现有网络模型的使用与修改
vgg16_false = torchvision.models.vgg16(pretrained=False) # 加载一个未预训练的模型
vgg16_true = torchvision.models.vgg16(pretrained=True)
# 把数据分为了1000个类别print(vgg16_true)以下是vgg16预训练模型的输出
VGG((features): Sequential((0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU(inplace=True)(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU(inplace=True)(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(6): ReLU(inplace=True)(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(8): ReLU(inplace=True)(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace=True)(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(13): ReLU(inplace=True)(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(15): ReLU(inplace=True)(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(18): ReLU(inplace=True)(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(20): ReLU(inplace=True)(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(22): ReLU(inplace=True)(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(25): ReLU(inplace=True)(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(27): ReLU(inplace=True)(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(29): ReLU(inplace=True)(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))(classifier): Sequential((0): Linear(in_features=25088, out_features=4096, bias=True)(1): ReLU(inplace=True)(2): Dropout(p=0.5, inplace=False)(3): Linear(in_features=4096, out_features=4096, bias=True)(4): ReLU(inplace=True)(5): Dropout(p=0.5, inplace=False)(6): Linear(in_features=4096, out_features=1000, bias=True))
)预训练模型的输出从1000类别转为10类别
import torchvision
from torch import nn
# 因为数据集过大,所以注释掉此行代码
# train_data = torchvision.datasets.ImageNet("./data_image_net", split='train', download=True,
# transform=torchvision.transforms.ToTensor())vgg16_false = torchvision.models.vgg16(pretrained=False) # 加载一个未预训练的模型
vgg16_true = torchvision.models.vgg16(pretrained=True)
# 把数据分为了1000个类别print(vgg16_true)# vgg16_true.add_module("add_linear", nn.Linear(1000, 10))
vgg16_true.classifier.add_module("add_linear", nn.Linear(1000, 10))
# 在预训练模型的最后添加了一个新的全连接层,用于将最后的输出转化为10个类别
print(vgg16_true)print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096, 10)
# 未预训练模型的最后一层的输出特征数更改为了10
print(vgg16_false)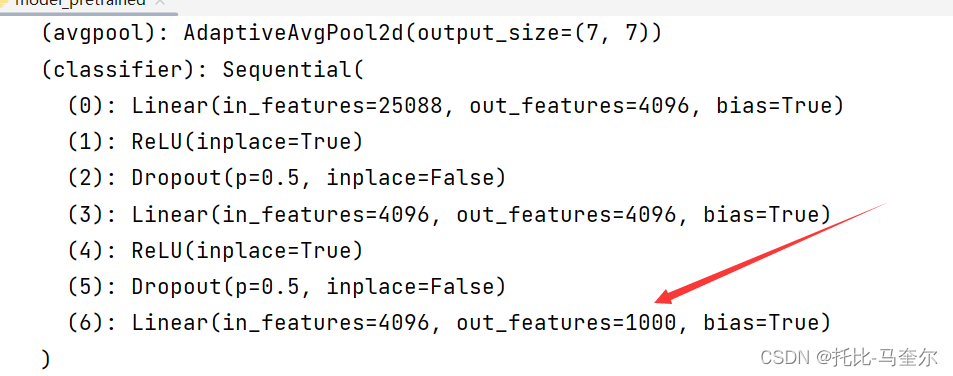
网络模型的保存与读取
加载未预训练的模型
vgg16 = torchvision.models.vgg16(pretrained=False)方式一
# 保存方式1 保存的模型结构+模型参数
torch.save(vgg16, "vgg16_method1.pyth")#读取方式1
model = torch.load("vgg16_method1.pth")方式二
# 保存方式2 不再保存模型结构,而是保存模型的参数为字典结构 推荐
torch.save(vgg16.state_dict(), "vgg16_method2.pyth")# 方式2,加载模型
# model = torch.load("vgg16_method2.pth") #这样输出的是字典类型
# print(model)
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth")) # 将其恢复为网络模型
print(vgg16)完整的模型训练套路
准备数据集
# 准备数据集
train_data = torchvision.datasets.CIFAR10("../data", train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),download=True)train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为{}".format(train_data_size)) # 50000
print("测试数据集的长度为{}".format(test_data_size)) # 10000# 利用Dataloader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)创建网络模型
# 创建网络模型 神经网络的代码在train_module文件
tudui = Tudui()train_module文件
# 搭建神经网络
class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()# 简化操作,并且按顺序进行操作self.model1 = Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):x = self.model1(x)return x构建损失函数
# 损失函数
loss_fn = nn.CrossEntropyLoss()构建优化器
# 优化器
# 如果学习率过大,模型可能会在最小值附近震荡而无法收敛;如果学习率过小,模型训练可能会过于缓慢
learning_rate = 0.01
# 使用随机梯度下降算法来更新模型的权重
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)设置训练集参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10添加tensorboard
# 将数据写入 TensorBoard 可视化的日志文件中
writer = SummaryWriter("../logs_train")训练步骤
# tudui.train()
for data in train_dataloader:imgs, targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs, targets)# 优化器优化模型optimizer.zero_grad()# 将优化器中的梯度缓存(如果有的话)清零loss.backward()# 计算损失函数(loss)相对于模型参数的梯度optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:# .item()是将tensor张量变为正常的数字print("训练次数:{},Loss:{}".format(total_train_step, loss.item()))# loss.item()是当前步骤的损失值writer.add_scalar("train_loss", loss.item(), total_train_step)# 使用add_scalar可以将一个标量添加到之前的所有标量值中,# 这样就可以在TensorBoard中绘制一个标量随时间变化的图表测试步骤

# 测试步骤开始
# tudui.eval()
total_test_loss = 0
total_accuracy = 0
# 不会对以下的代码进行调优
with torch.no_grad():for data in test_dataloader:imgs, targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs, targets)total_test_loss = total_test_loss + loss.item()# argmax(1)是横向看,argmax(0)是纵向看accuracy = (outputs.argmax(1) == targets).sum()# argmax在找到模型预测的最大概率对应的类别# 预测正确的个数total_accuracy = total_accuracy + accuracyprint("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
# 测试集上的总损失
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1