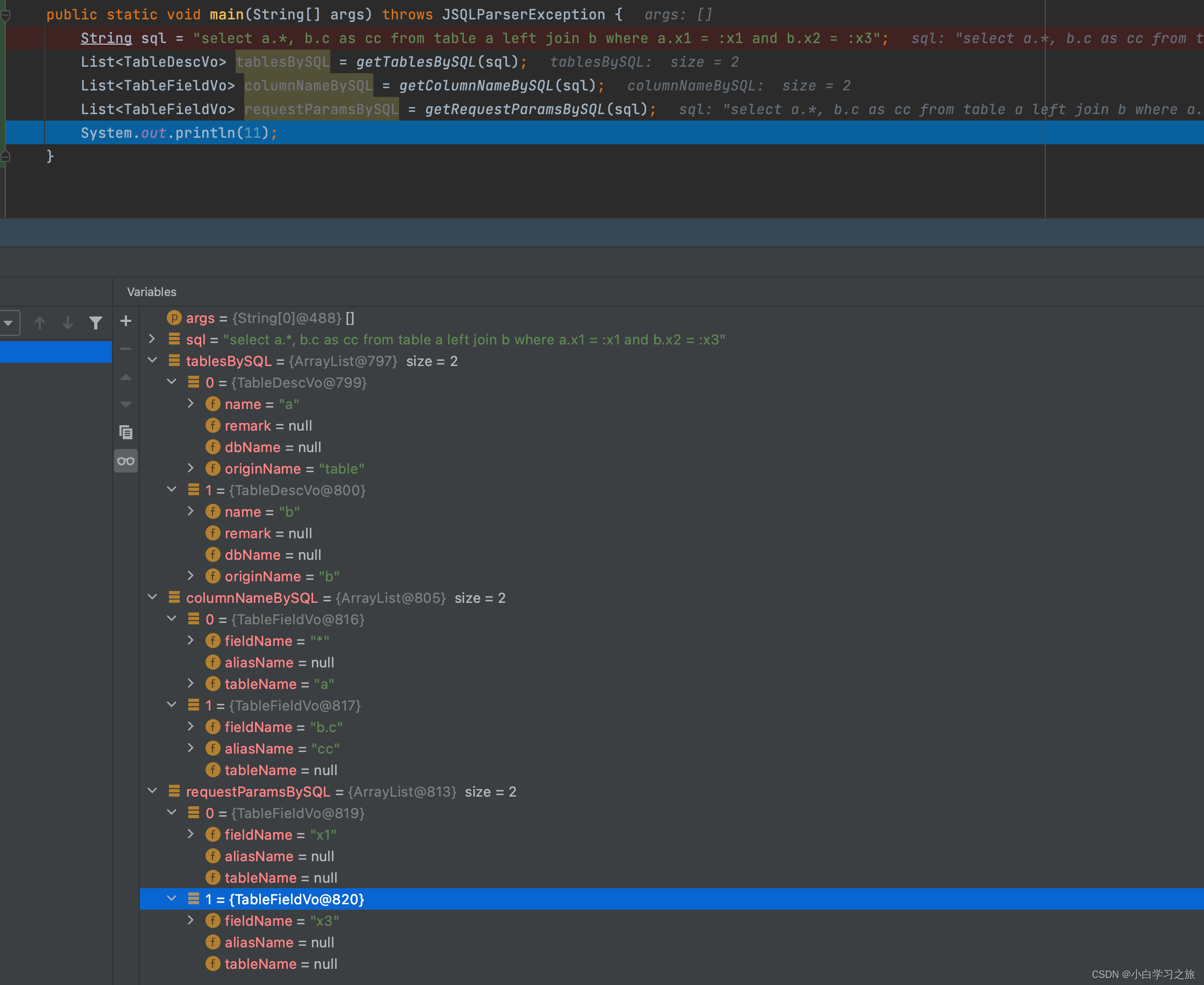
简介: 本文根据2023云栖大会演讲实录整理而成,演讲信息如下
演讲人:张治国|阿里云智能计算平台研究员、阿里云MaxCompute负责人
演讲主题:MaxCompute架构升级及开放性解读
活动:2023云栖大会
MaxCompute发展经历了三个阶段:MaxCompute1.0,主旨是达到大规模的数据处理能力,在性能和规模上提供给用户一个分布式处理平台;MaxCompute2.0,主旨是Serverless,强调弹性和性价比;MaxCompute3.0阶段主旨一体化,包括湖仓一体、离线实时一体化等。

在整个MaxCompute发展过程中,可以从五个维度看一下数仓的发展趋势;
- 随着现代数据驱动各个不同业务的发展,数据规模越来越大;
- 在不同规模下,应用越来越多元化,其中包括数据结构化、半结构化和非结构化,应用随着AI的兴起,AI的应用也越来越多,对数仓的要求也会越来越高;
- 数据的实时性、时效性要求越来越高,我们需要更多做数据实时大批量的流式导入、实时数仓这方面的工作;
- 对数据的准确性要求也越来越高,我们需要大规模数据治理、质量控制这方面的工作;
- AI兴起,大家都围绕着数据来做业务决策,怎么从现有数据中产出更高的价值,这也是大家对数仓发展的一个越来越高的要求;
围绕这五个不同发展趋势,阿里云提出MaxCompute4.0开放一体架构,围绕近实时,开放性、性价比、Data+AI一体化等多维度进行升级。

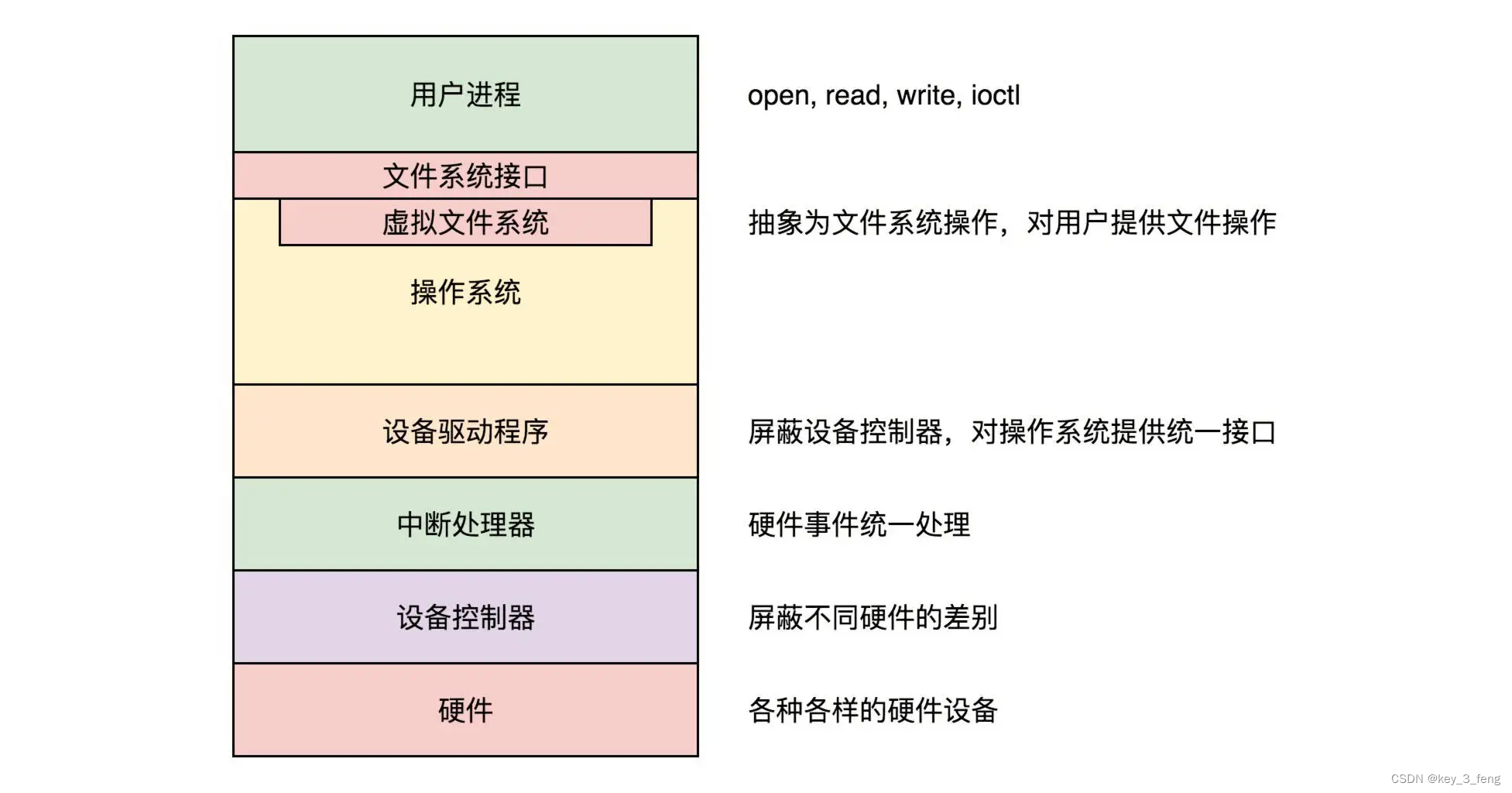
MaxCompute4.0开放一体架构,底层数据高并发、实时流式数据导入,数据同时可以选择导入到MaxCompute自己的盘古存储系统,也可以导入到OSS一些开放数据结构中,内置存储选用的是自己的AliORC。在这之上设计了统一的语言数据管理服务,可以纳管内置的存储数据,同时可以通过DF同时管理OSS和HDFS上面的开放数据结构。通过一个开放存储的服务,提供一个统一的接口给上层不同计算引擎做不同业务场景下的计算要求。再往上使用弹性计算资源调度,可以很容易调度不同的计算引擎在整个计算平台上去计算数据。最上层是对接不同的开发平台和数据应用。
