目录
一、SQL Server
1.1、简介
1.2、安装包
二、安装SQL Server
2.1、双击安装包
2.2、选择自己想要安装的位置
2.3、点击安装
2.4、安装完成之后会出现以下页面,按照序号依次点击
2.5、不用管密钥,点击下一步
2.6、选择【我接受】
2.7、是否检查更新
2.8、由于我没有Azure的ID什么的,就跳过了直接下一步
2.9、功能选择
2.10、实例配置
2.11、服务账户配置
2.12、数据库引擎配置
2.13、点击安装
2.14、安装完成
三、安装SSMS
3.1、双击安装包,修改安装位置
3.2、等待安装完成
3.3、安装完成
3.4、打开SSMS
3.5、登录
四、使用
4.1、数据库的操作
4.2、表的操作
一、SQL Server
1.1、简介
SQL Server数据库是Microsoft开发设计的一个关系数据库智能管理系统(RDBMS),现在是全世界主流数据库之一;
SQL Server数据库具备方便使用、可伸缩性好、相关软件集成程度高等优势,能够从单一的笔记本上运行或以高倍云服务器集群为基础,或在这两者之间任何东西上运行。尽管说成“任何东西”,可是依然要考虑有关的软件和硬件配置;
1.2、安装包
百度网盘自取
通过网盘分享的文件:SQL Server
链接: https://pan.baidu.com/s/1PmS8Buf9ze96wuDCeL9VmQpwd=1234 提取码: 1234
二、安装SQL Server
2.1、双击安装包
会出现下面的页面,有三种安装类型,我们当然是选择自定义安装了

2.2、选择自己想要安装的位置
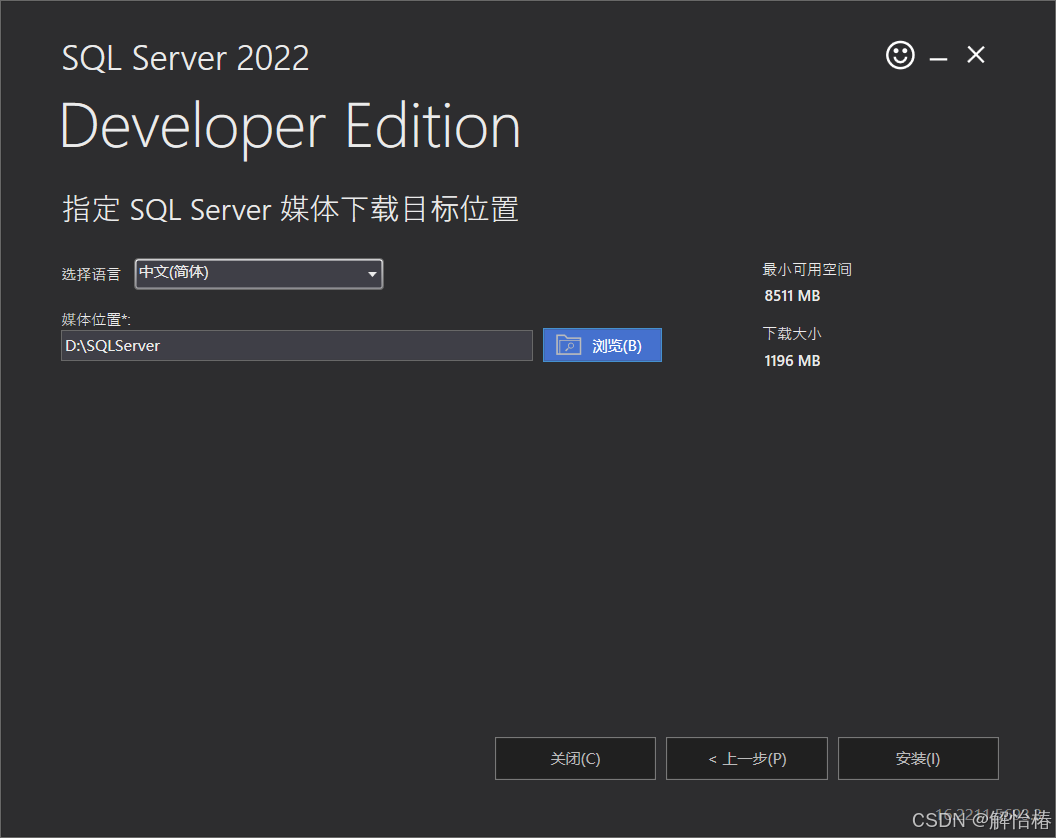
2.3、点击安装
随后就开始了,就是可能有点慢
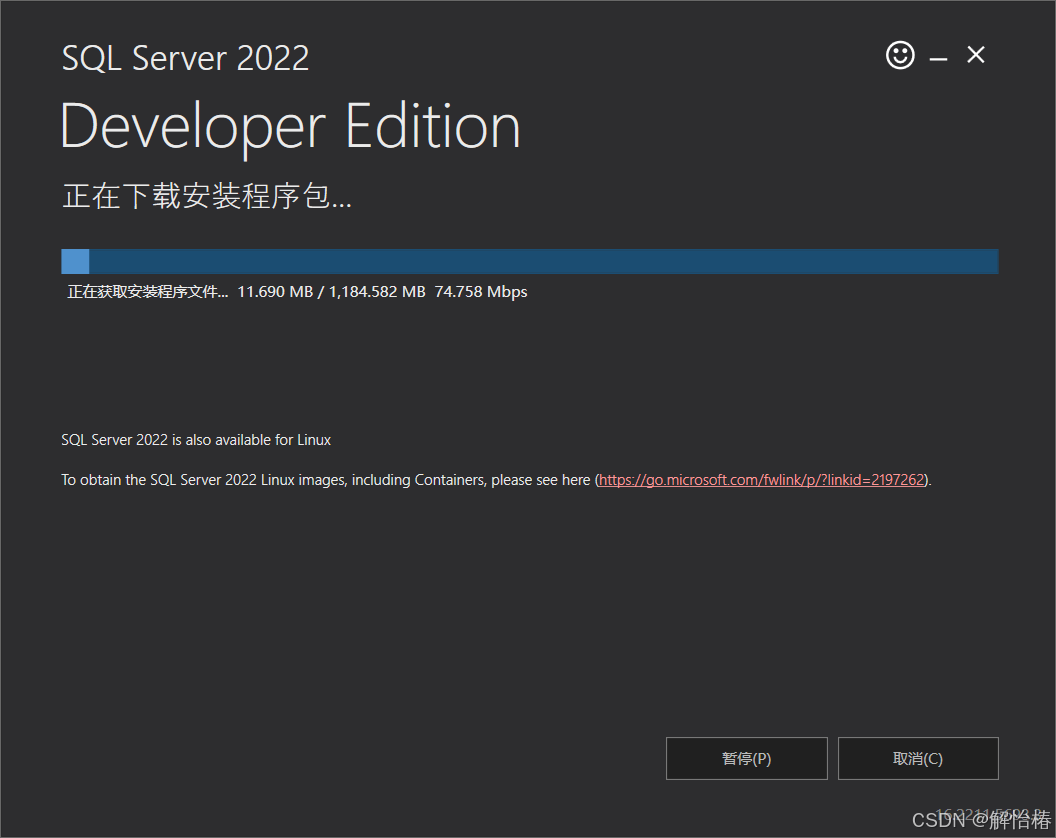
2.4、安装完成之后会出现以下页面,按照序号依次点击
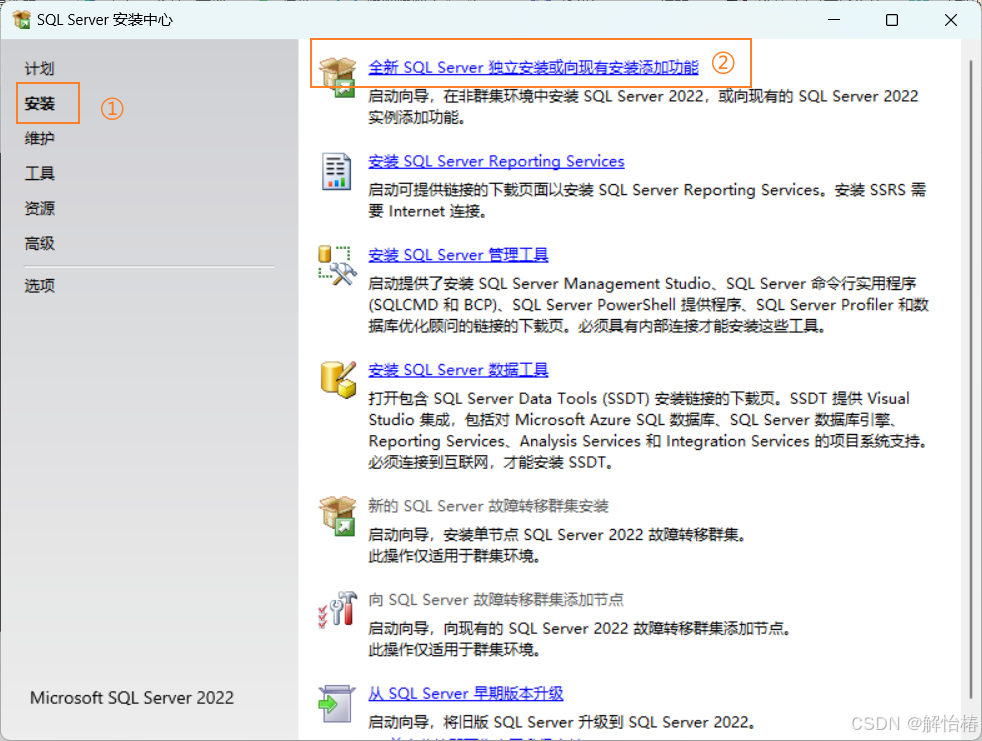
2.5、不用管密钥,点击下一步
