一、各组件版本
| 组件 | 版本 |
|---|---|
| Flink | 1.16.1 |
| kafka | 2.0.0 |
| Logstash | 6.5.4 |
| Elasticseach | 6.3.1 |
| Kibana | 6.3.1 |
针对按照⽇志⽂件⼤⼩滚动⽣成⽂件的⽅式,可能因为某个错误的问题,需要看好多个⽇志⽂件,还有Flink on Yarn模式提交Flink任务,在任务执行完毕或者任务报错后container会被回收从而导致日志丢失,为了方便排查问题可以把⽇志⽂件通过KafkaAppender写⼊到kafka中,然后通过ELK等进⾏⽇志搜索甚⾄是分析告警。
二、Flink配置将日志写入Kafka
2.1 flink-conf.yaml增加下面两行配置信息
env.java.opts.taskmanager: -DyarnContainerId=$CONTAINER_ID
env.java.opts.jobmanager: -DyarnContainerId=$CONTAINER_ID
2.2 log4j.properties配置案例如下
##################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
##################################################################
# Allows this configuration to be modified at runtime. The file will be checked every 30 seconds.
monitorInterval=30# This affects logging for both user code and Flink
#rootLogger.appenderRef.file.ref = MainAppender
rootLogger.level = INFO
rootLogger.appenderRef.kafka.ref = Kafka
rootLogger.appenderRef.file.ref = RollingFileAppender# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = INFO# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO
logger.shaded_zookeeper.name = org.apache.flink.shaded.zookeeper3
logger.shaded_zookeeper.level = INFO# Log all infos in the given file
appender.rolling.name = RollingFileAppender
appender.rolling.type = RollingFile
