文章目录
- 数据挖掘案例:利用Python获取新冠状病毒肺炎的疫情数据并进行可视化分析
- 一、疫情数据报告网站地址
- 1.1 pyecharts介绍
- 1.2 要用到的库
- 1.3 爬取数据
- 1.3.1 方法1
- 1.3.2 方法2(采用)
- 1.地址
- 2.自己来获取试试看
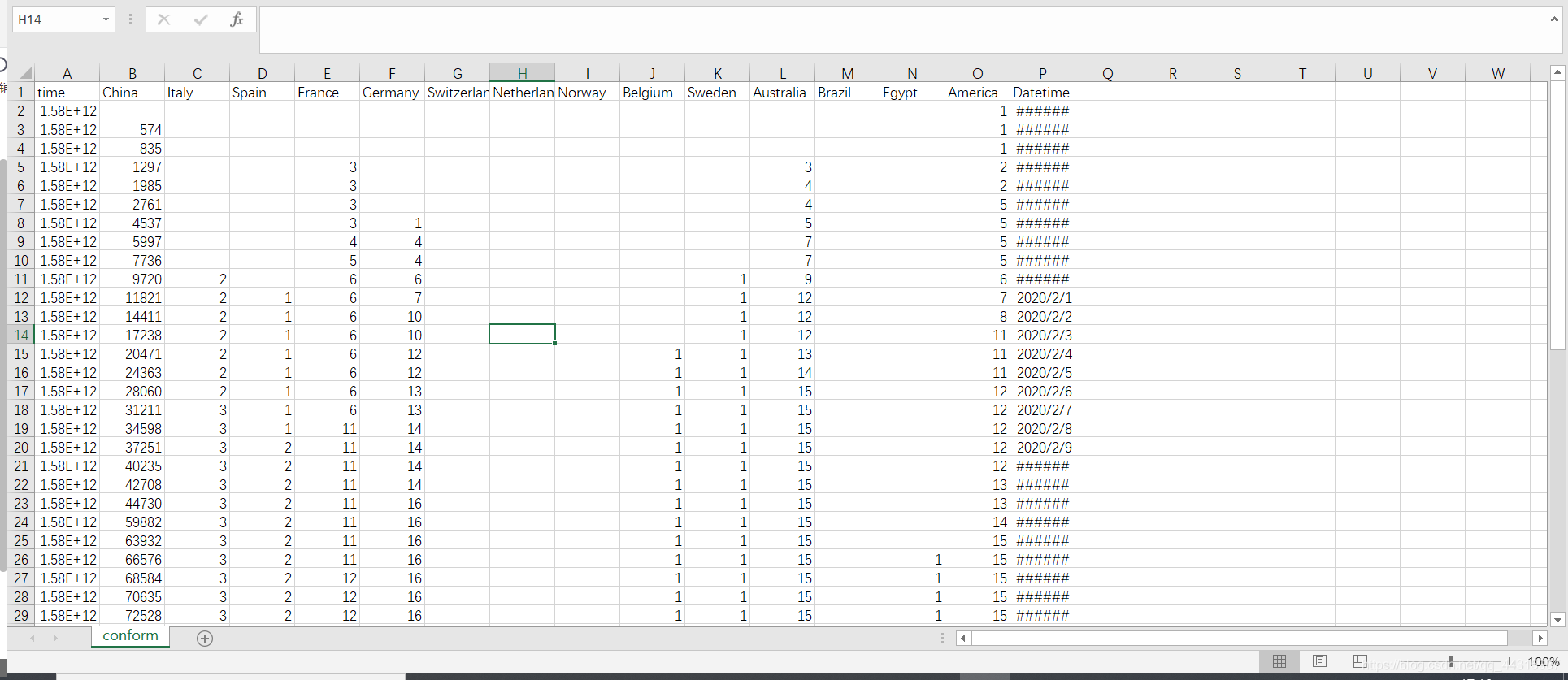
- 二、爬取的数据初查看
- 三、爬取数据的处理
- 3.1 只要data的数据
- 3.2 再变成字典,用两次json.load
- 3.3 将字典命名成变量
- 3.4 读取字典的键
- 四、爬取数据的参数解析
- 1.lastUpdateTime
- 2.chinaTotal
- 3.chinaAdd
- 4.isShowAdd
- 5.showAddSwitch
- 6.chinaDayList
- 7.chinaDayAddList
- 8.dailyNewAddHistory
- 9.dailyDeadRateHistory
- 10.dailyHealRateHistory
- 11.areaTree
- 12.articleList
- 五、处理省份的数据
- 5.1 使用for循环到省份
- 5.2 每个省当天的数据
- 5.3 每个省总的数据情况
- 5.4 将数据变成列表再变成dataframe
- 5.5 查看dataframe数据
- 5.6 安装pyecharts和echarts-china-provinces-pypkg
- 5.7 删除没有用的两列
- 5.7.1 按照数据类型来删除datafram的列【重要】
- 1.先查看一下类型
- 2.目的
- 3.方法
- 4.参数的意思
- 5.我们的处理
- 5.8 对原数据进行覆盖
- 5.9 查看现在的数据
- 六、定义地图,填充数据
- 6.1 pyecharts中的地图
- 6.2 安装导入pyecharts
- 6.3 对当前的库pyecharts进行使用和讲解
- 6.3.1 他的地图map不支持一种格式
- 6.3.2 解决办法
- 6.3.3 导入pyecharts的Map和options(配色,标题要用到)
- 6.3.4 Map.add的参数
- 压缩
- 6.3.5 下一个参数写chaina,其他的国家也可以
- 6.3.6 运行,查看地图
- 七、填充地图颜色部分的说明
- 7.1 颜色配置放在这里
- 7.1.1 颜色配置必须是list包裹dict
- 7.1.2 1-9人之类的范围我们改一下颜色
- 八、打印地图
- 九、数据存储
- 9.1 看一下各个值
- 9.2 保存到mysql
- 9.3 链接数据库
- 9.4 保存每天 的数据,行变列
- 9.5 数赋值给dataframe
- 9.6 数据类型的转换
- 9.7 sql语句
- 9.8 数据传进来了
- 9.9 保存数据
- 9.9.1 国家数据
- 9.9.2 中国各个省份数据
数据挖掘案例:利用Python获取新冠状病毒肺炎的疫情数据并进行可视化分析
一、疫情数据报告网站地址
网站地址:https://news.qq.com/zt2020/page/feiyan.htm
数据来源:https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-28CXBTFt-1582118503090)(img/1582075629587.png)]](https://img-blog.csdnimg.cn/20200219212155486.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
1.1 pyecharts介绍
pyecharts在本地就可以进行交互式画图
1.2 要用到的库
request爬虫
json处理数据
pandas处理数据
import request
import json
import pandas as np
1.3 爬取数据
1.3.1 方法1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DVll0cSN-1582118488194)(img/1582113686860.png)]](https://img-blog.csdnimg.cn/20200219212310611.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GoTywYif-1582118488194)(img/1582113715507.png)]](https://img-blog.csdnimg.cn/20200219212323542.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
ua ,cokkies也可以不带,这个页面没有什么拦截,后面拦截的话可以再加
import requests
import json
import pandas as pddef getData():url = 'https://news.qq.com/zt2020/page/feiyan.htm'headers = {'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'}r = requests.get(url,headers)if r.status_code == 200:return r.text
getData()
爬取到了
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LTsnuyy8-1582118488195)(img/1582113898046.png)]](https://img-blog.csdnimg.cn/20200219212341210.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
怎么取出来呢
bs4
正则
xpath
都可以
1.3.2 方法2(采用)
网站上找直接获取数据的地方
1.地址
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JgD1MA0T-1582118488195)(img/1582114110467.png)]](https://img-blog.csdnimg.cn/2020021921235242.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eINkOBlU-1582118488196)(img/1582114131238.png)]](https://img-blog.csdnimg.cn/2020021921240150.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
这里面有每一天的数据
每个省份 地级市的数据
拿出这些数据源的地址
2.自己来获取试试看
import requests
import json
import pandas as pddef getData():url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5'headers = {'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'}r = requests.get(url,headers)if r.status_code == 200:return json.loads(r.text)
getData()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0FbQ3Vfn-1582118488196)(img/1582114203686.png)]](https://img-blog.csdnimg.cn/20200219212411436.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
json转换成字典的了
二、爬取的数据初查看
