动手点关注

干货不迷路
作为 CEO,Sam 将 OpenAI 的内部氛围组织的很好,有位 OpenAI 的前员工告诉拾象团队,当 2018 年 GPT-2 的论文被驳回时,Sam 在团队周会上将拒信的内容朗读给所有员工,并告诉大家在通往成功的路上总会有阻碍,但是大家一定要有信念。
本文试图从技术角度,借助 GPT 的公开资料,解读如何入门 GPT 以及相关大语言模型,形成自己对问题的认知体系,加速对新知识的吸收和理解; 并基于此讨论 LLM 的使用,以及带来的在产学研以及个人上带来的影响;最后提出需要关注的几个要点。
前言
基于当前 GPT-4 的已公开能力,以及 OpenAI 内部的一些消息,GPT-5 的能力会更加强大,但考虑到后续其他生态的配套等发展,下次发布可能会等生态的逐步完善和发展,而这个时候有可能会像 iphone4 一样经典。
最近这几个月,大家都感觉各个研究机构的人都不睡觉,你追我赶在疯狂发 paper,arxiv 这个平台的出现满足了他们的高产诉求。除了 paper,现在新的 git 项目,甚至新的公司都在层出不穷。奈何,他们前进的步伐不受狙击,所以如何才能更好更快的不被他们牵着鼻子走呢?
嗯,合理的方式,是将主要的脉络抓清楚,对问题有自己的框架认识。论文并非都需要读,抓到关键 paper,合理利用大佬发布的博客,加速对问题的理解。在基础了解之后,再阅读最新的 paper。很快,就会发现,emm 大部分论文……读起来变顺畅了。
在这个基础上,找到自己想要深入的点,再深入研究即可。
在 LLM 发展日新月异的今天,如何快速 follow,事半功倍,无论是针对技术还是非技术同学,都是一个需要思考的问题。
本文分为五个方面来切入,首先进行基础论文的分享和串讲,这些是从技术上了解当前 LLM 的基础,有了他们才有可能可以快速 follow 新的知识;第二部分重点讲复现和追赶,进行这个工作重点需要考虑哪些方面;第三部分基于 LLM 理解它会带来怎么样的变革和影响;第四部分是几个值得关注和讨论的要点;最后一部分是 take away,总结要点。
本文适合读者:想要 follow 新技术的技术/非技术从业者;想要检验一个人是否在不懂装懂……可以作为参考;作为建立对 LLM 认知体系的基础,这样每次看到新的知识是可以直接叠加进去的。
基础论文阅读
首先我们要明白一个事情。论文,一般都是针对某几个 SOTA 问题,甚至是一个 SOTA 问题的针对性讨论,其中附带了这个问题的前因后果,对其的实验论证和分析,以及给他人挖的坑,所以它天然就不是给初学者写的东西啊。
在读论文之前,先搞明白基础,然后再有顺序的,有根据,【有选择】的读论文,就不会出现理解上的困难。特意强调有选择,是有一些论文已经过时了,不用看了。除非要做相关问题研究,需要对比,或者了解前人做过的实验,否则,想学会怎么开汽车,或者学会怎么改装汽车轮胎,确实不需要知道怎么养马。
首先需要了解 LLM 的一些基础知识,入门一定要从语言模型入门,这个只要是个学过数学的学生就能看懂的,而且是要了解 LLM 的基础。
ChatGPT 原理介绍:
从语言模型走近 ChatGPT:https://zhuanlan.zhihu.com/p/608047052
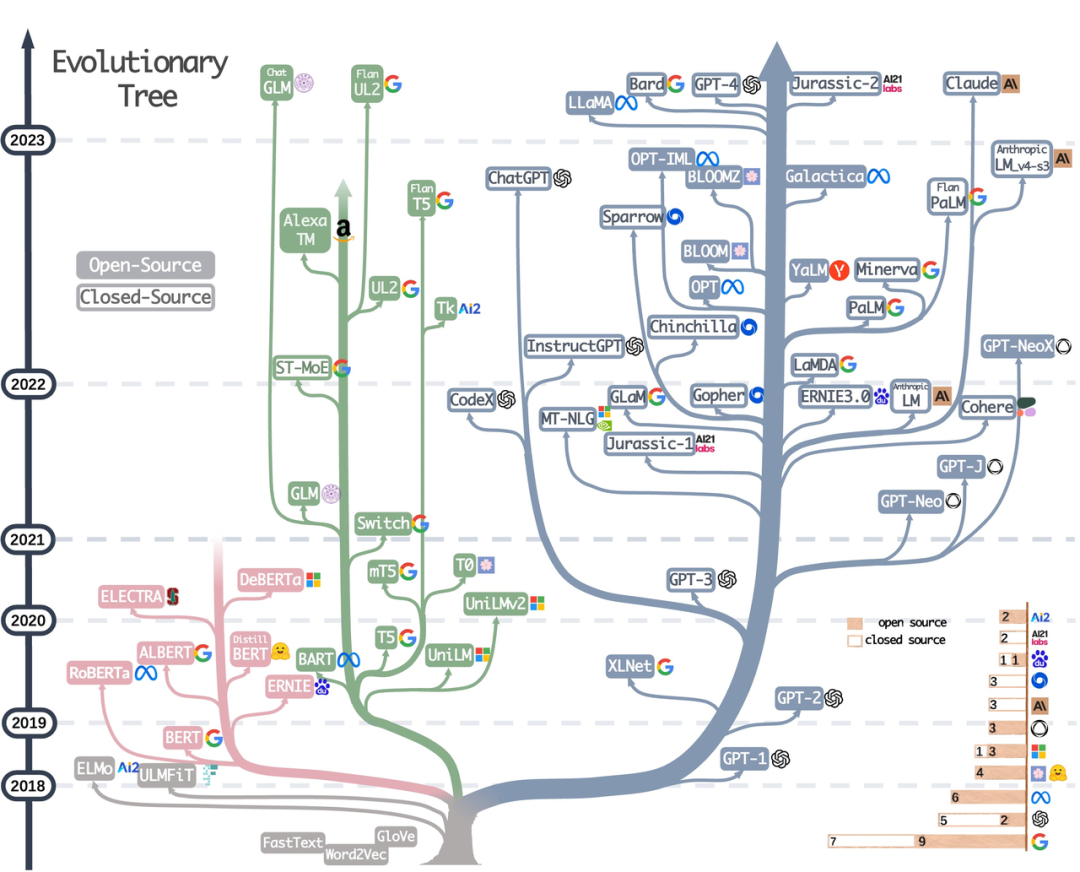
网络上有很整理的论文大集合,但这不是学习路线!https://github.com/Mooler0410/LLMsPracticalGuide
后面我将论文分为三大类,一类是与 ChatGPT 最相关的论文;一类则是与 OpenAI 有竞争相关的论文;最后一类则是基于这些论文的基础上,应该关心的其他相关研究。
这里仅放最重要的与 ChatGPT 相关的论文,其他内容放在最后的附录中。
GPT 系列
【GPT-1】Improving Language Understanding by Generative Pre-Training.