appender.rolling.append = false
appender.rolling.fileName = ${sys:log.file}
appender.rolling.filePattern = ${sys:log.file}.%i
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.rolling.policies.type = Policies
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size = 500MB
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = 10#appender.main.name = MainAppender
#appender.main.type = RollingFile
#appender.main.append = true
#appender.main.fileName = ${sys:log.file}
#appender.main.filePattern = ${sys:log.file}.%i
#appender.main.layout.type = PatternLayout
#appender.main.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
#appender.main.policies.type = Policies
#appender.main.policies.size.type = SizeBasedTriggeringPolicy
#appender.main.policies.size.size = 100MB
#appender.main.policies.startup.type = OnStartupTriggeringPolicy
#appender.main.strategy.type = DefaultRolloverStrategy
#appender.main.strategy.max = ${env:MAX_LOG_FILE_NUMBER:-10}# kafka
appender.kafka.type = Kafka
appender.kafka.name = Kafka
appender.kafka.syncSend = true
appender.kafka.ignoreExceptions = false
appender.kafka.topic = flink_logs
appender.kafka.property.type = Property
appender.kafka.property.name = bootstrap.servers
appender.kafka.property.value = xxx1:9092,xxx2:9092,xxx3:9092
appender.kafka.layout.type = JSONLayout
apender.kafka.layout.value = net.logstash.log4j.JSONEventLayoutV1
appender.kafka.layout.compact = true
appender.kafka.layout.complete = false# Suppress the irrelevant (wrong) warnings from the Netty channel handler
#logger.netty.name = org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.name = org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF#通过 flink on yarn 模式还可以添加⾃定义字段
# 日志路径
appender.kafka.layout.additionalField1.type = KeyValuePair
appender.kafka.layout.additionalField1.key = logdir
appender.kafka.layout.additionalField1.value = ${sys:log.file}
# flink-job-name
appender.kafka.layout.additionalField2.type = KeyValuePair
appender.kafka.layout.additionalField2.key = flinkJobName
appender.kafka.layout.additionalField2.value = ${sys:flinkJobName}
# 提交到yarn的containerId
appender.kafka.layout.additionalField3.type = KeyValuePair
appender.kafka.layout.additionalField3.key = yarnContainerId
appender.kafka.layout.additionalField3.value = ${sys:yarnContainerId}
上⾯的 appender.kafka.layout.type 可以使⽤ JSONLayout ,也可以⾃定义。
⾃定义需要将上⾯的appender.kafka.layout.type 和 appender.kafka.layout.value 修改成如下:
appender.kafka.layout.type = PatternLayout
appender.kafka.layout.pattern ={"log_level":"%p","log_timestamp":"%d{ISO8601}","log_thread":"%t","log_file":"%F","l
