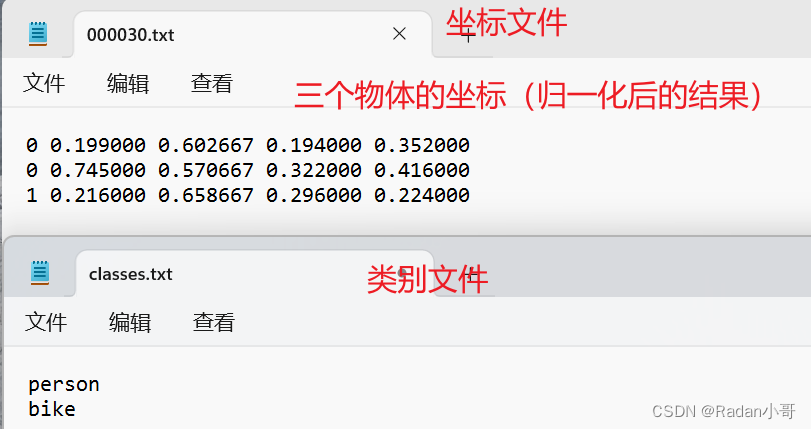
0.写在前面
上一篇博客全都是说明类型的,实际代码能不能跑起来两说,谨慎观看.本文中直接使用fashions数据实现softmax的简单训练并且完成结果输出.实现一个预测并且观测到输出结果.
并且更重要的是,在这里对一些训练的过程,数据的形式,以及我们在softmax中主要做什么以及怎么做来进行说明.
前提要求:一些数据包的需求先写在这里了,根据pip3进行按照需求下载即可
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
import pandas
from torch import nn
1.对于数据的下载以及处理
(1)数据的下载:
首先对于数据的下载,这里我们选择的方式是直接在都d2l环境下(D2L是什么请自行进行百度),下载这个名为fashions的数据集合.
#这个就是下载数据集合了,这里获取到了数据集合并且放到内存里面
d2l.use_svg_display()数据下载以后应该是在我们自己的内存里面,在这里我指定的是./data,不同的人大概是不同的目录,请自行参考.
然后接下来对数据进行处理,这个数据集合是一个PIL形式,在这里我们需要把每个图像转化为浮点数形式,这里有个很重要的函数dataset,他可以理解为一种容器,一般是以一个二维数组的方式来存储我们的数据.
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式,
# 并除以255使得所有像素的数值均在0~1之间
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="./data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="./data", train=False, transform=trans, download=True)mnist_train和mnist_test都是我们俗称的一个dataset对象,故名思意,就算数据集合.
虽然这个东西并不是二维数组,但是我们可以使用二维数组的方式进行读取
mnist_train是一个dataset对象,是一个[n,2]形状的二维数组
举个例子[0][0]为一个1×28×28的图像张量,也就是我们的输入input
print(mnist_train[0][1]) label就是一个单独的数字,在这个数据中是一个数字,或者说标量张量
如果我们在python中输出,效果就是这样子的
print(mnist_train[0][0].shape) #Tensor.Size([1,28,28])
print(mnist_train[0][1]) #Tensor(9)#这里需要注意到的问题后面都会解释到位(2)数据的处理
数据的处理其实我们要考虑到两个方面进行处理,一个用来训练的时候,我们需要把这东西转化为张量的形式,而且更重要的是我们不可能一次性投入这么多数据(提示一下,虽然fashion数据集合只有60000条,但是这个想法很重要),主要是在计算损失的时候,要保证低耦合度,一次性寻找适量数目的数据(这个将会在后面有补充)
其次就是,我们需要对整体的情况有一个总览,所以说我们要根据数据的整体计算一个损失,但是问题是dataset对象并不是张量,我们需要对其进行一些简单的处理;
那么首先是第一条:如何对数据进行读取,这也是我们进行遍历训练的时候需要做的事情,这里我们需要知道的另一个很重要的对象dataloader,这个东西吧dataset对象分成多个批次,然后设置成一个迭代器对象,如图所示
batch_size=256
train_iter=data.DataLoader(mnist_train,batch_size=256,shuffle=True,num_workers=4) #将这个数据集划分为256一打,洗牌模式随机抽取,四个线程进行读取
test_iter=data.DataLoader(mnist_test,batch_size=256,shuffle=True,num_workers=4) # 这样就生成一个类似迭代器的东西了,使用for循环可以进行读取
这个iter明显就是一个迭代的意思,很简单,但是有个问题,据我所知这个东西只能for循环来进行读取
如果我们强还行print,那么啥都得不到
print(train_iter)
#dataloader所产生的数据可以使用for循环来进行获取,也只能使用for循环才能得到对象正确的读取方法应该是这样子的,通过这样的方法进行读取数据,这样子能保证每次返回的都是一批张量
for features,labels in train_iter:print(features,labels)在这里需要单独说明,首先我们之前设定为批次是256,并且feature是一个三维张量,label是一个常量张量(注意常量张量和向量张量是完全不同的两个东西),所以这里print出来的张量应该是这两个形状的东西
[256,1,28,28]
[256,1]批次在这里的体现就是,我们把256个作为一个批次,然后合并在一起.
