使用张量表征真实数据
本文为书pytorch深度学习实战的一些学习笔记和扩展知识,涉及到的csv文件等在这里不会给出,但是我会尽量脱离这一些文件将书本想要表达的内容给展示出来。
文章目录
- 使用张量表征真实数据
- 1. 加载图像文件
- 2. 改变布局
- 3. 加载目录下图像
- 4. 正规化数据
- 5. 三维图像:体数据
- 6. 表示表格数据
- 7. 独热编码
- 8. 分类与阈值
- 9. 处理时间序列
学习目标:我们如何获取一段数据,并以一种适合训练深度学习模型的方式用张量表示?这就是这篇博文的主要内容,我们将介绍不同类型的数据,并展示如何将这些数据表示为张量。
1. 加载图像文件
使用imageio模块加载PNG格式图像:
import imageio
img_arr = imageio.v2.imread('./1.png')
print(img_arr)
print(img_arr.shape)
[[[45 46 48][44 45 47][44 45 49]...[30 31 35][30 31 35][30 31 35]][[44 45 47][44 45 47][43 44 48]...[30 31 35][30 31 35][30 31 35]][[44 45 47][44 45 47][44 45 49]...[30 31 35][30 31 35][30 31 35]]...[[44 45 49][44 45 49][44 45 49]...[30 31 35][30 31 35][30 31 35]][[44 45 49][44 45 49][44 45 49]...[30 31 35][30 31 35][30 31 35]][[44 45 49][44 45 49][44 45 49]...[30 31 35][30 31 35][30 31 35]]]
(256, 252, 3)
这段输出显示的是一个RGB图像的像素数据,以及该图像的尺寸和颜色通道信息。
-
像素数据: 输出的大部分是一个三维数组,代表了图像中每个像素的颜色信息。
- 数组的每个元素是一个长度为3的小数组,分别对应RGB颜色模型中的红色(R)、绿色(G)和蓝色(B)通道。
- 每个通道的值范围通常是0-255,表示该颜色通道的强度。例如,[45, 46, 48] 代表一个像素点,其中红色通道的强度为45,绿色为46,蓝色为48。
-
图像尺寸: 输出的最后部分
(256, 252, 3)描述了图像的尺寸和颜色通道。- 256: 图像的高度(像素行数)。
- 252: 图像的宽度(像素列数)。
- 3: 颜色通道数,这里是RGB的3个通道。
唯一要注意的是维度布局,处理图像数据的pytorch模块要求张量排列为C H W,分别表示通道高度宽度。
2. 改变布局
我们可以用张量的permute()方法将每个新的维度,利用旧维度得到一个合适的布局。
img = torch.from_numpy(img_arr)
out = img.permute(2,0,1) #permute()函数对通道进行重排CxHxW—>HxWxC
注意点是,这个操作没有复制张量数据,而是让out使用与img相同的底层储存,所以img中的像素改变也会影响out中的数据。
3. 加载目录下图像
从一个输入目录中加载所有的PNG图像,并将它们储存在张量中:
batch_size = 3
batch = torch.zeros(batch_size, 3, 256, 256, dtype=torch.uint8)
import os
data_dir = '......'
filenames = [name for name in os.listdir(data_dir)if os.path.splitext(name)[-1]=='.png']
for i ,filename in enumerate(filenames):img_arr = imageio.imread(os.path.join(data_dir,filename))img_t = torch.from_numpy(img_arr)img_t = img_t.permute(2, 0, 1)img_t = img_t[:3]batch[i] = img_t
print(batch)
4. 正规化数据
神经网络通常使用浮点数张量作为输入,当输入数据的范围在0~1或-1~1时,神经网络表现出最佳的训练性能。
- 归一化:
batch = batch.float()
batch /= 255.0 # 将数据归一到[0,1]
print(batch)
在数字图像处理中,每个像素的颜色通道通常用一个8位整数来表示,这意味着每个通道的值都是0到255,所以最大值就是255,这里的除以255就是这样来的。
- 标准化:
batch_size = 3
batch = torch.zeros(batch_size, 3, 256, 256, dtype=torch.uint8)
import os
data_dir = '...'
filenames = [name for name in os.listdir(data_dir)if os.path.splitext(name)[-1]=='.png']
for i ,filename in enumerate(filenames):img_arr = imageio.cv2.imread(os.path.join(data_dir,filename))img_t = torch.from_numpy(img_arr)img_t = img_t.permute(2, 0, 1)img_t = img_t[:3]batch[i] = img_t
batch = batch.float()n_channels = batch.shape[1]
for c in range(n_channels):mean = torch.mean(batch[:,c])std = torch.std(batch[:,c])batch[:,c] = (batch[:,c] - mean)/std
print(batch)
print(batch.shape)
在pytorch中,处理单张图片时候用到的是CHW格式,而在处理一个批次时,用到的是NCHW格式,N是批次大小。所以这里用到的是n_channels=batch.shape[1]
5. 三维图像:体数据
以上的内容都是对二维图像进行操作,而在某些情况下,例如CT的医学成像应用程序,这通常需要大量的从头到脚的大量图像序列,而这一些序列代表的就是人体的一份份切片,也就是二维图像。CT图像通常是灰度图像,意味着每个像素点不是彩色的,而是只有一个强度值,这个值表示在那个特定位置X射线通过身体组织后剩余的强度。这些强度值通常被编码为12位或更高,这意味着它们有比8位灰度图像(0到255的范围)更高的强度范围。这个高强度范围使得CT图像能够展现出更细致的组织密度差异,对于检测各种体内结构,如骨骼、器官和异常组织等非常有用。由于CT扫描是三维的,它包含了多个连续的切片,这些切片堆叠在一起构成了整个扫描区域的三维体数据。在处理CT数据时,通常会处理这个三维数组,而不仅仅是单个二维图像。三维体数据使得医生和算法能够更好地理解和分析身体内部的结构。
dir_path = '...'
vol_arr = imageio.volread(dir_path,'DICOM')
print(vol_arr.shape)
vol = torch.from_numpy(vol_arr).float()
vol = torch.unsqueeze(vol,0)
print(vol.shape)
6. 表示表格数据
加载csv文件最常用的三种是:python自带的csv模块、numpy、pandas
import torch
import numpy as np
wine_path = '.\\deeply\\data\\p1ch4\\tabular-wine\\winequality-white.csv'
wine_numpy = np.loadtxt(wine_path, dtype=np.float32, delimiter=";",skiprows=1)
print(wine_numpy)
wine_tensor = torch.from_numpy(wine_numpy)
print(wine_tensor.shape,wine_tensor.dtype)col_list = next(csv.reader(open(wine_path), delimiter= ';'))
print(col_list)
[[ 7. 0.27 0.36 ... 0.45 8.8 6. ][ 6.3 0.3 0.34 ... 0.49 9.5 6. ][ 8.1 0.28 0.4 ... 0.44 10.1 6. ]...[ 6.5 0.24 0.19 ... 0.46 9.4 6. ][ 5.5 0.29 0.3 ... 0.38 12.8 7. ][ 6. 0.21 0.38 ... 0.32 11.8 6. ]]
torch.Size([4898, 12]) torch.float32
['fixed acidity', 'volatile acidity', 'citric acid', 'residual sugar', 'chlorides', 'free sulfur dioxide', 'total sulfur dioxide', 'density', 'pH', 'sulphates', 'alcohol', 'quality']
7. 独热编码
独热编码比较陌生,但它很容易理解:
独热编码(One-Hot Encoding)是一种处理分类数据的方法,常用于机器学习和数据分析领域。在独热编码中,每个类别都被表示为一个二进制向量,这个向量中只有一个元素是1,其余都是0。这种表示法使得不同的类别之间在数值上彼此独立,没有任何数值上的大小关系。
特点:
- 二进制向量:每个类别由一个长度等于类别总数的向量表示。
- 单一激活位:在每个类别的向量中,只有一个位置被置为1(表示当前类别),其余位置都是0。
- 去除数值关系:由于每个类别都由独立的位表示,因此避免了不同类别间可能存在的数值上的比较或排序。
示例:
假设有一个类别变量,包含三个可能的类别:猫、狗和鸟。在独热编码中,这些类别将被编码为:
- 猫:[1, 0, 0]
- 狗:[0, 1, 0]
- 鸟:[0, 0, 1]
应用:
- 机器学习模型:许多机器学习算法和模型要求输入数据是数值形式。独热编码能够将非数值类别特征转换为数值形式,使其能够被这些模型处理。
- 去除类别间的偏序关系:在一些情况下,类别数据可能会被错误地解释为有序数据。例如,如果直接使用数字1、2、3来表示猫、狗、鸟,模型可能会错误地假设狗大于猫,鸟大于狗。独热编码消除了这种假设。
###独热编码
###使用scatter_()方法获得独热编码,该方法将沿着参数提供的索引方向将源张量的值填充进输入张量中
target_onehot = torch.zeros(target.shape[0],10)
target_onehot.scatter_(1, target.unsqueeze(1), 1.0)
print(target_onehot,target_onehot.shape)
8. 分类与阈值

我们用第六点:表示表格数据,来作为例子,为了更好衔接并且脱离csv文件,我先把上面代码放下来:
import torch
import numpy as np# 葡萄酒评分
wine_path = '.\\deeply\\data\\p1ch4\\tabular-wine\\winequality-white.csv'
wine_numpy = np.loadtxt(wine_path, dtype=np.float32, delimiter=";",skiprows=1) ###skiprows=1表示不读第一行,因为其中包含列名
wine_tensor = torch.from_numpy(wine_numpy)# 表示分数
data = wine_tensor[:,:-1]
target = wine_tensor[:,-1].long()
"""
data = wine_tensor[:,:-1]:这行代码获取了除了最后一列之外的所有列,即葡萄酒的特征。
target = wine_tensor[:,-1].long():这行代码获取了最后一列,并将其转换为长整型(long),这一列是葡萄酒的评分(目标标签)。
"""# 计算均值和方差
data_mean = torch.mean(data, dim=0)
data_var = torch.var(data, dim=0)# 标准化数据
data_normalized = (data - data_mean)/torch.sqrt(data_var)
bad_index = target <= 3 # 在这一列中筛选
print(target)
print(bad_index)
print(target.shape, bad_index.shape, bad_index.sum())
# 输出:
tensor([6, 6, 6, ..., 6, 7, 6])
tensor([False, False, False, ..., False, False, False])
torch.Size([4898]) torch.Size([4898]) tensor(20)
知道了我们不需要的索引,所以现在可以剔除不需要的数据了:
bad_data = data[bad_index]
print(bad_data.shape)
# 输出: torch.Size([20, 11])
下面就是一系列常见的操作了,我会在我觉得需要的地方加以补充和注释:
# 分为好中劣三等
bad_data = data[target <= 3]
mid_data = data[(target > 3) & (target < 7)]
good_data = data[target >= 7]
# 对每一列取均值
bad_mean = torch.mean(bad_data,dim=0)
mid_mean = torch.mean(mid_data,dim=0)
good_mean = torch.mean(good_data,dim=0)
# 使用二氧化硫总量的阈值来区分酒的好劣
total_sulfur_threshold = 141.83 # 设定阈值
total_sulfur_data = data[:,6] # 从 data 张量中提取第7列(索引为6),这列代表总硫化物含量# 比较筛选操作,这里不要和上面代码块意义一样,也是筛选,只是没有使用符号而已
predicted_indexes = torch.lt(total_sulfur_data,total_sulfur_threshold)
# 得到真正好酒的索引
actual_indexes = target > 5
print(actual_indexes.shape,actual_indexes.dtype,actual_indexes.sum(),actual_indexes)
# 检验预测与实际结果是否相符
# item()方法 将数组元素复制到标准Python标量并返回它。
n_matches = torch.sum(actual_indexes & predicted_indexes).item()
n_predicted = torch.sum(predicted_indexes).item()
n_actual = torch.sum(actual_indexes).item()
print(f'预测得到的优质酒数量:',n_matches)
print(f'2700瓶中的预测准确率:',n_matches/n_predicted)
print(f'整个数据集中的预测准确率:',n_matches/n_actual)
9. 处理时间序列
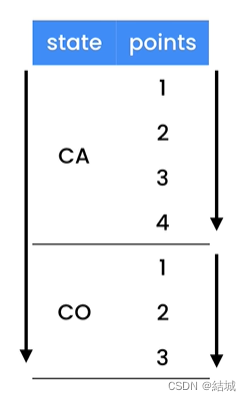
在表示平面表中组织的数据时,我们发现表中的每一行都是独立于其他行的,它们的顺序毫无关系,换句话说没有那一列对那些出现较早或者较晚的信息进行编码。那如果有一组数据是要我们观察它是如何一年一年变化的或者有一组数据是共享单车的使用情况的,调查共享单车的使用情况有时间,季节等,这时就需要将一维多通道数据转化为二维多通道数据。如下图所示:

下面就来给出代码,以及我学习过程中有疑惑地方的解释:
bikes_numpy = np.loadtxt('.\\deeply\\data\\p1ch4\\bike-sharing-dataset\\hour-fixed.csv',dtype = np.float32,delimiter = ",",skiprows =1,converters={1: lambda x: float(x[8:10])})
bikes = torch.from_numpy(bikes_numpy)
有疑惑的地方就是converters,这个的意思就是假设在csv文件里面有一列为日期XXXX-XX-XX(年月日)当我们困惑如何将它们存起来时,converters可以解决,上面代码的意思就是他将日期中的日XX提取出来并分开为X和X,两个单独为一列。当然你也可以根据自己需求选择。
# 使用view()按时间段调整数据
daily_bikes = bikes.view(-1, 24, bikes.shape[1])
view(): 这个方法用于重新塑形张量,而不改变其数据。这里的 -1, 24, bikes.shape[1] 意味着将数据重塑为一个三维张量。-1 表示该维度的大小由其他维度确定,24 表示每天有24小时,bikes.shape[1] 保持原始数据的特征数不变。
原始形状:一个二维数组,形状为 (17520, 17)。
变换后的形状:一个三维数组,形状为 (730, 24, 17)。
# 调整为 NxCxL 次序
daily_bikes = daily_bikes.transpose(1, 2)
transpose(1, 2): 这个方法用于交换张量中的两个维度。这里,它交换了第二和第三维度(维度索引从0开始计数)调整时候变为(730, 17, 24)
全部代码:
bikes_numpy = np.loadtxt('.\\deeply\\data\\p1ch4\\bike-sharing-dataset\\hour-fixed.csv',dtype = np.float32,delimiter = ",",skiprows =1,converters={1: lambda x: float(x[8:10])})
bikes = torch.from_numpy(bikes_numpy)
# 使用view()按时间段调整数据
daily_bikes = bikes.view(-1, 24, bikes.shape[1])
# 调整为NxCxL次序
daily_bikes = daily_bikes.transpose(1,2)