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mUUnTNKv-1582118488197)(img/1582114226266.png)]](https://img-blog.csdnimg.cn/20200219212420879.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
第一行不要,后面的有用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T7Ag1W1U-1582118488197)(img/1582114251659.png)]](https://img-blog.csdnimg.cn/20200219212428634.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
对应之前的网页 ,1751这些都是有的,都不用计算了
三、爬取数据的处理
3.1 只要data的数据
3.2 再变成字典,用两次json.load
3.3 将字典命名成变量
import requests
import json
import pandas as pddef getData():url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5'headers = {'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'}r = requests.get(url,headers)if r.status_code == 200:return json.loads(json.loads(r.text)['data'])
data_dict = getData()
3.4 读取字典的键
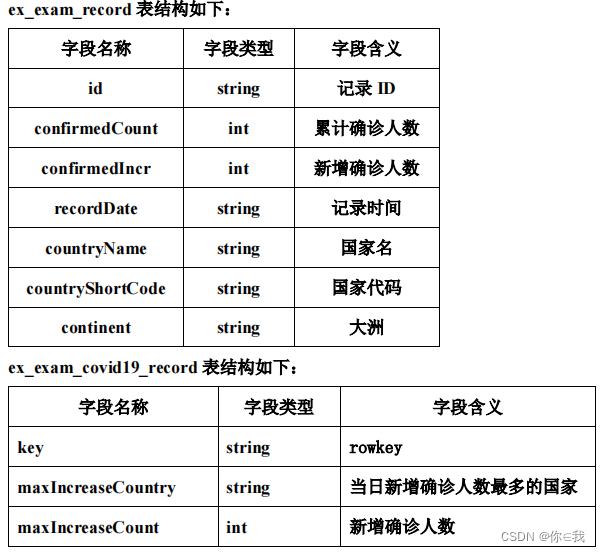
data_dict.keys()dict_keys(['lastUpdateTime', 'chinaTotal', 'chinaAdd', 'isShowAdd', 'showAddSwitch', 'chinaDayList', 'chinaDayAddList', 'dailyNewAddHistory', 'dailyDeadRateHistory', 'dailyHealRateHistory', 'areaTree', 'articleList'])
四、爬取数据的参数解析
1.lastUpdateTime
lastUpdateTime :最后更新时间
'2020-02-19 20:06:10'
2.chinaTotal
chinaTotal :累计值
- confirm 确诊
- heal 治愈
- dead 死亡
- nowConfirm 现有确诊
- suspect 疑似
- nowSevere 重症
{'confirm': 74281,'heal': 14479,'dead': 2009,'nowConfirm': 57793,'suspect': 5248,'nowSevere': 11977}
3.chinaAdd
chinaAdd :每日新增 和 chinaTotal字段一致
-
confirm 确诊
-
heal 治愈
-
dead 死亡
-
nowConfirm 现有确诊
-
suspect 疑似
-
nowSevere 重症
{'confirm': 1753,'heal': 1918,'dead': 139,'nowConfirm': -304,'suspect': -994,'nowSevere': 236}
4.isShowAdd
前端进行判断的状态码
True
5.showAddSwitch
前端进行判断的状态码
{'all': True,'confirm': True,'suspect': True,'dead': True,'heal': True,'nowConfirm': True,'nowSevere': True}
6.chinaDayList
每一天的数据(2020.1.13-至今)
- confirm 确诊
- heal 治愈
- dead 死亡
- nowConfirm 现有确诊
- suspect 疑似
- nowSevere 重症
- deadRate 死亡率
- healRate 治愈率
- date 日期
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AmDH45eF-1582118488198)(img/1582115367684.png)]](https://img-blog.csdnimg.cn/202002192124450.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
7.chinaDayAddList
同上一天比增加的数据
同比上一天新增加的数据 和 chinaDayList字段一致
- confirm 确诊
- heal 治愈
- dead 死亡
- nowConfirm 现有确诊
- suspect 疑似
- nowSevere 重症
- deadRate 死亡率
- healRate 治愈率
- date 日期
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yBWhyfaR-1582118488199)(img/1582115408770.png)]](https://img-blog.csdnimg.cn/2020021921245567.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
8.dailyNewAddHistory
湖北内外每天新增确诊情况对比
- date 日期
- hubei 湖北新增人数
- country 全国的新增人数
- notHubei 湖北以外的新增人数
[{'date': '01.20', 'hubei': 72, 'country': 77, 'notHubei': 5},{'date': '01.21', 'hubei': 105, 'country': 149, 'notHubei': 44},{'date': '01.22', 'hubei': 69, 'country': 131, 'notHubei': 62},{'date': '01.23', 'hubei': 105, 'country': 259, 'notHubei': 154},{'date': '01.24', 'hubei': 180, 'country': 444, 'notHubei': 264},{'date': '01.25', 'hubei': 323, 'country': 688, 'notHubei': 365},{'date': '01.26', 'hubei': 371, 'country': 769, 'notHubei': 398},{'date': '01.27', 'hubei': 1291, 'country': 1771, 'notHubei': 480},{'date': '01.28', 'hubei': 840, 'country': 1459, 'notHubei': 619},{'date': '01.29', 'hubei': 1032, 'country': 1737, 'notHubei': 705},{'date': '01.30', 'hubei': 1220, 'country': 1982, 'notHubei': 762},{'date': '01.31', 'hubei': 1347, 'country': 2102, 'notHubei': 755},{'date': '02.01', 'hubei': 1921, 'country': 2590, 'notHubei': 669},{'date': '02.02', 'hubei': 2103, 'country': 2829, 'notHubei': 726},{'date': '02.03', 'hubei': 2345, 'country': 3235, 'notHubei': 890},{'date': '02.04', 'hubei': 3156, 'country': 3893, 'notHubei': 737},{'date': '02.05', 'hubei': 2987, 'country': 3697, 'notHubei': 