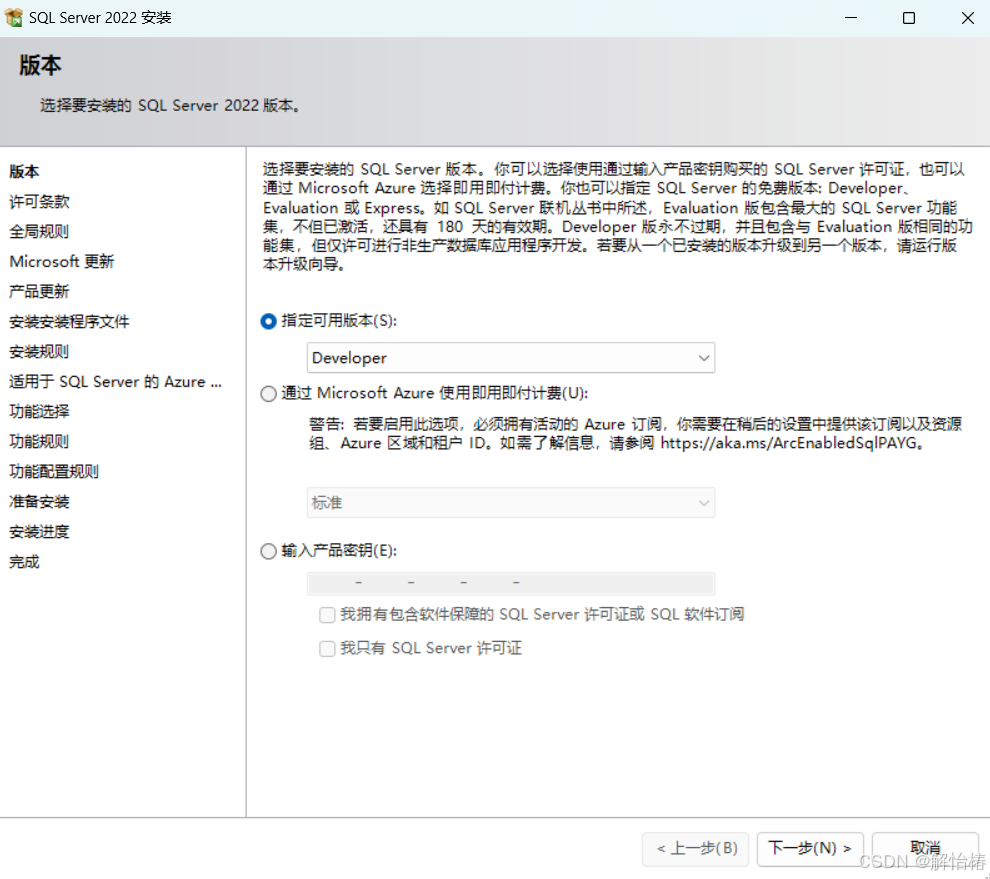
2.6、选择【我接受】
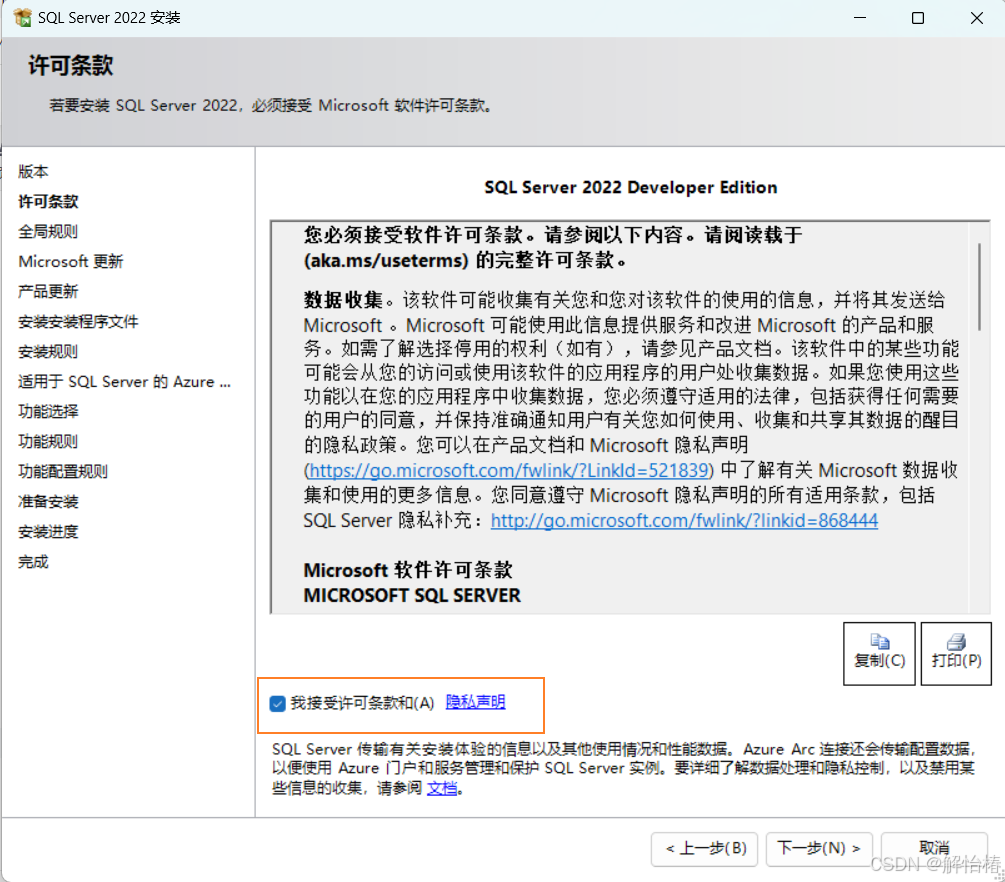
2.7、是否检查更新
会出现以下页面,可以自己选择是否使用检查更新,我选择不使用
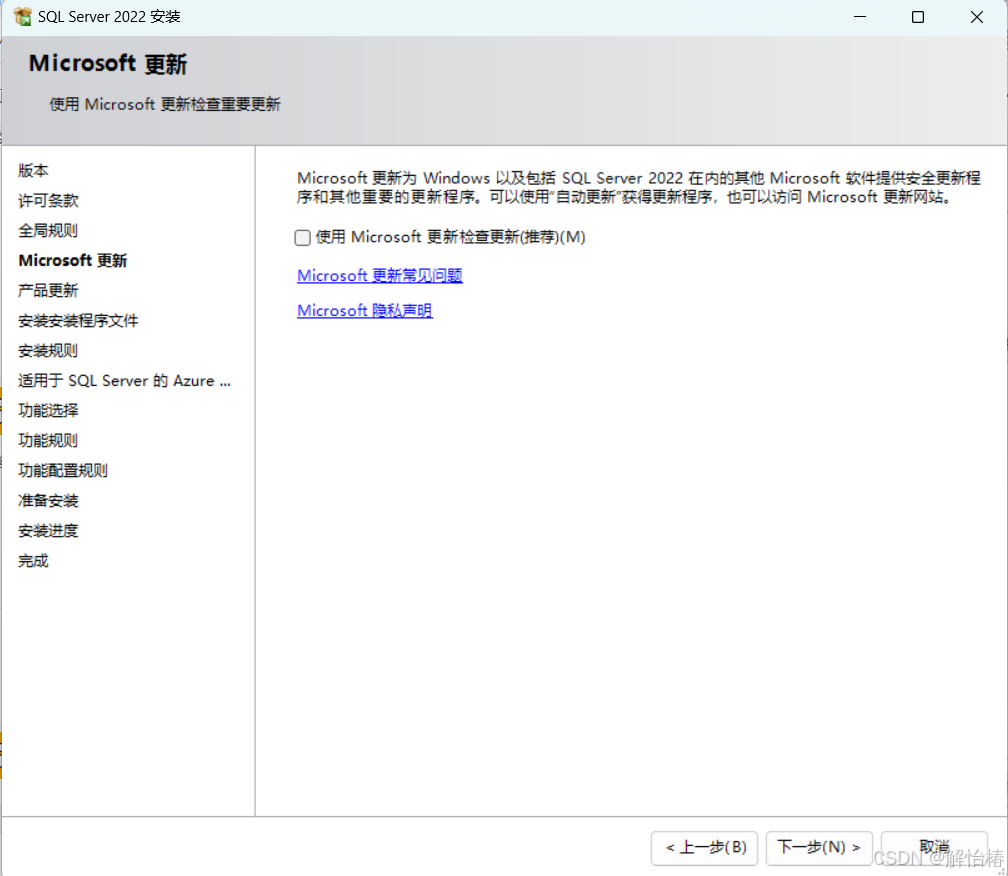
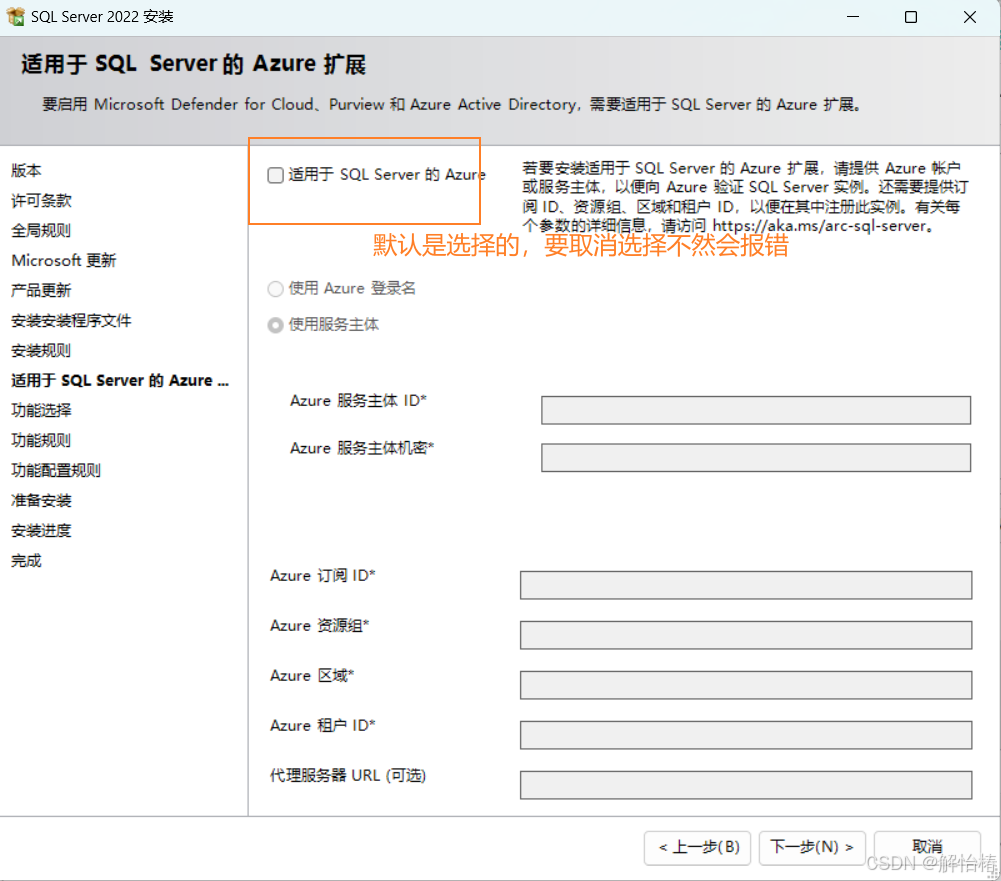
2.8、由于我没有Azure的ID什么的,就跳过了直接下一步
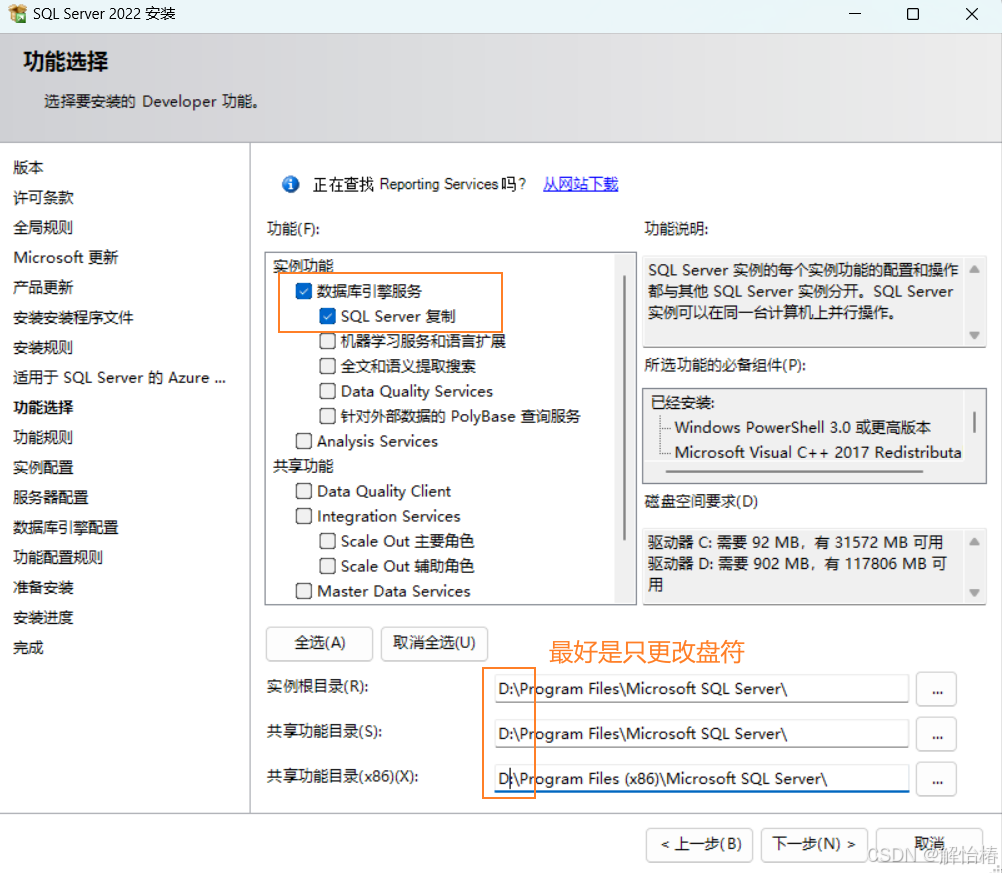
2.9、功能选择
建议选择这两个基本功能,更改实例根目录
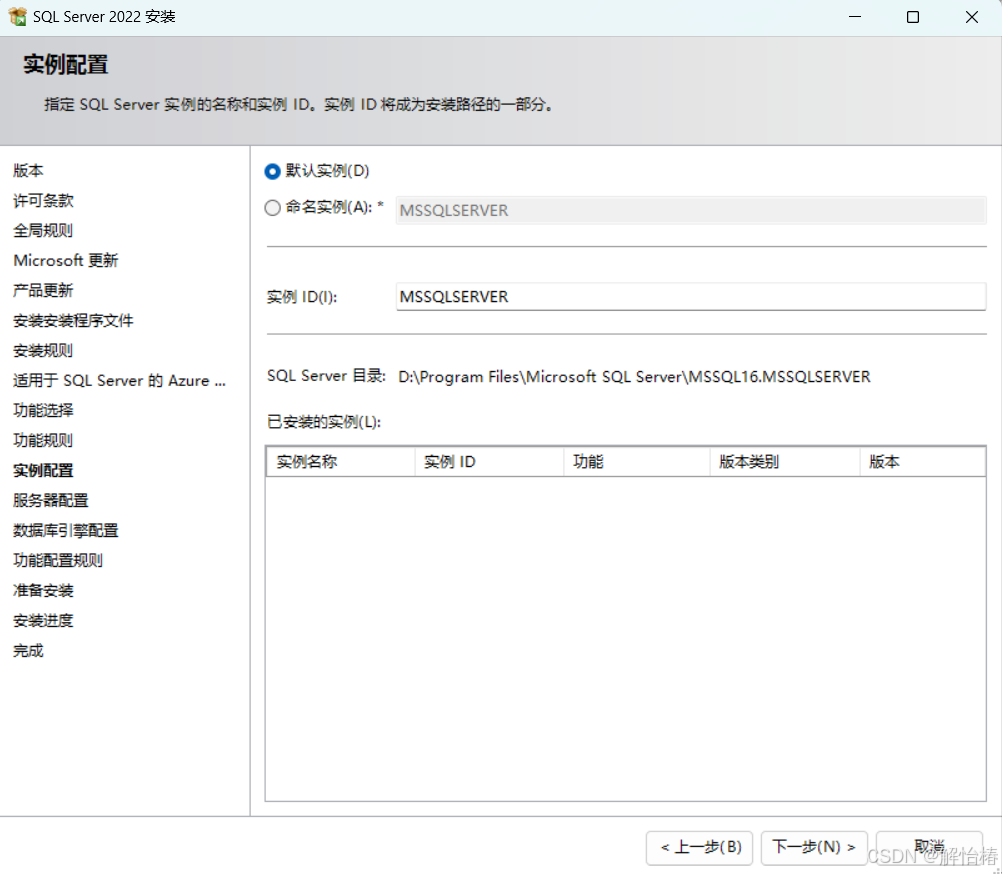
2.10、实例配置
一般选择默认实例
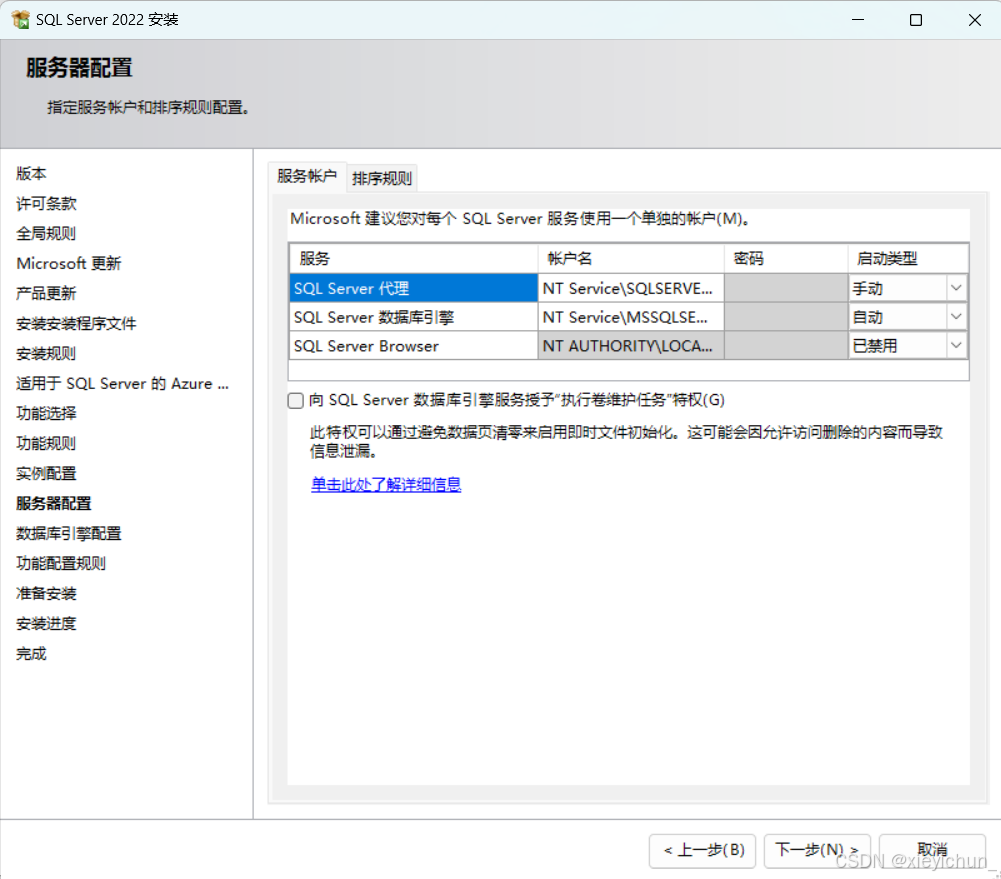
2.11、服务账户配置
这里可以选择SQL Server代理和引擎的账户,一般保持默认并且安装好后还可以修改
