自动驾驶高效预训练--降低落地成本的新思路
- 1. 之前的方法
- 2. 主要工作——面向自动驾驶的点云预训练
- 2.1. 数据准备
出发点:通过预训练的方式,可以利用大量无标注数据进一步提升3D检测
- https://arxiv.org/pdf/2306.00612.pdf
1. 之前的方法
1.基于对比学习的方法——利用关联帧信息构建正样本对
- 利用不同视角对应的点作为positive pairs:将视角进行一些变换,然后将关联的点作为正样本对,将不相关的点作为负样本对
- Pointcontrast:Unsupervised pre-training for 3d point cloud understanding (ECCV 2020)
- Exploring Geometry-aware Contrast and Clustering Harmonization for
Self-supervised 3D Object Detection (ICCV 2021) - ProposalContrast: Unsupervised Pre-training for LiDAR-based 3D Object Detection
- 利用时序上对应的点作为positive pairs:
- Spatio-temporal Self-Supervised Representation Learning for 3D Point Clouds(ICCV 2021)
- 利用不同物体(infrastructure 和 vehicle)上的点作为pairs:
- CO3: Cooperative Unsupervised 3D Representation Learning for Autonomous Driving(ICLR 2023)
2.基于MAE的方法
- Voxel上:
- Voxel-MAE - Masked Autoencoders for Self-Supervised Learning on Automotive Point Clouds
- BEV上
- BEV-MAE: Bird’s Eye View Masked Autoencoders for Outdoor Point Cloud Pre-training
- Hierarchicald空间 :
- GD-MAE: Generative Decoder for MAE Pre-training on LiDAR Point Clouds (CVPR 2023)
之前工作的缺点:
- 预训练和finetune是在同一批数据,只不过分上下游;当不一致的时候微调效果一般
所以设想希望:
- 预训练一个通用的骨干网络,可以接下游很多任务
- 在增加预训练数据量的时候,下游finetune效果的变得更好
2. 主要工作——面向自动驾驶的点云预训练
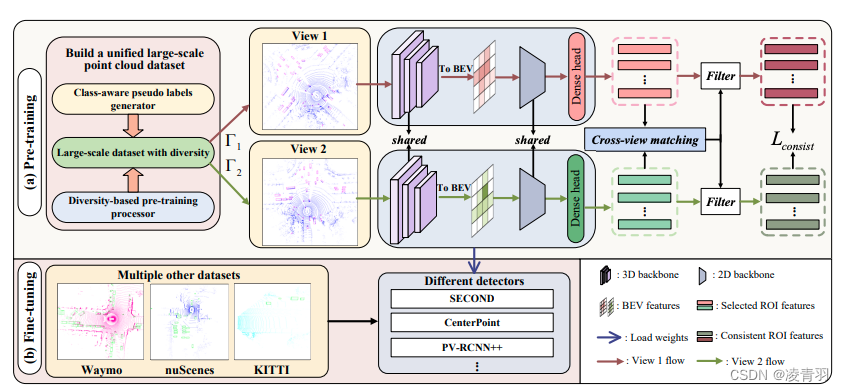
预训练分为两块:
- 数据处理&准备:
- 伪标签生成器:对未标注处理(Once数据集待标注是无标注的0.5%)
- voxel预训练,然后在SECOND、CenterPoint、PV-RCNN上加载
2.1. 数据准备
-
[1]类别注意的伪标签生成
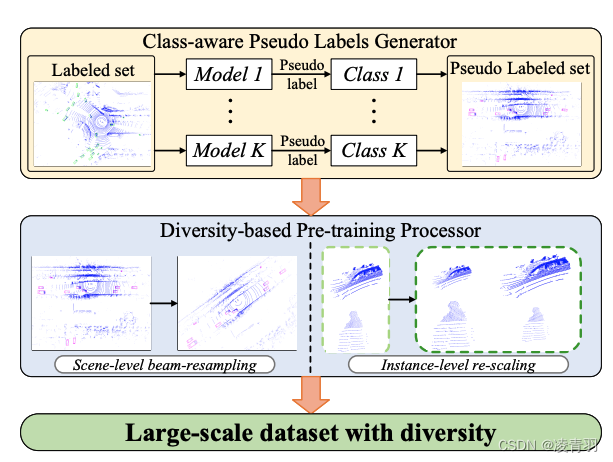
-
[2]数据多样性的生成:
- 1.上/下采样:将点云投影到图像上,将图像作为中间过程,对点云进行上/下采样

- 2.目标尺度缩放:对Bbox进行re-scale

- 1.上/下采样:将点云投影到图像上,将图像作为中间过程,对点云进行上/下采样
-
在大规模预训练后,在NuScenes数据集上的表现比较差,主要因为类别的不一致性,同时,在继续训练时会抑制预训练的类别激活
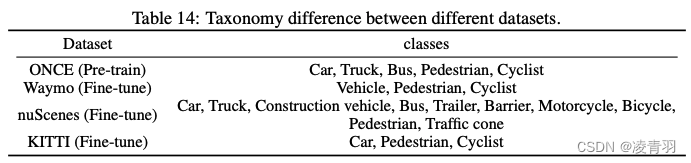
-
Ped和Cyclist在自动驾驶场景一般检测比较差,标注比较少;在未标注的数据上接近每帧2个label没标注,可以利用上(如下图)
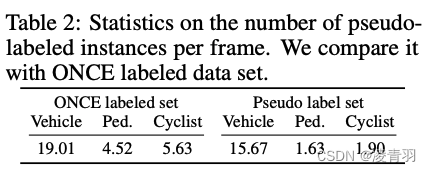
-
对于未标注图片前景物体的判断:采用两路head,分别预测
- 当两路分支的结果分别高于一定的阈值,并且俩路定位距离比较近,判断为前景
- 加入Consistency loss









![[BUUCTF NewStar 2023] week5 Crypto/pwn](https://img-blog.csdnimg.cn/b72e3abe449d476b85135804cb1a0304.png)
![Java快速排序算法、三路快排(Java算法和数据结构总结笔记)[7/20]](https://img-blog.csdnimg.cn/8c4e8bd2f7f642858db799aabd4cd295.png)