一、前言
有赞目前,结合insight接口自动化平台、horizons用例管理平台、引流回放平台、页面比对工具、数据工厂等,在研发全流程中,已经沉淀了对应的质量保障的实践经验,并在逐渐的进化中。
在AI能力大幅进步的背景下,笔者尝试将业务场景给到ChatGPT,进行了文本用例生成的测试,观察到其输出测试用例的逻辑和测试人员编写用例的逻辑有较大的相似之处。在对ChatGPT的输出结果进行简单的调整和修改后,就可以用于业务测试中了。笔者发现AI设计的测试用例场景既能包括正向场景,也能包括逆向的异常场景,并能较为准确的给出测试用例描述和预期结果。在自动化测试中,测试工程师需要花费较多的时间去设计、实现和维护用例,对于该场景,我们是否可以应用ChatGPT的内容生成能力,来提升自动化测试脚本的编写效率呢?如果结合Fuzzing的测试思路,借助大量的生成用例来执行是否能挖掘潜在的代码问题呢?下面将介绍目前在做的基于Fuzzing(模糊测试)和ChatGPT结合的探索实践。
技术交流群
建了技术答疑、交流群!想要进交流群、资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流

二、调研过程
2.1 什么是Fuzzing
模糊测试(Fuzzing)的核心思想是通过系统自动生成随机数据作为输入,来验证被测程序的可靠性。在测试领域中,Fuzzing经常作为一种补充接口测试手段,来覆盖/探索接口中潜在的异常/临界值场景。简单来说,系统通过给定种子用例,随机生成大批量用例,调用被测接口,尝试发现问题(挖掘bug)。
模糊测试的难点在于如何基于种子用例生成随机有效的用例数据,从业界的经验来看,测试人员通过对生成内容进行建模、设计相应算法来匹配被测对象,才能取得比较好的生成效果。随着ChatGPT的发布,其AIGC的能力令人惊艳,如果借助ChatGPT的优势,能否降低生成随机数据的成本呢?于是,笔者围绕ChatGPT生成用例的可行性进行了尝试。
2.2 ChatGPT生成用例的可行性
为了验证ChatGPT生成数据的能力,笔者随机找了一份公司的PRD,摘取了一部分需求(已脱敏)来测试ChatGPT生成用例的质量,以下是调研过程中的部分结果展示。
摘取需求:商品设置了会员价-会员等级-打折,则群团团下单享受会员折扣。前置条件为当前店铺A,消费者P是店铺的会员,店铺A笔记内的商品M售价100元,运费0元,店铺设置了该商品M会员打8折。
部分问答内容:


可以从上述的图片中发现,在给定较为完善的背景情况下,ChatGPT生成的测试用例还算那么回事。笔者和相关业务同学确认,如果在ChatGPT给出的用例上再做一些调整,就可以直接用于功能测试了,所以在ChatGPT生成用例这件事上,是有可行性的,值得进一步探索。而自动化测试,无外乎将生成内容和规则变更,让ChatGPT产出可行的入参内容即可。


2.3 结合Fuzzing与ChatGPT可以做什么
经过上述的调研,模糊测试(Fuzzing)的思路是 基于种子用例生成随机用例 -> 执行用例 -> 发现问题(bug挖掘),但其难点在于如何生成高质量的随机用例,而ChatGPT的内容生成能力,似乎可以解决这一问题。笔者将两者尝试结合,模糊测试作为核心思想,ChatGPT作为用例生成服务,目标是通过大量ChatGPT生成的用例,来挖掘被测对象潜在的问题。
