切换到postgresql数据库,各种不适应吧。
有个需求需要查询数据表的各种信息。
下面我们一起学习吧。
●PostgreSQL: Documentation
PostgreSQL: Documentation
●pg_namespace
存储名字空间。名字空间是 SQL 模式下层的结构:每个名字空间有独立的关系, 类型等集合但并不会相互冲突。
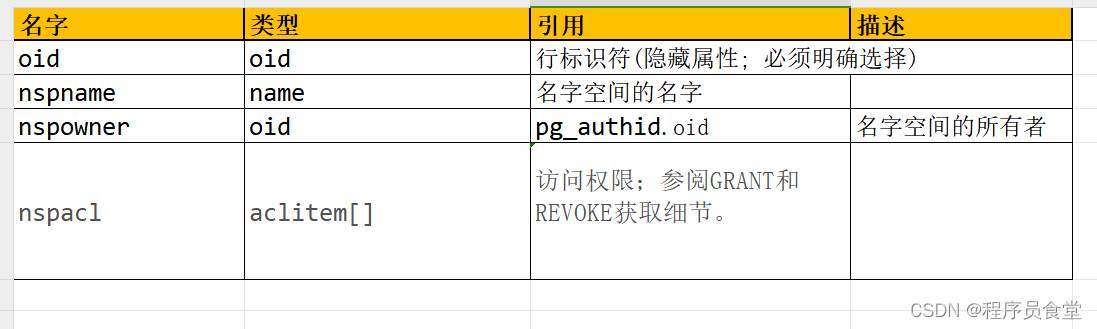
OID
在PostgreSQL中,对象标识符Object identifiers (OIDs) 用来在整个数据集簇中唯一的标识一个数据库对象,这个对象可以是数据库、表、索引、视图、元组、类型等等。
OID的分配由系统中的一个全局OID计数器来实现,OID分配时会采用互斥锁加以锁定以避免多个要求分配OID的请求获得相同的OID。
sql
select * from pg_namespace WHERE nspname ='screen';
●pg_tables
pg_tables 提供了对有关数据库中每个表的有用信息地访问。
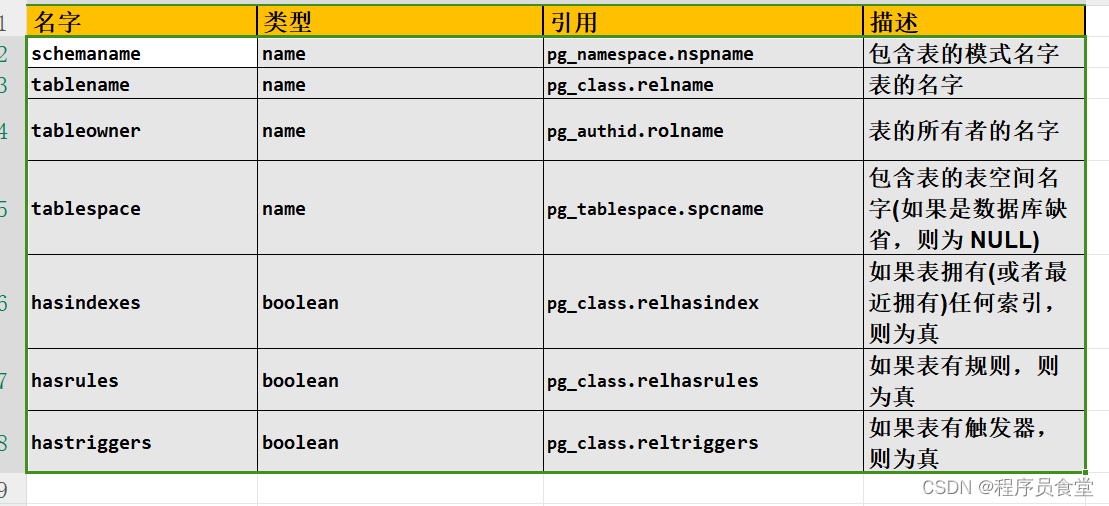
SQl
select * from pg_tables where schemaname = 'creen' and tablename = 'title';
●pg_class
pg_class表记载表和几乎所有有字段或者是那些类似表的东西。 包括索引(不过还要参阅pg_index)、序列、视图、物化视图、 复合类型和一些特殊关系类型;
| 名字 | 类型 | 引用 | 描述 |
| oid | oid | 行标识符(隐藏属性; 必须明确选择) | |
| relname | name | 表、索引、视图等的名字。 | |
| relnamespace | oid | pg_namespace.oid | 包含这个关系的名字空间(模式)的 OID |
| reltype | oid | pg_type.oid | 如果有,则为对应这个表的行类型的数据类型的OID(索引为零,它们没有pg_type记录)。 |
| reloftype | oid | pg_type.oid | 对于类型表,为底层复合类型的OID,对于所有其他关系为0 |
| relowner | oid | pg_authid.oid | 关系所有者 |
| relam | oid | pg_am.oid | 如果行是索引,那么就是所用的访问模式(B-tree, hash 等等) |
| relfilenode | oid | 这个关系在磁盘上的文件的名字,0表示这是一个"映射的"关系, 它的文件名取决于行级别的状态 | |
| reltablespace | oid | pg_tablespace.oid | 这个关系存储所在的表空间。如果为零,则意味着使用该数据库的缺省表空间。 如果关系在磁盘上没有文件,则这个字段没有什么意义。 |
| relpages | int4 | 以页(大小为BLCKSZ)的此表在磁盘上的形式的大小。 它只是规划器用的一个近似值,是由VACUUM,ANALYZE 和几个 DDL 命令,比如CREATE INDEX更新。 | |
| reltuples | float4 | 表中行的数目。只是规划器使用的一个估计值,由VACUUM,ANALYZE 和几个 DDL 命令,比如CREATE INDEX更新。 | |
| relallvisible | int4 | 在表的可见映射中标记所有可见的页的数目。只是规划器使用的一个估计值, 由VACUUM,ANALYZE 和几个 DDL 命令,比如CREATE INDEX更新。 | |