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf 2018.6
【GPT-2】Language Models are Unsupervised Multitask Learners.
https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf 2019.2
【GPT-3】Language Models are Few-Shot Learners.
https://arxiv.org/abs/2005.14165 2020.5
【CodeX】Evaluating Large Language Models Trained on Code.
https://arxiv.org/abs/2107.03374 2021.7
【WebGPT】WebGPT: Browser-assisted question-answering with human feedback.
https://arxiv.org/abs/2112.09332 2021.11
【InstructGPT】Training language models to follow instructions with human feedback.
https://arxiv.org/pdf/2203.02155.pdf 2022.3
【ChatGPT】
blog: https://openai.com/blog/chatgpt 2022.11.30
【GPT-4】
https://arxiv.org/pdf/2303.08774.pdf 2023.3R
重要支持论文
【RLHF】Augmenting Reinforcement Learning with Human Feedback.
https://www.cs.utexas.edu/~ai-lab/pubs/ICML_IL11-knox.pdf 2011.7
【PPO】Proximal Policy Optimization Algorithms.
https://arxiv.org/abs/1707.06347 2017.7
ChatGPT 的诞生
从时间上我们看一下,在 iGPT 出现之前,先后尝试了 CodeX、WebGPT 两个工作,然后在这个基础上训练了 iGPT 以及出圈的 cGPT。
下图我们看到,自 2017 年 tranformer 这个特征提取器发表以来,基于它其实有三条经典路线,GPT、T5、Bert。用直白的话讲,Decoder-only的是 GPT 系列,encoder-only 的是 bert 系列,而 T5 则是原本的 en-de,是在 transformer 的基础上发展来的。在这些信息的基础上,我们可以看到 gpt、t5 和 bert 本身是三条不同的技术路线,自然他们在擅长的任务,各自的特点上也有所不同。
GPT:自回归,适合做生成;由于其特点,为了在理解任务上达到和bert相同的效果,成本较高。
T5:en-de,理论上是结合了 GPT 和 BERT 的优点,但会带来参数的暴涨,训练成本很高,google 提出后并未过多发展,性价比相比 GPT 暂时未知(但我觉得潜力很大);T5 统一了 NLP 任务的形式,一切都可以是 Text2Text 的形式,与 GPT 解决问题的思路是一致的。
Bert:自编码,不适合做生成,在理解任务上 finetune 形式性价比很高。
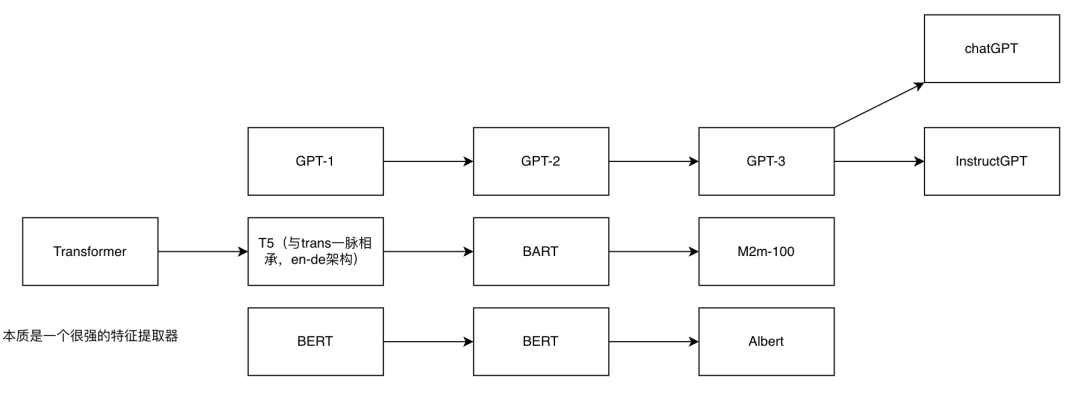
当前我们来核心看看 cGPT 是怎么诞生的,其他就先不管了。
GPT1 到 GPT3,CodeX、WebGPT、InstructGPT 是关键的几个论文,也是我们能够最直接了解到 OpenAI 当前工作进展的几个开源工作,而 RLHF 与 PPO 则是训练方法相关的论文,为了达到 cGPT 的效果,这些训练方法起到了重要的作用。
GPT(GPT-1):这是 GPT 系列的第一个模型,发布于 2018 年。GPT-1 拥有 1.17 亿参数,其突破性之处在于引入了单向上下文建模,通过预测下一个词来生成连贯文本。
从此时起,让 NLP 进入了预训练大语言模型+finetune 的时代。
GPT-2:发布于 2019 年,GPT-2 具有 15 亿参数,相较于 GPT-1 有很大的改进。它使用了更大的训练数据集,提升了模型在处理不同语言任务和生成连贯文本方面的能力。当时,GPT-2 因其生成能力强大而引起关注,甚至引发了有关潜在滥用风险的讨论。
开放了 API,开源了一个相对小的模型,没有开源论文中的所有模型
论证了 zero-shot 的效果和 promising 的前景
开始了大数据,大模型的演进之路
GPT-3:发布于 2020 年,GPT-3 是当时最大、最强大的自然语言处理模型之一。它拥有 1750 亿参数,对比 GPT-2 有很大的扩展。GPT-3 在多种任务中表现出色,如代码生成、文本生成、问答等,甚至可以在未经微调的情况下完成某些任务。尽管 GPT-3 取得了显著的进步,但仍存在一些问题,如偶尔产生有害或不相关的内容。(开始 close AI)
提出了 in-context learning,避免 fintune 会将模型的信息遗忘,导致能力下降。泛化性变弱。