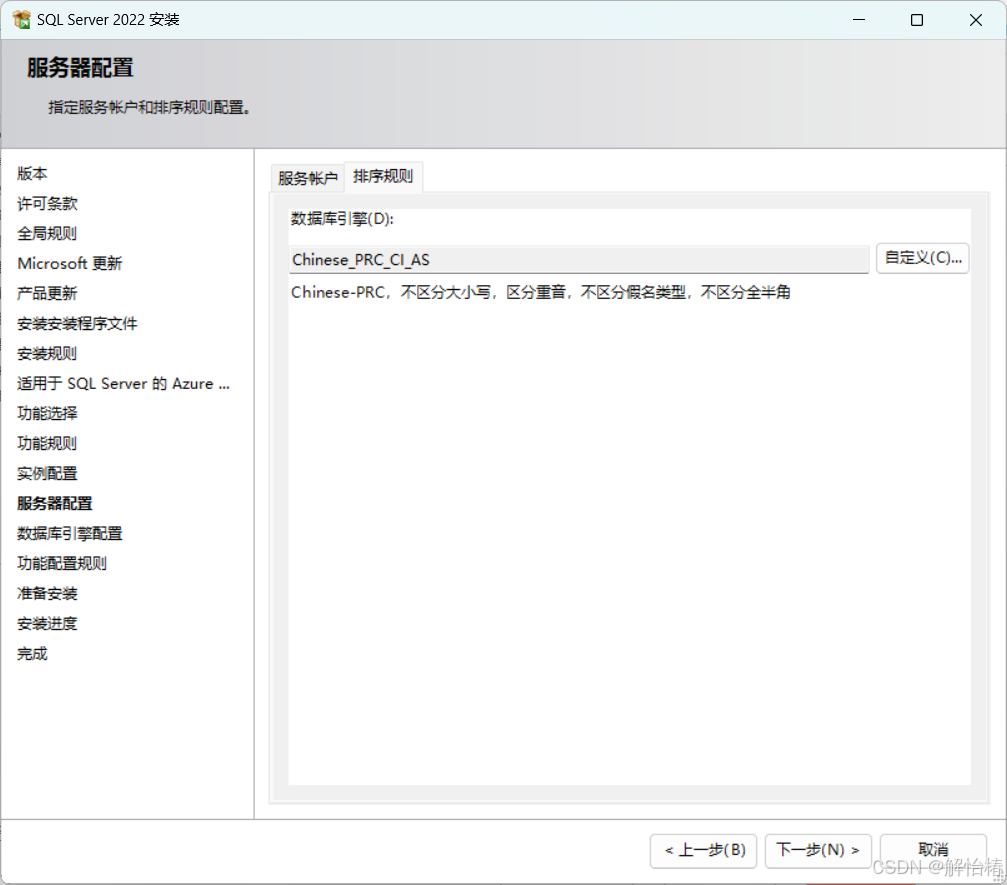
排序规则保持默认即可,如需要修改点击自定义,选择指定排序规则(注意:数据库迁移和高可用搭建需保持排序规则一致,排序规则在安装后不易修改),点击下一步
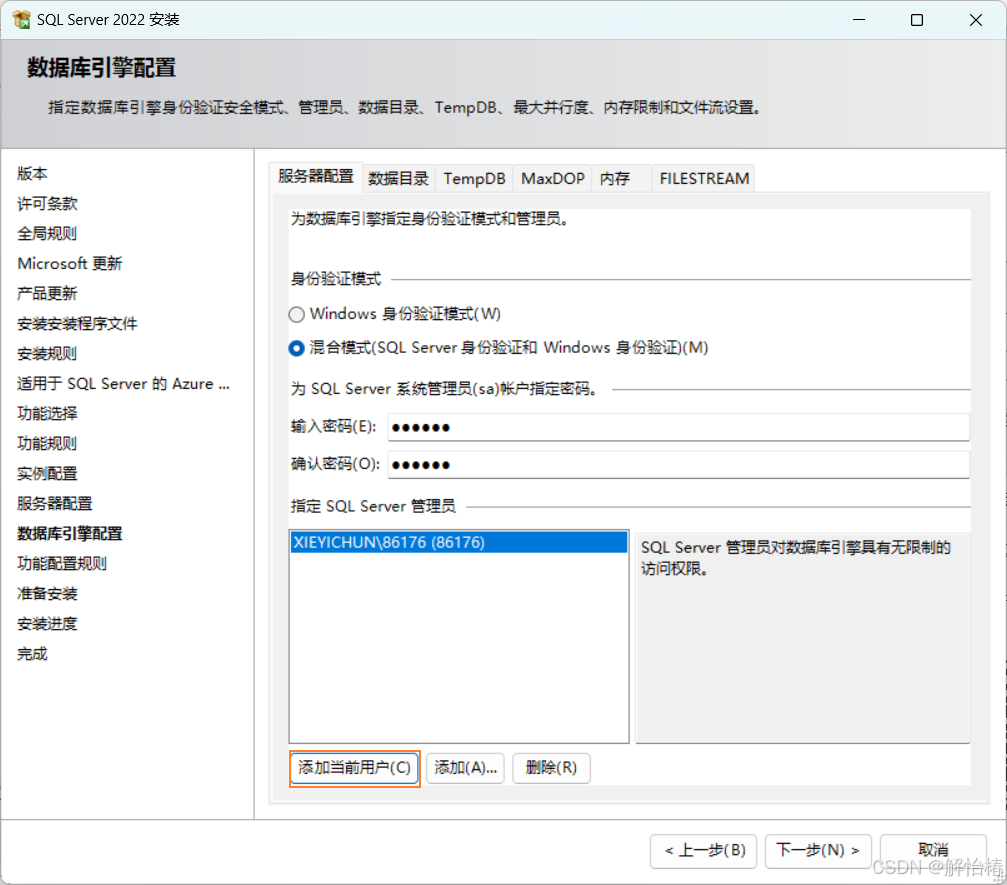
2.12、数据库引擎配置
服务器配置,选择混合模式,设置sa密码(sa是sql server的超级管理员),点击添加当前用户
数据目录,这里可以更改用户数据库文件的默认位置,可以保持默认,建议单独建立目录进行分配
注意:数据库根目录不要修改!!!
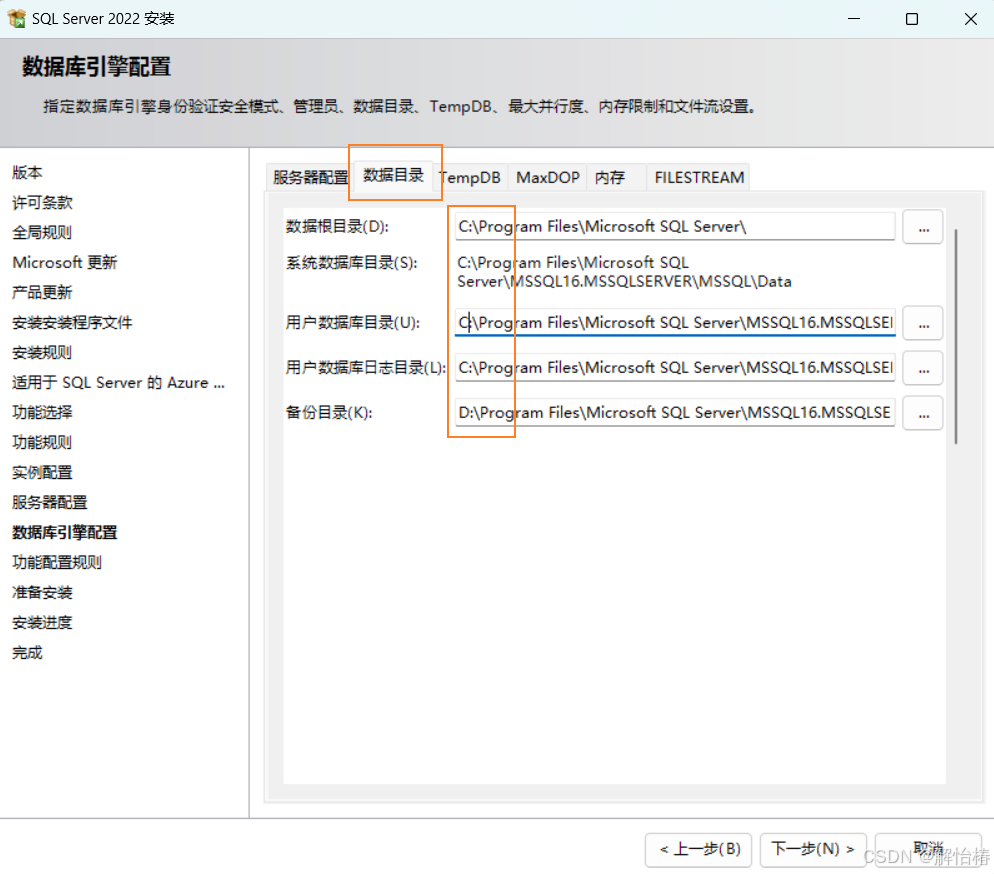
TempDB(系统临时数据库,重启数据库自动更新),可以设置TempDB数据文件初始数量(建议4-8个,不要超过8个)和TempDB数据文件目录,建议单独分配磁盘和目录,可以保持默认,点击下一步
2.13、点击安装
2.14、安装完成
三、安装SSMS
