文章目录 1 scrapy简介 2 创建项目 3 自定义初始化请求url 4 定义item 5 定义管道
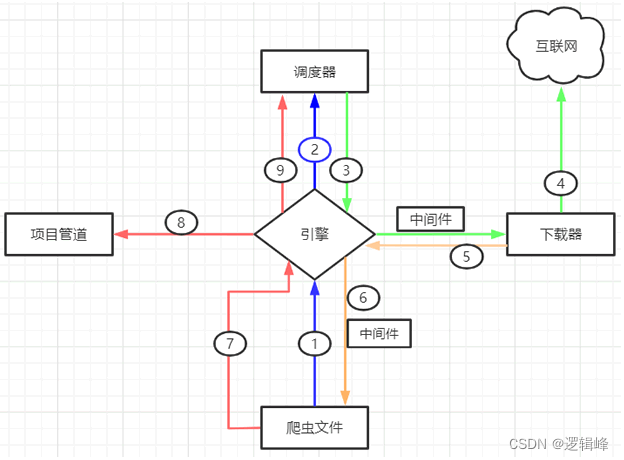
scrapy常用命令 项目的目录树结构 Scrapy 五大组件 名称 作用说明 Engine(引擎) 整个 Scrapy 框架的核心,主要负责数据和信号在不同模块间传递。 Scheduler(调度器) 用来维护引擎发送过来的 request 请求队列。 Downloader(下载器) 接收引擎发送过来的 request 请求,并生成请求的响应对象,将响应结果返回给引擎。 Spider(爬虫程序) 处理引擎发送过来的 response, 主要用来解析、提取数据和获取需要跟进的二级URL,然后将这些数据交回给引擎。 Pipeline(项目管道) 用实现数据存储,对引擎发送过来的数据进一步处理,比如存 MySQL 数据库等。
两大中间件 下载器中间件,位于引擎和下载器之间,主要用来包装 request 请求头,比如 UersAgent、Cookies 和代理 IP 等 蜘蛛中间件,位于引擎与爬虫文件之间,它主要用来修改响应对象的属性。 工作流程图
scrapy startproject Medical
cd Medical
scrapy genspider medical www.baidu.com
import scrapy
import json
from scrapy. http import Response
from Medical. items import MedicalItem
from tqdm import tqdm'''
具体的爬虫程序
''' class MedicalSpider ( scrapy. Spider) : name = "medical" allowed_domains = [ "beian.cfdi.org.cn" ] def start_requests ( self) : start_url = 'https://www.baidu.com/CTMDS/pub/PUB010100.do?method=handle05&_dt=20231101162330' data = { 'pageSize' : '1353' , 'curPage' : '1' , } yield scrapy. FormRequest( url= start_url, formdata= data, callback= self. parse) def parse ( self, response) : jsonRes = json. loads( response. body) status = jsonRes[ 'success' ] if status: dataList = jsonRes[ 'data' ] for row in tqdm( dataList, desc= '爬取进度' ) : urlDetail = f"https://www.baidu.com/CTMDS/pub/PUB010100.do?method=handle04&compId= { row[ 'companyId' ] } " yield scrapy. Request( url= urlDetail, callback= self. parseDetail, meta= { 'row' : row} ) def parseDetail ( self, response: Response) : item = MedicalItem( ) row = response. meta[ 'row' ] item[ 'companyId' ] = row[ 'companyId' ] item[ 'linkTel' ] = row[ 'linkTel' ] item[ 'recordNo' ] = row[ 'recordNo' ] item[ 'areaName' ] = row[ 'areaName' ] item[ 'linkMan' ] = row[ 'linkMan' ] item[ 'address' ] = row[ 'address' ] item[ 'compName' ] = row[ 'compName' ] item[ 'recordStatus' ] = row[ 'recordStatus' ] item[ 'cancelRecordTime' ] = row. get( 'cancelRecordTime' , '' ) divTextList = response. xpath( "//div[@class='col-md-8 textlabel']/text()" ) . extract( ) divtextList = [ text. strip( ) for text in divTextList] compLevel = '' if len ( divtextList) > 2 : compLevel = divtextList[ 2 ] recordTime = '' if len ( divtextList) > 5 : recordTime = divtextList[ 6 ] item[ 'compLevel' ] = compLevelitem[ 'recordTime' ] = recordTimedivListOther = response. xpath( "//div[@class='col-sm-8 textlabel']/text()" ) . extract( ) divtextListOther = [ text. strip( ) for text in divListOther] otherOrgAdd = ',' . join( divtextListOther) item[ 'otherOrgAdd' ] = otherOrgAddtrList = response. xpath( "//table[@class='table table-striped']/tbody/tr" ) tdTextList = [ tr. xpath( "./td/text()" ) . extract( ) for tr in trList] item[ 'tdTextList' ] = tdTextListyield item
import scrapyclass MedicalItem ( scrapy. Item) : areaName = scrapy. Field( ) companyId = scrapy. Field( ) compName = scrapy. Field( ) compLevel = scrapy. Field( ) linkMan = scrapy. Field( ) linkTel = scrapy. Field( ) recordNo = scrapy. Field( ) address = scrapy. Field( ) recordStatus = scrapy. Field( ) cancelRecordTime = scrapy. Field( ) recordTime = scrapy. Field( ) otherOrgAdd = scrapy. Field( ) tdTextList = scrapy. Field( )
from itemadapter import ItemAdapter
import pymysqlfrom Medical. items import MedicalItemclass MedicalPipeline : def open_spider ( self, spider) : self. db = pymysql. connect( host= 'localhost' , port= 3306 , user= 'root' , password= 'logicfeng' , database= 'test2' ) self. cursor = self. db. cursor( ) def process_item ( self, item, spider) : companyId = item[ 'companyId' ] linkTel = item[ 'linkTel' ] recordNo = item[ 'recordNo' ] areaName = item[ 'areaName' ] linkMan = item[ 'linkMan' ] address = item[ 'address' ] compName = item[ 'compName' ] recordStatus = item[ 'recordStatus' ] cancelRecordTime = item. get( 'cancelRecordTime' , '' ) compLevel = item. get( 'compLevel' , '' ) recordTime = item. get( 'recordTime' , '' ) otherOrgAdd = item. get( 'otherOrgAdd' , '' ) tdTextList = item[ 'tdTextList' ] sql1 = "insert INTO medical_register(company_id,area_name,record_no,comp_name,address,link_man,link_tel,record_status,comp_level,record_time,cancel_record_time,other_org_add) " sql2 = f"values(' { companyId} ',' { areaName} ',' { recordNo} ',' { compName} ',' { address} ',' { linkMan} ',' { linkTel} ',' { recordStatus} ',' { compLevel} ',' { recordTime} ',' { cancelRecordTime} ',' { otherOrgAdd} ')" = sql1 + sql2self. cursor. execute( sql3) self. db. commit( ) for tdText in tdTextList: tdText. insert( 0 , companyId) sql4 = "insert into medical_register_sub (company_id,professional_name,principal_investigator,job_title) values(%s,%s,%s,%s)" self. cursor. execute( sql4, tdText) self. db. commit( ) return itemdef close_spider ( self, spider) : self. cursor. close( ) self. db. close( ) print ( "关闭数据库!" )