带领了 Prompt 的兴起(其实 GPT/bert 的时候就已经有了初步的 prompt,当时为了构建一些任务或者训练样本,会对数据做一些小改动)。
CodeX:发布于 2021,基于 GPT-3 finetune 得来,专门用于提高软件开发和编程的效率和质量,也是 Copilot 背后的技术支持。相关研究发现,在大量科学文献 / 代码上进行训练可以显著提高基础模型的推理/编码能力。
在给定数据集 HumanEval 上论证了 LLM 在解决代码编写问题上的可能性,在 repeated sampling 机制下 Codex 能解决大部分的编程问题。
引起广泛关注和讨论:CodeX 的发布引起了广泛的关注和讨论,认为它将极大地改变软件开发和编程的方式。但同时也引发了一些担忧和问题。
这个工作的诞生为后续 ChatGPT 强大的代码能力埋下了伏笔(我理解也是坚定了 OpenAI 的信心)。
代码的强逻辑性和规范性,猜测有利于 LLM 的能力优化。
WebGPT:同样在 2021 年,基于 GPT-3 finetune 得来,是一次与 Bing 的强联合,利用 Bing API 创建了一个模型和交互的搜索浏览环境,先利用 Bing API 进行信息检索,然后将检索的结果+问题交给 LLM 进行解答(这个过程会重复进行,由模型决策,pre-autogpt)。
收集了用户行为数据,用来教模型决策(嗅到了 autogpt 的味道)。
这里和后续的 cGPT 其实很像,都是对问题的回答,但用了 Bing 的检索结果作为 LLM 的 Prompt。
这篇论文的训练方法中用到了基于 BC 的 SFT(这里的 BC 就是用户行为数据 Behavior cloning),基于 BC 模型训练了一个RM模型,从而将 RM 输出的奖励(惩罚)使用 PPO 算法在对 BC 模型进行微调,以进一步提高模型的学习效果。
这篇工作就是 iGPT 的前序工作,只是在 iGPT 中将对齐的内容/目标做了改动,里面暴露了很多数据收集分析上的细节,同时也是LLM和搜索的一个结合的重要工作。
果然是微软的一个研究院。
InstructGPT:较为详细的介绍了 iGPT,大家也是认为这个工作是 cGPT 的重点暴露,因为 cGPT 号称和 iGPT 的技术点几乎一模一样。而iGPT的核心主要有三点:
Alignment:与用户对齐的理念,好的技术方案设计和执行导致了其良好的效果。这一点非常关键
SFT 训练(supervised fine-tuning):收集prompt&Answer pair(对于 cGPT 来说,prompt&answer 的格式是 dialogue format 的),基于这些数据对 LM 进行 SFT 训练(supervised fine-tuning)
RLHF:
RM:奖励模型的训练(reward model training)。基于收集好的 prompt,让 SFT 好的模型输出结果,然后人工标注好,让 RM 学习哪些标注好的数据是正确的
PPO:近端策略优化模型( reinforcement learning via proximal policy optimization):基于上面训练好的两个模型,让 SFT 对 prompt 进行输出,然后基于 RM 给出的分数作为模型自我迭代的依据,从而不断优化模型。
cGPT:理论上和 instructGPT 是并行关系,只是在数据格式上有所不同:We mixed this new dialogue dataset with the InstructGPT dataset, which we transformed into a dialogue format.
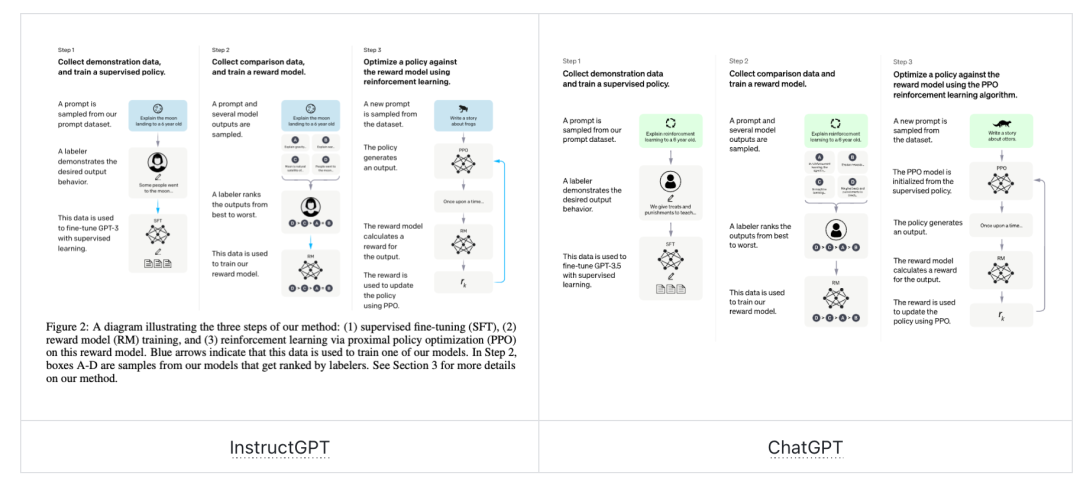
从上面的工作我们可以看到,18 年开始,确定一个技术方向,在这个过程中不断的尝试,不断基于之前的工作进行修正,探索,一步一步前进,这个过程很有趣,最终得到了 cGPT。
技术点概括
我们浏览一下以上的论文,可以总结出其取得当前成绩的关键点:
infra:需要提前建设
算力:硬件(钱和基础设施支持。
工程:随着数据上升,工程与算法的互相匹配实现就很重要。
数据:决定了上限:公开数据有很多,但具体如何收集,如何处理、分析应用是关键。
从论文中,我们看到即便是公开数据,也花了很大的功夫去分析比如 train/test 之间的覆盖,benchmark 对模型的评估与模型训练数据之间的关系等要素影响。
训练数据的选择清洗很细节。
收集用户标注数据的时候,有很细节的设计,包括但不限于 gui,数据可靠性机制设计等。
决定了应用效果。
算法:模型设计决定了能多逼近上限。
评估标准:(量化)评估模型性能。论文中虽然没有提出一个评估标准,但是我们看到 OpenAI 做了大量的工作来分析模型性能,以及数据对模型性能的影响。有评估,才能知道模型当前的进展以及新的工作怎么发展。(参见 GLUE or CLUE)
Wrapper for 应用:
技术应用:Prompt-engineer;梳子模型(梳子的齿是prompts,横着的齿根是 LLM 底座)。
业务应用:ChatGPT 等。
商业化方式:除了产品使用会员制外,暂无明确路径。
团队构建:有动力,有灵魂人物拍板,合理的商业化运作(做事情是需要正反馈的)。
| 模型 | 介绍 |
|---|---|
| GPT4 | 预计参数量 1-1.7w 亿,支持文本和图像,输出文本(但是可以支持编程绘图),在各项任务上表现更好 |
| GPT3.5(instructGPT和chatGPT) | 1750 亿参数,文字输入输出;规范了 Alignment 这个概念,规范了训练流程:SFT、RLHF(RW+PPO);基于上文,我们看到这里集合了 WebGPT 和 CodeX 的优点。 |
| GPT3 | 1750 亿参数,文字输入输出。提出 in-context learning(0/few-shot) |
| GPT2 | 15 亿参数,文字输入输出。弱化版 GPT3,也是大家摸索 GPT3 的重要参考 |
| GPT1 | 1.17 亿参数,文字输入输出,无监督预训练,task oriented finetuning->下游任务上需要 finetune,没有足够泛化性,同时 finetune 需要数据 |
复现与追赶
在当前有一个真理可以记住,只要有人说:“论文都是公开的,技术都是现成的,只要有钱,给一定的时间,大家训练个大预言模型不是分分钟的事情。”就一定是外行。
ChatGPT 的工程、模型和算法细节没有公开,数据处理细节没有公开;当前openAI已经将相关技术作为商业机密进行保留,从 GPT-3 就开始保密,至今已经有三年。
当前大模型调研
由于我们是想要跟进最新的内容,所以自然可以放弃很多过程指标。之前讲到,整体其实有两条路线可以走,T5 和 GPT。我们以这样的方式列出来。
对于应用和学术,要以两种视角来看待。应用方,当前一定关心的是ChatLLM,因为这是一个可以在淘金时代卖水以及最快测试应用场景的基础应用;而技术视角,除了关心 chatLLM,还应该关注其底层的 LLM 是什么,这才是基础。
以下是截止成文的时候比较流行的工作,从开源程度,学习上手以及运行的成本看,推荐学校出得,ChatGLM 和 Moss 或许会友好一点。
| 名称 | 介绍 | 地址 |
|---|---|---|
| Moss | 复旦大学邱老师组发布的语言模型,支持对话,全部开源,推荐了解和学习。 | https://github.com/OpenLMLab/MOSS |
| ChatYuan | 元语智能发布,孵化于中文 NLP 开源社区 CLUE。CLUE 整合大量中文资源,均由 NLP 自由开发/爱好者推动,推荐了解。 | https://github.com/clue-ai/ChatYuan |
| ChatGLM | 清华大学发布。ChatGLM 版本多,效果好,可以在自己电脑上运行,因此十分受欢迎。十分值得大家尝试!中英双语。另,推荐了解 GLM,chatGLM 的基座,yangzhilin(XLNet 作者)参与的工作https://arxiv.org/abs/2103.10360 | https://github.com/THUDM/ChatGLM-6B/blob/main/README_en.md |
| OPT | MetaAI 发布,175B 模型,模型结构与 GPT-3 基本一致,推荐了解,可以帮助理解 GPT-3。单语言。 | https://github.com/facebookresearch/metaseq/tree/main/projects/OPT |
| Bloom | 多语言, Bigscience 发布,与 GPT-3 基本一致,全部开源,训练框架使用 Megatron-DeepSpeed,效果也很好,推荐了解和试用 | https://github.com/huggingface/transformers-bloom-inference |
| LamDA | 137B 参数,google 发布。decoder-only,理论上与 ChatGPT 架构相似。 | https://github.com/conceptofmind/LaMDA-rlhf-pytorch |
| LLaMA | LLaMA 是著名的 MetaAI 开源的大语言预训练模型,也因为它的开源以及斯坦福发布的 Alpaca 工作,让 LLaMA 成为最近这些天发布的模型的基础(也就是说最近很多模型都是用 LLaMA 微调的)。而这个是 Decapoda Research 在 HuggingFace 上部署的。是将原始的预训练结果转换成与 Transformers/HuggingFace 兼容的文件。 | https://github.com/juncongmoo/pyllama |
| 百度、阿里、讯飞等 | 当前国内的公司在不断的发展和推进,无论从使用上还是从底层技术上都推荐 follow。 |
大语言模型发展历程:https://briefgpt.xyz/lm
如何复现
既然在开头已经吐槽过,那么我们这里直接说复现思路——当一个强大的工程师,不需要思考,照着开源抄,就领先了 99% 的人。
从 GPT 已经公开的资料来看,LM 这个模型基底结构其实并不是最重要的,当前我们已经有的结构,只要包括了 decoder,其实都可以做到文本生成,在很多细节上,也有多种优化点。但当前能让 OpenAI 破局的,核心是如何构建数据,如何收集数据,如何将这些数据用来做模型训练,才是关键和核心。这些是需要格外注意的。
From Scratch
从 0 开始,有两种思路
