很多人在学习数据库知识的时候,知识点都是比较分散的,本章旨在将数据库知识进行整合串联,使之可以达到知其所以然的地步。
从数据结构说起
(1)时间复杂度
对于数据库本身而言,重要不仅仅是数据量,而是在数据量增长之后如何增加相应的运算能力?
时间复杂度用来检验某个算法处理一定量的数据要花多长时间,时间复杂度不会给出确切的运算次数,但是给出的是一种理念。
 (1) 绿:O(1)或者叫常数阶复杂度,保持为常数(要不人家就不会叫常数阶复杂度了)。
(1) 绿:O(1)或者叫常数阶复杂度,保持为常数(要不人家就不会叫常数阶复杂度了)。
(2)红:O(log(n))对数阶复杂度,即使在十亿级数据量时也很低。
(3)粉:最糟糕的复杂度是 O(n^2),平方阶复杂度,运算数快速膨胀。
(4)黑和蓝:另外两种复杂度(的运算数也是)快速增长。
如果要处理2000条元素?
O(1) 算法会消耗 1 次运算
O(log(n)) 算法会消耗 7 次运算
O(n) 算法会消耗 2000 次运算
O(n*log(n)) 算法会消耗 14,000 次运算
O(n^2) 算法会消耗 4,000,000 次运算
(2)归并排序
理解 sort() 函数的工作原理
(3)二叉搜索树
数据库中查询的时间复杂度,是我们无法使用矩阵,转而使用二叉搜索树
二叉搜索树只需 log(N) 次运算,而如果你直接使用阵列则需要 N 次运算
(4)B+树索引
查找一个特定值这个树挺好用,但是当你需要查找两个值之间的多个元素时,就会有大麻烦了。你的成本将是 O(N),因为你必须查找树的每一个节点,以判断它是否处于那 2 个值之间(例如,对树使用中序遍历)。而且这个操作不是磁盘I/O有利的,因为你必须读取整个树。
这就是为什么引入B+树索引
如果你在数据库中增加或删除一行(从而在相关的 B+树索引里):
(1)你必须在B+树中的节点之间保持顺序,否则节点会变得一团糟,你无法从中找到想要的节点.
(2)你必须尽可能降低B+树的层数,否则 O(log(N)) 复杂度会变成 O(N).
(5)哈希表
当你想快速查找值时,哈希表是非常有用的。而且,理解哈希表会帮助我们接下来理解一个数据库常见的联接操作,叫做『哈希联接』。这个数据结构也被数据库用来保存一些内部的东西(比如锁表或者缓冲池,我们在下文会研究这两个概念)。
为什么不用阵列呢?
(1)如果有了好的哈希函数,在哈希表里搜索的时间复杂度是 O(1)。
(2)一个哈希表可以只装载一半到内存,剩下的哈希桶可以留在硬盘上。
(3)用阵列的话,你需要一个连续内存空间。如果你加载一个大表,很难分配足够的连续内存空间.
全局概览
我们已经了解了数据库内部的部分重要算法,现在我们需要回来看看数据库的全貌了。
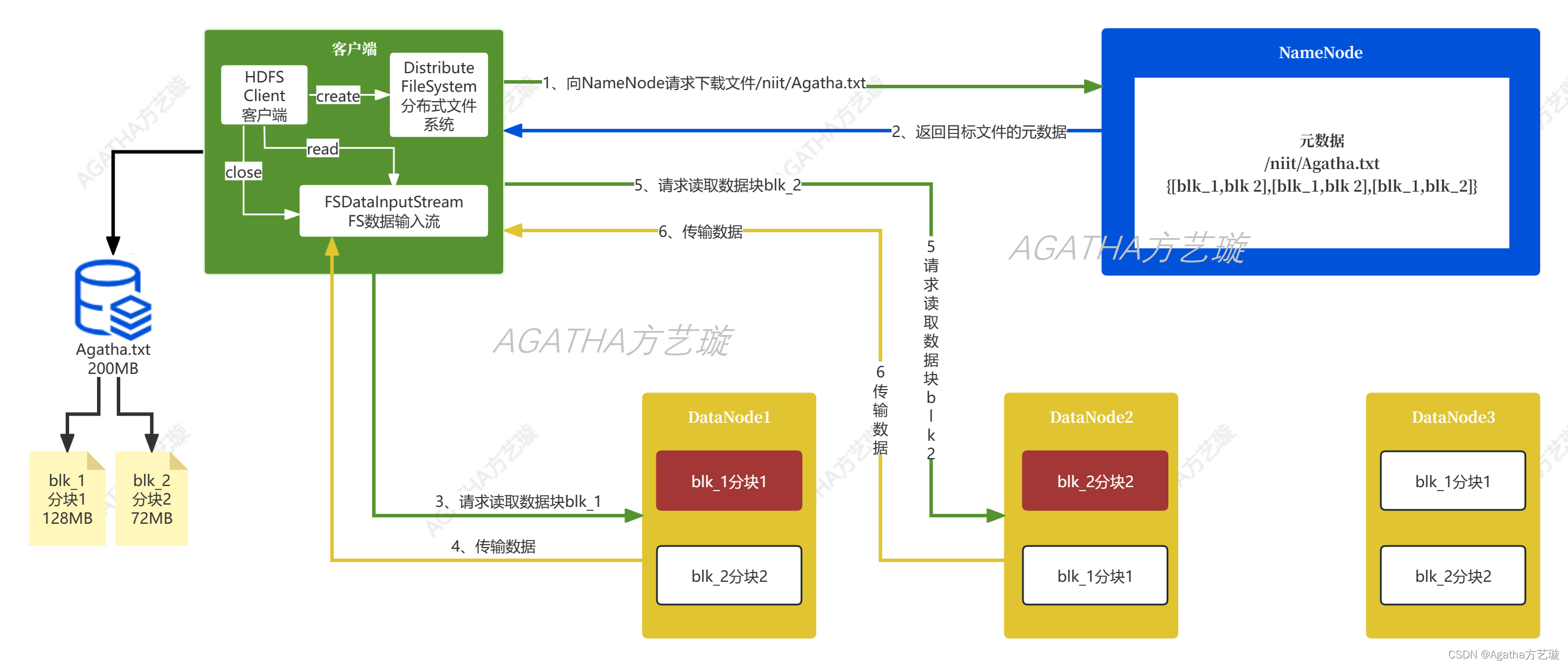
