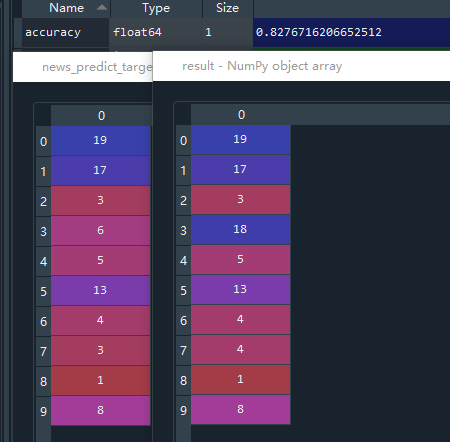
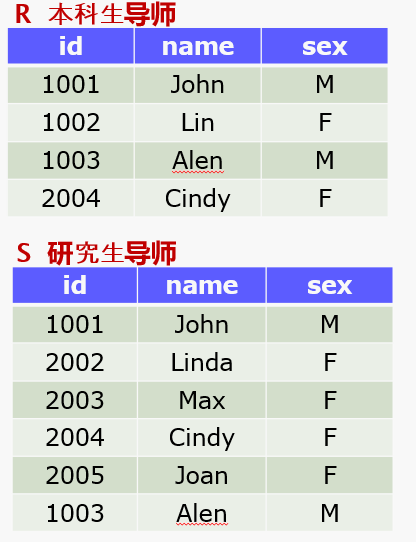
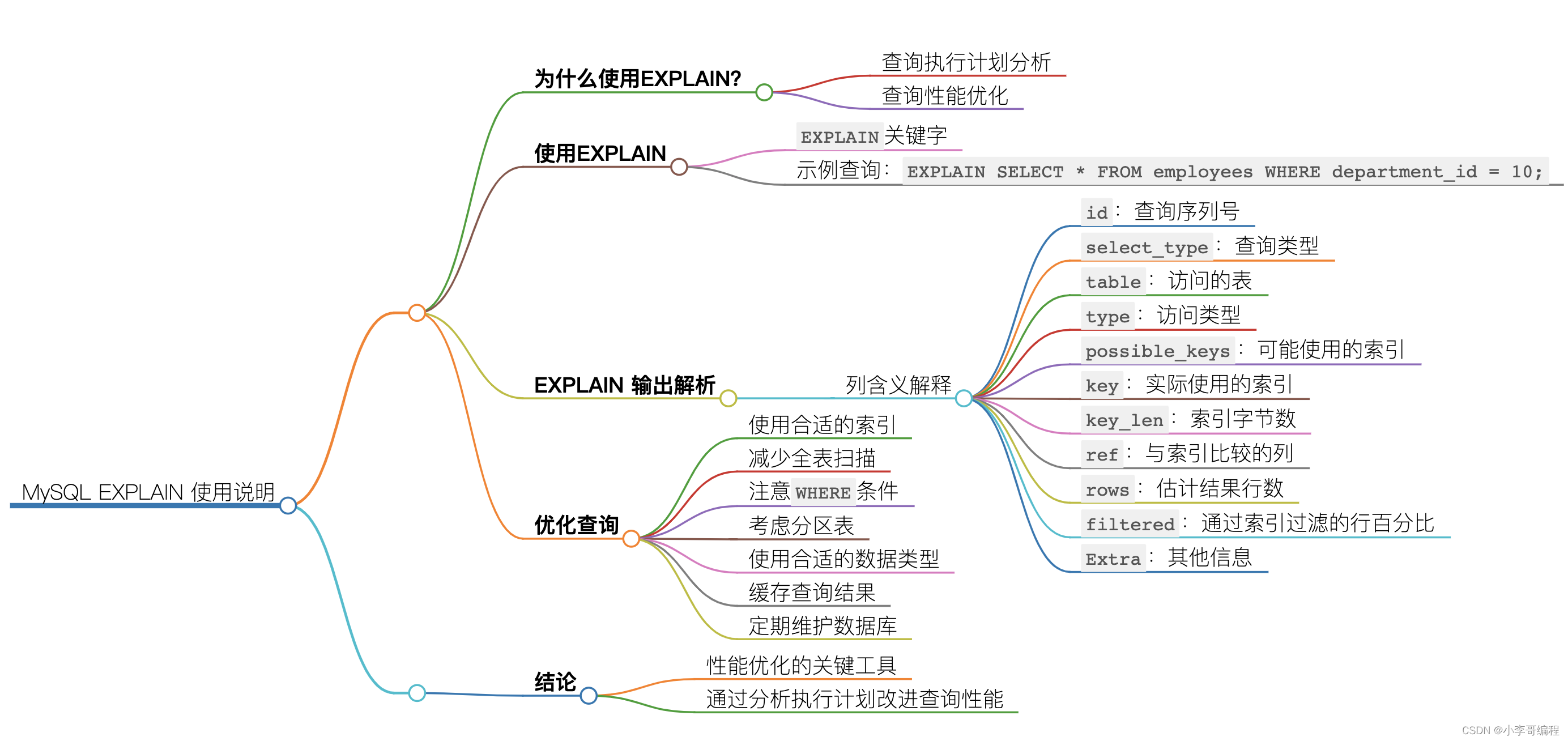
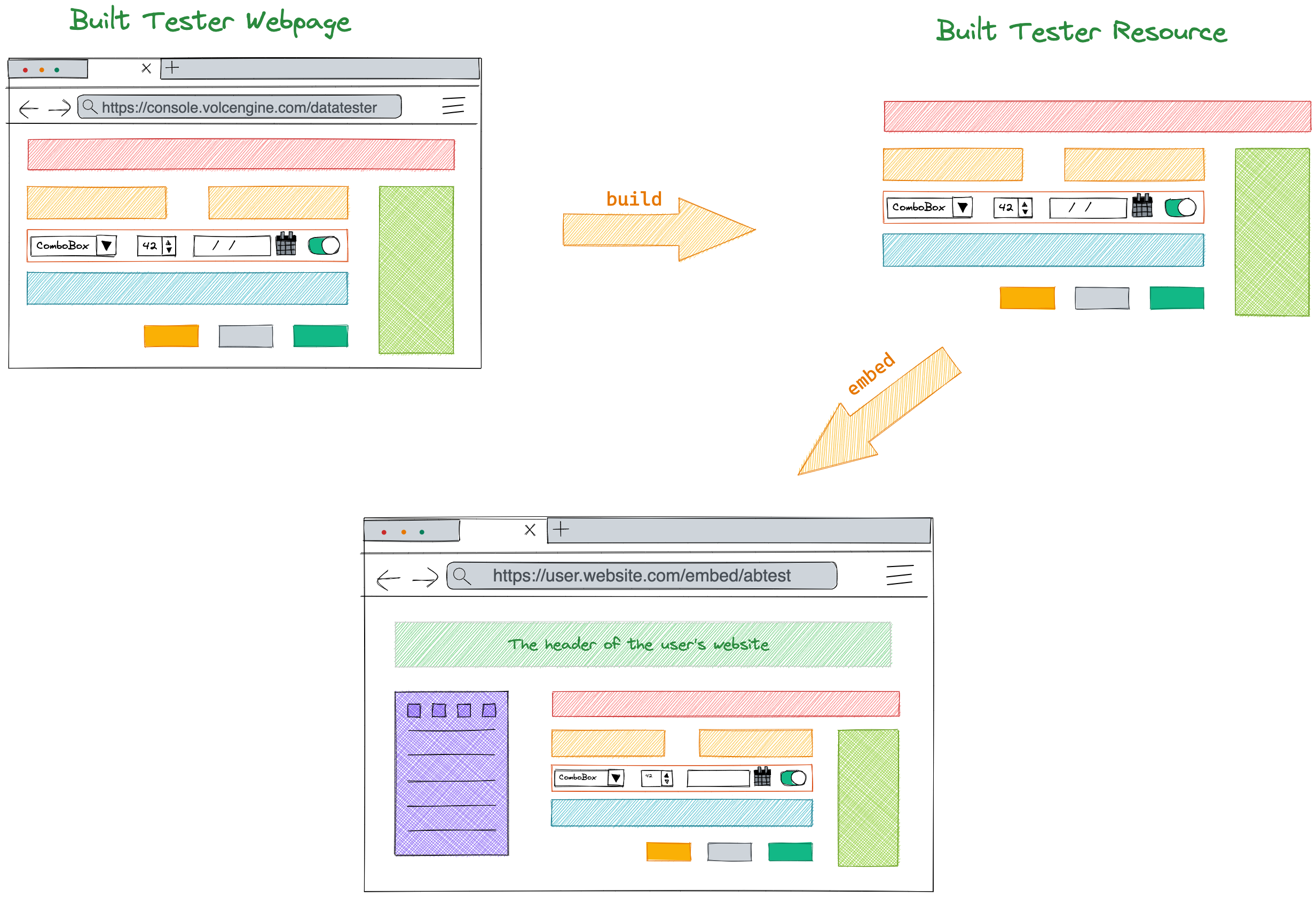
以下是一个简单的Python爬虫程序,用于爬取商户的内容。这个程序使用了requests和BeautifulSoup库来进行网络请求和内容解析。

import requests
from bs4 import BeautifulSoup# 爬虫爬虫IP信息
proxy_host = 'duoip'
proxy_port = '8000'# 请求URL
url = '目标网站'# 创建一个requests的Session对象,并设置爬虫IP
session = requests.Session()
session.proxies = {'http': f'http://{proxy_host}:{proxy_port}','https': f'https://{proxy_host}:{proxy_port}'
}# 发送GET请求,获取网页内容
response = session.get(url)
response.encoding = 'utf-8'# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')# 找到所有的商品内容
items = soup.find_all('div', class_='item')# 打印商品内容
for item in items:print(item.text)
注:这个程序只是一个简单的示例,实际的爬虫程序需要根据具体的网页结构和需要爬取的数据进行调整。此外,使用爬虫IP需要注意遵守相关法律法规和网站的使用协议。