使用场景: 表值函数即 UDTF,⽤于进⼀条数据,出多条数据的场景。
开发流程:
- 实现 org.apache.flink.table.functions.TableFunction 接⼝
- 实现⼀个或者多个⾃定义的 eval 函数,名称必须叫做 eval,eval ⽅法签名必须是 public 的
- eval ⽅法的⼊参是直接体现在 eval 函数签名中,出参是体现在 TableFunction 类的泛型参数 T 中
注意:
eval 是没有返回值的,和标量函数不同,Flink TableFunction 接⼝提供了 collect(T) 来发送输出的数据,如果体现在函数签名上,就成了标量函数,使⽤ collect(T) 能体现出 进⼀条数据 出多条数据。
在 SQL 中是⽤ SQL 中的 LATERAL TABLE() 配合 JOIN 、 LEFT JOIN xxx ON TRUE 使⽤。
开发案例:
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.*;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.TableFunction;
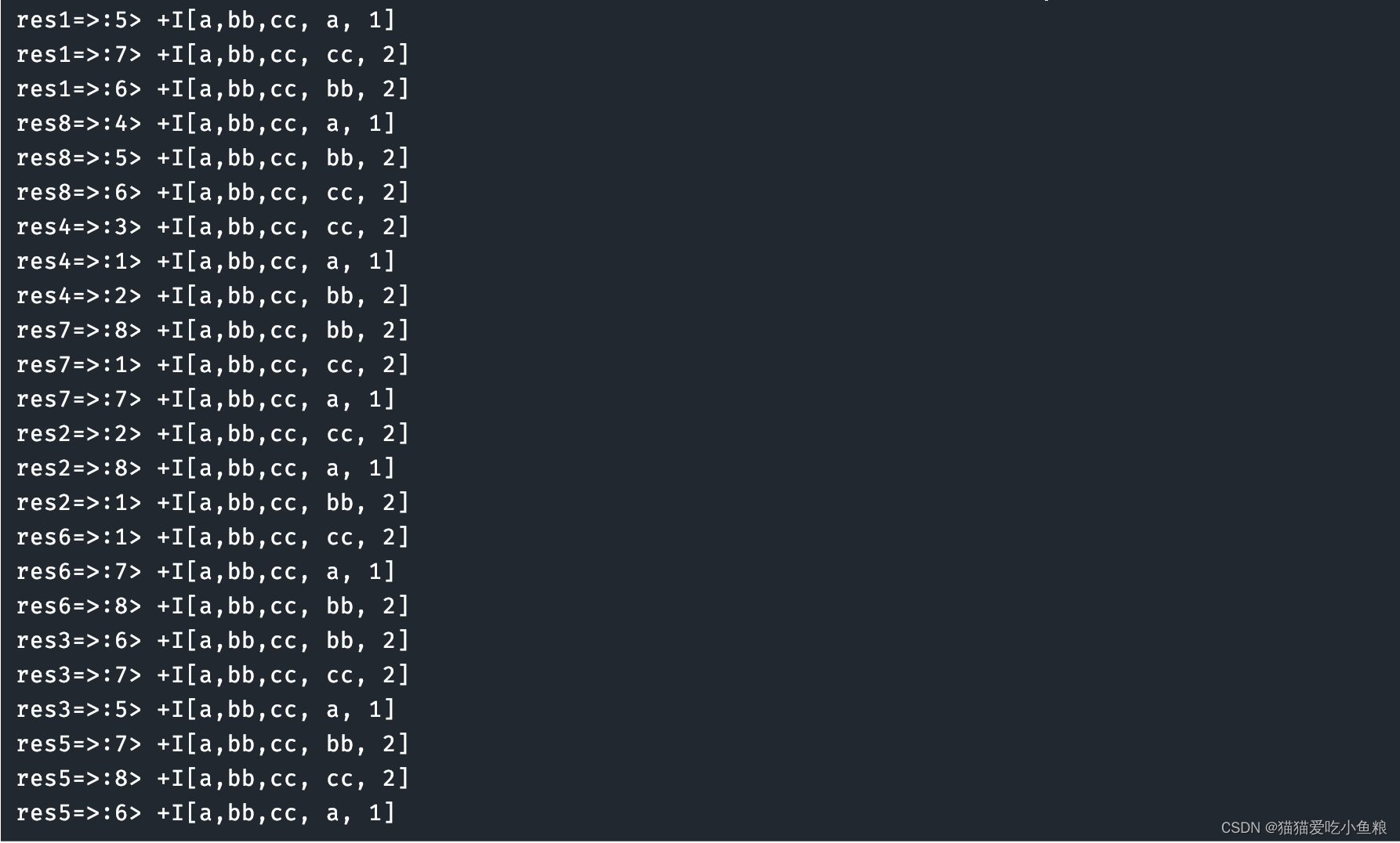
import org.apache.flink.types.Row;import static org.apache.flink.table.api.Expressions.*;/*** 输入数据:* nc -lk 8888* a,bb,cc* * 输出结果:* * res1=>:5> +I[a,bb,cc, a, 1]* res1=>:7> +I[a,bb,cc, cc, 2]* res1=>:6> +I[a,bb,cc, bb, 2]* res8=>:4> +I[a,bb,cc, a, 1]* res8=>:5> +I[a,bb,cc, bb, 2]* res8=>:6> +I[a,bb,cc, cc, 2]* res4=>:3> +I[a,bb,cc, cc, 2]* res4=>:1> +I[a,bb,cc, a, 1]* res4=>:2> +I[a,bb,cc, bb, 2]* res7=>:8> +I[a,bb,cc, bb, 2]* res7=>:1> +I[a,bb,cc, cc, 2]* res7=>:7> +I[a,bb,cc, a, 1]* res2=>:2> +I[a,bb,cc, cc, 2]* res2=>:8> +I[a,bb,cc, a, 1]* res2=>:1> +I[a,bb,cc, bb, 2]* res6=>:1> +I[a,bb,cc, cc, 2]* res6=>:7> +I[a,bb,cc, a, 1]* res6=>:8> +I[a,bb,cc, bb, 2]* res3=>:6> +I[a,bb,cc, bb, 2]* res3=>:7> +I[a,bb,cc, cc, 2]* res3=>:5> +I[a,bb,cc, a, 1]* res5=>:7> +I[a,bb,cc, bb, 2]* res5=>:8> +I[a,bb,cc, cc, 2]* res5=>:6> +I[a,bb,cc, a, 1]*/
public class TableFunctionTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);DataStreamSource<String> source = env.socketTextStream("localhost", 8888);Table table = tEnv.fromDataStream(source, "field");tEnv.createTemporaryView("SourceTable", table);// 在 Table API ⾥可以直接调⽤ UDFTable res1 = tEnv.from("SourceTable").joinLateral(call(SplitFunction.class, $("field"))).select($("field"), $("word"), $("length"));Table