数据库一般可以用如下图形来理解:

核心组件
(1)进程管理器(process manager):很多数据库具备一个需要妥善管理的进程/线程池。再者,为了实现纳秒级操作,一些现代数据库使用自己的线程而不是操作系统线程。
(2)网络管理器(network manager):网路I/O是个大问题,尤其是对于分布式数据库。所以一些数据库具备自己的网络管理器。
(3)文件系统管理器(File system manager):磁盘I/O是数据库的首要瓶颈。具备一个文件系统管理器来完美地处理OS文件系统甚至取代OS文件系统,是非常重要的。
(4)内存管理器(memory manager):为了避免磁盘I/O带来的性能损失,需要大量的内存。但是如果你要处理大容量内存你需要高效的内存管理器,尤其是你有很多查询同时使用内存的时候。
(5)安全管理器(Security Manager):用于对用户的验证和授权。
(6)客户端管理器(Client manager):用于管理客户端连接。
…
Tools
(1)备份管理器(Backup manager):用于保存和恢复数据。
(2)恢复管理器(Recovery manager):用于崩溃后重启数据库到一个一致状态。
(3)监控管理器(Monitor manager):用于记录数据库活动信息和提供监控数据库的工具
(4)管理员管理器(Administration manager):用于保存元数据(比如表的名称和结构),提供管理数据库、模式、表空间的工具。
…
Query Manager
(1)查询解析器(Query parser):用于检查查询是否合法
(2)查询重写器(Query rewriter):用于预优化查询
(3)查询优化器(Query optimizer):用于优化查询
(4)查询执行器(Query executor):用于编译和执行查询
Data Manager
(1)事务管理器(Transaction manager):用于处理事务
(2)缓存管理器(Cache manager):数据被使用之前置于内存,或者数据写入磁盘之前置于内存.
(3)数据访问管理器(Data access manager):访问磁盘中的数据
数据查询的流程(Client Manager)
客户端管理器是处理客户端通信的。客户端可以是一个(网站)服务器或者一个最终用户或最终应用。客户端管理器通过一系列知名的API(JDBC, ODBC, OLE-DB …)提供不同的方式来访问数据库。客户端管理器也提供专有的数据库访问API。

当你连接到数据库时:
(1)管理器首先检查你的验证信息(用户名和密码),然后检查你是否有访问数据库的授权。这些权限由DBA分配。
(2)然后,管理器检查是否有空闲进程(或线程)来处理你对查询.
(3)管理器还会检查数据库是否负载很重.
(4)管理器可能会等待一会儿来获取需要的资源。如果等待时间达到超时时间,它会关闭连接并给出一个可读的错误信息。
(5)然后管理器会把你的查询送给查询管理器来处理.
(6)因为查询处理进程不是『不全则无』的,一旦它从查询管理器得到数据,它会把部分结果保存到一个缓冲区并且开始给你发送。
(7)如果遇到问题,管理器关闭连接,向你发送可读的解释信息,然后释放资源。
查询管理器
这部分是数据库的威力所在,在这部分里,一个写得糟糕的查询可以转换成一个快速执行的代码,代码执行的结果被送到客户端管理器。

这个多步骤操作过程如下:
(1)查询首先被解析并判断是否合法
(2)然后被重写,去除了无用的操作并且加入预优化部分
(3)接着被优化以便提升性能,并被转换为可执行代码和数据访问计划。
(4)然后计划被编译
(5)最后,被执行
查询解析器
每一条SQL语句都要送到解析器来检查语法,如果你的查询有错,解析器将拒绝该查询.
但这还不算完,解析器还会检查关键字是否使用正确的顺序,比如 WHERE 写在 SELECT 之前会被拒绝。
然后,解析器要分析查询中的表和字段,使用数据库元数据来检查:
(1)表是否存在
(2)表的字段是否存在
(3)对某类型字段的 运算 是否 可能(比如,你不能将整数和字符串进行比较,你不能对一个整数使用 substring() 函数)
a.接着,解析器检查在查询中你是否有权限来读取(或写入)表。这些权限由DBA分配。
b.在解析过程中,SQL 查询被转换为内部表示(通常是一个树)
c.如果一切正常,内部表示被送到查询重写器。
查询重写器
在这一步,我们已经有了查询的内部表示,重写器的目标是:
(1)预优化查询
(2)避免不必要的运算
(3)帮助优化器找到合理的最佳解决方案
重写器按照一系列已知的规则对查询执行检测。如果查询匹配一种模式的规则,查询就会按照这条规则来重写。下面是(可选)规则的非详尽的列表:
1.视图合并:如果你在查询中使用视图,视图就会转换为它的 SQL 代码。
2.子查询扁平化:子查询是很难优化的,因此重写器会尝试移除子查询
例如:
SELECT PERSON.*
FROM PERSON
WHERE PERSON.person_key IN
(SELECT MAILS.person_key
FROM MAILS
WHERE MAILS.mail LIKE 'christophe%');
会转换为:
SELECT PERSON.*
FROM PERSON, MAILS
WHERE PERSON.person_key = MAILS.person_key
and MAILS.mail LIKE 'christophe%';
1.去除不必要的运算符:比如,如果你用了 DISTINCT,而其实你有 UNIQUE 约束(这本身就防止了数据出现重复),那么 DISTINCT 关键字就被去掉了。
2.排除冗余的联接:如果相同的 JOIN 条件出现两次,比如隐藏在视图中的 JOIN 条件,或者由于传递性产生的无用 JOIN,都会被消除。
3.常数计算赋值:如果你的查询需要计算,那么在重写过程中计算会执行一次。比如 WHERE AGE > 10+2 会转换为 WHERE AGE > 12 , TODATE(“日期字符串”) 会转换为 datetime 格式的日期值。
4.(高级)分区裁剪(Partition Pruning):如果你用了分区表,重写器能够找到需要使用的分区。
5.(高级)物化视图重写(Materialized view rewrite):如果你有个物化视图匹配查询谓词的一个子集,重写器将检查视图是否最新并修改查询,令查询使用物化视图而不是原始表。
6.(高级)自定义规则:如果你有自定义规则来修改查询(就像 Oracle policy),重写器就会执行这些规则。
7.(高级)OLAP转换:分析/加窗 函数,星形联接,ROLLUP 函数……都会发生转换(但我不确定这是由重写器还是优化器来完成,因为两个进程联系很紧,必须看是什么数据库)
统计
数据库和操作系统如何保存数据。两者使用的最小单位叫做页或块(默认 4 或 8 KB)。这就是说如果你仅需要 1KB,也会占用一个页。要是页的大小为 8KB,你就浪费了 7KB。
当你要求数据库收集统计信息,数据库会计算下列值:
1.表中行和页的数量
2.表中每个列中的:--唯一值--数据长度(最小,最大,平均)--数据范围(最小,最大,平均)
3.表的索引信息
这些统计信息会帮助优化器估计查询所需的磁盘 I/O、CPU、和内存使用
对每个列的统计非常重要。比如,如果一个表 PERSON 需要联接 2 个列: LAST_NAME, FIRST_NAME。根据统计信息,数据库知道FIRST_NAME只有 1,000 个不同的值,LAST_NAME 有 1,000,000 个不同的值。因此,数据库就会按照 LAST_NAME, FIRST_NAME 联接。因为 LAST_NAME 不大可能重复,多数情况下比较 LAST_NAME 的头 2 、 3 个字符就够了,这将大大减少比较的次数。
不过,这些只是基本的统计。你可以让数据库做一种高级统计,叫直方图。直方图是列值分布情况的统计信息。例如:
1.出现最频繁的值
2.出现最频繁的值
......