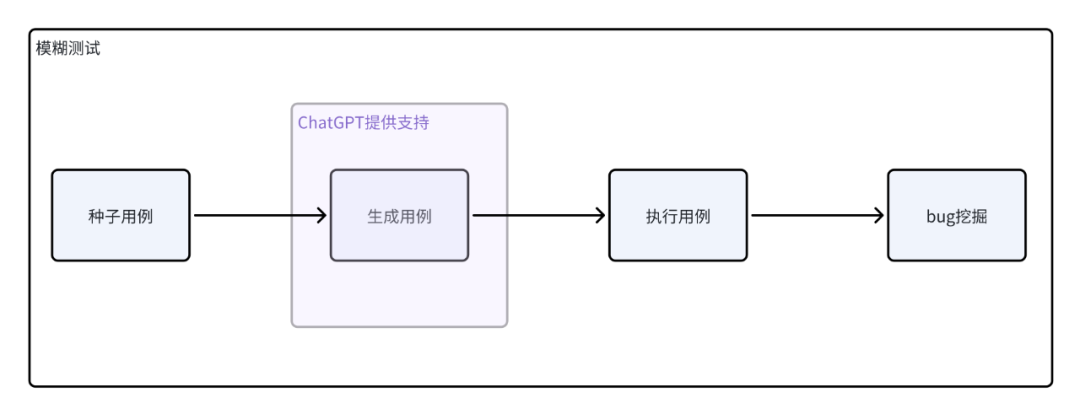
在自动化测试中,如果仅依赖模糊测试和ChatGPT生成的用例还不够,因为我们无法判断ChatGPT生成的用例是否有效,笔者尝试引入了自动化测试覆盖率的概念,将整体流程给串联起来:以模糊测试为基石,让ChatGPT来充当规则变异器,自动生成接口测试用例,覆盖率作为检验生成用例的有效性,目的是 发现问题和提高自动化测试的效率。
下面,笔者将以 ChatGPT用例生成、bug挖掘、代码覆盖率作为主线,来进行AI自动化测试实践。
三、设计与实现
前言提到,有赞已经有几个成熟的平台可以使用,为了降低实现的成本,笔者将尽可能基于现有平台的能力,来做设计与实现。
3.1 整体思路
有赞目前已有成熟的接口测试平台insight、流量回放平台zan-hunter,来承接日常接口测试、线上巡检、引流回放等测试活动。基于调研结果,笔者经过整理,核心思路可概括为 拾取用例->生成用例->执行结果判别->覆盖率条件循环。具象的说,就是 (1)insight/zan-hunter 获取用例生成模版数据 ->(2)根据模版数据生成ChatGPT的输入(prompt)->(3)调用ChatGPT,根据要求生成用例(JSON输出)-> (4) 执行用例,调用java应用的接口进行测试 ,输出测试结果(bug挖掘)->(5)获取接口对应的行覆盖率,并根据判断是否要继续执行 ->(6)循环往复,直到覆盖率摸高到天花板(可能是70%~80%)->(9)End。
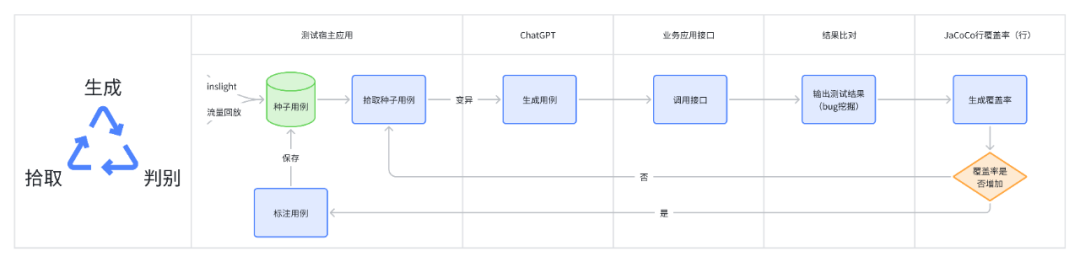
在现有资源限制、功能实现复杂度较高的背景下,笔者将其拆解为2个阶段来完成,同时本期将优先实现第一阶段的功能:
-
第一阶段:完成基于ChatGPT用例推荐,结合insight 用例创建与执行来实现测试环境与基准环境的结果比对,验证ChatGPT用例推荐有效性和被测代码稳定性,目标是能够挖掘出有效问题。
-
第二阶段:接入自动化覆盖率采集能力。目的是通过接口执行覆盖率是否提升的判断,来优化测试用例生成的有效性,使其达到目标自动化覆盖率。
3.2 功能设计
笔者根据实际情况,将实现内容做了拆解。
-
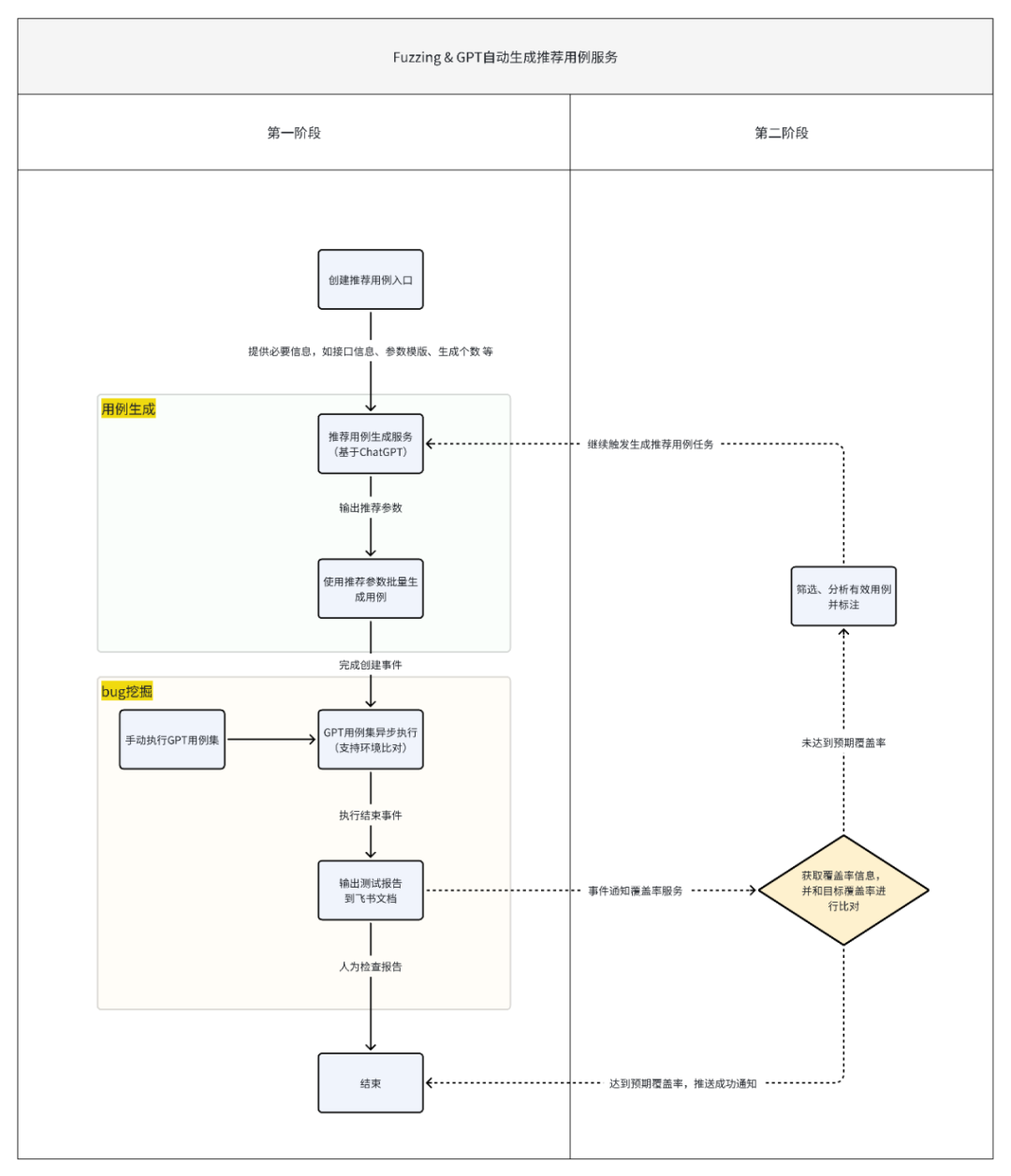
第一阶段需要实现的功能分成3块:
-
1. 搭建自动生成推荐用例前端展示、后端增删改查的框架;
-
2. 后端用例生成核心逻辑部分;
-
3.后端用例执行结束bug挖掘部分。
-
第二阶段的功能做了简单的设计规划,主要是 覆盖率的收集、比对判别、有效用例筛选标记、循环生成用例四大块。
-
以下主要是自动生成推荐用例的后端服务部分的流程图。
3.3 实现情况
目前,第一阶段的开发和验证已经结束,包括基于ChatGPT的推荐用例生成服务、用例执行、断言回写、结果输出等。实践结果证明基于ChatGPT创建的推荐用例,已经能够正确执行并感知到代码异常错误。第二阶段做了初步调研,暂未实现功能。
基于ChatGPT的推荐用例生成服务:前端页面输入提供生成规则,系统推荐参数模版;后端基于GPT-3.5模型,设计prompt来生成准确可靠的随机内容入参,结合insight已有能力,创建测试用例与执行集。