res2 = tEnv.from("SourceTable").leftOuterJoinLateral(call(SplitFunction.class, $("field"))).select($("field"), $("word"), $("length"));// 在 Table API ⾥重命名 UDF 的结果字段Table res3 = tEnv.from("SourceTable").leftOuterJoinLateral(call(SplitFunction.class, $("field"))).as("myField", "newWord", "newLength").select($("myField"), $("newWord"), $("newLength"));// 注册函数tEnv.createTemporarySystemFunction("SplitFunction", SplitFunction.class);// 在 Table API ⾥调⽤注册好的 UDFTable res4 = tEnv.from("SourceTable").joinLateral(call("SplitFunction", $("field"))).select($("field"), $("word"), $("length"));Table res5 = tEnv.from("SourceTable").leftOuterJoinLateral(call("SplitFunction", $("field"))).select($("field"), $("word"), $("length"));// 在 SQL ⾥调⽤注册好的 UDFTable res6 = tEnv.sqlQuery("SELECT field, word, length " +"FROM SourceTable, LATERAL TABLE(SplitFunction(field))");Table res7 = tEnv.sqlQuery("SELECT field, word, length " +"FROM SourceTable " +"LEFT JOIN LATERAL TABLE(SplitFunction(field)) ON TRUE");// 在 SQL ⾥重命名 UDF 字段Table res8 = tEnv.sqlQuery("SELECT field, newWord, newLength " +"FROM SourceTable " +"LEFT JOIN LATERAL TABLE(SplitFunction(field)) AS T(newWord, newLength) ON TRUE");tEnv.toDataStream(res1).print("res1=>");tEnv.toDataStream(res2).print("res2=>");tEnv.toDataStream(res3).print("res3=>");tEnv.toDataStream(res4).print("res4=>");tEnv.toDataStream(res5).print("res5=>");tEnv.toDataStream(res6).print("res6=>");tEnv.toDataStream(res7).print("res7=>");tEnv.toDataStream(res8).print("res8=>");env.execute();}@FunctionHint(output = @DataTypeHint("ROW<word STRING, length INT>"))public static class SplitFunction extends TableFunction<Row> {public void eval(String str) {for (String s : str.split(",")) {// 输出结果collect(Row.of(s, s.length()));}}}
}
注意: 如果使⽤ Scala 实现函数,不要使⽤ Scala 中 object 实现 UDF,Scala object 是单例的,可能会导致并发问题。
测试结果: