ElasticSearch系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】ElasticSearch下载和安装 | https://zhenghuisheng.blog.csdn.net/article/details/129260827 |
| 【二】ElasticSearch概念和基本操作 | https://blog.csdn.net/zhenghuishengq/article/details/134121631 |
| 【三】ElasticSearch的高级查询Query DSL | https://blog.csdn.net/zhenghuishengq/article/details/134159587 |
| 【四】ElasticSearch的聚合查询操作 | https://blog.csdn.net/zhenghuishengq/article/details/134159587 |
ElasticSearch的聚合查询操作
- 一,深入理解es的聚合查询
- 1,Metric Aggregation
- 2,Bucket Aggregation
- 3,Pipeline Aggregation
- 4,ElasticSearch聚合结果不精准原因
- 4.1,不精准原因
- 4.2,如何提高精准度
- 4.3,聚合查询优化
一,深入理解es的聚合查询
在关系型数据库中,存在聚合操作,如mysql的求最大值,最小值,平均值等。在es中,也是存在着这些操作的。
在Elasticsearch中,聚合操作可以分为三类,分别是 Metric Aggregation 、Bucket Aggregation 、Pipeline Aggregation
在针对具体的类型之前,先创建一个索引库,后面的举例都会用到该索引库。首先先创建一个员工索引库,如下面两个属性,一个是姓名,不需要分词,一个是工资
DELETE /employees
#创建索引库
PUT /employees
{"mappings": {"properties": {"name":{"type": "keyword"},"salary":{"type": "integer"}}}
}
创建完成之后,往里面插入一些数据,这里插入10条即可
PUT /employees/_bulk
{ "index" : { "_id" : "1" } }
{ "name" : "huisheng1","salary":35000 }
{ "index" : { "_id" : "2" } }
{ "name" : "huisheng2","salary": 50000}
{ "index" : { "_id" : "3" } }