可能你就要问了,唉,256这个多出来的维度不影响训练吗,问题不大吗,因为神经网络有自己的处理方法
-----------------------------------------------
另一个需要处理的数据其实就是整体,毕竟我们后面需要用损失函数计算一个整体的估计情况,来确定一个总的训练效果.
这里就没什么奇怪的东西了,需要手动操作,把从mnist_train和muist_test中遍历出来的数据转化出来,变成一个我们能接受的张量的性质
#使用方法把完整的数据集合改成张量
# 定义空的张量用于存储输入和输出
inputs = []
outputs = []# 遍历数据集的每个样本
for sample in mnist_train:image = sample[0] # 图像数据label = sample[1] # 标签数据# 将图像数据和标签数据分别添加到张量中inputs.append(image)outputs.append(label)# 将列表转换为张量对象
inputs = torch.stack(inputs)
outputs = torch.tensor(outputs)# 打印张量的形状,这里一共检测到60000个数据
print("输入张量的形状",inputs.shape) # 输入张量的形状
print("输出张量的形状",outputs.shape) # 输出张量的形状至于这两个东西后面怎么用,我们后面会详细解释
2.关于神经网络的构建
(1)大致构建以及对于数据的处理
首先是我们在这个代码中构建的神经网络的大致结构
net=nn.Sequential(nn.Flatten(),nn.Linear(784,256),nn.ReLU(),nn.Linear(256,10),nn.Softmax(dim=1)
)
先解释一下神经网络是干什么的,在这个神经网络中,首先使用一个Flatten对于张量进行展平,展平的效果就是这样子的,
[256,1,28,28] => [256,784]然后经过两个密集层,就变成了
[256,10]=====>内部大致的结构如下:
0:[1,2,3,4,5,6,7,8,9,10]
1:[1,2,3,4,5,6,7,8,9,10]
..........
255:[1,2,3,4,5,6,7,8,9,10]最后softmax函数在这里我们就不加解释了,在这里我们注明了dim=1.也就是沿着行的生长方向进行softmax归一化操作
0:[0.1,0.3,............]
1:[0.4,................]
2:[....................]
.............
当然这里很容易遇到两个问题:首先是第一个,我们的数据是被绑定成了一个巨大的张量,把256个数据绑定在了一起,这也就是我们想要在这里说明的事情.
首先是第一点,前向传播这个过程中,我们可以很清楚的看到(事实上你对於每个层进行这种操作也会发现一个肥肠类似的结果)对于一个层{linear([256,10])}来说,如果我们传入的是Size=[60000,256]这样的一个尺寸的张量 , 则我们可以得到一个向前传播的计算结果[60000,10], 仅仅是对最后一个维度实现了神经元上的收敛,别的好像没什么.
这是因为神经网络的一个重要特性,在代码中我们经常是按照批次来传入的,这就要求批次处理好数量.因此pytorch中秉持的原则就是,在向前传播的时候,只对最后一层的维度进行计算.
然后是第二点,可以看到在传入的时候把数据传输为一个[256,1,28,28]的部分,第一步我们进行的是一个展平的操作,但是要注意的一点是,我们对某个层进行单独的操作以后,可以看到最终在内部进行输出结果的是[256,784].因为flatten这个展平,永远不会操作第一个维度
所以综上所述我们可以看到一个东西,net对批量数据的操作其实是依赖于一些层和函数本身的性质/数学运算,而不是net的刻意的准备.这样我们就结合矩阵运算,实现了一个批量计算
(2)关于权重的配置
首先要说明一点,对于这种神经网络初始化权重的方法有很多,可以直接对某一层的属性进行访问和配置.当然我们更多是借用神经网络对象的apply函数.