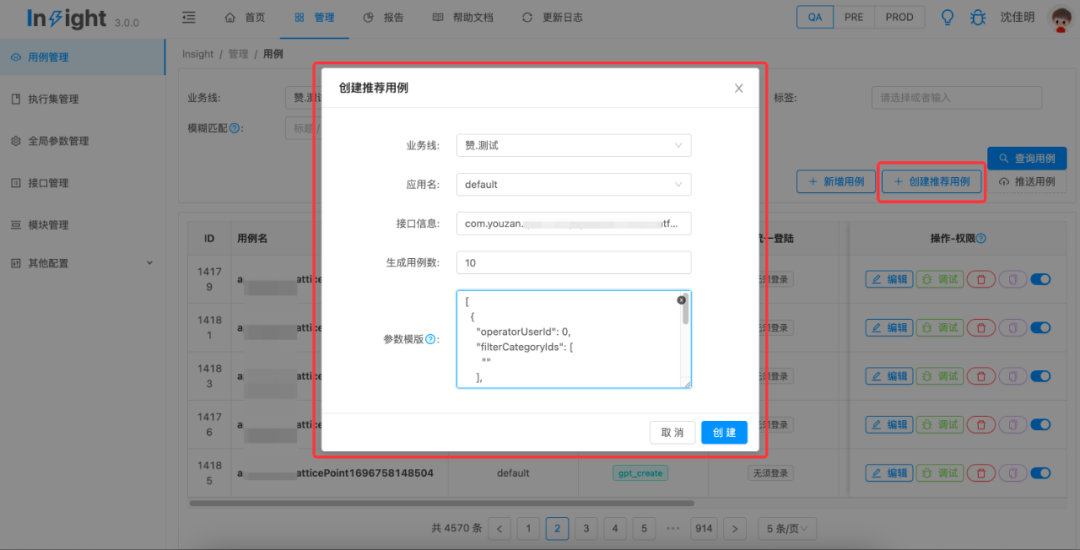
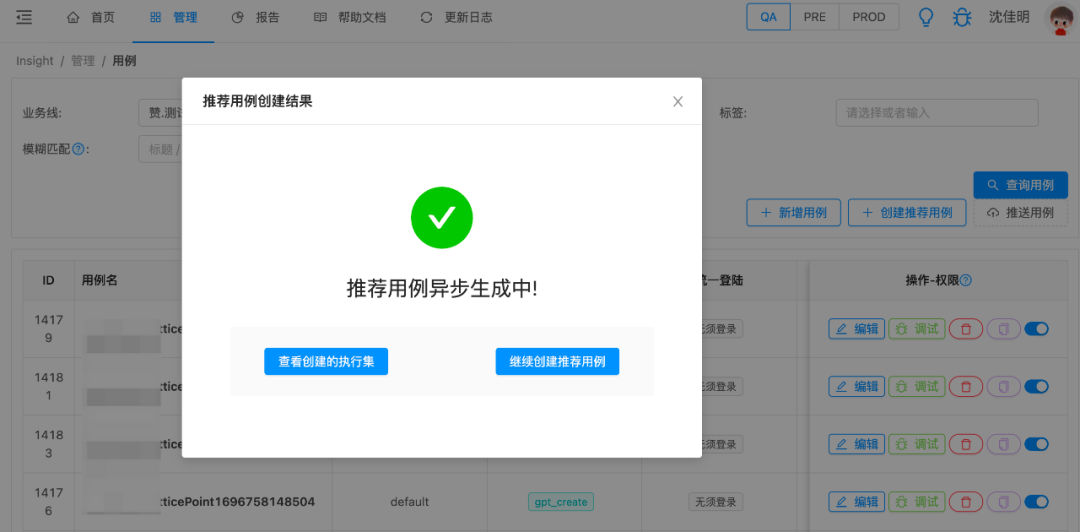
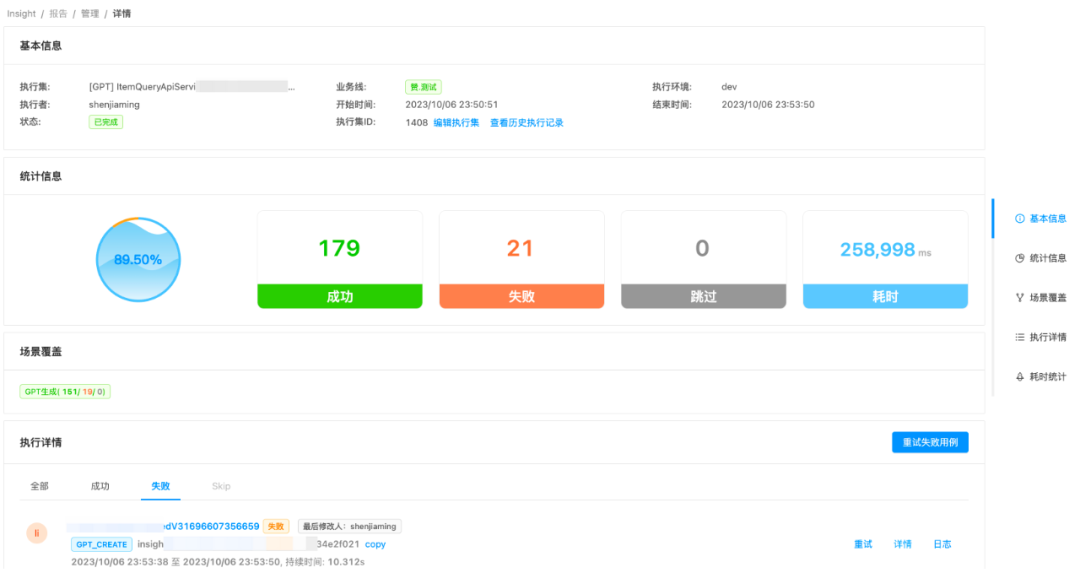
用例创建执行:基于ChatGPT生成的随机内容入参构建测试用例和创建执行集,insight执行并获得测试报告。(左:执行集详情;右:执行集结果)
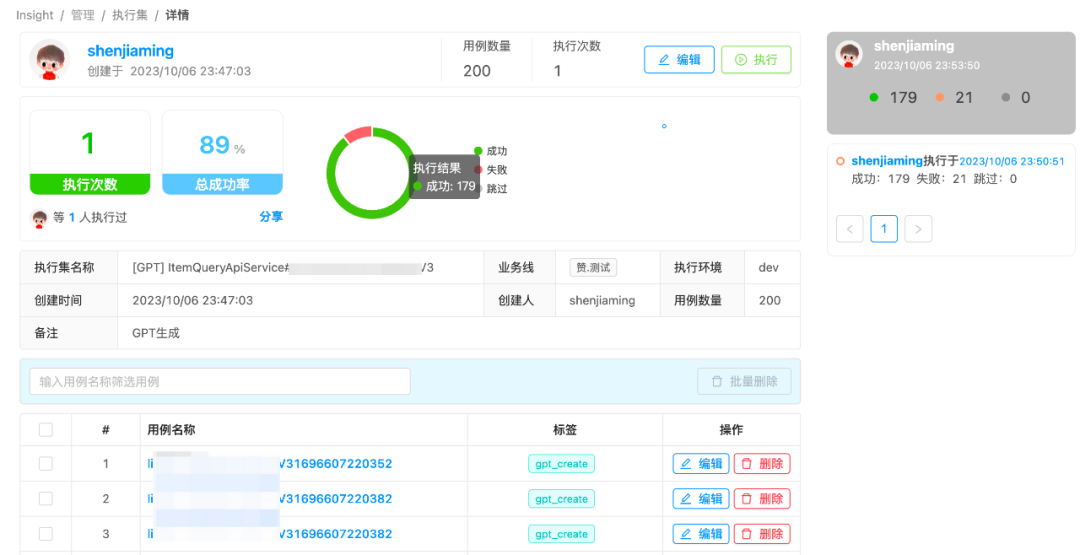
断言回写:由于执行结果的不确定性,我们将每一条用例第一次执行的结果作为用例基准断言。
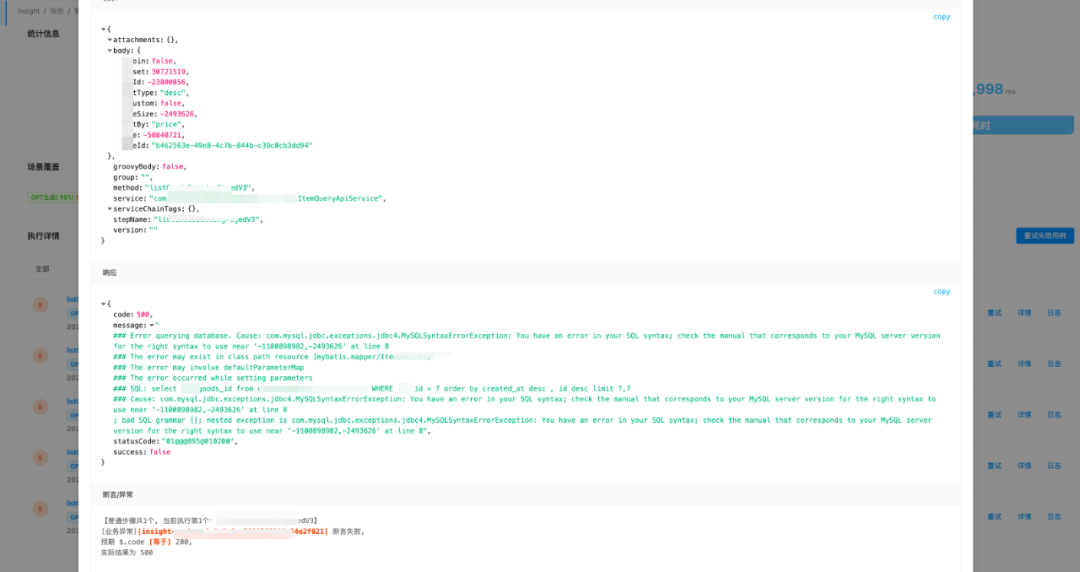
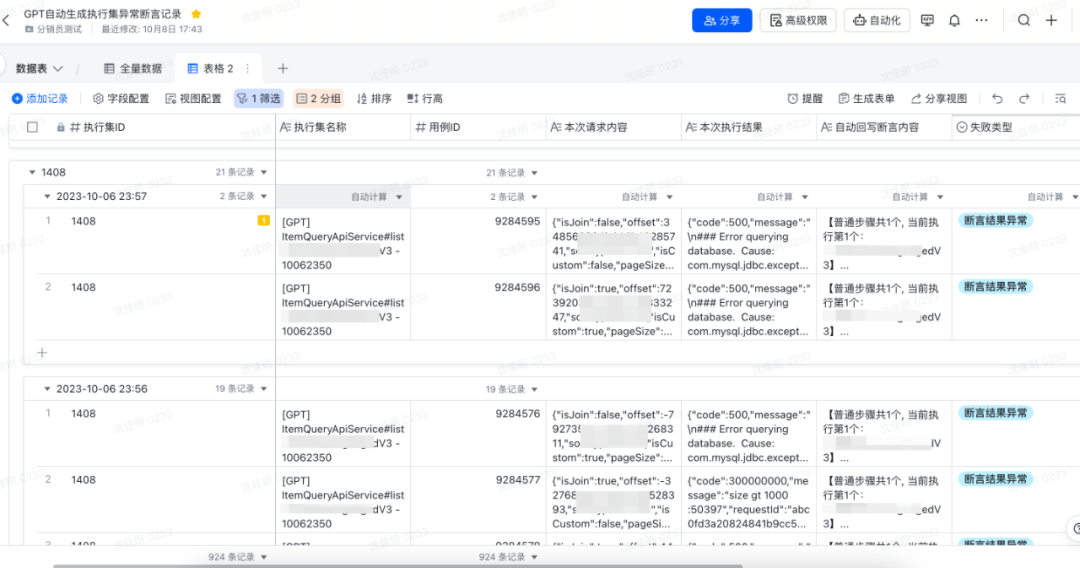
结果输出:insight平台还没有合适的聚合结果展示能力,我们将每一条用例第一次执行的结果、后续执行的失败结果,系统进行规则过滤后,将潜在风险问题均输出到飞书文档,方便测试人员可视化观察。(左:平台单条错误展示;右:飞书表格聚合展示)
bug挖掘: 由于输出的结果经过系统的第一次过滤,产生报告量数据适中,可以通过人为检查结果的方式来判断在当次执行的结果中,是否存在有效问题。
3.4 现阶段使用效果
由于资源分配、时间的关系,目前只完成第一阶段功能的开发验证。这里也将只基于第一阶段已经实现的能力做下使用总结,主要从生成速率、生成质量上来阐述使用效果。
3.4.1 用例生成速率
通过ChatGPT生成千条用例并执行完毕产出报告的速率在8分钟左右(测试条件:推荐用例生成的入参字段个数<10个 ),相较于原先的手工测试,使用用例生成服务,可以节省大量参数构造以及用例执行所需的时间。
3.4.2 用例生成质量(bug挖掘情况)
用例生成质量可以通过能否发现有效问题,或者接口能够正常拦截异常输入的角度来判定生成质量好坏。
笔者在测试过程中,主要对分销员业务接口(包含少量美业、群团团接口)进行bug挖掘验证,筛选验证接口共25(21 + 1 + 3)个接口,通过ChatGPT共生成了3400余条推荐用例,共发现4个有效问题,剩余21个接口能正常拦截异常错误。其中,发现的有效问题主要是SQL注入类异常报错(涉及代码安全问题)、业务代码NPE处理不健全2类;正常拦截错误的接口,说明其接口相对健壮,能够合法处理异常输入且不影响业务使用。
从测试的结果来看,用例生成质量符合预期(能发现问题)。
3.4.3 结论分析
结合目前第一阶段计划中已经实现的功能和使用效果,笔者对其有了更加深刻的认知,主要从工具定位、工具承担的使命、工具和现有测试手段的关系做了简短的总结。当然,现有的结论下,并不会影响到先前第二阶段的初步设计,在解决了第一阶段发现的问题后,继续推进。
3.4.3.1 工具定位
-
扫描接口,利用随机入参带来的不确定性,来验证接口的稳定性。
-
比如:用作新接口的异常测试入参验证
新接口的异常测试入参校验在没有经过测试验证前,校验项是容易存在遗漏缺失,通过随机生成的入参内容,可以用来验证校验逻辑的完备性
-
在不同代码版本中,回归接口的稳定性。
-
比如用作新老代码在异常入参测试领域用作回归测试
生成的推荐用例可以用来验证同一接口在不同代码版本下响应,理论上针对推荐用例的响应,预期是一致的
3.4.3.2 它能做什么、不能做什么
-
可以做
-
创建并执行随机参数输入的模糊测试
-
批量测试用例生成(非业务语义)
-
基于创建的执行集,在每个代码版本中用作回归测试验证(不同代码版本对同一份测试用例的结果校验);
-
暂时不能做
-
替代手工测试/场景化测试,原因是ChatGPT还不能很好的生成具有业务语义内容的数据(详见4.1)。
3.4.3.3 与现有自动化/功能测试之间的关系
-
原有自动化/功能测试不会针对异常入参场景做详尽的参数输入测试,而自动推荐用例服务,可以在数量上弥补这一场景。
-
从替代性上来说,目前无法替代现有的自动化/功能测试,只能用作辅助测试。最大的问题还是自动推荐用例服务还不具备完善的业务语义(真实)数据生成的能力。
四、未来的计划
通过这段时间的实践,笔者认为结合Fuzzing&ChatGPT的自动生成用例服务是可行的,但也存在着一些问题需要优化改进,比如具有业务语义推荐入参的生成策略、如何提高生成内容的准确性和稳定性等。当然,笔者会继续尝试 prompt微调、数据集训练模型等方式,来优化业务语义生成的准确性;通过工程架构优化、接入公司AI基建能力,来提高生成服务的稳定性。在Q4解决了这些问题后,后续将按照第二阶段的计划,结合接口测试代码覆盖率来推进ChatGPT生成用例的有效性。
在实践的过程中,笔者也看到很多测试同行在结合AI大模型做着各种各样协助测试提效、为团队赋能的事情,振奋人心。测试和AI的结合,不仅限于自动化测试,在CI/CD、测试环境治理上都能有AI辅助的身影,只要有想法且付诸实践,都会发现AI神奇的魅力。随着时间的发展各种国产大模型的崛起,LLM的能力被进一步挖掘,笔者相信,各种各样的测试活动都有可能通过AI来提效,也由衷地希望AI可以给测试行业带来新鲜的变化,甚至颠覆行业。
其他:碰到的问题与解决方案
笔者在实际开发、测试自动生成用例服务的过程中,也踩了不少坑,在这里分享几个比较典型的问题。
1.1 入参推荐准确度(具有业务语义)
使用推荐用例生成服务,需要提供关键的参数格式、生成数量和规则给到ChatGPT。如果不对生成规则在生成的时候,总是会生成错误的、不符合预期的数据,这样的用例在实际执行的过程中,大概率是不能走到对应的业务逻辑代码中去,导致无效用例生成数量在执行集中的占比偏高,执行效果不理想。
如果需要解决该问题,有2种比较合适的方案:
-
一是创建私有模型数据来训练ChatGPT,通过微调的方式来优化ChatGPT的业务语义数据生成准确性;
-
二是通过人为指定参数生成方式,来保障预期字段数据的准确性,从而达到获得目标业务语义数据的结果。
受限于ChatGPT使用资源、私有模型数据集整理收集的高昂成本问题,笔者退而求其次尝试了第二种方法,尽可能的将生成结果靠近预期内的数据。
这里尝试借鉴使用了MVEL模版语言的规则,经过验证,ChatGPT是能够自主理解MVEL模版语言和如何使用该语言的,即使结果不太符合预期,也可以通过 提示 使ChatGPT更加理解我们的需求,并生成准确数据。