{ "name" : "huisheng3","salary":18000 }
{ "index" : { "_id" : "4" } }
{ "name" : "huisheng4","salary": 22000}
{ "index" : { "_id" : "5" } }
{ "name" : "huisheng5","salary":18000 }
{ "index" : { "_id" : "6" } }
{ "name" : "huisheng6","salary": 25000}
{ "index" : { "_id" : "7" } }
{ "name" : "huisheng7","salary":20000 }
{ "index" : { "_id" : "8" } }
{ "name" : "huisheng8","salary": 20000}
{ "index" : { "_id" : "9" } }
{ "name" : "huisheng9","salary":22000 }
{ "index" : { "_id" : "10" } }
{ "name" : "huisheng10","salary": 9000}
1,Metric Aggregation
表示的是一些数学运算,可以对文档字段进行统计分析,比如说求min,max,avg等
如求用户的最大工资,就是上面salary字段的最大值,需要通过max关键字。在返回数据时,会将查询的数据以及最终的结果全部返回,因此可以加上一个size属性,其value设置为0
POST /employees/_search
{"size": 0,"aggs": { //前缀,固定搭配"max_salary": { //别名"max": { //需要的聚合操作"field": "salary"}}}
}
求用户的最小工资,需要通过min关键字
POST /employees/_search
{"size": 0,"aggs": {"min_salary": {"min": {"field": "salary"}}}
}
求用户的平均工资,需要通过这个avg的关键字
POST /employees/_search
{"size": 0,"aggs": {"avg_salary": {"avg": {"field": "salary"}}}
}
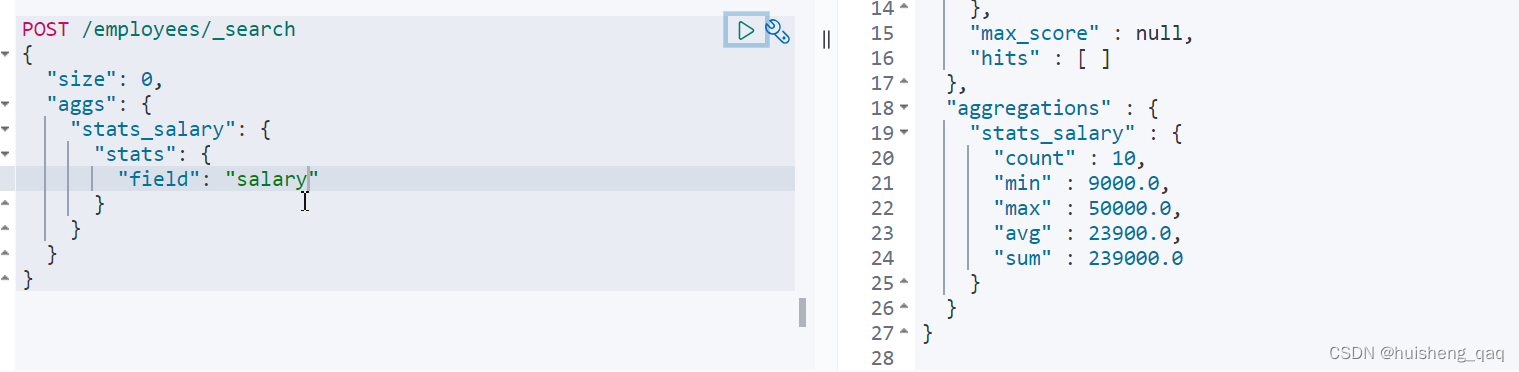
或者直接通过一个 stats ,将要查询的聚合结果值全部返回
POST /employees/_search
{"size": 0,"aggs": {"stats_salary": {"stats": {"field": "salary"}}}
}
去重操作,可以直接使用 cardinality 关键字,去重的字段必须是一个keyword的字段
POST /employees/_search
{"size": 0,"aggs": {"cardinate_salary": { //别名"cardinality": {"field": "salary"}}}
}
2,Bucket Aggregation
桶查询,类似于mysql的分组查询,将相同结果的放在一个桶里面,如对用户的姓名进行分组,最后再对每个组的数据进行统计,并以降序的方式。trems精确查询,一定是要对应 keyword 的字段
GET /employees/_search
{"size": 0,"aggs": {"name_count": {"terms": {"field":"name", //对用户姓名进行分组"size": 10,"order": {"_count": "desc" }}}}
}
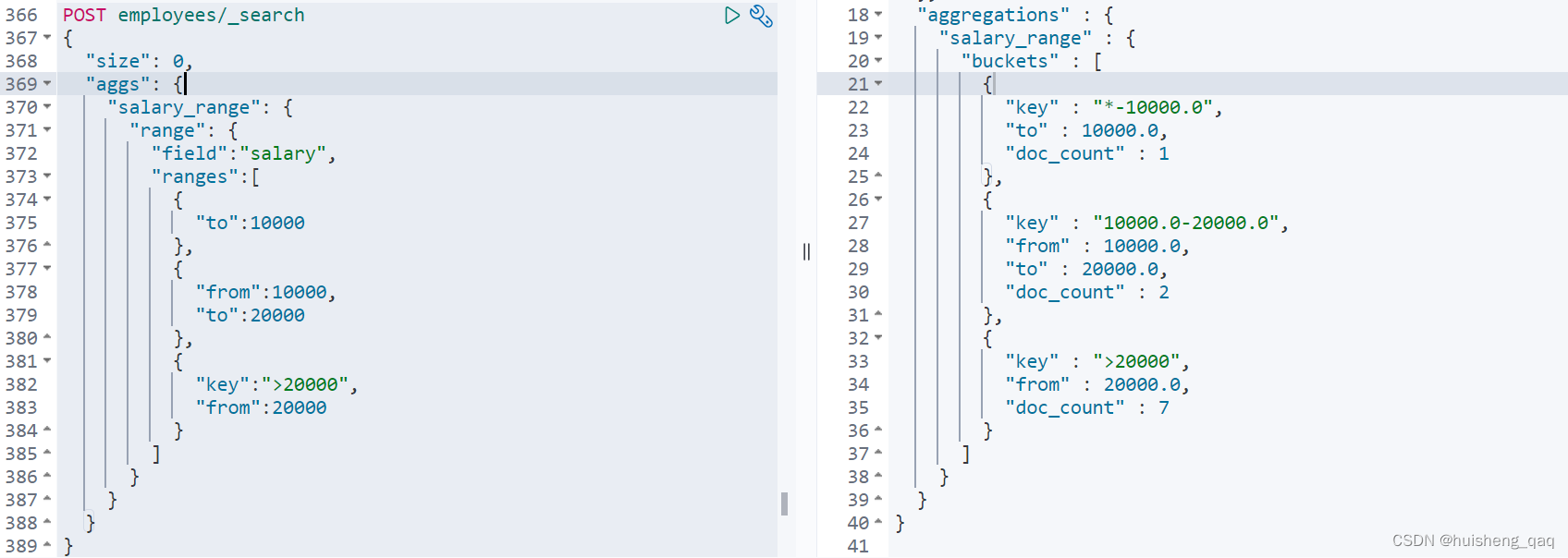
除了这个terms精确查询之外,还可以直接使用这个 ranges 进行分为分组,默认是从闭区间0开始,to的值为区间的结束值。如下面的区间就是 [0-100000),[10000,20000),[20000,无穷)
POST employees/_search
{"size": 0,"aggs": {"salary_range": {"range": {"field":"salary","ranges":[{"to":10000},{"from":10000,"to":20000},{"key":">20000","from":20000}]}}}
}
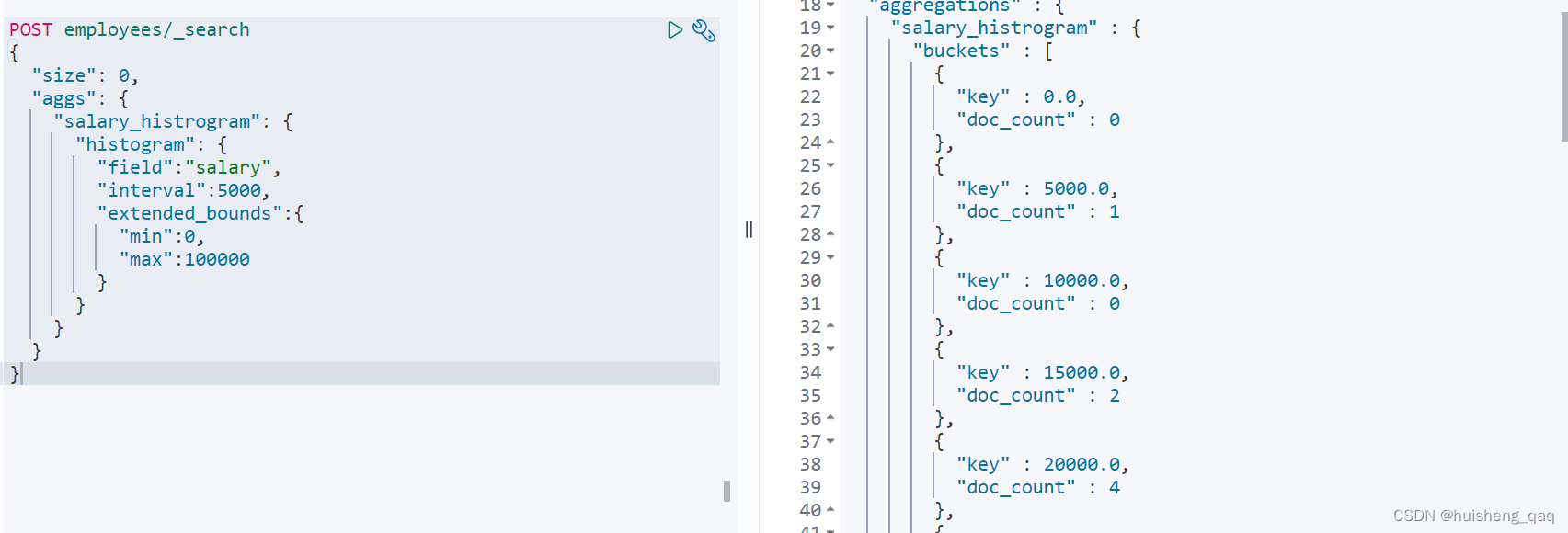
也可以直接按照直方图的方式进行区间分桶,如5000为一个区间
POST employees/_search
{"size": 0,"aggs": {"salary_histrogram": {"histogram": {"field":"salary","interval":5000,"extended_bounds":{"min":0, //直方图的起始值"max":50000 //直方图的最大值}}}}
}
上面的集合单个的查询中,可以直接通过聚合操作将上面的操作嵌套使用。如先分组,随后求分组后的最大值最小值,以及中间可以经过多次分组等。如下面的先通过工资进行分桶,随后再对每一个桶进行求最大值和最小值
POST /employees/_search
{"size": 0,"aggs": {"salary_count": {"terms": {"field": "salary"},"aggs": {"salary": {"stats": {"field": "salary"}}}}}
3,Pipeline Aggregation