710},{'date': '02.06', 'hubei': 2447, 'country': 3143, 'notHubei': 696},{'date': '02.07', 'hubei': 2841, 'country': 3401, 'notHubei': 560},{'date': '02.08', 'hubei': 2147, 'country': 2656, 'notHubei': 509},{'date': '02.09', 'hubei': 2618, 'country': 3062, 'notHubei': 444},{'date': '02.10', 'hubei': 2097, 'country': 2484, 'notHubei': 387},{'date': '02.11', 'hubei': 1638, 'country': 2022, 'notHubei': 384},{'date': '02.12', 'hubei': 14840, 'country': 15153, 'notHubei': 313},{'date': '02.13', 'hubei': 4832, 'country': 5093, 'notHubei': 261},{'date': '02.14', 'hubei': 2420, 'country': 2644, 'notHubei': 224},{'date': '02.15', 'hubei': 1843, 'country': 2009, 'notHubei': 166},{'date': '02.16', 'hubei': 1933, 'country': 2051, 'notHubei': 118},{'date': '02.17', 'hubei': 1807, 'country': 1891, 'notHubei': 84},{'date': '02.18', 'hubei': 1693, 'country': 1751, 'notHubei': 58}]
9.dailyDeadRateHistory
湖北内外每天病死率
- date 日期
- hubeiRate 湖北病死率
- countryRate 全国的病死率
- notHubeiRate 湖北以外的病死率
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OiIsXkqX-1582118488199)(img/1582115446904.png)]](https://img-blog.csdnimg.cn/20200219212504766.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
10.dailyHealRateHistory
湖北内外每天自愈率 和 dailyDeadRateHistory字段一致
- date 日期
- healRate 湖北治愈率
- countryRate 全国的治愈率
- notHubeiRate 湖北以外的治愈率
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GsEzTAaq-1582118488200)(img/1582115457028.png)]](https://img-blog.csdnimg.cn/20200219212513680.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
11.areaTree
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J8EcN881-1582118488200)(img/1582115474464.png)]](https://img-blog.csdnimg.cn/20200219212521657.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
现在有26个国家得病:
len(data_dict.get('areaTree'))
#26
孩子就是省:
data_dict.get('areaTree')[0]['children']
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TI5mcnjy-1582118488201)(img/1582115564797.png)]](https://img-blog.csdnimg.cn/20200219212528675.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
12.articleList
疫情来源的文章信息
[{'cmsId': 'PGZ2020021902567900','source': 'push','media': '贵州省卫生健康委员会','publish_time': '2020-02-19 19:01:48','can_use': 1,'desc': '2月19日0时至12时,贵州无新增新冠肺炎确诊病例,累计146例,死亡2例,现有疑似病例19例。','url': 'https://view.inews.qq.com/a/PGZ2020021902567900','title': '贵州确诊146例:无新增确诊病例'},{'cmsId': 'CSD2020021902212000','source': 'push','media': '健康山东','publish_time': '2020-02-19 15:42:39','can_use': 1,'desc': '2月19日0-12时,山东无新增新冠肺炎确诊病例,累计确诊544例;新增疑似病例2例,现有疑似病例36例。','url': 'https://view.inews.qq.com/a/CSD2020021902212000','title': '好消息!山东无新增确诊病例'},{'cmsId': '20200219A0CB1700','source': 'push','media': '上海发布','publish_time': '2020-02-19 13:26:11','can_use': 1,'desc': '2月19日0-12时,上海无新增新型冠状病毒肺炎确诊病例。','url': 'https://view.inews.qq.com/a/20200219A0CB1700','title': '上海今日0-12时无新增确诊病例'},{'cmsId': 'CYN2020021901739300','source': 'push','media': '云南发布','publish_time': '2020-02-19 12:42:18','can_use': 1,'desc': '快讯!19日0时至12时,云南累计确诊新冠肺炎173例,无新增确诊病例,死亡1例。','url': 'https://view.inews.qq.com/a/CYN2020021901739300','title': '云南确诊173例:新增0例、死亡1例'},{'cmsId': '20200219A08GMK00','source': 'push','media': '上海发布','publish_time': '2020-02-19 11:16:09','can_use': 1,'desc': '上海今天又有9例确诊病例痊愈出院,另有1例死亡,目前共有186例出院。','url': 'https://view.inews.qq.com/a/20200219A08GMK00','title': '上海今天9例确诊病例痊愈出院 1例死亡'},{'cmsId': 'KCV2020021901265000','source': 'push','media': '西藏自治区卫生健康委员会','publish_time': '2020-02-19 09:55:39','can_use': 1,'desc': '截至2月18日24时,西藏现有新冠肺炎确诊病例0例,连续20天无新增确诊或疑似病例。','url': 'https://view.inews.qq.com/a/KCV2020021901265000','title': '西藏连续20天无新增确诊或疑似病例'},{'cmsId': 'CEI2020021901123300','source': 'push','media': '北方新报','publish_time': '2020-02-19 09:18:00','can_use': 1,'desc': '2月18日9时至19日8时,内蒙新增新冠肺炎确诊病例2例,累计75例,新增疑似病例3例,累计17例。','url': 'https://view.inews.qq.com/a/CEI2020021901123300','title': '累计75例!内蒙新增确诊病例2例'},{'cmsId': 'LNC2020021901119800','source': 'push','media': '辽宁卫健委','publish_time': '2020-02-19 09:16:12','can_use': 1,'desc': '2月18日0时至24时,辽宁省无新增新型冠状病毒肺炎确诊病例,新增12例治愈出院病例。','url': 'https://view.inews.qq.com/a/LNC2020021901119800','title': '辽宁新增12例治愈出院病例'},{'cmsId': 'CYN2020021901139900','source': 'push','media': '云南网','publish_time': '2020-02-19 09:15:06','can_use': 1,'desc': '刚刚!云南累计确诊病例173例:新增28岁男性染病患者,其中危重1例,重症11例,仍有正在观察2212人。','url': 'https://view.inews.qq.com/a/CYN2020021901139900','title': '云南新增1例染病患者:累计173例'},{'cmsId': 'PGZ2020021901116800','source': 'push','media': '健康贵州','publish_time': '2020-02-19 09:14:54','can_use': 1,'desc': '2月18日12时至24时,贵州无新增新冠肺炎确诊病例,累计146例 ,新增治愈出院病例3例。','url': 'https://view.inews.qq.com/a/PGZ2020021901116800','title': '贵州确诊146例:新增0例感染者'}]
五、处理省份的数据
5.1 使用for循环到省份
for province in data_dict.get('areaTree')[0]['children']:print(province['name'])湖北
广东
河南
浙江
湖南
安徽
江西
江苏
重庆
山东
四川
黑龙江
北京
上海
河北
福建
广西
陕西
云南
海南
贵州
山西
天津
辽宁
甘肃
吉林
新疆
内蒙古
宁夏
香港
台湾
青海
澳门
西藏
5.2 每个省当天的数据
for province in data_dict.get('areaTree')[0]['children']:print(province['today']){'confirm': 1693, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 3, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 5, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 1, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 1, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 4, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 1, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 2, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 2, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 1, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 6, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 6, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 6, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 0, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 4, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 1, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 2, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 2, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 1, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 0, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 0, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 1, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 3, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 0, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 0, 'confirmCuts': 0, 'isUpdated': False}
{'confirm': 1, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 0, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 2, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 1, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 1, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 1, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 0, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 0, 'confirmCuts': 0, 'isUpdated': True}
{'confirm': 0, 'confirmCuts': 0, 'isUpdated': True}
today是今日新增没有什么用
5.3 每个省总的数据情况
for province in data_dict.get('areaTree')[0]['children']:print(province['total']){'confirm': 61682, 'suspect': 0, 'dead': 1921, 'deadRate': '3.11', 'showRate': False, 'heal': 9128, 'healRate': '14.80', 'showHeal': True, 'name': '湖北'}
{'confirm': 1331, 'suspect': 0, 'dead': 5, 'deadRate': '0.38', 'showRate': False, 'heal': 571, 'healRate': '42.90', 'showHeal': True, 'name': '广东'}