#但是这里首先也需要初始化一下 nn.init.normal_(m.weight, std=0.01),这个是比较重要的初始化吧
def init(m):if type(m)==nn.Linear:nn.init.normal_(m.weight,std=0.1)nn.init.constant_(m.bias,0.1)#apply函数会保证每个层都能用的上这个初始化函数
net.apply(init)其中,apply自动会对每个层都执行一遍这个函数.只要我们判断出这一层是神经网络层,就进行这种操作
init.normal_主要用来给权重初始随机数值
init.constant_是给权重一个固定数值
(3)关于一些其他函数的配置
首先是训练函数,也就是迭代器,我们使用随机梯度下降的函数,并且传入net的参数
#训练函数
train = torch.optim.SGD(net.parameters(), lr=0.03) 然后是损失计算函数,损失计算函数其实是可以自己进行编写的,但是写好了为啥不用
监狱我们使用softmax进行一个数据的计算,所以这里我们使用"交叉熵损失函数"
这个函数大致的原理:
softmax这种分类问题最好用到别的损失函数,比如交叉商损失函数nn.CrossEntropyLoss(reduction='none')
这里解释一下输入 [0.7,0.2,0.1],[0.1,0.1,0.8] (每种可能性标签的概率) 和标签[0,2](真实的标签应该是什么),然后这个函数会返回一个张量形式的东西
这个公式其实是整理过一次了,在之前写过的csdn里面,这里的计算结果就是
1×log(0.7)+ 0×log(0.2)+ 0*log(0.1),以及
0×log(0.1)+ 0×log(0.2)+ 1*log(0.8),这两个元素,形成一维张量
其公式是这样子的,对于第c个输入和输出数据,假设其中第i个标签为真实的,并且对这个标签的预测概率为yci, 则这个数据的损失是
则对于总的这一批数据n,我们需要取平均值,就能找到其cost,这个在这里就不演示了
(4)模式
在开始训练之前,net对象其实存在有两个模式
net.train() # 训练模式
net.eval() #评估模式训练模式会存储梯度,而评估模式不会存储,也就是对应了一个用来训练一个用来评估
3.训练过程,数据处理
其实训练过程都是大同小异:计算损失,清除梯度,计算梯度,更新四步,如果有需要,可以对每一个循环增加的时候进行检查loss
epoch_num=10
for epoch in range(epoch_num):for X,y in train_iter:l=loss(net(X),y).mean() train.zero_grad()l.backward() train.step()l=loss(net(inputs),outputs)print(f'epoch {epoch + 1}, loss {l.mean():f}')对于这里就要注意两点
(1)不同的loss对于输入和输出的要求是不一样的.比如交叉熵损失函数要求的输入和输出分别是:
举个例子
[0.7,0.2,0.1],[0.1,0.1,0.8] (每种可能性标签的概率) 和标签[0,2](真实的标签应该是什么),然后这个函数会返回一个张量形式的东西
但是对于MSLoss这种损失函数,我们得到的结果则完全不一样,输入和输出都是同样尺寸的一维数组,然后直接计算出一个纳米孔数据.
(2)反向传播只能针对一个数字的标量张量计算,这也就是我们使用mean和sum这种函数压缩计算得到的结果.