当然,标准的MVEL语言有自己的编写规范,我们要做的是设定自己的编写方式,目的是降低使用者在撰写推荐入参时的理解成本。为了让ChatGPT理解什么时候要通过MVEL模版语言进行生成数据,我们通过MVEL()来标记字段,并结合prompt来传达生成规则。
我们现在可以通过自定义MVEL表达式编写方式,来解决具有业务语义参数的指向性生成,比如在接口参数中需要指定 “kdtId” 字段的取值范围在某几个特定的店铺范围内,可以在入参中写为 {“kdtId”:“MVEL(1 || 55 || 160)”} ,ChatGPT在处理字段数据生成时,就会按照自定义规则在 [1,55,160] 数组中选取任意一个数字作为"kdtId"的值。但是,在方案二的实现中,我们仍然不能要求ChatGPT自主生成期望的“随机”业务语义数据,这也是其带来的一个弊端。

1.2 prompt设计
1.2.1 中文prompt
刚开始接触ChatGPT时,如何准确的向ChatGPT传达我的需求,成为了最大的问题。最开始都是将它作为搜索工具来使用的,类似于百度、谷歌,用来解决代码问题时特别好用。但当我需要解决一个复杂问题的时候,如果直接通过人类语言描述的方式,ChatGPT理解起来有一定难度,经常答非所问。并且,ChatGPT说到底还是LLM,本质还是在根据提供的上下文,预测下一个最优解。所以如何构建ChatGPT能够理解的上下文,成为了破局的关键。在这次实践中,我需要拆解我的需求,以及构建尽可能简短精炼的prompt(应对token上限)。
在prompt设计中,我首先选择中文来编写我的prompt,毕竟是母语,能够直白快速的撰写我所理解的需求。实际使用体验下来,基本上能够满足我的要求。但也发现了几个问题:
-
prompt编写受限于token数,所以在prompt需要设计的尽可能简短,笔者仅使用规则形式来限制生成逻辑。当入参格式、入参模版字段个数、单次生成用例条数,都会影响到生成的效果。
-
通过纯中文方式描述的字段生成规则,在实际ChatGPT解析过程中,还是会出现误差。
在查阅相关资料、多次和ChatGPT深入沟通后,笔者尝试优化了中文的prompt。基于问题1,笔者从工程层面做了生成规则上的限制,使其保持在相对稳定的生成状态下。基于问题2,在了解到ChatGPT理解结构化的语言能力比理解自然语言的能力更强,笔者将纯中文描述的生成规则改成了json格式的生成规则(未全部去除中文描述),在改造后的版本使用情况上看,ChatGPT给到的回答更加准确了。同时,笔者在翻阅资料的过程中,也发现ChatGPT的训练模型中大多数据都是英文数据集,使用中文prompt自然会增加其转换损耗,逐渐有了使用英文重构prompt的想法。
### 中文版本"""
用户会提供一份接口信息,你将按照规则,依据接口信息生成测试数据。以下是规则:
1. 接口信息数据格式:{\"paramTemplate\":{},\"generateCasesNum\":0},字段依次是种子参数模版,生成的测试用例数量。
2. 依据paramTemplate提供的内容作为种子参数,按照内容进行生成测试数据。依据generateCasesNum作为生成测试数据的条数。
3. 生成规则,按照条件顺序作为生成数据的规则优先级:
3.1 在生成的所有数据中,将要生成的用例总数为{generateNum}个,计算单个字段的值重复率,阈值为50%,超过阈值则丢弃当前导致超过阈值的该条数据,并重新生成。
3.2 如果字段内容不是MVEL表达式
3.2.1 生成规则:
a. {\"type\": String, \"rule\":[\"rule1.长度不超过15位\",\" rule2.如果字符串中只有数字,生成任意可以表示为纯数字的字符串\",\"rule3. 不符合rule2的,可以生成任意包含数字、字母、字符组合的字符串\"]}
(...)
3.2.2 兜底生成规则:
(...)
3.3 如果字段内容是MVEL表达式
3.3.1 如果存在字段格式为 \"value\":\"MVEL(*expression*)\",则认为 value 取值范围为符合 表达式 *expression* 的所有值
4. 测试数据输出格式:{generatedParams:[param:{},param:{}]} ;
5. 测试数据输出要求:生成的测试数据存储在数组generatedParams;只输出 minified json,no explain word;只输出 minified json,no explain word;只输出 minified json,no explain word。
理解上述要求后不需要回复,用户将提供接口信息: ${paramTemplate},请根据要求数据结果。
"""
1.2.2 英文prompt
在今年6月份,Open AI发布了GPT-3.5 新的训练模型版本,同时GPT-3.5也支持了16K的模型,笔者开始着手英文prompt版本的设计。
即使是在prompt中使用了Chinglish(中式英语),英文版本的执行效果还是略好于中文版本。笔者在使用英文prompt和ChatGPT进行交互时,发现其回答的响应速度有明显的提升,不过其回答的准确度似乎有所降低,可能原因在于我去掉了中文prompt中的详细规则描述。
回答准确度降低的表现形式,包括但不限于 1. 输出格式不为json格式;2. 生成内容重复率高;3. 不同结构的入参格式在生成过程中的解析能力差导致生成错误等。得益于"gpt-3.5-turbo-16k-0613"新版本,prompt的编写可以不再考虑token的限制了(目前需求达不到16K tokens上限),同时还能使用到function calling的新特性,笔者尝试在英文prompt中增加了 问答案例(让ChatGPT学习生成规则、方式)、函数调用的能力(结合问答案例,方便输入固定格式内容进行问答,便于工程化管理),优化了输出格式的规则要求等其他措施,基本解决了生成内容不稳定的问题。
当然,现有版本还有很大的优化空间,包括 如何保障json格式的稳定输入输出(引入DSL)、paramTemplate 的解析稳定性、ChatGPT生成数据的准确性、通过案例数据集微调私有模型等,在未来的规划中,会尝试逐一去解决这些问题。
### 英文版本"""
**Prompts**:\n
Base on fuzzing test and {{Mvel Expression}} , generate {{generateNum}} random {{generateParam}} by given {{paramTemplate}}.\n