{'confirm': 1262, 'suspect': 0, 'dead': 19, 'deadRate': '1.51', 'showRate': False, 'heal': 552, 'healRate': '43.74', 'showHeal': True, 'name': '河南'}
{'confirm': 1173, 'suspect': 0, 'dead': 0, 'deadRate': '0.00', 'showRate': False, 'heal': 544, 'healRate': '46.38', 'showHeal': True, 'name': '浙江'}
{'confirm': 1008, 'suspect': 0, 'dead': 4, 'deadRate': '0.40', 'showRate': False, 'heal': 542, 'healRate': '53.77', 'showHeal': True, 'name': '湖南'}
{'confirm': 986, 'suspect': 0, 'dead': 6, 'deadRate': '0.61', 'showRate': False, 'heal': 424, 'healRate': '43.00', 'showHeal': True, 'name': '安徽'}
{'confirm': 934, 'suspect': 0, 'dead': 1, 'deadRate': '0.11', 'showRate': False, 'heal': 362, 'healRate': '38.76', 'showHeal': True, 'name': '江西'}
{'confirm': 631, 'suspect': 0, 'dead': 0, 'deadRate': '0.00', 'showRate': False, 'heal': 296, 'healRate': '46.91', 'showHeal': True, 'name': '江苏'}
{'confirm': 555, 'suspect': 0, 'dead': 5, 'deadRate': '0.90', 'showRate': False, 'heal': 254, 'healRate': '45.77', 'showHeal': True, 'name': '重庆'}
{'confirm': 544, 'suspect': 0, 'dead': 3, 'deadRate': '0.55', 'showRate': False, 'heal': 225, 'healRate': '41.36', 'showHeal': True, 'name': '山东'}
{'confirm': 514, 'suspect': 0, 'dead': 3, 'deadRate': '0.58', 'showRate': False, 'heal': 177, 'healRate': '34.44', 'showHeal': True, 'name': '四川'}
{'confirm': 470, 'suspect': 0, 'dead': 12, 'deadRate': '2.55', 'showRate': False, 'heal': 108, 'healRate': '22.98', 'showHeal': True, 'name': '黑龙江'}
{'confirm': 393, 'suspect': 0, 'dead': 4, 'deadRate': '1.02', 'showRate': False, 'heal': 145, 'healRate': '36.90', 'showHeal': True, 'name': '北京'}
{'confirm': 333, 'suspect': 0, 'dead': 2, 'deadRate': '0.60', 'showRate': False, 'heal': 186, 'healRate': '55.86', 'showHeal': True, 'name': '上海'}
{'confirm': 306, 'suspect': 0, 'dead': 4, 'deadRate': '1.31', 'showRate': False, 'heal': 136, 'healRate': '44.44', 'showHeal': True, 'name': '河北'}
{'confirm': 293, 'suspect': 0, 'dead': 0, 'deadRate': '0.00', 'showRate': False, 'heal': 96, 'healRate': '32.76', 'showHeal': True, 'name': '福建'}
{'confirm': 244, 'suspect': 0, 'dead': 2, 'deadRate': '0.82', 'showRate': False, 'heal': 76, 'healRate': '31.15', 'showHeal': True, 'name': '广西'}
{'confirm': 242, 'suspect': 0, 'dead': 0, 'deadRate': '0.00', 'showRate': False, 'heal': 89, 'healRate': '36.78', 'showHeal': True, 'name': '陕西'}
{'confirm': 173, 'suspect': 0, 'dead': 1, 'deadRate': '0.58', 'showRate': False, 'heal': 60, 'healRate': '34.68', 'showHeal': True, 'name': '云南'}
{'confirm': 163, 'suspect': 0, 'dead': 4, 'deadRate': '2.45', 'showRate': False, 'heal': 79, 'healRate': '48.47', 'showHeal': True, 'name': '海南'}
{'confirm': 146, 'suspect': 0, 'dead': 2, 'deadRate': '1.37', 'showRate': False, 'heal': 69, 'healRate': '47.26', 'showHeal': True, 'name': '贵州'}
{'confirm': 131, 'suspect': 0, 'dead': 0, 'deadRate': '0.00', 'showRate': False, 'heal': 61, 'healRate': '46.56', 'showHeal': True, 'name': '山西'}
{'confirm': 128, 'suspect': 0, 'dead': 3, 'deadRate': '2.34', 'showRate': False, 'heal': 64, 'healRate': '50.00', 'showHeal': True, 'name': '天津'}
{'confirm': 121, 'suspect': 0, 'dead': 1, 'deadRate': '0.83', 'showRate': False, 'heal': 55, 'healRate': '45.45', 'showHeal': True, 'name': '辽宁'}
{'confirm': 91, 'suspect': 0, 'dead': 2, 'deadRate': '2.20', 'showRate': False, 'heal': 62, 'healRate': '68.13', 'showHeal': True, 'name': '甘肃'}
{'confirm': 90, 'suspect': 0, 'dead': 1, 'deadRate': '1.11', 'showRate': False, 'heal': 36, 'healRate': '40.00', 'showHeal': True, 'name': '吉林'}
{'confirm': 76, 'suspect': 0, 'dead': 1, 'deadRate': '1.32', 'showRate': False, 'heal': 14, 'healRate': '18.42', 'showHeal': True, 'name': '新疆'}
