使用场景: 聚合函数即 UDAF,常⽤于进多条数据,出⼀条数据的场景。
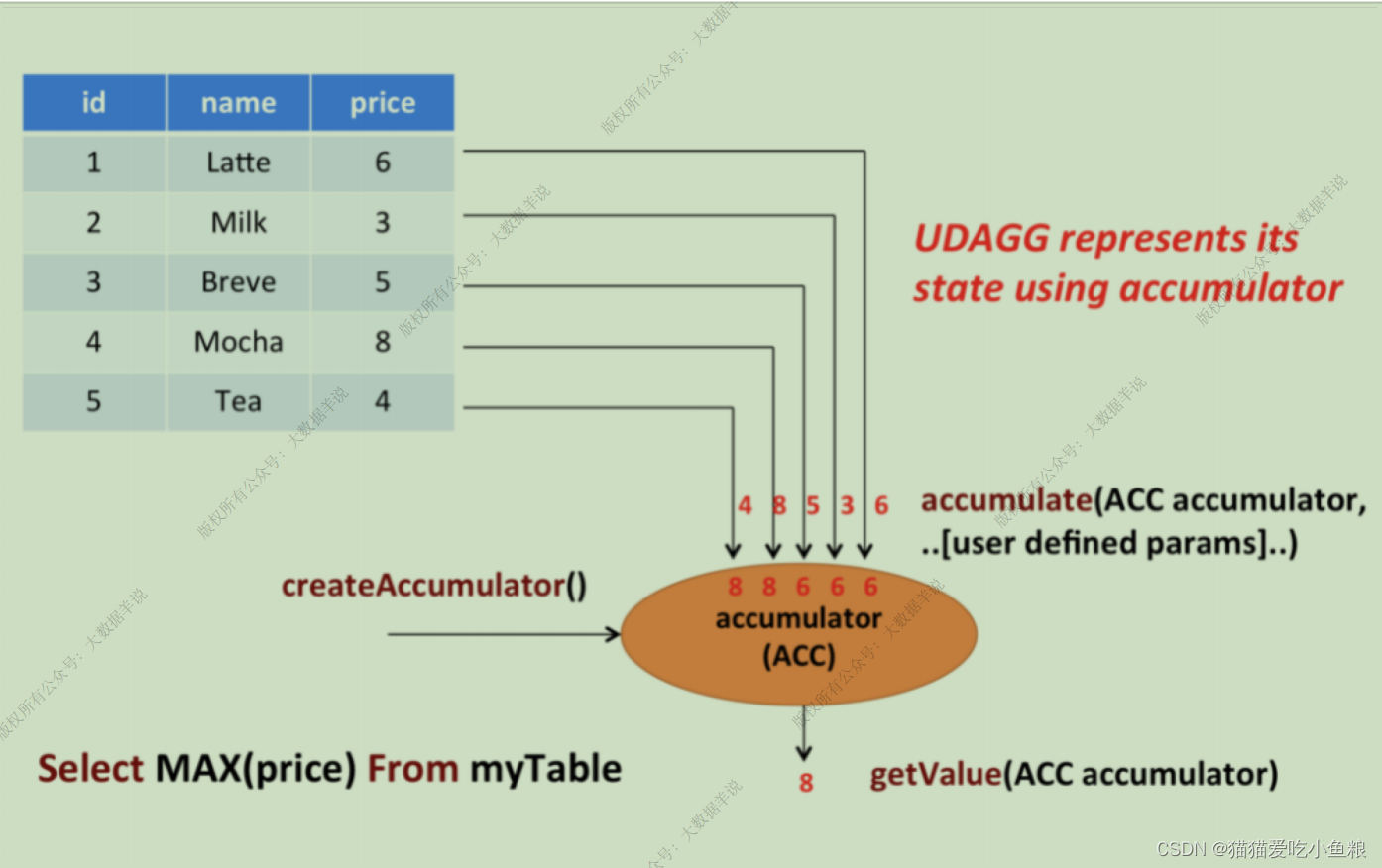
上图展示了⼀个 聚合函数的例⼦ 以及 聚合函数包含的重要⽅法。
案例场景:
关于饮料的表,有三个字段,分别是 id、name、price,表⾥有 5 ⾏数据,找到所有饮料⾥最贵的饮料的价格,即执⾏⼀个 max() 聚合拿到结果,遍历所有 5 ⾏数据,最终结果就只有⼀个数值。
开发流程:
实现 AggregateFunction 接⼝,其中所有的⽅法必须是 public 的、⾮ static 的;
必须实现以下⽅法:
- Acc聚合中间结果 createAccumulator() : 为当前 Key 初始化⼀个空的 accumulator,其存储了聚合的中间结果,⽐如在执⾏ max() 时会存储当前的 max 值;
- accumulate(Acc accumulator, Input输⼊参数) : 每⼀⾏数据,调⽤ accumulate() ⽅法更新 accumulator,处理每⼀条输⼊数据,方法必须声明为 public 和⾮ static 的,accumulate ⽅法可以重载,⽅法的参数类型可以不同,并且⽀持变⻓参数。
- Output输出参数 getValue(Acc accumulator) : 通过调⽤ getValue ⽅法来计算和返回最终的结果。
某些场景下必须实现:
- retract(Acc accumulator, Input输⼊参数) : 在回撤流的场景下必须实现,在计算回撤数据时调⽤,如果没有实现会直接报错。
- merge(Acc accumulator, Iterable it) : 在批式聚合以及流式聚合中的 Session、Hop 窗⼝聚合场景下必须要实现,此外,这个⽅法对于优化也有帮助,例如,打开了两阶段聚合优化,需要 AggregateFunction 实现 merge ⽅法,在数据 shuffle 前先进⾏⼀次聚合计算。
- resetAccumulator() : 在批式聚合中是必须实现的。
关于⼊参、出参数据类型信息的⽅法:
默认情况下,⽤户的 Input 输⼊参数( accumulate(Acc accumulator, Input输⼊参数) 的⼊参 Input输⼊参数 )、accumulator( Acc聚合中间结果 createAccumulator() 的返回结果)、 Output输出参数数据类型( Output输出参数 getValue(Acc accumulator) 的 Output输出参数 )会被 Flink 使⽤反射获取到。
对于 accumulator 和 Output 输出参数类型,Flink SQL 的类型推导在遇到复杂类型时会推导出错误的结果(注意:Input输⼊参数 因为是上游算⼦传⼊的,类型信息是确认的,不会出现推导错误),⽐如⾮基本类型 POJO 的复杂类型。
同 ScalarFunction 和 TableFunction, AggregateFunction 提供了 AggregateFunction#getResultType() 和AggregateFunction#getAccumulatorType() 指定最终返回值类型和 accumulator 的类型,两个函数的返回值类型是TypeInformation。
- getResultType() : 即 Output 输出参数 getValue(Acc accumulator) 的输出结果数据类型;
- getAccumulatorType() : 即 Acc聚合中间结果 createAccumulator() 的返回结果数据类型。
案例: 加权平均值
- 定义⼀个聚合函数来计算某⼀列的加权平均
- 在 TableEnvironment 中注册函数
- 在查询中使⽤函数
