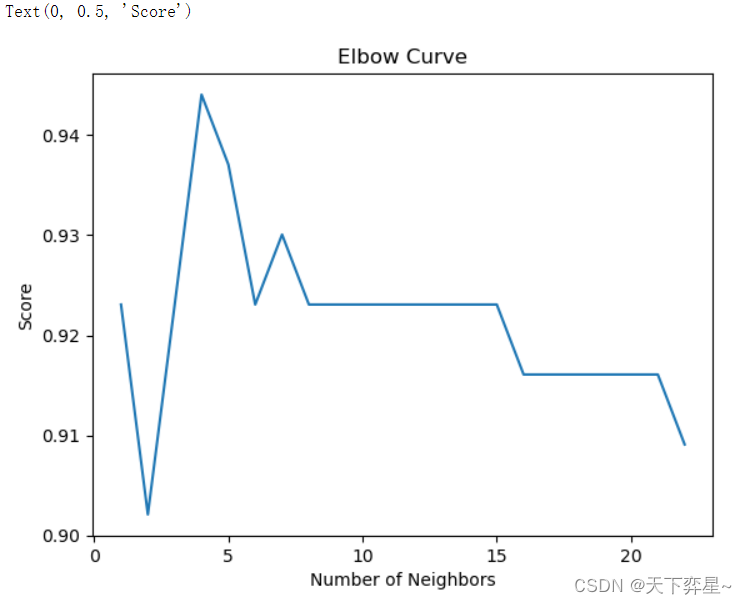
随着大模型带来的应用需求提升,最近以来多家海外知名向量数据库创业企业传出融资喜讯。 随着AI时代的到来,向量数据库市场空间巨大,目前处于从0-1阶段,预测到2030年,全球向量数据库市场规模有望达到500亿美元,国内向量数据库市场规模有望超过600亿人民币。
今天我们一起来简单聊一聊什么是向量数据库!
目录
一、了解向量数据库
二、其他主流向量数据库对比
三、向量数据库的应用场景
四、个人总结
一、了解向量数据库
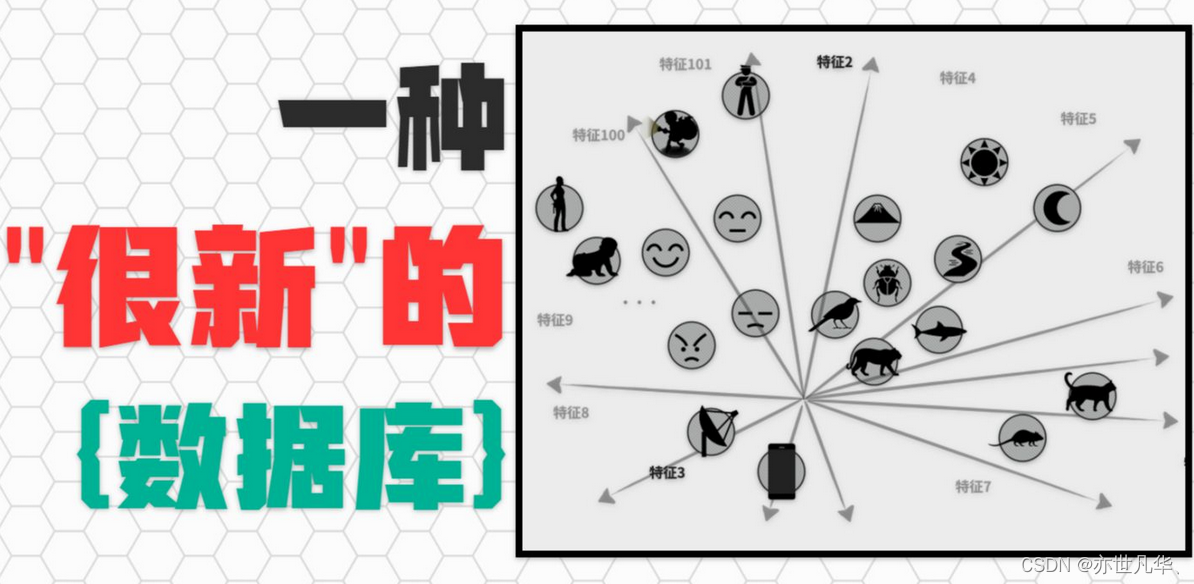
向量数据库是什么:在我们讨论向量数据库之前,我们必须先搞懂向量数据库,那么向量数据库是什么呢?简单来说向量数据库就是一种专门用于处理和查询向量数据的数据库,与传统数据库以表格形式组织和存储数据不同,向量数据库采用多维数值数组的形式处理和存储数据。其主要目标支持高效的向量相似性搜索和查询。
因此向量数据库在人脸识别、图像搜索、视频分析、语言识别、推荐系统等领域有着广泛的应用。它能实现高效的数据检索与分析,具备 “记忆” 功能,这是传统数据库所无法实现的,如果说大语言模型为我们带来了未来世界的一点光辉,那么向量数据库就是打开未来世界之门的钥匙!
接下来我们以亚马逊云科技向量引擎 Amazon OpenSearch Serverless 为例展开我们今天的话题:
亚马逊云科技宣布退出 Amazon OpenSearch Serverless 向量引擎预览版,该向量引擎在Amazon OpenSearch Serverless 中提供了一种简单、可扩展、高性能的相似性搜索功能,让用户能够轻松构建由现代化机器学习(ML)增强的搜索体验和生成式AI应用程序无需管理底层向量数据库基础设施,构建于 Amazon OpenSearch Serverless 的向量引擎天然具备鲁棒性,使用向量数据库用户不必担心后端基础设施的选型、调优和扩展问题,因为大语言模型在处理文本数据时,常常将文本转换为高维向量,这些向量规模庞大。传统的数据库系统难以高效存储与查询,向量数据库专为存储和查询向量数据而设计,能够提供高效的数据存储和检索功能。其官方网址:跳转链接 :

亚马逊云科技向量引擎为索引和工作负载搜索提供了单独的计算资源,让用户可以实时无缝地获取更新和删除向量,同时确保用户查询性能丝毫不受影响,通过向量数据库提供的高效向量计算和查询功能,可以加速模型的训练和推理过程,提高模型的训练速度和推理效率;向量数据库也提供了向量相似度计算的能力,可以支持更加智能的文本匹配和语义搜索,提升用户体验。跳转链接 :

除了上述亚马逊云科技向量引擎对于大语言模型的 “大脑作用” 之外,向量引擎支持相同的 Open Search 开源套件API,而且通过集成 LangChain Amazon Bedrock 和 Amazon SageMaker 用户可以轻松地将首选机器学习和AI系统与向量数据库引擎集成,以上功能还只是该向量引擎的预览版的功能就已经看出其性能的 “鲁棒性”,以及其对大语言模型不可或缺的作用。
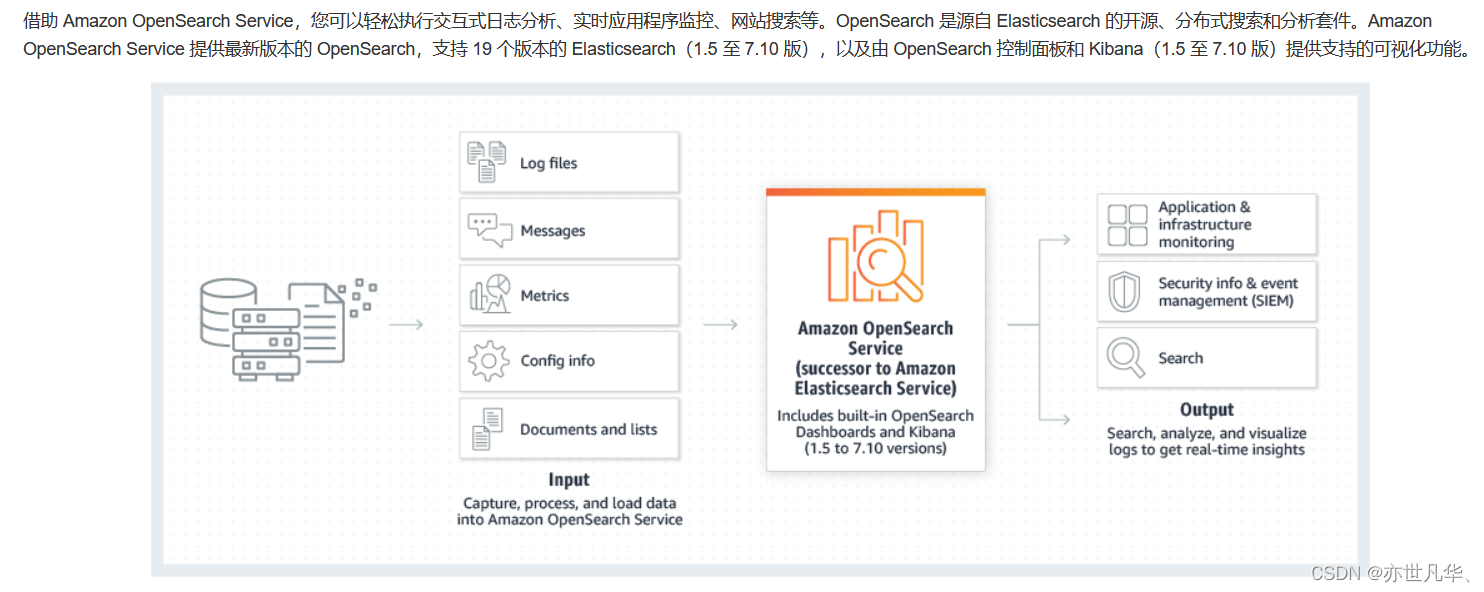
在可以预期的未来几年内,亚马逊云科技向量引擎正式版就可能即将问世,其在优化向量图的性能和内存使用,包括改进缓存和合并等功能方面将要展现出怎样强大的能力,让我们拭目以待!
二、其他主流向量数据库对比
国内有许多主流的向量数据库供应商,它们在不同的应用场景和技术特点上都有各自的优势。接下来将对这些主流向量数据库进行对比,帮助您了解它们的特点、功能和适用性,从而为您在选择合适的向量数据库时提供参考。