{'confirm': 75, 'suspect': 0, 'dead': 0, 'deadRate': '0.00', 'showRate': False, 'heal': 9, 'healRate': '12.00', 'showHeal': True, 'name': '内蒙古'}
{'confirm': 71, 'suspect': 0, 'dead': 0, 'deadRate': '0.00', 'showRate': False, 'heal': 42, 'healRate': '59.15', 'showHeal': True, 'name': '宁夏'}
{'confirm': 63, 'suspect': 0, 'dead': 2, 'deadRate': '3.17', 'showRate': False, 'heal': 4, 'healRate': '6.35', 'showHeal': True, 'name': '香港'}
{'confirm': 23, 'suspect': 0, 'dead': 1, 'deadRate': '4.35', 'showRate': False, 'heal': 2, 'healRate': '8.70', 'showHeal': True, 'name': '台湾'}
{'confirm': 18, 'suspect': 0, 'dead': 0, 'deadRate': '0.00', 'showRate': False, 'heal': 15, 'healRate': '83.33', 'showHeal': True, 'name': '青海'}
{'confirm': 10, 'suspect': 0, 'dead': 0, 'deadRate': '0.00', 'showRate': False, 'heal': 5, 'healRate': '50.00', 'showHeal': True, 'name': '澳门'}
{'confirm': 1, 'suspect': 0, 'dead': 0, 'deadRate': '0.00', 'showRate': False, 'heal': 1, 'healRate': '100.00', 'showHeal': True, 'name': '西藏'}
数据说明:这些数据目前是字典
对于pandas数据分析
我们要把这些数据变成dataframe
然后可以导入到excel或者SQL中
5.4 将数据变成列表再变成dataframe
province_list = list()
for province in data_dict.get('areaTree')[0]['children']:province_info = province['total']province_info['name'] = province['name']province_list.append(province_info)
province_df = pd.DataFrame(province_list)
#按照数据类型删除列
#include=包含什么类型, exclude=不包含什么类型
province_df = province_df.select_dtypes(exclude=['bool'])
5.5 查看dataframe数据
province_df
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vHgpkqJ7-1582118488202)(img/1582116287075.png)]](https://img-blog.csdnimg.cn/20200219212548996.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
5.6 安装pyecharts和echarts-china-provinces-pypkg
pip install pyecharts -i https://pypi.douban.com/simplepip install echarts-china-provinces-pypkg -i https://pypi.douban.com/simple
5.7 删除没有用的两列
5.7.1 按照数据类型来删除datafram的列【重要】
1.先查看一下类型
province_list = list()
for province in data_dict.get('areaTree')[0]['children']:province_info = province['total']province_info['name'] = province['name']province_list.append(province_info)
province_df = pd.DataFrame(province_list)
#按照数据类型删除列
#include=包含什么类型, exclude=不包含什么类型
province_df = province_df.select_dtypes(exclude=['bool'])
province_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 34 entries, 0 to 33
Data columns (total 7 columns):
confirm 34 non-null int64
dead 34 non-null int64
deadRate 34 non-null object
heal 34 non-null int64
healRate 34 non-null object
name 34 non-null object
suspect 34 non-null int64
dtypes: int64(4), object(3)
memory usage: 1.9+ KB
2.目的
把两组布尔值的删掉
3.方法
#按照数据类型删除列
#include=包含什么类型, exclude=不包含什么类型
province_df = province_df.select_dtypes(exclude=['bool'])
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Uz3wFKj5-1582118488202)(img/1582116912530.png)]](https://img-blog.csdnimg.cn/20200219212600764.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
4.参数的意思
include是包含什么类型
exclude是不包含什么类型
是两个选项
两个都不包含也可以写在一起
5.我们的处理
不包含布尔值
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DIws0Spk-1582118488203)(img/1582116924810.png)]](https://img-blog.csdnimg.cn/20200219212610295.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
5.8 对原数据进行覆盖
province_df = province_df.select_dtypes(exclude=['bool'])#对原数据进行覆盖
5.9 查看现在的数据
province_df
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uCI0XFF8-1582118488203)(img/1582116975295.png)]](https://img-blog.csdnimg.cn/20200219212619165.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
六、定义地图,填充数据
6.1 pyecharts中的地图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MqOqMsST-1582118488204)(img/1582080059312.png)]](https://img-blog.csdnimg.cn/20200219212629302.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