4.一点小小的总结和完整代码
一点简单的小小总结:
1.首先是关于net:
net可以接受小批量,甚至是一个完整那个的数据list的输入的,也就是说我们传入的小批量其实是[256,1,28,28]
然后我们最终的输出结果为[256,1],虽然这不是我们要的东西
其实net本质就是一个张量处理机,’压缩‘成需要的格式
张量处理机:一开是的猜测是会根据批量逐一处理那些张量,但是事实是net本身并不会对其进行太多的区分
传入进来的仍然是一个整体张良,需要在net中自己操作dim得到需要的结果以及形式
而且那个自定义层因为没有可训练的参数,所以可能不被接受?因此在训练的过程中,loss没有发生任何变化
另外注意一个问题,Fattern是无法展平dim=0这个维度的,这也就是为什么小批量的size保持了稳定
2.还有一个问题,其实在计算的时候大多问题就出在loss上面,这个函数计算误差的时候,最基本的要求就是输入和输出是同一个形式的,比如这里
loss希望net(x)和y都是长度一样的Size[256],然后自动进行sum计算,但是因为第一层无法折叠,所以net(x)为[256,1],所以我们在loss计算的时候就是用reshape([-1])来进行处理
很多时候都是这样的问题,所以要进行一点处理
3.在估算整体误差的时候要转化成张量,这里用函数处理成张量
这个有点复杂,但是记住net只是一个tensor压缩机
4.dataset对象是可以通过二维数组的方法获取标签和数据
dataloader可以转化为一个迭代器iter,迭代器通过for循环(或许有别的手段)得到的是小批量数据,而且是张量格式
5.最后就是lr记得小一点,不然就爆炸了
爆炸以后直接nan,我做梦都没想到在js没踩过的坑,在这里实现了,这是因为最开始梯度设置为0.5太大而导致的
6.另外记住两个初始化函数,用来给某个层初始化权重的
nn.init.normal_(m.weight,std=0.1) 用来随机赋值,一般是w
nn.init.constant_(m.bias,0.1) 用来常量赋值,一般是b
7.最后总结一下这段流程
神经网络构建(sequential)===》参数设置(使用方法,然后对模型apply)===》损失函数设置(使用库函数即可)===》优化函数设置(传入net的参数parameter)===》训练
训练就是:计算损失===》梯度清零以后进行反响传播计算===》执行优化迭代
数据就是:从文件中读取dataset对象(这个对象是保存了数据[][]),然后使用dataloader获取可以用来训练的迭代器
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
import pandas
from torch import nn#这个就是下载数据集合了,这里获取到了数据集合并且放到内存里面
d2l.use_svg_display()# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式,
# 并除以255使得所有像素的数值均在0~1之间
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="./data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="./data", train=False, transform=trans, download=True)batch_size=256
train_iter=data.DataLoader(mnist_train,batch_size=256,shuffle=True,num_workers=4) #将这个数据集划分为256一打,洗牌模式随机抽取,四个线程进行读取
test_iter=data.DataLoader(mnist_test,batch_size=256,shuffle=True,num_workers=4) # 这样就生成一个类似迭代器的东西了,使用for循环可以进行读取
print(train_iter)net=nn.Sequential(nn.Flatten(),nn.Linear(784,256),nn.ReLU(),nn.Linear(256,10),nn.Softmax(dim=1)#先用softmax处理一下
)# 得出结论,展平层永远对最开始的一层都不起效果#所以上面那一层的问题就是:我们期待的输出是[256],而不是[256,1]#神经元先设定为训练模式
net.train()#损失函数
#loss = nn.MSELoss()
loss = nn.CrossEntropyLoss(reduction='none')#但是这里首先也需要初始化一下 nn.init.normal_(m.weight, std=0.01),这个是比较重要的初始化吧
def init(m):if type(m)==nn.Linear:nn.init.normal_(m.weight,std=0.1)nn.init.constant_(m.bias,0.1)#apply函数会保证每个层都能用的上这个初始化函数
net.apply(init)#训练函数
train = torch.optim.SGD(net.parameters(), lr=0.03) #使用方法把完整的数据集合改成张量
# 定义空的张量用于存储输入和输出
inputs = []
outputs = []# 遍历数据集的每个样本
for sample in mnist_train:image = sample[0] # 图像数据label = sample[1] # 标签数据# 将图像数据和标签数据分别添加到张量中inputs.append(image)outputs.append(label)# 将列表转换为张量对象
inputs = torch.stack(inputs)
outputs = torch.tensor(outputs)# 打印张量的形状,这里一共检测到60000个数据
print("输入张量的形状",inputs.shape) # 输入张量的形状
print("输出张量的形状",outputs.shape) # 输出张量的形状epoch_num=10
for epoch in range(epoch_num):for X,y in train_iter: l=loss(net(X),y).mean() train.zero_grad()l.backward() train.step()l=loss(net(inputs),outputs)print(f'epoch {epoch + 1}, loss {l.mean():f}')#然后把模型切换为评估模式
net.eval()