SQL Server Management Studio (SSMS) 是一种集成环境,用于管理从 SQL Server 到 Azure SQL 数据库的任何 SQL 基础结构。 SSMS 提供用于配置、监视和管理 SQL Server 和数据库实例的工具。 使用 SSMS 部署、监视和升级应用程序使用的数据层组件,以及生成查询和脚本。
下载SSMS
3.1、双击安装包,修改安装位置
3.2、等待安装完成
3.3、安装完成
3.4、打开SSMS
点击开始按钮,找到刚才安装的SQL Server Management Studio Management Studio 20软件,双击打开


3.5、登录
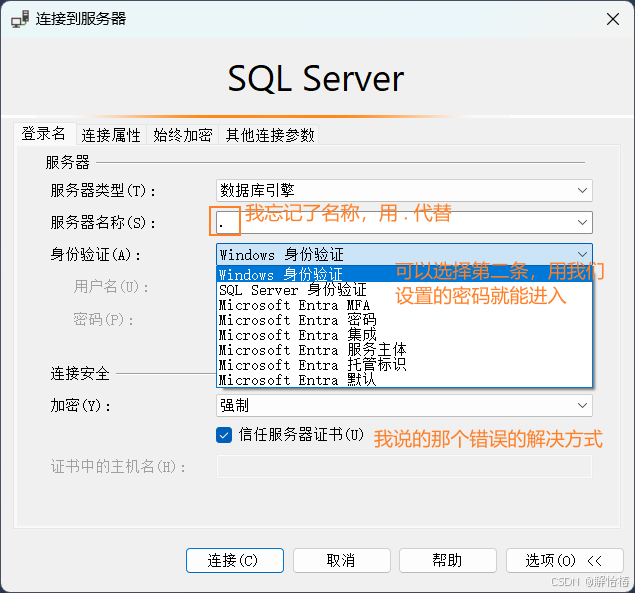
下面就是登录界面
我在连接的时候遇到报错
A connection was successfully established with the server, but then an error occurred