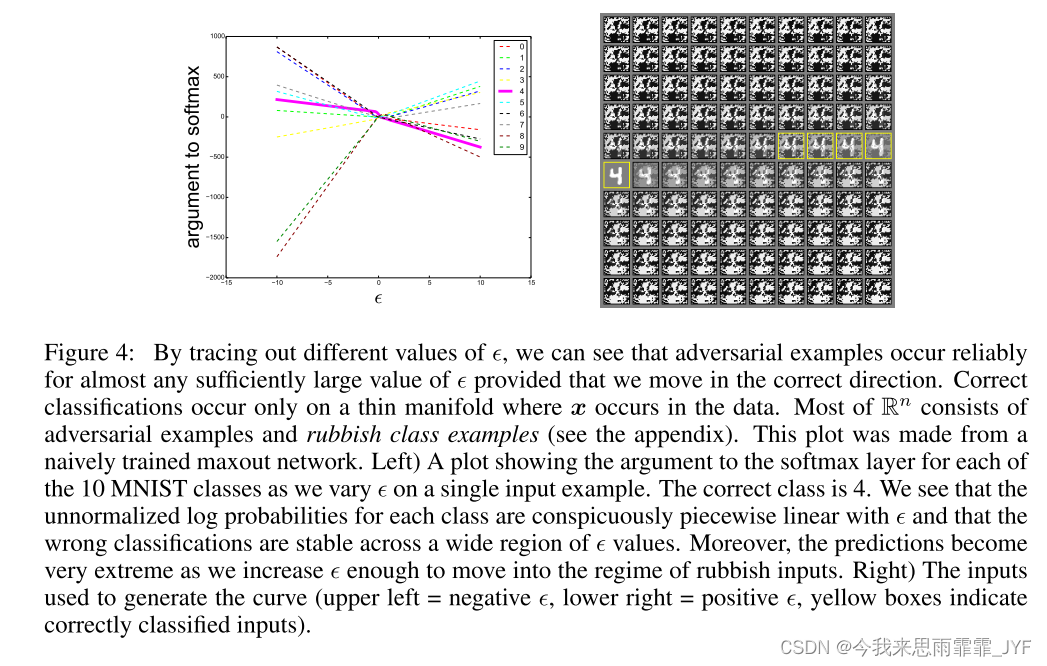
为了解释为什么多个分类器将同一类分配给对抗性示例,我们假设使用当前方法训练的神经网络都类似于在同一训练集上学习的线性分类器。当在训练集的不同子集上进行训练时,该参考分类器能够学习大致相同的分类权重,这仅仅是因为机器学习算法能够泛化。基础分类权重的稳定性反过来又导致对抗性示例的稳定性。
为了检验这个假设,我们在深度 maxout 网络上生成对抗性示例,并使用浅层 softmax 网络和浅层 RBF 网络对这些示例进行分类。对于maxout网络误分类的例子,RBF网络预测maxout网络的类分配的概率只有16.0%,而softmax分类器预测maxout网络的类分配的准确率为54.6%。这些数字很大程度上是由不同模型的错误率所决定的。如果我们不考虑两个模型比较都出错的情况,那么softmax回归预测maxout类的概率为84.6%,而RBF网络预测maxout类的概率仅为54.3%。相比之下,RBF 网络可以在 53.6% 的时间内预测 softmax 回归的类别,因此它的自身行为确实具有很强的线性成分。我们的假设并不能解释所有 maxout 网络的错误或所有跨模型泛化的错误,但显然其中很大一部分与线性行为一致,线性行为是跨模型泛化的主要原因。
对抗样本存在性的其他假设
我们现在考虑并反驳一些关于对抗性例子存在的替代假设。首先,一个假设是生成训练可以对训练过程提供更多约束,或者使模型学习如何区分“真实”数据和“假”数据,并且只对“真实”数据有信心。MP-DBM(Goodfellow 等人,2013a)提供了一个很好的模型来检验这一假设。其推理过程在 MNIST 上获得了良好的分类精度(错误率为 0.88%)。这个推理过程是可微的。其他生成模型要么具有不可微的推理过程,使得计算对抗性示例变得更加困难,要么需要额外的非生成判别器模型才能在 MNIST 上获得良好的分类精度。在 MP-DBM 的情况下,我们可以确定生成模型本身正在响应对抗性示例,而不是顶部的非生成分类器模型。我们发现该模型很容易受到对抗性例子的影响。当 e 为 0.25 时,我们发现 MNIST 测试集生成的对抗性示例的错误率为 97.5%。某些其他形式的生成训练仍然可能会产生抵抗力,但显然,仅生成这一事实还不够。
关于为什么存在对抗性例子的另一个假设是,单个模型有奇怪的怪癖,但对许多模型进行平均可能会导致对抗性例子被淘汰。为了检验这个假设,我们在 MNIST 上训练了 12 个 maxout 网络的集合。每个网络都使用不同的随机数生成器种子进行训练,随机数生成器用于初始化权重、生成 dropout mask 以及选择小批量数据进行随机梯度下降。在设计用于扰乱整个集成的对抗性示例上,集成的错误率为 91.1%,且 e= 0.25。如果我们使用旨在仅扰乱整体中一名成员的对抗性示例,则错误率会降至 87.9%。集成仅提供有限的对抗性扰动抵抗力。
总结与讨论
- 对抗性例子可以解释为高维点积的属性。它们是模型过于线性而不是过于非线性的结果。
- 不同模型中对抗性示例的泛化可以解释为对抗性扰动与模型的权重向量高度一致,并且不同模型在训练执行相同任务时学习相似的功能。
- 最重要的是扰动的方向,而不是空间中的特定点。特征空间中并没有充满像有理数那样精细地平铺实数的对抗性例子。
- 因为方向是最重要的,所以对抗性扰动可以泛化到不同的干净例子中。
- 我们引入了一系列用于生成对抗性示例的快速方法。
- 我们已经证明,对抗性训练可以带来正则化;甚至比 dropout 更进一步的正规化。
- 我们进行了控制实验,但未能使用更简单但效率较低的正则化器(包括 L1 权重衰减和添加噪声)重现这种效果。
- 易于优化的模型也很容易受到干扰。
- 线性模型缺乏抵抗对抗性扰动的能力;只有具有隐藏层的结构(通用逼近定理适用的地方)才应该被训练以抵抗对抗性扰动。
- RBF 网络能够抵抗对抗性例子。
- 经过训练来对输入分布进行建模的模型无法抵抗对抗性示例。
- 模型集成不能抵抗对抗性例子。
(有些地方确实没明白作者的意思,欢迎留言指教!)