一种是基于 GPT-2 或者 Bloom 等 GPT 系列的 LM,参考其发展路线,自行实现;
另一种则是基于当前已经摸索清楚路线,且开源的 Moss、LLama 等,依据实现。
听起来比较简单,需要重点解决的依然是上面提到过的一些要点:
数据:数据收集、数据清洗、数据标注等细节问题,包括成本与标准流程。
老师(算法细节)决定上限:当前无开源模型解决 GPT-4,且 GPT4 并非 OpenAI 内部最强的进展。这部分的差异需要自行推导摸索。LLM 时代,暴力穷举可能性,大力出奇迹来追赶 SOTA,特别算力受限,可能性不高。
工程:如何快速进行训练和推理,是一个好问题。
其他:很重要,但在解决上面的问题才会出现的,比如安全、评估、成本优化、效率等方面。
From a strong baseline
From scratch,讲的是技术路线甚至代码都已经 ready,但是模型是需要自己重新训练的,里面会有很多细节操作。
而从一个强有力的 baseline 开始,那么就是在一个已经有的模型的基础上进行改良。
需要关注和解决的问题是:
同样,上面提到的几项也很关键,对每一项的理解都很重要,但对实现的全面性和细节都要求更低。
要往哪个方向 fine-tining。
未开源部分依然需要自行摸索。
相信的力量
最近听一些分享/讲座等,有说到想象力、愿力、心力。都差不多。本质是需要有坚定的信念才可以。
OpenAI 在 GPT-2 被退稿的时候依然能够坚持这个方向(其实GPT系列被退也没错,Roberta 当年也没过,原因大差不差)。
有一些玄学,本质是需要有灵魂人物来带领。
评估的重要性
前面我们讲到了评估,这一点很重要,直接决定了这些追赶和复现的团队是否有足够明晰的目标和标尺来衡量自己的工作进展,而这一点当前很困难。
举个 🌰
如果我们认为高考可以反映一切,那么高考分数高的,就应该在一切上表现更好。那么我们干什么都可以直接用高考分数来衡量了。
显然,已知用人单位会从多个角度来考虑,高考分数高,等于适应环境,可以吃高考的苦,有较好的学习理解能力,在大学受到了较好的培养。更进一步,会考虑到在哪个省份高考,从而更进一步考虑其综合能力,潜力,高考难度等……多种因素。所以说明高考分数只能反映一部分能力。
所以当模型仅被用于执行单一任务的时候,我们可以出考题(benchmark)来评估其能力;
但当 LLM 成为一个综合模型,我们想要将其应用于多类型任务时候,就意味着需要进行多维度考察;
而当其成为一个对话应用的时候,那么我们更希望可以对其进行拟人化的考察,除了硬性能力,还希望可以 check 其是否更像人。
……所以就很麻烦。
可以参见以下报道,UCB 在引入 Elo 进行评估,爱丁堡大学的 Fuyao 在研究从推理上评价模型能力,CLUE发布SuperCLUE进行中文通用大模型综合性评测基准。
https://36kr.com/p/2243109425885057
https://github.com/FranxYao/chain-of-thought-hub
https://mp.weixin.qq.com/s/6CDnyvMsEXtmsJ9CEUn2Vw
LLM带来的影响
LLM 的出现,给产学界带来了冲击,此时思考它的出现到底带来了什么样的影响。由于每个人所处情况不同,我们可以从不同的视角来看待这个问题。
首先,得用,这样才能获取第一手感知;其次思考这个的出现给学术界带来了什么;接下来考虑它会对整个产学界带来什么影响;然后考虑给个人带来的影响;最后基于这些因素,考虑基于 LLM 的公司或者产品会是怎么样的。
如何使用模型
这里讲如何使用模型,核心是如何按照自己的想法激活其能力,这里就需要了解 in-context learning,了解 Pormpt。
In-Context Learning 是机器学习领域的一个概念,指不调整模型自身参数,而是在 Prompt 上下文中包含特定问题相关的信息,就可以赋予模型解决新问题能力的一种方式。这个主要是在 few/one-shot 的情况下,给定的示例。所以我认为叫做 ICL 不够贴切,应该叫做 In Context Inference。
Prompt:Prompt(引导词),是一段自然语言描述的文本,它作为AI模型的重要输入来指导模型生成内容。Prompt 的质量对于模型生成效果有较大影响。(本质上 prompt 和 instruct 是一种东西,一个概念,主要是看如何构造 prompt)。
有了这两个基础概念之后,我们就发现,其核心要做的是设计 Prompt 来让LLM(包括 chatLLM)发挥出我们想要其发挥的能力。市场上有很多资料,同样我们抓主要矛盾:
一条 prompt 的组成要素:
Instruction:一个特定的任务或者指令
context:示例、上下文、甚至知识(库)
Input data:就是提问,比如搜索一些东西的时候,输入的问题(有时候和instruction重叠)
Output Indicator:输出格式
prompt 的编写技巧:精准,正面输出信息,不要使用反问等手法;尝试使用 COT-step by step。
多轮 prompt refine:这里要表达的是,基于第一次的prompt以及对应的结果,重新设计第二轮 prompt,通过多轮 refine 来获取更加符合预期的结果。
APE(Automatic Prompt Engineer):自动 prompt 生成。
注意:一条 prompt 在不同的 LLM 上的表现是可以不同的
推荐吴恩达的课程:https://www.deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers/
给学术界带来了什么
研究方向的变化:大模型 LLM 领域,有哪些可以作为学术研究方向? - 知乎(https://www.zhihu.com/question/595298808/answer/2982013608)
由于当前 LLM 对资金以及数据的诉求,大学这样的学术场所未来是否依然适合作为相关研究的孵化地,要打一个问号;是否工业实验室更适合。
LLM 只是一个缩影,LLM 可能会应用到很多领域;也可能会有很多与LLM类似的领域,或许未来这些都不适合在高校进行研究。
给国内学术界:当新的技术爆发越来越多呈现在各个领域散点出现,如何给大众以良好的土壤并激发他们的创新热情将会是一个很值得研究的命题。
给整体的产学界/工业界带来了什么
简单来说,分为三大类影响:
从事 LLM 底层技术开发:需要快速 follow 技术,尽快建立生态,获取生态主导权的 LLM 将会建立壁垒。
从事基于 LLM 的应用开发:理解业务,理解用户,并将这部分理解以及用户反馈数据用于对自己应用的优化,形成闭环飞轮(已有模糊技术路线但尚待验证),这将会是自己的壁垒。
在这个环境下,“卖水卖铲子”的市场会异常活跃。
在这个三类影响下,借助陆奇分享的 ppt,用下图来看看全面形态。左下角就是 LLM 底层技术,在他的基础上无论是 ChatGPT 还是相应的 playground 等,都属于应用,尽管有应用内应用(比如 chatgpt-plugin),而在往上一层走,就到了 copilot 等产品层面。
从这图上看,这个 OpenAI 的生态当前已经初步形成,也就是说它的竞争壁垒已经初步建立。如果说这真的是一个操作系统级别的革命的话,那么未来市场上一定只会存在有限家公司有各自的生态,比如苹果和安卓。

可以说,在新的时代下,公司之间竞争的依然是用户。LLM 竞争开发者,应用竞争下游用户,卖水卖铲子的竞争前两个的淘金者。这些用户会产生数据,而如何将这些数据用在模型上,是一个依然值得研究的问题。
结合 LLM 进行的服务,当前思路主要有两种:
一种是以 LLM 作为 backbone,对其生产的结果进行后处理以确保符合预期;
一种是当前的主流系统作为 backbone,利用 LLM 做优化(即将前者输出作为 prompt 构成)。
基于这样的思路,也就能看到,将数据融合进去的思路,要么融合到LLM中去,要么融合到确定性结果中去(知识库)。
第二种思路,就是深度学习当前挂靠到各个业务的方式。但若说LLM是一个操作系统级别的变化,那一定不会止步于此,未来会是什么样子的呢?还需要思考。
个人从业者的影响
对于个人来说,快速了解相关技术,建立自己的认知体系,加快对新知识的 follow 最关键。
在这个基础上,选定自己的定位和角色,快速出击。明显看到生态壁垒、用户和业务壁垒依然可行,要快速找到建立的方向并贯彻执行。
对传统的互联网技术同学来说,以下是可以参考的技术栈。对于非技术同学来说,则是要好好感受和使用大模型的能力。这是一个需要技术和非技术同学一起探索新需求和应用的时代,都需要对新的技术进行理解和把握,才能提出有价值的应用。

未来基于 LLM 的公司/产品会是什么样子的
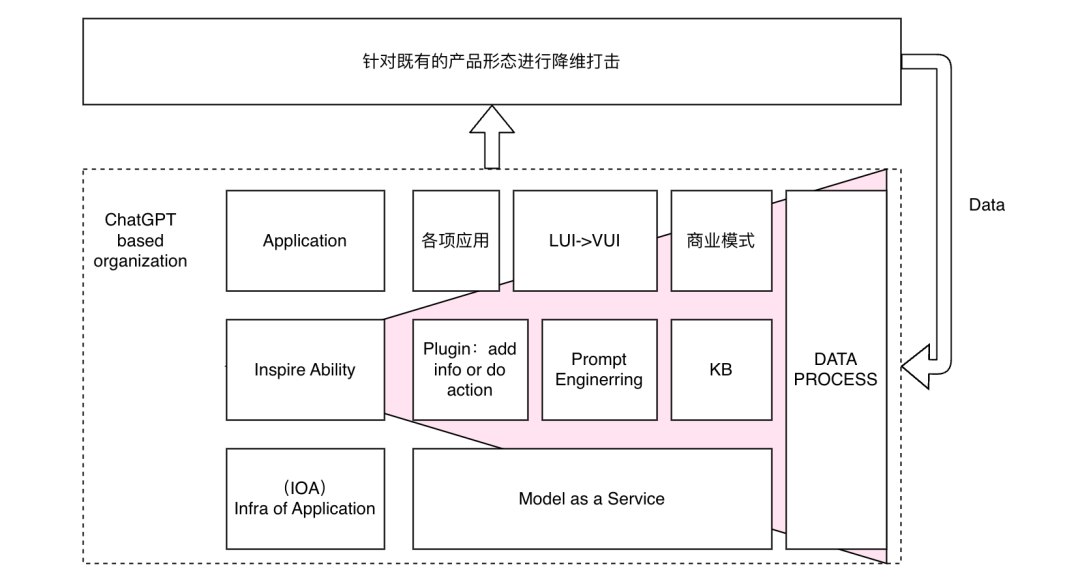
上图是一个比较粗糙的示意图。在新的浪潮下,要找到自己的公司的定位在哪里。从之前陆奇分享的 OpenAI 的生态中,我们可以看到很多东西,将其整合抽象简化,那么在当前的时代,我们的工作有上图中描述的:
APP:应用层。除了应用外,由于 cGPT 的出现,那么在 UI 上会有很大变化,除了语言外,要留意语音巨大的潜力。
Inspire Ability:能力激发层。由于我们基于 Maas 进行上层开发设计,那么如何能够激发模型的能力,放大模型的能力(plugin),对模型能力进行补充(事实性等 KB),则是这一层重点要做的工作。
MaaS:除了模型本身能力的优化,训练/推理的速度和成本,上层开发者生态友好性等都是重点问题。简单的衡量标准,就是别人是否愿意在你的 MaaS 上进行后续开发。
DATA 层:这一层很关键,因为它关系到了能力是否可以长期迭代,某种意义上也是壁垒是否可以形成的关键要素。
应该关注的几个要点
如何理解推理能力
重点参考 or 复制:
https://yaofu.notion.site/6dafe3f8d11445ca9dcf8a2ca1c5b199
本文是 fuyao 分享的关于复杂推理相关的分析,其认为这是 GPT 这样的 LLM 成为下一代计算平台 / 操作系统的关键能力。其中关于 Code/Math 等相关的分析特别有趣,推荐阅读。
在科学文献/代码上进行训练可能会提高推理能力,这部分的讨论很有趣,也很符合直觉。
Lewkowycz et. al. 2022. Minerva: Solving Quantitative Reasoning Problems with Language Models
在来自 Arxiv 论文的 38.5B 的 token 上继续训练 PaLM 540B。
在 MATH (一个需要使用 LaTeX 格式回答问题的困难数据集),上的得分为 33.6(GPT-4 的得分是 42.5)。
Taylor et. al. 2022. Galactica: A Large Language Model for Science
在包含论文、代码、参考资料、知识库和其他内容的 106B token 上预训练一个 120B 语言模型。
在 MATH 上的表现为 20.4(Minerva 33.6,GPT-4 42.5)。
Chen et. al. 2021. Codex: Evaluating Large Language Models Trained on Code
在 159GB 代码数据上继续训练 12B GPT-3 模型,提高了 HumanEval 数据集上的代码性能。
LLM 作为下一代操作系统是什么意思
首先,虽然炒的沸沸扬扬,如果真的类比操作系统,当前新的 os 的具体形态并不清晰,承载物究竟是什么样子,看起来在高速发展,但如果停滞不前的话(假设当前技术发展中遇到了不可预知的难题)也很难承载操作系统这样的重任。
但是我们可以看到,在当前 LLM 远超过历史模型能力的加持下,在当前已经给交互带来事实性冲击的基础上,未来一定有大的变化。只是这个变化大概率还会有一次大的技术升级或者融合,毕竟 GPT-4 才刚发布,从这个角度看,已公开技术上还有肉眼可见的发展空间。
最后,我们将其认定为操作系统,那么最后一定只有有限家,大家分别在不同领域各领风骚。走得早和走的好都很重要。
从这一点上看,所谓生态先行就显得尤为重要,谁能先把生态搭建,抢占用户心智,自然就可以建立一种无形的壁垒。就好比安卓和苹果,tensorflow 和 pytorch。这一点对于国内的同行来说应该是当前最为紧急的。
学习社区的紧迫性
当前以 fuyao 为代表的 notion 交互,国外流行的 twitter 交互加剧了当前在专业领域内的小范围通过文本交互和讨论的氛围。
陆奇的每一次演讲都在疯狂更新资料,组建大模型日报团队专门分享日报以跟进前沿信息
各路大佬每隔一段时间就会出来一次,每天都有新的 blog、新的论文、新的产品甚至公司出现
大家对学习社区的渴求程度,对沟通和思维碰撞的渴求越来越高;但由于个人的实际知识背景不同,导致同频讨论越发困难,如何能够有同时具备以下特点的学习社区,是一个很好的问题:
如何建立小型、敏捷的互动学习
大型、专业的分享社区
如何找到 MaaS 擅长的应用
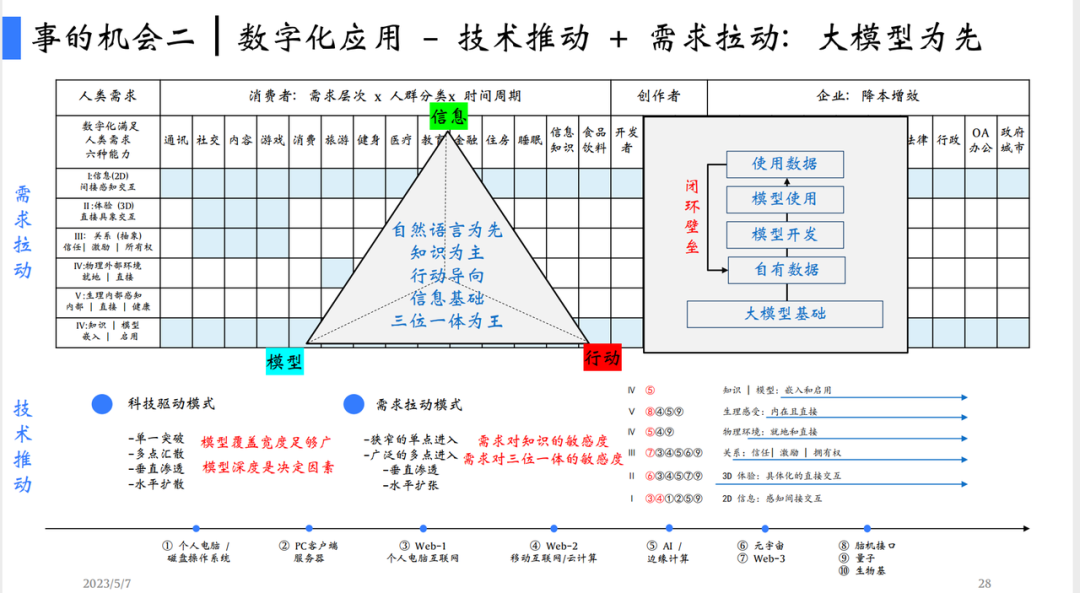
以自然语言为先来设计产品。在新的时代,一定有其擅长的产品或者领域。上面讲到了基于 LLM 的公司/产品会对既有产品生态形成降维打击,那么如何才能找到擅长的部分呢?陆奇在5月7日北京的分享上给出了他的认识。
首先基于传统认识,应用一定是技术推动+需求拉动发展的,且要利用好大模型的优势。从三个维度分析,信息、模型以及行动。信息一定是基础,而模型(知识+思考整合+输出)影响越大的部分,大模型的优势就越明显。而行动,当前仅在数字化系统内部是 ok 的,譬如 autoGPT。
第二点则是应用上的壁垒,要将对数据使用的结果能够反馈到使用的各个环节,才能够形成正向飞轮从而不断迭代优化。
能够做到有多好,核心在于认知能力和对工具的使用能力。
OpenAI 的发展历史
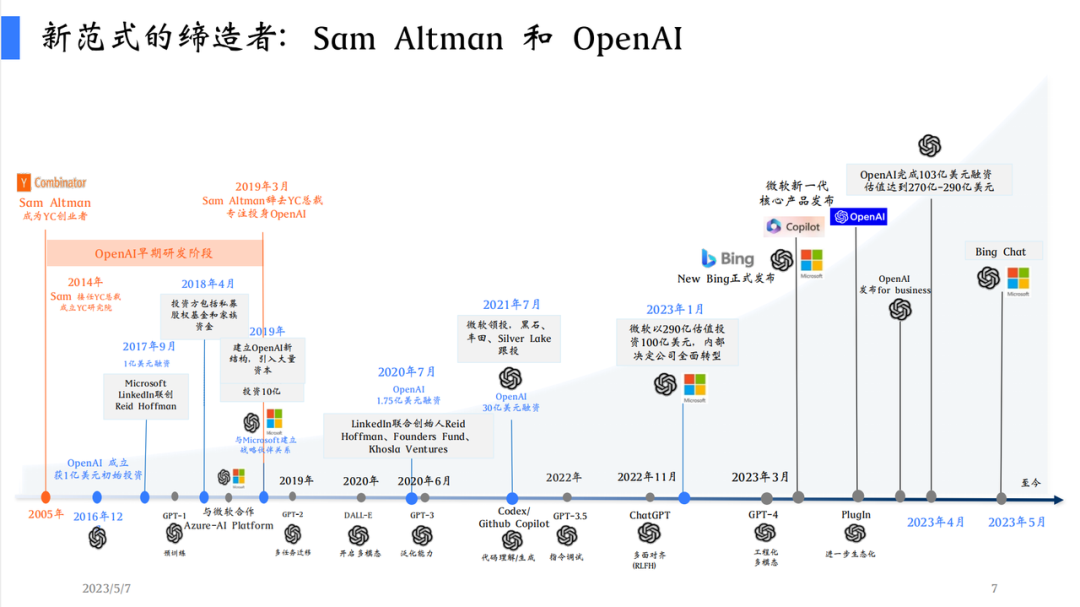
陆奇分享了自己的一个认识,OpenAI 有自己的思想体系,所以现在必须要能自己做科研,自己写代码,自己做平台和商业化。
商业化
本文没有讨论商业模式,这是一个很重要的点,在这个时代,谁先探索出合适的商业模式,就可以形成利润闭环,从而快速迭代自身业务。
一些思考可以参见:https://zhuanlan.zhihu.com/p/611867921
Take away
当前 LLM 进展迅速,首先搞清楚 LLM 是大预言模型,chatgpt 是基于 LLM 做的一个应用导向的产品。抓住基础,然后 follow sota,才能看懂听懂
搞清楚核心竞争力:
做 LLM 的:技术可以领先,但无法成为壁垒。但是生态可以成为壁垒,让用户靠你来养活自己。这是竞争的核心要素。
做 LLM 上的应用:需要将用户数据和业务数据进行闭环,加速模型在业务上的表现,这个是存在壁垒的,如何可以很好的闭环,是一件值得研究的事情。
研究者:从业者和研究者。独到的见解(有点虚)。换句话说应该更加强调认知能力和执行力,对于很多知识的学习可以放下,工具性质的使用能力需要很强。
由于数据的重要性,所以如何形成自己好的数据处理 framework or pipeline 是一个关键问题。
aiot 未来一定有大机会,当信息获取与理解,模型思考与决策这样的能力都具备的时候,那么切入到实际的 action 中就显得十分重要而合理。
当前 ChatGPT 的出现,其实很像一个咨询的角色,究竟是提升咨询的效率还是替换咨询的角色,是一个很好的问题。
人嘛,最重要的是开心
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

附录:
论文合集
OpenAI系列
重点
[1]【GPT-1】Improving Language Understanding by Generative Pre-Training.
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf 2018.6
[2]【GPT-2】Language Models are Unsupervised Multitask Learners.
https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf 2019.2
[3]【GPT-3】Language Models are Few-Shot Learners.
https://arxiv.org/abs/2005.14165 2020.5
[4]【CodeX】Evaluating Large Language Models Trained on Code
https://arxiv.org/abs/2107.03374 2021.7
[5]【WebGPT】WebGPT: Browser-assisted question-answering with human feedback.
https://arxiv.org/abs/2112.09332 2021.11
[6]【InstructGPT】Training language models to follow instructions with human feedback.
https://arxiv.org/pdf/2203.02155.pdf 2022.3
[7]【ChatGPT】 blog: https://openai.com/blog/chatgpt 2022.11.30
[8]【GPT-4】https://arxiv.org/pdf/2303.08774.pdf 2023.3R
[9]【RLHF】Augmenting Reinforcement Learning with Human Feedback.
https://www.cs.utexas.edu/~ai-lab/pubs/ICML_IL11-knox.pdf 2011.7
[10]【PPO】Proximal Policy Optimization Algorithms.
https://arxiv.org/abs/1707.06347 2017.7
其他可关注论文
[1] Fine-tuning language models from human preferences.
pdf(https://arxiv.org/abs/1909.08593)
code(https://github.com/openai/lm-human-preferences) 2019.9
[2] Learning to summarize from human feedback.
pdf(https://arxiv.org/abs/2009.01325)
code(https://github.com/openai/summarize-from-feedback) 2020.9
[3] Text and Code Embeddings by Contrastive Pre-Training
pdf(https://arxiv.org/abs/2201.10005) 2022.1
[4] Efficient Training of Language Models to Fill in the Middle
pdf(https://arxiv.org/abs/2207.14255) 2022.7
[5] Training Verifiers to Solve Math Word Problems
pdf(https://arxiv.org/abs/2110.14168) 2021.10
[6] Recursively Summarizing Books with Human Feedback
pdf(https://arxiv.org/abs/2109.10862) 2021.9
[7] Generating Long Sequences with Sparse Transformers
pdf(https://arxiv.org/abs/1904.10509) 2019.4
可关注工作
[1] GPT-3: Its Nature, Scope, Limits, and Consequences
https://link.springer.com/article/10.1007/s11023-020-09548-1?trk=public_post_comment-text
[2] Understanding the Capabilities, Limitations, and Societal Impact of Large Language Models
https://arxiv.org/abs/2102.02503 2021.2
[3] Generative Language Modeling for Automated Theorem Proving
https://arxiv.org/abs/2009.03393 2020.9
[4] Process for Adapting Language Models to Society (PALMS) with Values-Targeted Datasets
https://cdn.openai.com/palms.pdf 2022.6
[5] Scaling Laws for Neural Language Models
https://arxiv.org/abs/2001.08361 2020.1
[6] ChatGPT is not all you need. A State of the Art Review of large Generative AI models
https://arxiv.org/abs/2301.04655 【说你行很麻烦,不行却很容易】
[7] In context learning survey
pdf https://arxiv.org/abs/2301.00234 2022.11
[8] Reasoning with Language Model Prompting- A Survey
https://arxiv.org/abs/2212.09597
竟对模型:介绍了其他流行的语言模型,如 BERT、XLNet、RoBERTa、ELECTRA、Sparrow等
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(https://arxiv.org/pdf/1810.04805.pdf)
【LaMda】 LaMDA: Language Models for Dialog Applications.
pdf(https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2201.08239) 2022.1
【Sparrow】 Improving alignment of dialogue agents via targeted human judgements. pdf(https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2209.14375) 2022.9
【T5】Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer https://arxiv.org/pdf/1910.10683.pdf
DeepSpeed-Chat. Blog(https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat)
GPT4All. Repo(https://github.com/nomic-ai/gpt4all)
OpenAssitant. Repo(https://github.com/LAION-AI/Open-Assistant)
ChatGLM. Repo(https://github.com/THUDM/ChatGLM-6B)
MOSS. Repo(https://github.com/OpenLMLab/MOSS)
Lamini. Repo(https://github.com/lamini-ai/lamini/) Blog (https://lamini.ai/blog/introducing-lamini)
Finetuned language models are zero-shot learners pdf(https://arxiv.org/abs/2109.01652) 2021.9
Scaling Instruction-Finetuned Language Models. pdf(https://arxiv.org/abs/2210.11416) 2022.10
XLNet: Generalized Autoregressive Pretraining for Language Understanding
RoBERTa: A Robustly Optimized BERT Pretraining Approach
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Longformer: The Long-Document Transformer
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Reformer: The Efficient Transformer
Attention Is All You Need(https://arxiv.org/abs/1706.03762.pdf):Transformer (Google AI blog post)(https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html)
Music Transformer: Generating music with long-term structure(https://arxiv.org/pdf/1809.04281.pdf)
https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models(https://arxiv.org/abs/2201.11903)
PaLM: Scaling Language Modeling with Pathways
OPT: Open Pre-trained Transformer Language Models
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
LaMDA "LaMDA: Language Models for Dialog Applications" . 2021. Paper(https://arxiv.org/abs/2201.08239)
LLaMA "LLaMA: Open and Efficient Foundation Language Models" . 2023. Paper(https://arxiv.org/abs/2302.13971v1)
GPT-4 "GPT-4 Technical Report" . 2023. Paper(http://arxiv.org/abs/2303.08774v2)
BloombergGPT BloombergGPT: A Large Language Model for Finance, 2023, Paper(https://arxiv.org/abs/2303.17564)
GPT-NeoX-20B: "GPT-NeoX-20B: An Open-Source Autoregressive Language Model" . 2022. Paper(https://arxiv.org/abs/2204.06745)
参考
陆奇北京演讲:陆奇最新演讲《新范式新时代新机会》完整PPT.pdf(https://miracleplus.feishu.cn/file/TGKRbW4yrosqmixCtprcUlAynzg)
上述 Paper
文中引用链接
感谢大家在网络上的无私分享,很多认识都是基于网络资料形成。






![[Unity] 使用 Visual Effect Graph 制作射击枪焰特效](https://img-blog.csdnimg.cn/73bad64b955246578455763f6fd8ab21.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5buJ5Lu35Za1,size_17,color_FFFFFF,t_70,g_se,x_16#pic_center)