during the login process. (provider: SSL Provider, error: 0 - 证书链是由不受信任的颁发机构颁发的
可以点击选项,在"加密"下有一个 “信任服务器证书”,选择即可
这个就是我登陆成功之后的界面
至此,连接成功
四、使用
4.1、数据库的操作
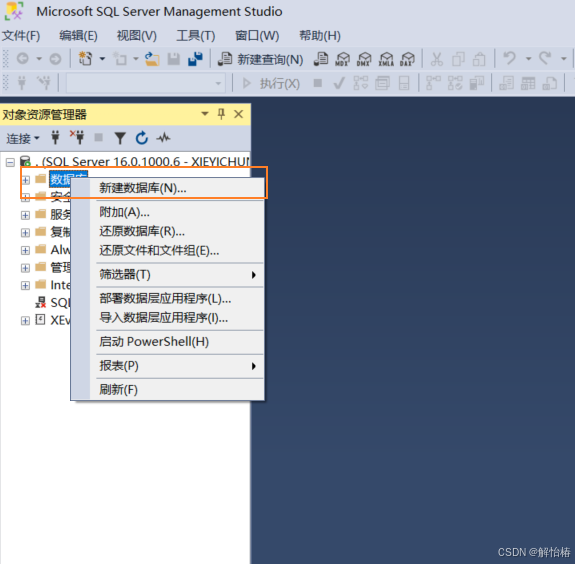
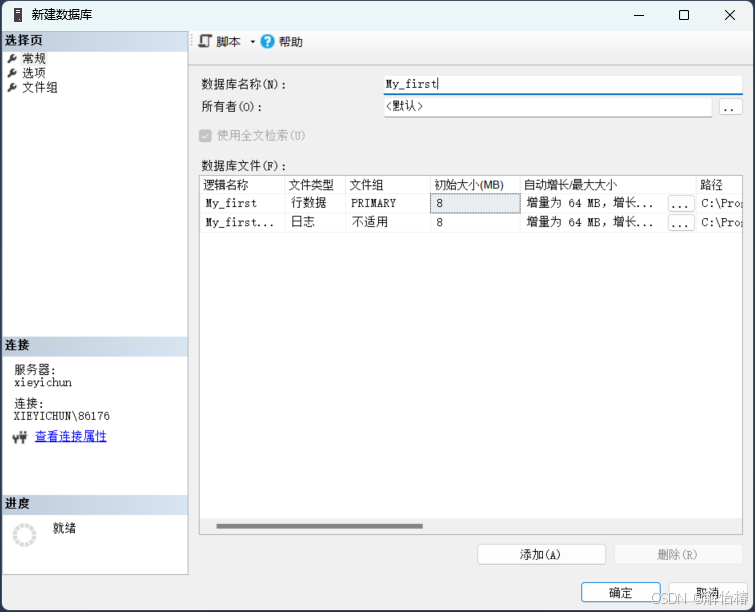
右键点击数据库–>新建数据库
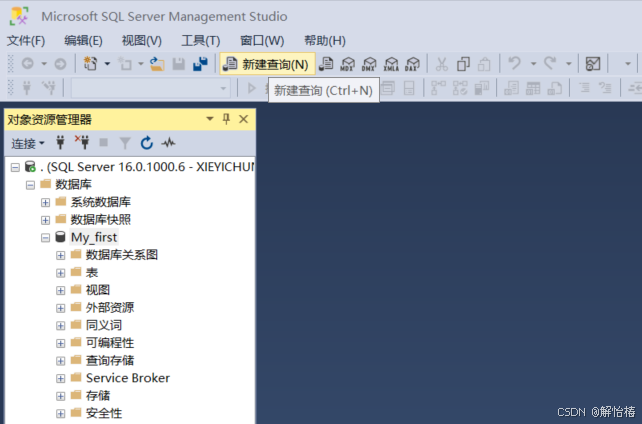
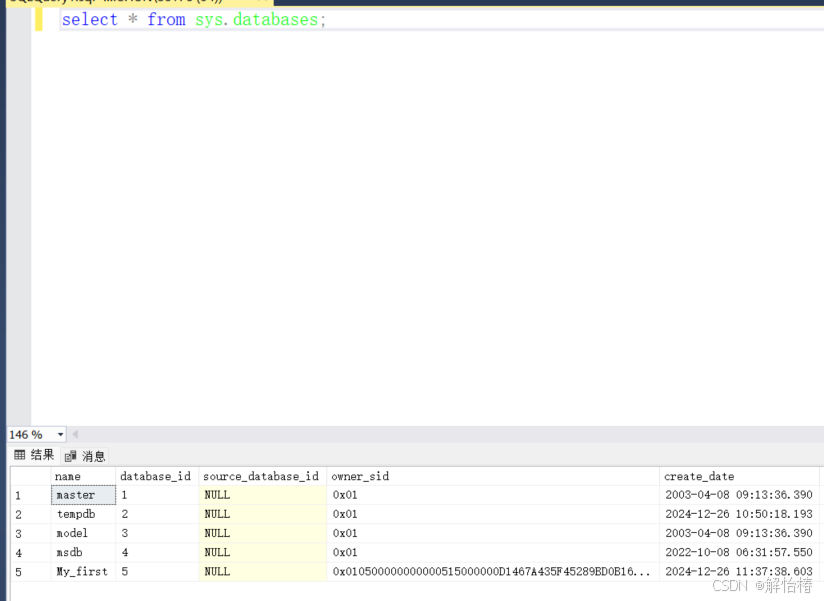
可以点击新建查询检查我们的数据库是否建立成功
select * from sys.databases;
在"mysql"这款数据库的软件一般是database,但是“sql server”是要在database的前面加上sys.(sys有“计算机系统”含义)。
