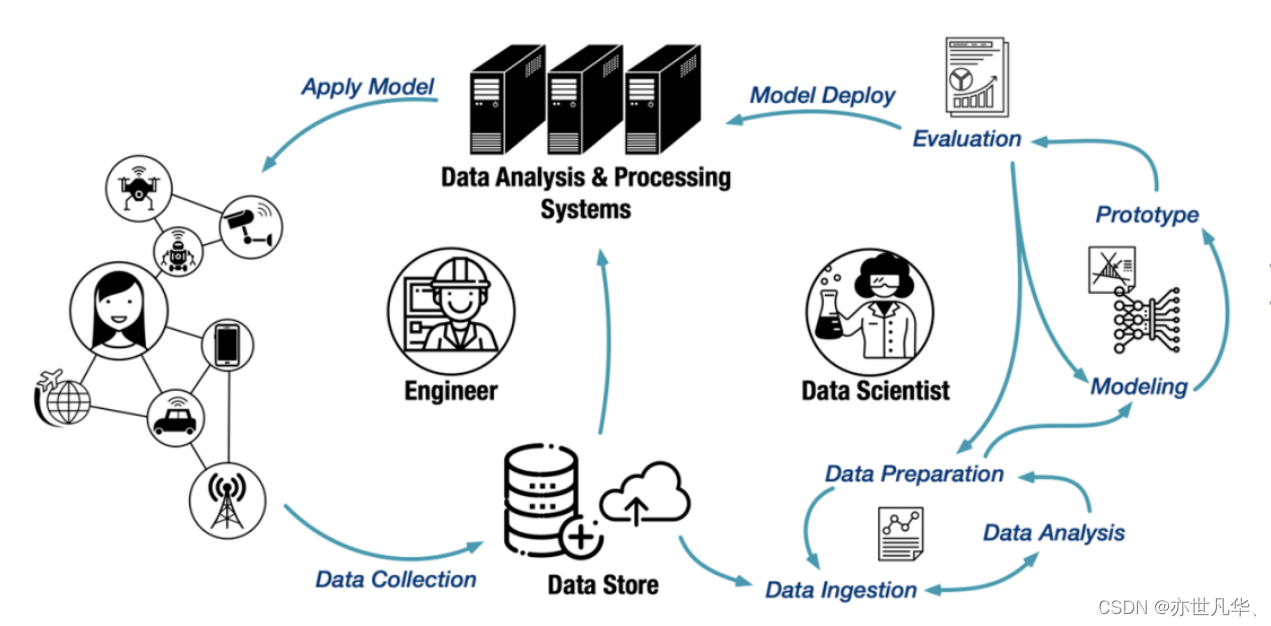
Ruby 爬虫程序如下:
require 'open-uri'
require 'nokogiri'# 定义代理信息
proxy_host = 'jshk.com.cn'# 定义要爬取的网页 URL
url = 'http://www.example.com'# 使用代理信息打开网页
open-uri.with_proxy(proxy_host, proxy_port) do |proxy|# 使用 Nokogiri 库解析网页内容doc = Nokogiri::HTML(proxy.open(url))
end
代码解释:
-
首先,我们引入了两个 Ruby 模块,即
open-uri和nokogiri。open-uri模块用于打开网络资源,nokogiri模块用于解析 HTML 文档。 -
然后,我们定义了代理信息,即代理服务器的主机名和端口号。
-
接着,我们定义了要爬取的网页 URL。
-
使用
open-uri.with_proxy方法打开网页,其中第一个参数是代理服务器的主机名,第二个参数是代理服务器的端口号。在with_proxy方法内部,我们使用proxy.open方法打开网页。 -
使用
Nokogiri::HTML方法解析打开的网页内容。