[Introduction]:\n - {{Mvel Expression}}, a language like java/groovy.\n
[GenerateRule]:\n
- priority 1:if there is a key/a element in array contains {{Mvel Expression}} in given {{paramTemplate}}, base on {{Mvel Expression}} to generate.\n
- priority 2:based on key/element in array semantics to generate.\n
- priority 3:based on key/element in array type to generate.\n
- priority 4:based on [Good Example] cases in [Examples] to generate.\n
- priority 5:Ensure all keys' value/all elements in array will generate new data.\n
- priority 6:if the given {{paramTemplate}} is a array, generate {{generateNum}} arrays in same given array size, and every element in array will generate a new value, set arrays in a Multi-dimensional Array. \n
[OutputRule]:\n
- only minify json.\n
- set results in {{generatedParams}} by Json or Multi-dimensional Array, ensure the size of results equals to given {{generateNum}}.\n
- Don't truncate generated data for readability purpose.\n
[Examples]:\n
[Good Example]:\n
- >input: generate {\"keyA\":\"MVEL(334 || 160)\",\"keyB\":0, \"keyC\":\"\"},3\n >output: {\"generatedParams\":[{\"keyA\":334,\"keyB\":10, \"keyC\":\"tom\"},{\"keyA\":160,\"keyB\":1, \"keyC\":\"david\"},{\"keyA\":334,\"keyB\":7,\"keyC\":\"linda\"}]}\n
- >input: generateData [0],4 >output: {\"generatedParams\":[[1231],[4422],[33],[8]]}\n
(examples...)