6.2 安装导入pyecharts
pip install pyecharts -i https://pypi.douban.com/simplepip install echarts-china-provinces-pypkg -i https://pypi.douban.com/simple
6.3 对当前的库pyecharts进行使用和讲解
6.3.1 他的地图map不支持一种格式
不认识series
我们刚才的pandas就是一列一列的series
6.3.2 解决办法
可以用tolist把省份的名称和累计确诊的数据转换成list
province_name = province_df.name.tolist()province_confirm = province_df.confirm.tolist()
6.3.3 导入pyecharts的Map和options(配色,标题要用到)
from pyecharts.charts import Mapfrom pyecharts import options as opts #配色 标题
6.3.4 Map.add的参数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9uytJEhh-1582118488204)(img/1582117107063.png)]](https://img-blog.csdnimg.cn/20200219212639949.png)
压缩
因为索引是一样的,所以可以进行压缩,然后用for循环
china_map = Map()
#定义地图,填充数据
china_map.add('全国疫情分布',[tup for tup in zip(province_name,province_confirm)],'china')这是一个列表生成器
尝试看一下
for tup in zip(province_name, province_confirm):print(tup)('湖北', 61682)
('广东', 1331)
('河南', 1262)
('浙江', 1173)
('湖南', 1008)
('安徽', 986)
('江西', 934)
('江苏', 631)
('重庆', 555)
('山东', 544)
('四川', 514)
('黑龙江', 470)
('北京', 393)
('上海', 333)
('河北', 306)
('福建', 293)
('广西', 244)
('陕西', 242)
('云南', 173)
('海南', 163)
('贵州', 146)
('山西', 131)
('天津', 128)
('辽宁', 121)
('甘肃', 91)
('吉林', 90)
('新疆', 76)
('内蒙古', 75)
('宁夏', 71)
('香港', 63)
('台湾', 23)
('青海', 18)
('澳门', 10)
('西藏', 1)
6.3.5 下一个参数写chaina,其他的国家也可以
china_map = Map()
#定义地图,填充数据
china_map.add('全国疫情分布',[tup for tup in zip(province_name,province_confirm)],'china')
6.3.6 运行,查看地图
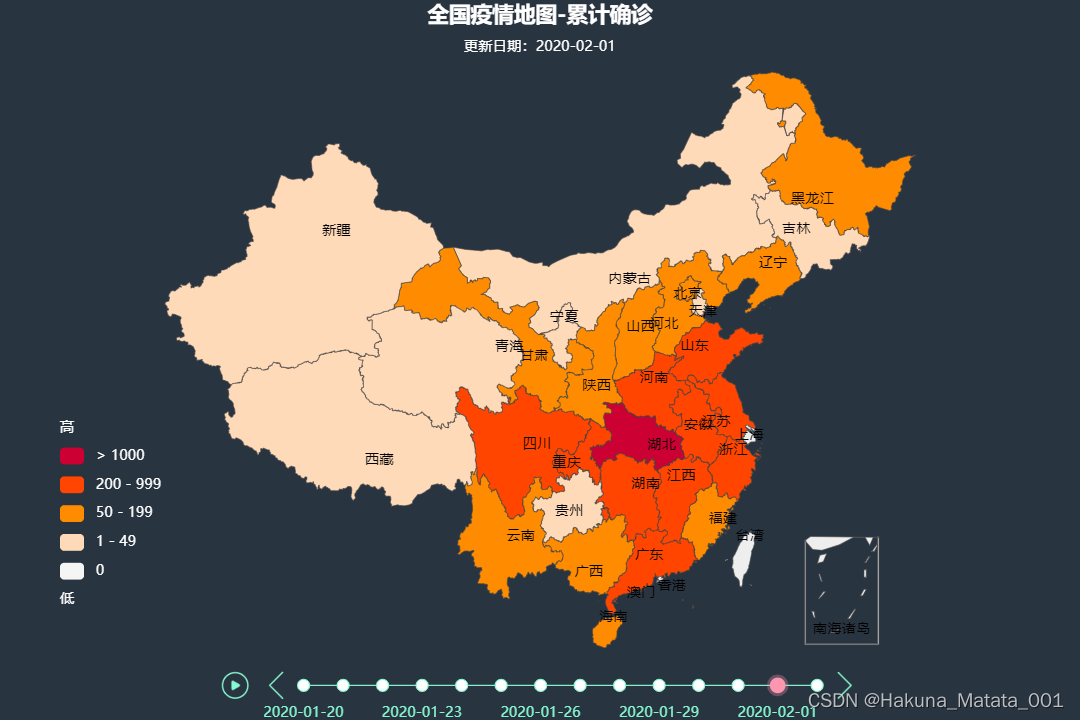
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vISwKVHo-1582118488205)(img/1582117224116.png)]](https://img-blog.csdnimg.cn/20200219212653280.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
七、填充地图颜色部分的说明
人数不同,颜色不同的配色
7.1 颜色配置放在这里
#填充
china_map.set_global_opts(title_opts=opts.TitleOpts(title='中国加油!武汉加油!'),\visualmap_opts=opts.VisualMapOpts(is_piecewise=True,pieces=pieces))
7.1.1 颜色配置必须是list包裹dict
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4rUoCk5i-1582118488205)(img/1582117295502.png)]](https://img-blog.csdnimg.cn/20200219212701967.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
7.1.2 1-9人之类的范围我们改一下颜色
#颜色配置 必须是一个list包裹dict
pieces = [{'min':1,'max':9,'color':'#FFE0E0'},{'min':10,'max':99,'color':'#FFC0C0'},{'min':100,'max':499,'color':'#FF9090'},{'min':500,'max':999,'color':'#FF6060'},{'min':1000,'max':9999,'color':'#FF3030'},{'min':10000,'color':'#DD0000'},]china_map = Map()
#定义地图,填充数据
china_map.add('全国疫情分布',[tup for tup in zip(province_name,province_confirm)],'china')
#填充
china_map.set_global_opts(title_opts=opts.TitleOpts(title='中国加油!武汉加油!'),\visualmap_opts=opts.VisualMapOpts(is_piecewise=True,pieces=pieces))
#打印地图
china_map.render_notebook()
八、打印地图
#打印地图
china_map.render_notebook()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RIPhFIyM-1582118488206)(img/1582117361741.png)]](https://img-blog.csdnimg.cn/20200219212711125.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
九、数据存储
9.1 看一下各个值
import requests
import json
import pandas as pd
from sqlalchemy import create_enginedef getData():url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5'headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}r = requests.get(url,headers)if r.status_code == 200:return json.loads(json.loads(r.text)['data'])
data_dict = getData()
data_dict.keys()
dict_keys(['lastUpdateTime', 'chinaTotal', 'chinaAdd', 'isShowAdd', 'showAddSwitch', 'chinaDayList', 'chinaDayAddList', 'dailyNewAddHistory', 'dailyDeadRateHistory', 'dailyHealRateHistory', 'areaTree', 'articleList'])
9.2 保存到mysql
9.3 链接数据库
#配置数据库链接字符串