实现思路:
为了计算加权平均值,accumulator 需要存储加权总和以及数据的条数,定义了类 WeightedAvgAccumulator 作为 accumulator,Flink 的 checkpoint 机制会⾃动保存 accumulator,在失败时进⾏恢复,保证精确⼀次的语义。
WeightedAvg(聚合函数)的 accumulate ⽅法有三个输⼊参数,第⼀个是 WeightedAvgAccum accumulator,另外两个是⽤户⾃定义的输⼊:输⼊的值 ivalue 和 输⼊的权重 iweight,尽管 retract()、merge()、resetAccumulator() ⽅法在⼤多数聚合类型中都不是必须实现的,但在样例中提供了他们的实现,并且定义了 getResultType() 和 getAccumulatorType()。
代码案例:
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.AggregateFunction;import java.io.Serializable;import static org.apache.flink.table.api.Expressions.$;
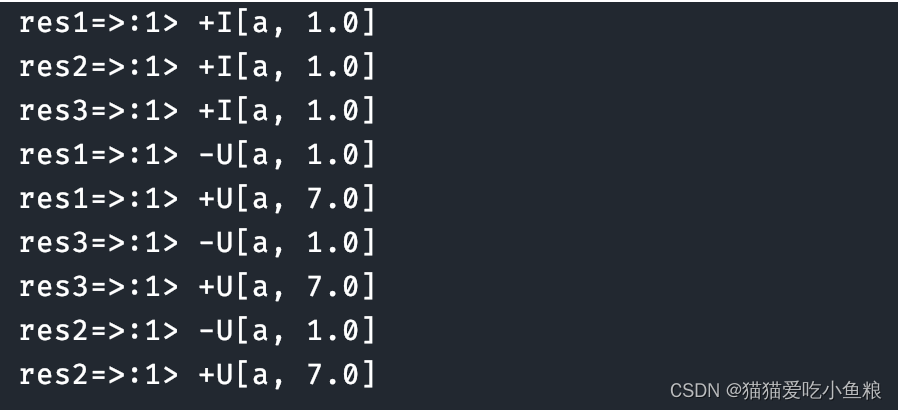
import static org.apache.flink.table.api.Expressions.call;/*** 输入数据:* a,1,1* a,10,2** 输出结果:* res1=>:1> +I[a, 1.0]* res2=>:1> +I[a, 1.0]* res3=>:1> +I[a, 1.0]** res1=>:1> -U[a, 1.0]* res1=>:1> +U[a, 7.0]* res3=>:1> -U[a, 1.0]* res3=>:1> +U[a, 7.0]* res2=>:1> -U[a, 1.0]* res2=>:1> +U[a, 7.0]*/
public class AggregateFunctionTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);DataStreamSource<String> source = env.socketTextStream("localhost", 8888);SingleOutputStreamOperator<Tuple3<String, Double, Double>> tpStream = source.map(new MapFunction<String, Tuple3<String, Double, Double>>() {@Overridepublic Tuple3<String, Double, Double> map(String input) throws Exception {return new Tuple3<>(input.split(",")[0],Double.parseDouble(input.split(",")[1]),Double.parseDouble(input.split(",")[2]));}});Table table = tEnv.fromDataStream(tpStream, "field,iValue,iWeight");tEnv.createTemporaryView("SourceTable", table);Table res1 = tEnv.from("SourceTable").groupBy($("field")).select($("field"), call(WeightedAvg.class, $("iValue"), $("iWeight")));// 