表示的是支持聚合操作,允许将前面的结果作为后面的参数使用。如下面的例子,主要是看这个 stats_salary_by_name 里面的结果
POST /employees/_search
{"size": 0,"aggs": { "name": { //别名1"terms": {"field": "name"},"aggs": {"avg_salary": { //别名2"avg": {"field": "salary"}}}},"stats_salary_by_name":{"stats_bucket": { //桶名"buckets_path": "name>avg_salary" //桶路径}}}
}
除了这个 stats_bucket 用于求所有最大值最小值等聚合操作之外,还有下面的这些
cumulative_sum //累计求和
percentiles_bucket //求百分比
min_bucket //求最小值
4,ElasticSearch聚合结果不精准原因
在面对大数据量时,数据的实时性和精确度往往不能同时满足,就是要么只能满足精确度,要么只能满足数据的实时性
4.1,不精准原因
不准确的原因是因为在取数据时,协调者分片每次取的数据是每个分片的最大值的个数,而不是每个分片汇总后的最大值的个数。如取每个分片的top3的数据,如下所示,取出的数据是ABC,是因为第一个分片取出的数据是6、4、6,第二个分片取出的数据是6、2、3,协调者分片汇总数据的时候,会觉得c的结果4会大于d的结果3,所以将c的结果取出。
然而实际上在两个分片中,c的汇总为3+1等于4,d的汇总为3+3等于6,按理是需要将d的结果取出的,反而取出的是c,这就是造成数据不精准的原因

4.2,如何提高精准度
- 如果是数据量小的场景中,可以直接将主分片的值设置为1(推荐使用)
- 如果数据量大的场景,可以调大 shard_size 的值(推荐使用)
- 将size设置成全量值,不推荐使用
- 不用es,改用clickhouse/spark
4.3,聚合查询优化
1,启用 eager global ordinals 来提升高基数聚合性能,就是一个字段的的离散率大一点
2,在插入数据时进行预排序,如提前指定好需要排序的字段。但是这种方式会影响写性能,只适合读多写少的场景
PUT /my_index
{"settings": {"index":{"sort.field": "create_time","sort.order": "desc"}}
3,使用结点缓存Node query cache,可以有效缓存过滤器filter的值
4,使用分片缓存,在查询时直接设置size为0,只返回聚合结果,不返回查询结果
5,拆分聚合,使聚合并行化。通过msearch实现,将一个聚合拆分成多个查询