conn = "mysql+pymysql://root:123456@127.0.0.1:3306/info?charset=utf8"
9.4 保存每天 的数据,行变列
#保存每天的总数据
total = data_dict['chinaTotal']
total['date'] = data_dict['lastUpdateTime'].split()[0]
total_df = pd.DataFrame(pd.Series(total)).T
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FsuOt6xe-1582118488207)(img/1582117816310.png)]](https://img-blog.csdnimg.cn/2020021921272123.png)
9.5 数赋值给dataframe
#保存每天的总数据
total = data_dict['chinaTotal']
total['date'] = data_dict['lastUpdateTime'].split()[0]
total_df = pd.DataFrame(pd.Series(total)).T
9.6 数据类型的转换
改类型,现在都是字符串
int32更小节省空间、
-1是不要改最后一列
#数据类型转换
for i in total_df.iloc[:,:-1].columns:total_df.loc[:,i] = total_df.loc[:,i].astype('int32')
total_df.loc[:,'date'] = pd.to_datetime(total_df.loc[:,'date'])
total_df.iloc[:,:-1].astype('int32').info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1 entries, 0 to 0
Data columns (total 6 columns):
confirm 1 non-null int32
heal 1 non-null int32
dead 1 non-null int32
nowConfirm 1 non-null int32
suspect 1 non-null int32
nowSevere 1 non-null int32
dtypes: int32(6)
memory usage: 104.0 bytes改好了:
#数据类型转换
for i in total_df.iloc[:,:-1].columns:total_df.loc[:,i] = total_df.loc[:,i].astype('int32')
total_df.loc[:,'date'] = pd.to_datetime(total_df.loc[:,'date'])
total_df.info(0)<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1 entries, 0 to 0
Data columns (total 7 columns):
confirm 1 non-null int32
heal 1 non-null int32
dead 1 non-null int32
nowConfirm 1 non-null int32
suspect 1 non-null int32
nowSevere 1 non-null int32
date 1 non-null datetime64[ns]
dtypes: datetime64[ns](1), int32(6)
memory usage: 112.0 bytes
最后一列是data
特别处理了
9.7 sql语句
#sql语句
total_df.to_sql('china_total',conn,index=False,if_exists='append')
9.8 数据传进来了
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L3OgMO09-1582118488208)(img/1582082596143.png)]](https://img-blog.csdnimg.cn/2020021921273448.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
9.9 保存数据
9.9.1 国家数据
country_list = list()
for country in data_dict['areaTree']:
# print(data_dict['lastUpdateTime'],country['name'],country['today'],country['total'])country_dict = country['total']country_dict['add_confirm'] = country['today']['confirm']country_dict['name'] = country['name']country_dict['date'] = data_dict['lastUpdateTime']country_list.append(country_dict)
country_df = pd.DataFrame(country_list)
#删除bool值
country_df= country_df.select_dtypes(exclude=['bool'])
#把比例修改成浮点型
country_df.loc[:,['deadRate','healRate']] = country_df.loc[:,['deadRate','healRate']].astype('float32')
#把时间修改成时间序列类型
country_df.date = pd.to_datetime(country_df.date)
country_df.to_csv('country_df.csv')
9.9.2 中国各个省份数据
city_list = list()
for pro in data_dict['areaTree'][0]['children']:for city in pro['children']:city_dict = city['total']city_dict['add_confirm'] = city['today']['confirm']city_dict['city_name'] = city['name']city_dict['province_name'] = pro['name']city_dict['date'] = data_dict['lastUpdateTime']city_list.append(city_dict)
city_df = pd.DataFrame(city_list)
#删除bool值
city_df= city_df.select_dtypes(exclude=['bool'])
#把比例修改成浮点型
city_df.loc[:,['deadRate','healRate']] = city_df.loc[:,['deadRate','healRate']].astype('float32')
#把时间修改成时间序列类型
city_df.date = pd.to_datetime(city_df.date)
city_df.to_excel('city_df.xlsx',sheet_name='city',index =False)
ok
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WlE9YHMm-1582118488208)(img/1582118093595.png)]](https://img-blog.csdnimg.cn/20200219212742586.png)


![[Pyhon疫情大数据分析] 四.微博话题抓取及新冠肺炎疫情文本挖掘和情感分析](https://img-blog.csdnimg.cn/20200321143724497.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0Vhc3Rtb3VudA==,size_16,color_FFFFFF,t_70#pic_center)