MaxCompute 4.0 开放性升级:开放存储及计算架构
MaxCompute 4.0的开放性升级有两方面,一个是开放存储,一个是开放计算架构。开放存储我们希望把内置的数据格式能够通过开源内存格式提供给不同计算引擎。开放计算架构希望内置计算引擎可以通过同样一个API可以高效访问数据湖上的数据。
开放结构最主要提供的价值因为现在用户的应用、计算各个不同场景需要不同的计算引擎和不同的计算方式,MaxCompute 提供灵活开放的开源大数据AI引擎的计算方式给不同应用。并且在这种开放场景下,我们也可以提供比较灵活的计算资源。

如上图所示,左边是比较通用的一些场景,如果大家已经用了MaxCompute现代一些计算,同时需要一些AI计算或者一些其他计算,可以通过Storage API对接底下统一的数据源做不同的计算,这样可以提供一个数据零拷贝,不需要为了不同计算把数据拷贝出去放到不同地方然后做计算。另外我们希望能够提供统一的管理可以纳管不同的数据源,大家在云上或者别的地方有自己的计算资源也可以用自己的计算资源对接自己的数据做不同的计算。
现在数据的实时性方案很多在用的都是Lambda架构的模式,Lambda架构全链路数据治理都有很多痛点,这中间会有一些数据融合、数据一致性问题。在MaxCompute4.0升级的时候,做了近实时处理框架的发布,达到一份数据一份code,可以低成本低运维统一实施和批量处理链路。整个架构我们用一个统一的数据组织结构和数据管理,在这上面能够有统一的计算框架,大家不用在实时和离线框架上用不同计算引擎,最终实现所有数据不管实时还是离线都有统一的语言数据管理。
MaxCompute 4.0 致力于通过技术全方位提升性价比
随着AI的兴起,数据规模越来越大,用户对数据计算的性价比方面有更高的追求,MaxCompute4.0在过去一年,一直致力于做全方面的性价比提升。