这些额外的统计会帮助数据库找到更佳的查询计划,尤其是对于等式谓词(例如: WHERE AGE = 18 )或范围谓词(例如: WHERE AGE > 10 and AGE < 40),因为数据库可以更好的了解这些谓词相关的数字类型数据行(注:这个概念的技术名称叫选择率)
统计信息保存在数据库元数据内,例如(非分区)表的统计信息位置:
1.Oracle: USER / ALL / DBA_TABLES 和 USER / ALL / DBA_TAB_COLUMNS
2.DB2: SYSCAT.TABLES 和 SYSCAT.COLUMNS
统计信息必须及时更新。如果一个表有 1,000,000 行而数据库认为它只有 500 行,没有比这更糟糕的了。统计唯一的不利之处是需要时间来计算,这就是为什么数据库大多默认情况下不会自动计算统计信息。数据达到百万级时统计会变得困难,这时候,你可以选择仅做基本统计或者在一个数据库样本上执行统计。
查询优化器
所有的现代数据库都在用基于成本的优化(即CBO)来优化查询。道理是针对每个运算设置一个成本,通过应用成本最低廉的一系列运算,来找到最佳的降低查询成本的方法。
举例:即便一个简单的联接查询对于优化器来说都是个噩梦
索引
1. 要记住一点,索引都是已经排了序的
2. 另外,很多现代数据库为了改善执行计划的成本,可以仅为当前查询动态地生成临时索引
存取路径
在应用联接运算符(join operators)之前,你首先需要获得数据。以下就是获得数据的方法:
1.全扫描--简单的说全扫描就是数据库完整的读一个表或索引。就磁盘 I/O 而言,很明显全表扫描的成本比索引全扫描要高昂
2.范围扫描--其他类型的扫描有索引范围扫描,比如当你使用谓词 ” WHERE AGE > 20 AND AGE < 40 ” 的时候它就会发生(当然,你需要在 AGE 字段上有索引才能用到索引范围扫描)
3.唯一扫描--你只需要从索引中取一个值可以用唯一扫描
4.根据 ROW ID 存取--多数情况下,如果数据库使用索引,它就必须查找与索引相关的行,这样就会用到根据 ROW ID 存取的方式。例如,假如你运行:SELECT LASTNAME, FIRSTNAME from PERSON WHERE AGE = 28如果 person 表的 age 列有索引,优化器会使用索引找到所有年龄为 28 的人,然后它会去表中读取相关的行,这是因为索引中只有 age 的信息而你要的是姓和名但是,假如你换个做法:SELECT TYPE_PERSON.CATEGORY from PERSON ,TYPE_PERSONWHERE PERSON.AGE = TYPE_PERSON.AGEPERSON 表的索引会用来联接 TYPE_PERSON 表,但是 PERSON 表不会根据行ID 存取,因为你并没有要求这个表内的信息。虽然这个方法在少量存取时表现很好,这个运算的真正问题其实是磁盘 I/O。假如需要大量的根据行ID存取,数据库也许会选择全扫描

![[极客大挑战 2019]LoveSQL 1](https://img-blog.csdnimg.cn/img_convert/1a0380212085fca284886acd6a919253.png)



![[架构之路-252/创业之路-83]:目标系统 - 纵向分层 - 企业信息化的呈现形态:常见企业信息化软件系统 - 企业应用信息系统集成](https://img-blog.csdnimg.cn/f58d23300a22497991ad91de2b2b57ff.png)