og_line":"%L","log_message":"'%m'","log_path":"%X{log_path}","job_name":"${sys:flink
_job_name}"}%n
2.3 基于Flink on yarn模式提交任务前期准备
2.3.1 需要根据kafka的版本在flink/lib⽬录下放⼊kafka-clients的jar包
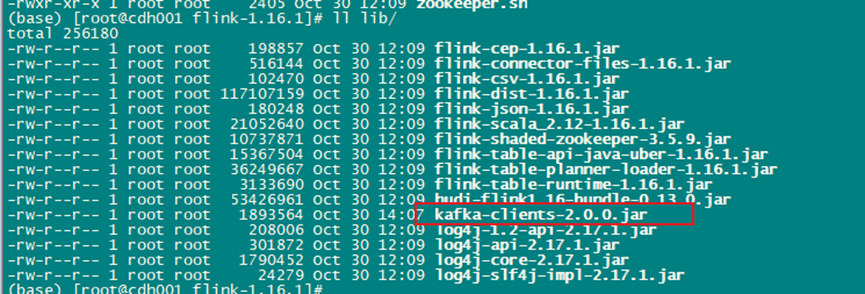
2.3.2 kafka处于启动状态
2.3.3 Flink Standalone集群
# 根据kafka的版本放⼊kafka-clients
kafka-clients-3.1.0.jar
# jackson对应的jar包
jackson-annotations-2.13.3.jar
jackson-core-2.13.3.jar
jackson-databind-2.13.3.jar
2.4 Flink on yarn任务提交案例
/root/software/flink-1.16.1/bin/flink run-application \
-t yarn-application \
-D yarn.application.name=TopSpeedWindowing \
-D parallelism.default=3 \
-D jobmanager.memory.process.size=2g \
-D taskmanager.memory.process.size=2g \
-D env.java.opts="-DflinkJobName=TopSpeedWindowing" \
/root/software/flink-1.16.1/examples/streaming/TopSpeedWindowing.jar
【注意】启动脚本需要加入这个参数,日志才能采集到任务名称(-D env.java.opts="-DflinkJobName=xxx")
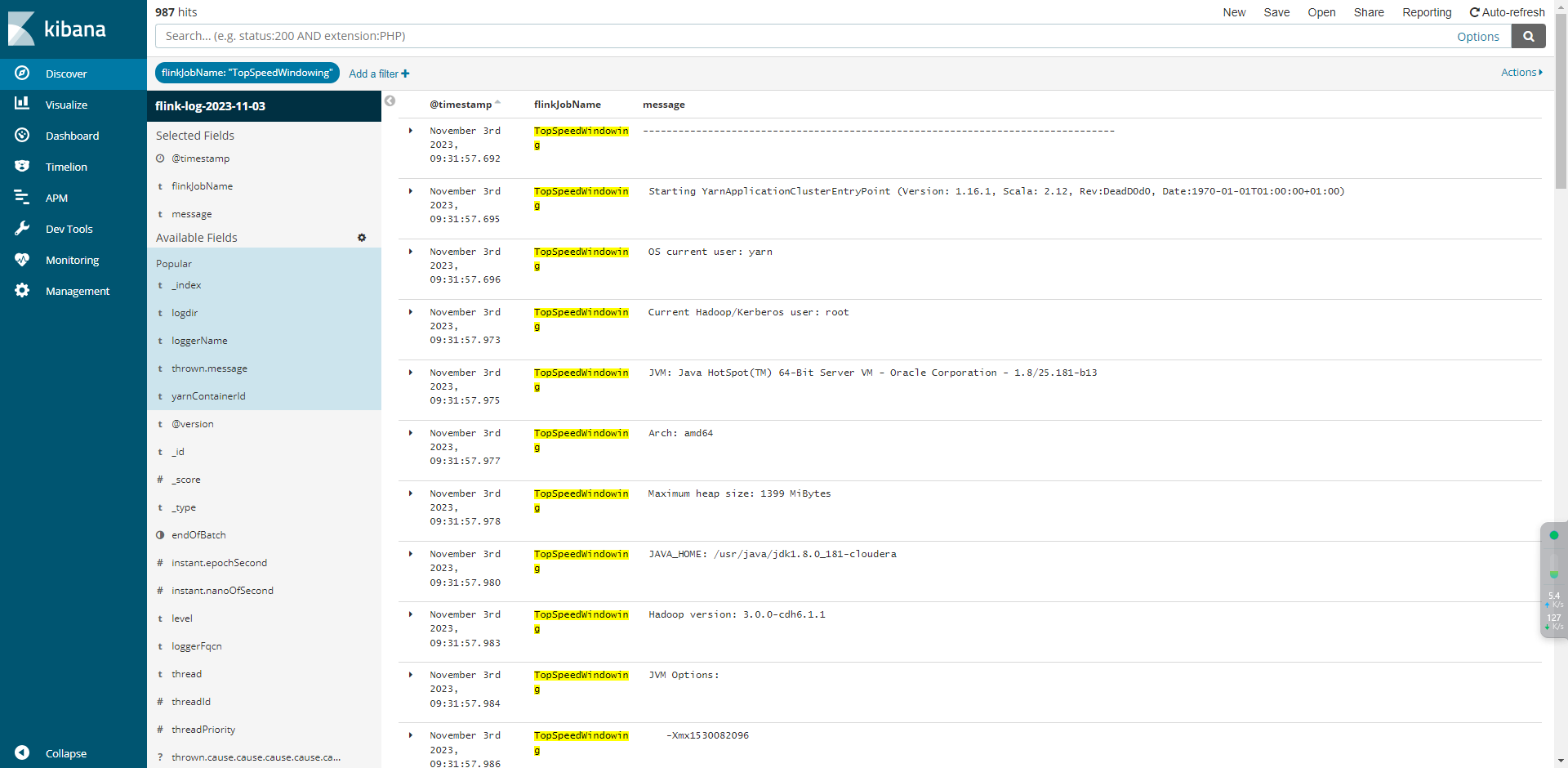
消费flink_logs案例
{instant: {epochSecond: 1698723428,nanoOfSecond: 544000000,},thread: 'flink-akka.actor.default-dispatcher-17',level: 'INFO',loggerName: 'org.apache.flink.runtime.rpc.akka.AkkaRpcService',message: 'Stopped Akka RPC service.',endOfBatch: false,loggerFqcn: 'org.apache.logging.slf4j.Log4jLogger',threadId: 68,threadPriority: 5,logdir: '/yarn/container-logs/application_1697779774806_0046/container_1697779774806_0046_01_000002/taskmanager.log',flinkJobName: 'flink-log-collect-test',yarnContainerId: 'container_1697779774806_0046_01_000002',
}
⽇志写⼊Kafka之后可以通过Logstash接⼊elasticsearch,然后通过kibana进⾏查询或搜索
三、LogStash部署
部署过程略,网上都有
需要注意Logstash内部kafka-clients和Kafka版本兼容问题,需要根据Kafka版本选择合适的Logstash版本
将以下内容写⼊config/logstash-sample.conf ⽂件中
input {kafka {bootstrap_servers => ["xxx1:9092,xxx2:9092,xxx3:9092"] group_id => "logstash-group"topics => ["flink_logs"] consumer_threads => 3 type => "flink-logs" codec => "json"auto_offset_reset => "latest"}
}output {elasticsearch {hosts => ["xxx:9200"] index => "flink-log-%{+YYYY-MM-dd}"}
}
Logstash启动:
logstash-6.5.4/bin/logstash -f logstash-6.5.4/config/logstash-sample.conf 2>&1 >logstash-6.5.4/logs/logstash.log &
四、Elasticsearch部署
部署过程略,网上都有
注意需要用root用户以外的用户启动Elasticsearch
启动脚本:
Su elasticsearchlogtestelasticsearch-6.3.1/bin/elasticsearch

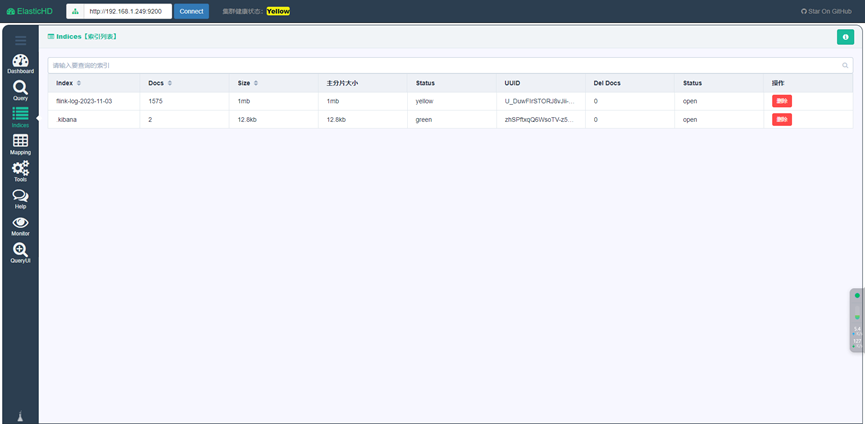
Windows访问ES客户端推荐使用ElasticHD,本地运行后可以直连ES
五、Kibana部署
部署过程略,网上都有
启动脚本:
kibana-6.3.1-linux-x86_64/bin/kibana
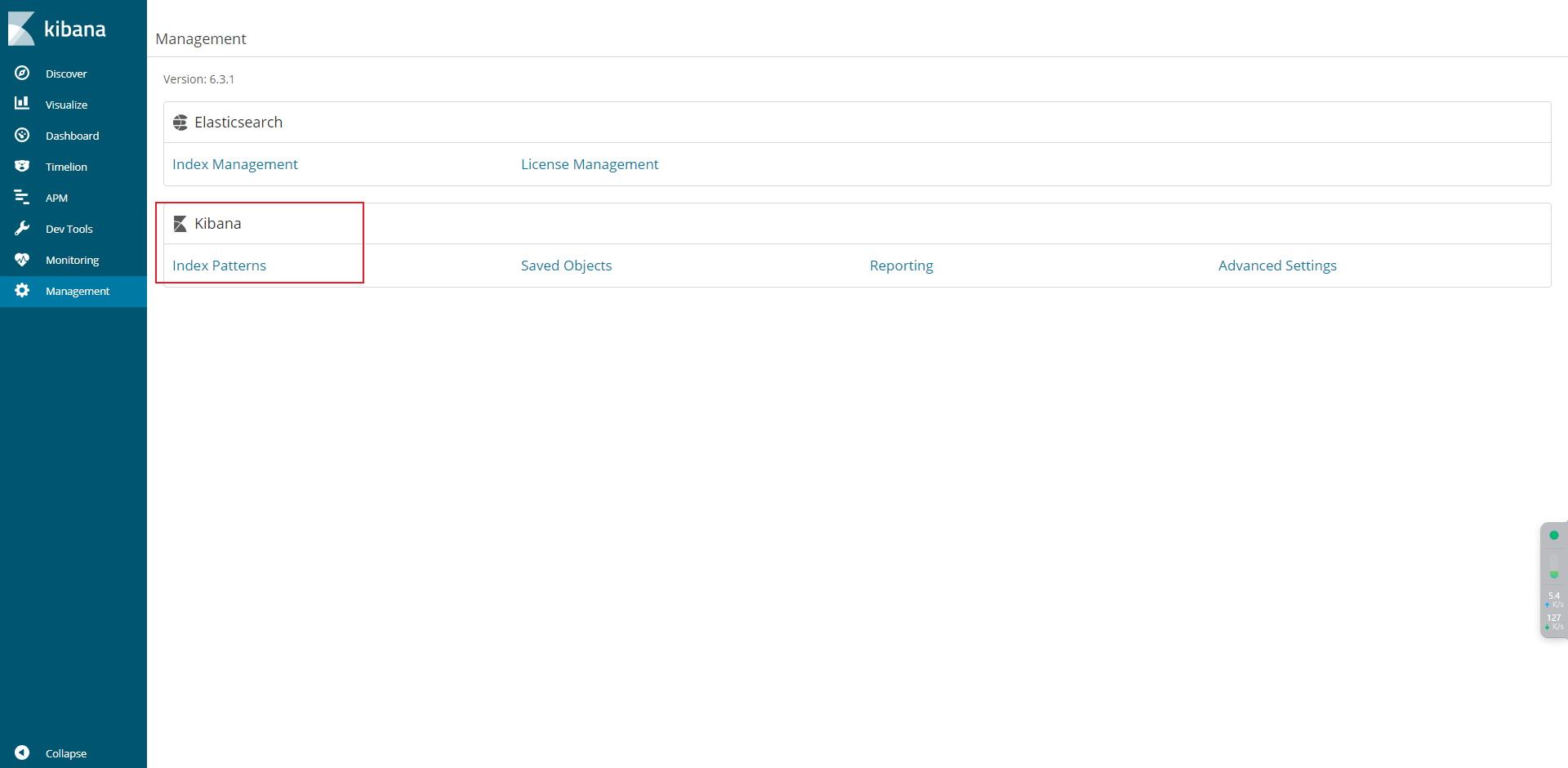
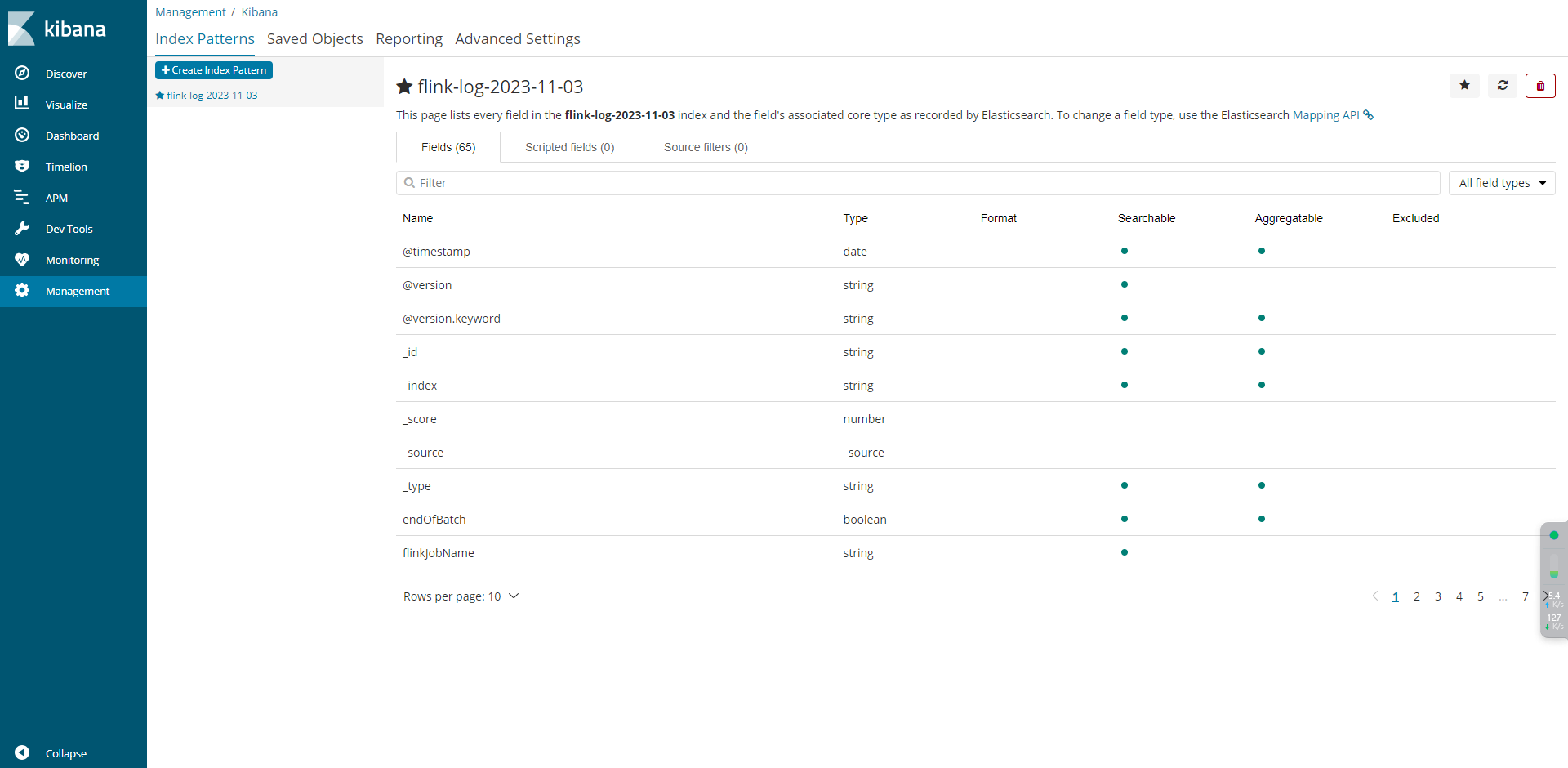
5.1 配置规则
5.2 日志分析









![[C++进阶篇]STL中vector的使用](https://img-blog.csdnimg.cn/85c584db808b4a119dd1fa4f185fa779.png)