计算高性能方面,SQL引擎方面在不断提高。在HBO/HBS根据历史查询数据,历史的统计信息我们能做更好的数据优化及查询优化,并且通过资源调度的优化提高性能。大家都知道大规模数据处理的时候,最主要的核心步骤是数据的shuffling,我们做了很多工作来提高整个数据shuffle性能。除此之外,MaxCompute4.0还尝试通过推荐能够帮助大家做一些物化视图的总结,根据物化视图消除重复性的计算。
在低成本方面,根据数据的冷热,访问的不同频率做到了分层存储。通过JSON半结构化数据的列存,实现更好的压缩。
在性价比方面,MaxCompute通过弹性资源调度、自适应SQL引擎、存储优化、智能数仓四个方面技术优化,实现了弹性CU最终降价50%。

- 弹性资源调度:当用户根据包年包月处理会有很多空闲时候,虽然没有用计算资源但是这个计算资源还是会算到里面去,如果有弹性资源就可以比较贴切计算的模型,根据不同时间段给不同的quota,从而达到降本增效。后面我们根据你的历史,比如过去三个月使用情况做一些不同的资源变配的推荐,满足资源降低成本的能力。
- 自适应的SQL引擎:我们做了更多的工作,可以分成stage和stage之间的自适应优化。在同一个stage不同算子之间我们也可以做到不同自适应算法。
- 存储优化:我们自研内部的数据格式AliORC,跟一些比较通用的parquet和ORC格式对比,测试结果显示读写性能是其2-6倍,压缩比我们比他们高大概30%。我们会根据你数据的访问频次能够自动推荐你在哪些数据可以做冷存数据,提供更高性价比的存储优化。
- 智能数仓:自研大数据对比开源大数据最大的区别就是我们是一个自闭环,能够做自动优化,将历史数据统一放到我们的原仓数据里,根据原仓信息,可以自动做一些存储方面和计算方面不同的优化。
MaxCompute 4.0 Data+AI:One Env+One Data+One Code
AI是一个新的浪潮,过去一年我们对数仓和AI如何结合做了很多思考。AI整个应用的生命周期是数据收集、数据清洗、数据预处理、数据训练、数据推理。有数据表明,大家认为80%的时间花在数据的处理上,数据处理有很多痛点:
- 大数据开发和AI开发是两个割裂的环境; 大数据开发很多时候大家用SQL,但是AI现在更多的用Python开发环境。
- AI更关注AI计算引擎; 对数据的大规模并发处理和分布式处理的能力有所欠缺,很多时候用户要在自己本地做数据清理,或者找数据开发师去做数据处理。
- 数据来源比较多样化; 很多数据大家会放在数据湖上,没有一个统一的数据管理的平台能够帮忙做数据管理,今天你处理了数据,而另外一个人需要产生非常相近的数据,但他不知道你这已经处理了这份数据他有可能重新跑一遍,不光花了时间也花了资源。
- 开发迭代效率低; 因为两套系统,导致整个开发链路都比较长,效率低下。

我们希望能够从数仓方面帮助用户解决那些痛点。MaxCompute 4.0主旨实现,One Env+One Data+One Code,这背后核心就是提供一个Python的开发环境,一个Notebook的开发体验。在Data For AI方面,MaxCompute全面升级DataFrame能力,发布分布式计算框架MaxFrame,100%兼容Pandas等数据处理接口,通过一行代码即可将原生Pandas自动转为MaxFrame分布式计算,打通数据管理、大规模数据分析、处理到ML开发全流程,打破大数据及AI开发使用边界,实现大数据AI开发一体化,大大提高开发效率。
另外在AI For Data方面,我们提供一个Python大数据处理,这样我们更容易使用一些丰富的AI和ML一些模型来做更好的数据挖掘和分析。
回头看整个MaxCompute4.0,我们希望做到数据的开放,计算引擎的包容,能够满足各种不同的数据计算场景的需求,以及根据数据实时性会增加增量计算的能力,满足大家对数据实时性的要求。后续MaxCompute也会持续在开放架构、增量处理、Data+AI三个方向持续发展。






![[工业自动化-12]:西门子S7-15xxx编程 - PLC从站 - ET200 SP系列详解](https://img-blog.csdnimg.cn/ed40b7ae0e9b42cbb846bd3ae3a4a03e.png)