大家好,特征选择是机器学习建模流程中最重要的步骤之一,特征选择的好坏直接决定着模型效果的上限,好的特征组合甚至比模型算法更重要。除了模型效果外,特征选择还有以下几点好处:
-
提高模型性能并降低复杂性(维数爆炸)
-
减少训练时间
-
由于无信息和冗余特征而降低了过度拟合的风险
-
简化的部署流程和实时数据管道,这是一个经常被低估的优势
本次给大家介绍一个小众的、可完全自动化的特征选择工具:AutoFeatSelect,使用它可以让繁琐的筛选过程变得非常轻松。
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
本文由粉丝群小伙伴总结与分享,如果你也想学习交流,资料获取,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:dkl88194,备注:来自CSDN + 加群
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
AutoFeatSelect介绍
AutoFeatSelect可以自动执行各种特征筛选步骤,比如计算相关性、消除高度相关的特征以及应用多种特征选择方法,并生成对应的筛选结果。该库自动化并简化了以下特征选择方法的实现:
-
数值型特征、分类型特征的相关性分析
-
使用 LightGBM、XGBoost、随机森林进行特征重要性分析
-
LassoCV 系数分析
-
permutation排列重要性
-
通过交叉验证进行递归特征消除
-
Boruta
GitHub连接:https://github.com/dorukcanga/AutoFeatSelect
实战案例
下面我们直接通过一个实战案例来说明如何使用autofeatselect。
首先pip安装包,然后导入。
pip install autofeatselect
import pandas as pd
import numpy as npfrom autofeatselect import CorrelationCalculator, FeatureSelector, AutoFeatureSelect
01 数据准备
数据:https://www.kaggle.com/competitions/porto-seguro-safe-driver-prediction/data
# 准备数据
df = pd.read_csv("train.csv")
df.drop('id', axis=1, inplace=True)# 设置数字和分类特征以进行进一步分析
response = 'target'
cat_feats = [c for c in df.columns if '_cat' in c]
bin_feats = [c for c in df.columns if '_bin' in c]
cat_feats = cat_feats + bin_feats
num_feats = [c for c in df.columns if c not in cat_feats+[response]]df[num_feats] = df[num_feats].astype('float')
df[cat_feats] = df[cat_feats].astype('object')df.replace(-1, np.nan, inplace=True)# 切分训练和测试集
X_train, X_test, y_train, y_test = train_test_split(df[num_feats+cat_feats],df[response],test_size=0.2,random_state=42)
autofeatselect有两种使用方法。
第一种是属于半自动的特征筛选,分步式地控制筛选方法和顺序。第二种是全自动化特征筛选,直接通过一个api函数配置参数即可完成整个筛选过程。
02 方法一:半自动方法
考虑到相关特征会对特征重要性和选择结果产生负面影响,因此必须首先删除高度相关的特征。可以使用CorrelationCalculator类的numeric_correlations和categorical_correlations方法检测。
# 静态特征即使与其他特征相关也不会被删除
static_features = ['ps_ind_01', 'ps_ind_03','ps_ind_14']# 检测相关特征
corr_df_num, num_remove_list = CorrelationCalculator.numeric_correlations(X_train,features=num_feats,static_features=static_features,threshold=0.9)corr_df_cat, cat_remove_list = CorrelationCalculator.categorical_correlations(X_train,features=cat_feats,static_features=None,threshold=0.9)#Remove correlated features
num_feats = [c for c in num_feats if c not in num_remove_list]
cat_feats = [c for c in cat_feats if c not in cat_remove_list]
从初始特征集中删除相关特征后,然后再使用FeatureSelector类计算 LightGBM 特征重要性分数:
# 创建特征选择器对象
feat_selector = FeatureSelector(modeling_type='classification',X_train=X_train, y_train=y_train,X_test=X_test, y_test=y_test,numeric_columns=num_feats,categorical_columns=cat_feats,seed=24)# 超参数和目标函数LightGBM 的值是可以改变的
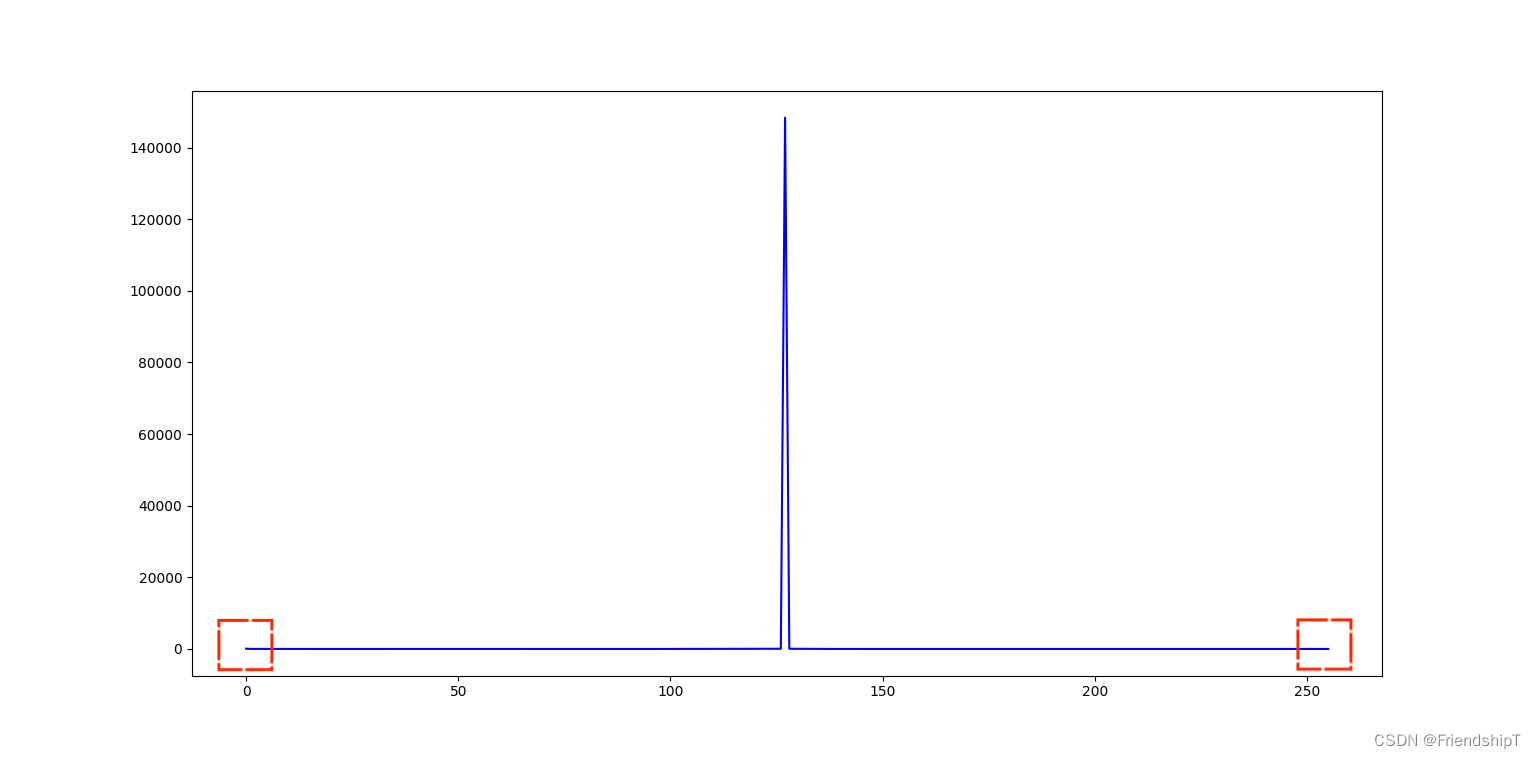
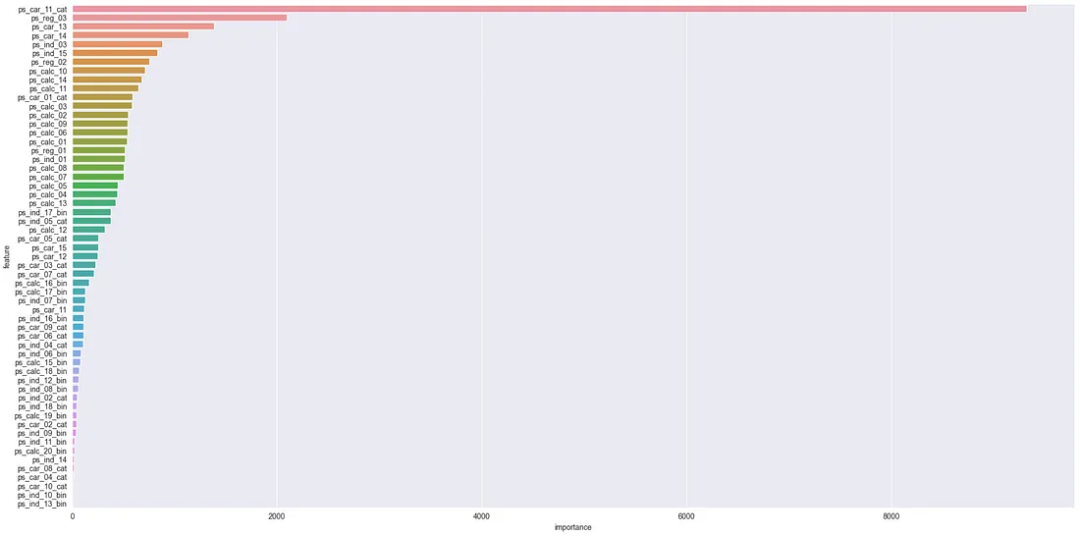
lgbm_importance_df = feat_selector.lgbm_importance(hyperparam_dict=None,objective=None,return_plot=True)
生成的特征重要性图:
当然,这里方法不唯一,也可以通过feat_selector来使用更多的选择方法。特征重要性筛选后再来应用递归特征消除。
# 用LightGBM作为估计器的RFECV特征排名
# LightGBM 和 RFECV 的 yper 参数都可以更改
rfecv_importance_df = feat_selector.rfecv_importance(lgbm_hyperparams=None,rfecv_hyperparams=None,return_plot=False)
方法 2:全自动方法
全自动方法的整个过程可以使用AutoFeatureSelect,它实现了一键自动筛选的效果,只需配置参数即可,而不像半自动需要逐一删除相关特征再应用特征选择方法等分步操作,全自动提供了更高效、更全面的方法来处理特征选择。
# 创建AutoFeatureSelect类
feat_selector = AutoFeatureSelect(modeling_type='classification',X_train=X_train,y_train=y_train,X_test=X_test,y_test=y_test,numeric_columns=num_feats,categorical_columns=cat_feats,seed=24)# 检测相关特征
corr_features = feat_selector.calculate_correlated_features(static_features=None,num_threshold=0.9,cat_threshold=0.9)
# 删除相关特征
feat_selector.drop_correlated_features()# 确定要应用的选择方法
# 所有方法的超参数都可以更改
selection_methods = ['lgbm', 'xgb', 'rf','perimp', 'rfecv', 'boruta']
final_importance_df = feat_selector.apply_feature_selection(selection_methods=selection_methods,lgbm_hyperparams=None,xgb_hyperparams=None,rf_hyperparams=None,lassocv_hyperparams=None,perimp_hyperparams=None,rfecv_hyperparams=None,boruta_hyperparams=None)# 打印结果
final_importance_df.head()
可以看到,只需几行代码就可以应用多种特征选择方法。然后会得到所有特征选择方法对所有特征的计算结果。

基于这个结果,我们就可以通过自己的阈值标准对特征进行子集的组合条件筛选,得到最终的筛选特征了。
结论
autofeatselect如名字一样,初衷就是为了简化并高效完成特征选择的过程,它提供了半自动和全自动两种方法,可以根据自己的习惯和需求进行灵活使用。