Tencent Cloud Vector DB:腾讯云正式发布AI原生向量数据库,该数据库能够被广泛应用于大模型的训练、推理和知识库补充等场景。是国内首个从接入层、计算层到存储层提供全生命周期AI化的向量数据库。腾讯云向量数据库最高支持10亿级向量检索规模,延迟控制在毫秒级,相比传统单机插件式数据库检索规模提升10倍,同时具备百万级每秒查询的峰值能力。跳转链接 :
Elasticsearch:由百度Elasticsearch团队自主开发向量引擎,专用于存储、检索、分析多维向量数据。支持多种索引类型和相似度计算方法,支持构建十亿级向量规模,实现毫秒级延迟。不仅能为文心等大模型提供外部知识库能力,提高大模型回答的准确性和时效性,还可广泛应用于推荐系统、问答系统、语义检索、智能客服等领域。跳转链接 :

Milvus:Zilliz公司推出的开源的向量数据库引擎,旨在支持大规模向量相似度搜索和相似度计算。它提供高效的向量索引与检索功能,适用于各种人工智能、数据挖掘和大数据分析应用。基于 FAISS、Annoy、HNSW 等向量搜索库构建,核心是解决稠密向量相似度检索的问题。跳转链接
当然还有其他一些流行的向量数据库,包括Faiss、Annoy和Pinecone等,如下简单介绍一下:
Faiss:由Facebook AI Research开发的一种高效的向量搜索和聚类工具库。可以处理大规模的数据,并且可以在CPU和GPU上进行高效的计算。主要优点是它的搜索速度非常快,这使得它在处理大规模的数据时非常有优势。缺点是它不支持在线的数据更新,这意味着如果我们需要添加或删除数据,我们可能需要重新构建整个索引。
Annoy:由Spotify开发的一种高效的向量搜索库,它可以在内存中存储大量的向量,并且可以快速地进行向量搜索。主要优点是它的内存使用效率非常高,这使得它在处理大规模的数据时非常有优势。缺点是它不支持在线的数据更新,这意味着如果我们需要添加或删除数据,我们可能需要重新构建整个索引。
Pinecone:是一种全托管的向量搜索服务,它可以处理大规模的数据,并且可以在云端进行高效的计算。主要优点是它的易用性,用户无需关心底层的实现细节,只需要通过API就可以进行向量搜索。缺点是它是一种付费服务,对于一些小型项目或个人用户来说,成本可能会比较高。
在市场上有许多流行的向量数据库,这些数据库各有优缺点,我们需要根据我们的具体需求和应用场景来选择最适合的向量数据库。
三、向量数据库的应用场景
向量数据库在不同领域的广泛应用场景。随着大数据和人工智能的快速发展,数据的向量化表示和处理变得越来越重要。而向量数据库作为一种创新的数据库技术,以其高效的向量索引和查询能力,在各种领域中展现出巨大的潜力。

以图像识别为例,向量数据库在图像搜索和相似度匹配方面的应用。通过将图像转化为向量表示,并利用向量数据库的高效索引和查询功能,我们可以实现快速准确的图像搜索,从海量图像库中找到与目标图像相似的图片。

四、个人总结
选择哪种类型的数据库取决于我们的具体需求和应用场景。无论是关系数据库、非关系数据库,还是向量数据库,它们都是我们数据处理工具箱中的重要工具,我们需要根据实际情况选择最适合的工具。
我们选择现在的向量数据库的原因主要是因为其有以下主要特点:
高效的向量索引和查询:
向量数据库能够将向量数据进行高效的索引和查询,使得在大规模数据集中快速找到相似的向量成为可能。这对于图像识别、文本处理等领域的相似度匹配和搜索任务非常有用。
支持复杂的数据关系:
向量数据库能够处理和分析复杂的数据关系,包括多维度的相似度计算和查询。这使得在推荐系统、广告推荐等领域中可以更好地理解用户和物品之间的关系,提供更精准的推荐和个性化服务。
多领域应用:
向量数据库在多个领域中都具有广泛的应用潜力,如图像识别、自然语言处理、推荐系统等。通过将不同领域的数据向量化表示,并利用向量数据库的功能,可以实现高效的数据处理和分析。
虽然向量数据库具有许多优点和潜力,但在实际应用中也需要权衡其与传统数据库相比的一些缺点和挑战:
存储和计算开销:
向量数据库通常需要消耗较大的存储和计算资源来存储和处理向量数据。特别是在处理大规模数据集时,可能需要更高的硬件成本和更复杂的系统架构来支持。
向量化表示的挑战:
将原始数据向量化表示是使用向量数据库的前提,但有时候向量化过程可能面临一定的挑战。如何选择合适的向量化方法和参数,以及如何处理高维度和稀疏数据等问题都需要仔细考虑和解决。
更新和维护的复杂性:
如果数据集经常更新或变动,向量数据库需要能够及时处理新增和修改的数据。这可能涉及到索引的更新和维护,需要考虑如何平衡数据更新和查询性能之间的关系。
向量数据库针对具体的应用场景,还需要进行仔细的评估和选择,以确保最佳的性能和效果。如果你也对向量数据库感兴趣,欢迎来尝试一下吧!