注册函数tEnv.createTemporarySystemFunction("WeightedAvg", WeightedAvg.class);// Table API 调⽤函数Table res2 = tEnv.from("SourceTable").groupBy($("field")).select($("field"), call("WeightedAvg", $("iValue"), $("iWeight")));// SQL API 调⽤函数Table res3 = tEnv.sqlQuery("SELECT field, WeightedAvg(`iValue`, iWeight) FROM SourceTable GROUP BY field");tEnv.toChangelogStream(res1).print("res1=>");tEnv.toChangelogStream(res2).print("res2=>");tEnv.toChangelogStream(res3).print("res3=>");env.execute();}// ⾃定义⼀个计算权重 avg 的 accmulatorpublic static class WeightedAvgAccumulator implements Serializable {public Double sum = 0.0;public Double count = 0.0;}// 输⼊:Long iValue, Integer iWeightpublic static class WeightedAvg extends AggregateFunction<Double, WeightedAvgAccumulator> {// 创建⼀个 accumulator@Overridepublic WeightedAvgAccumulator createAccumulator() {return new WeightedAvgAccumulator();}public void accumulate(WeightedAvgAccumulator acc, Double iValue, Double iWeight) {acc.sum += iValue * iWeight;acc.count += iWeight;}public void retract(WeightedAvgAccumulator acc, Double iValue, Double iWeight) {acc.sum -= iValue * iWeight;acc.count -= iWeight;}// 获取返回结果@Overridepublic Double getValue(WeightedAvgAccumulator acc) {if (acc.count == 0) {return null;} else {return acc.sum / acc.count;}}// Session window 使⽤这个⽅法将⼏个单独窗⼝的结果合并public void merge(WeightedAvgAccumulator acc, Iterable<WeightedAvgAccumulator> it) {for (WeightedAvgAccumulator a : it) {acc.count += a.count;acc.sum += a.sum;}}public void resetAccumulator(WeightedAvgAccumulator acc) {acc.count = 0.0;acc.sum = 0.0;}}
}
测试结果:







![论文阅读[121]使用CAE+XGBoost从荧光光谱中检测和识别饮用水中的有机污染物](https://img-blog.csdnimg.cn/5c7b9b90e3ba4c12a806aedc4d9c1e8c.png)