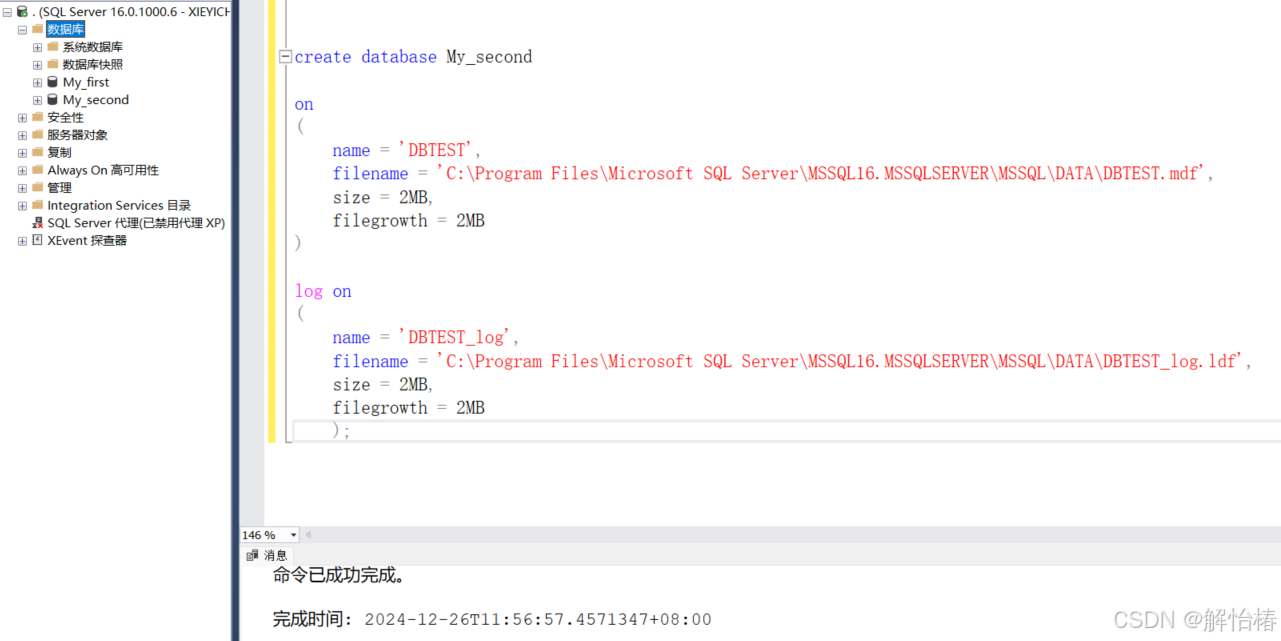
使用命令行创建数据库
create database 数据库名称
on
(
name = 数据文件名称,
filename = 数据文件地址,
size = 数据文件内存初始大小,
filegrowth = 数据文件递增内存大小
)log on --日志文件
(
name = 日志文件名称,
filename = 日志文件地址,
size = 日志文件初始化大小,
filegrowth = 日志文件递增内存大小
)
4.2、表的操作
在 My_first下
右键 “表”–>新建–>表

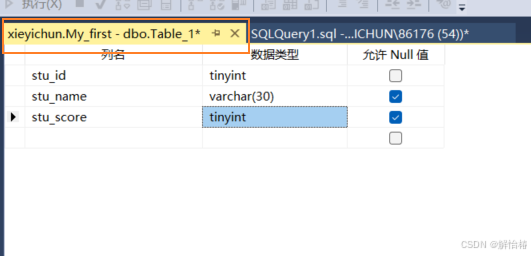
以下是SQL Server常用的数据类型
tinyint小整型数据,一般是1,2,3这类的数据
bigint大整型数据,一般表示比较大的数据类型
float(n)可选精度的浮点数(实数),精度至少为n为数字
char(n)长度为n的定长字符串
varchar(n) 最大长度为n的变长字符串
此时表的框架已经建好了,右键点击如下位置
点击保存
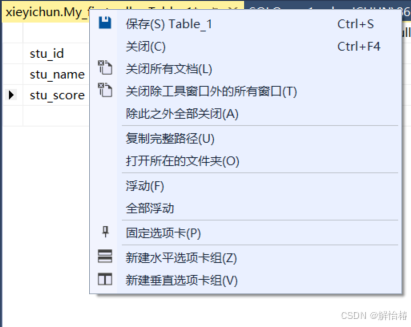
也可以直接Ctrl+S
给个表名
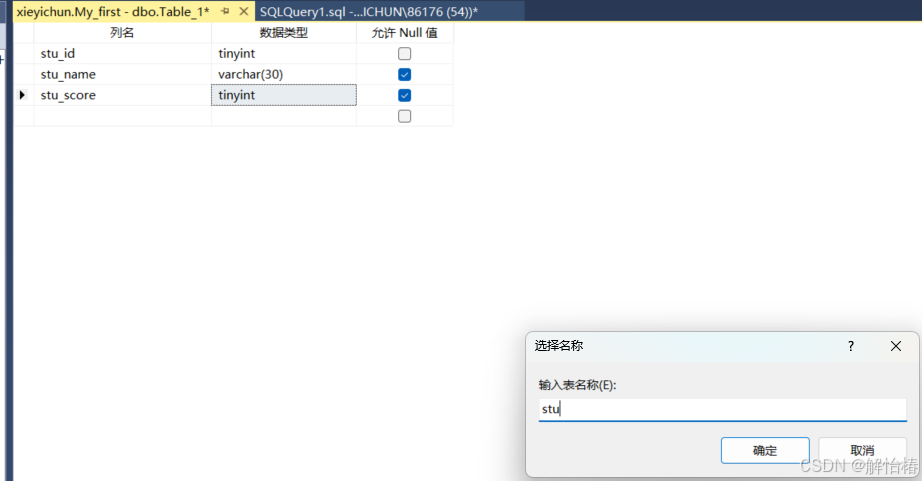
此时就是建好表了
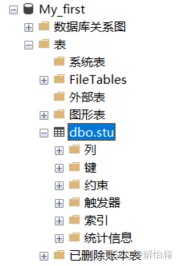
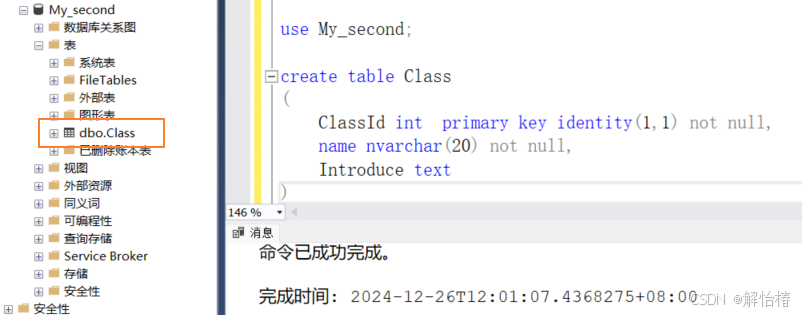
使用命令行创建表
先切换数据库
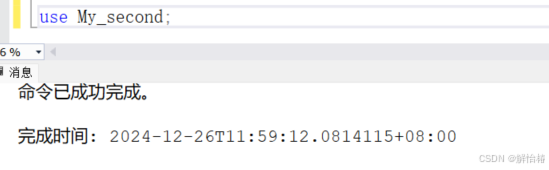
建表语句如下
create table 表名
(
参数名称1 数据类型,
参数名称2 数据类型,
)









![[矩形绘制]](https://i-blog.csdnimg.cn/img_convert/cd2e442afb825819d1c7be8f8f9b43da.png)