**Functions**\n
[~generateData,Args: {{paramTemplate}} , {{generateNum}}]\n
[INSTRUCTIONS]\n generate test cases function\n
[BEGIN]\n
<Based on **Prompts** , [Good Example] and given Args, generate test cases and only provide a minify JSON response following this format without deviation.> \n
[END]\n**Action**\n
Waiting for user to provide instructions,don't reponse.${givenQuestion}
"""
1.3 用例生成服务的稳定性
除了Prompt的设计,用例生成服务的稳定性也是至关重要的。基于上述的实现思路与设计,调用ChatGPT生成推荐用例是主流程上的一环,如果由于生成内容的不稳定性导致服务中断/返回异常,将直接中断生成用例的流程。期间可能产生中断的问题多样,笔者总结了比较典型的4类问题和对应的解决办法。
- 使用ChatGPT网络不稳定问题
- 更好的做法是,在工具前端页面上增加内容生成进度状态,发生异常及时通过状态通知到用户,在未来的计划中,会优化交互层面的问题。
-
网络问题统一通过失败重试、限制最大重试次数等工程化防御性编程来规避。
-
超时失败多次时,需要发出业务告警以及时被感知到,目前通过日志记录来实现了。
-
生成内容的准确性(强依赖正确的JSON格式)
-
ChatGPT在回答内容时,有一定概率返回错误的JSON格式,比较常见的错误是未闭合的JSON、错误的JSON格式、回答包含解释文案等。目前通过代码尝试修复JSON内容如补全未闭合的JSON、丢弃无法处理的JSON并重试来增强处理回答文本逻辑的健壮性。
-
生成内容的质量(重复、省略等)
-
生成内容预处理,过滤重复内容;
-
代码层面尝试修复省略后的回答,无法修复则采取丢弃重试策略
-
生成内容的效率(批量生成速度)
-
需要考虑单次响应时长,避免时间过长导致http请求失败
-
了解GPT账号资源使用风控规则,工程化规避风控场景,如降低请求并发频次、增加账号等分散单账号的压力等。
-
生成任务出现超时,业务告警
在以上问题解决后,用例生成服务在调用ChatGPT生成内容时,还是会出现一些奇怪的回答,目前只能发现一例解决一例。笔者认为,在基于ChatGPT生成数据功能的架构设计时,要多考虑工程化上的保障措施,特别是强依赖ChatGPT返回内容的场景。
1.4 断言回写方式选择
如何选择合适的断言作为第一次执行结果的判断,也困扰了笔者很久,毕竟对于未知的入参,其响应也是未知的,到底如何判定其运行结果的有效性呢?
在第一次设计断言回写时,笔者拍脑袋的认为状态码等于200就可以(其实是偷懒了~)。在实际测试和使用的过程中,证明了这个断言是多么愚蠢!根本原因是这类断言没有解决判断运行结果的有效性,大部分用例的执行结果状态码都是200,压根发现不了问题。
笔者和小伙伴进行了头脑风暴讨论,重新审视了使用断言的方式,发现和最初设想的不一样。最初的想法是基于模糊测试来发现问题,但并不需要对预期结果有要求,现在受限于现成平台(insight)的限制,断言成了强依赖,导致无法绕过断言设计的问题。
于是,我们转变了思路。既然我们的目标是发现问题,那么此断言可不作为预期断言。假设代码执行结果作为正确结果,通过在不同代码版本上去执行相同的用例,均以该结果为准,如果断言发生了报错,则能帮助我们发现预期外的问题。所以,笔者最终决定将其自生成的用例的第一次执行结果作为用例本身的断言。举个例子:在master代码版本V1中,创建了推荐用例集,执行后断言回写到用例集,当下一次master代码版本V2发布时,执行用例集,如果发现断言失败的情况,说明有场景不符合上一次返回的结果,可以介入排查问题。但该做法也有弊端,就是不能及时发现问题。
为了更加及时的发现问题,笔者尝试将2种方式结合,通过状态码等于200来初筛一遍执行结果,输出初筛报告方便人工检查;同时回写第一次执行的结果作为断言,以便与下一次回归测试时使用。总的来说,效果还算可以,但仍不是最终的解决办法。在下一个迭代计划中,笔者也会继续尝试解决该问题。
参考文档:TCP-Fuzz: Detecting Memory and Semantic Bugs in TCP Stacks with Fuzzing