| reltoastrelid | oid | pg_class.oid | 与此表关联的 TOAST 表的 OID ,如果没有为 0 。TOAST 表在一个从属表里"离线"存储大字段。 |
| reltoastidxid | oid | pg_class.oid | 对于 TOAST 表是它的索引的 OID ,如果不是 TOAST 表则为 0 |
| relhasindex | bool | 如果它是一个表而且至少有(或者最近有过)一个索引,则为真。 | |
| relisshared | bool | 如果该表在整个集群中由所有数据库共享则为真。只有某些系统表 (比如pg_database)是共享的。 | |
| relpersistence | char | p = permanent table(永久表), u = unlogged table(未加载的表), t = temporary table (临时表) | |
| relkind | char | r = ordinary table(普通表), i = index(索引), S = sequence(序列), v = view(视图), m = materialized view(物化视图), c = composite type(复合类型), t = TOAST table(TOAST 表), f = foreign table(外部表) | |
| relnatts | int2 | 关系中用户字段数目(除了系统字段以外)。在pg_attribute 里肯定有相同数目对应行。又见pg_attribute.attnum。 | |
| relchecks | int2 | 表里的CHECK约束的数目;参阅pg_constraint表 | |
| relhasoids | bool | 如果为关系中每行都生成一个 OID 则为真 | |
| relhaspkey | bool | 如果这个表有一个(或者曾经有一个)主键,则为真。 | |
| relhasrules | bool | 如表有(或曾经有)规则就为真;参阅pg_rewrite表 | |
| relhastriggers | bool | 如果表有(或者曾经有)触发器,则为真;参阅pg_trigger表 | |
| relhassubclass | bool | 如果有(或者曾经有)任何继承的子表,为真。 | |
| relispopulated | bool | 如果关系是填充的则为真(对所有关系为真,除了一些物化视图) | |
| relfrozenxid | xid | 该表中所有在这个之前的事务 ID 已经被一个固定的("frozen")事务 ID 替换。 这用于跟踪该表是否需要为了防止事务 ID 重叠或者允许收缩pg_clog 而进行清理。如果该关系不是表则为零(InvalidTransactionId)。 | |
| relminmxid | xid | 该表中所有在这个之前的多事务 ID 已经被一个事务 ID 替换。 这用于跟踪该表是否需要为了防止多事务 ID 重叠或者允许收缩pg_clog 而进行清理。如果该关系不是表则为零(InvalidTransactionId)。 | |
| relacl | aclitem[] | 访问权限。参阅GRANT和REVOKE获取详细信息。 | |
| reloptions | text[] | 访问方法特定的选项,使用"keyword=value"格式的字符串 |
SQl
select * from pg_class where relname = 'title' ;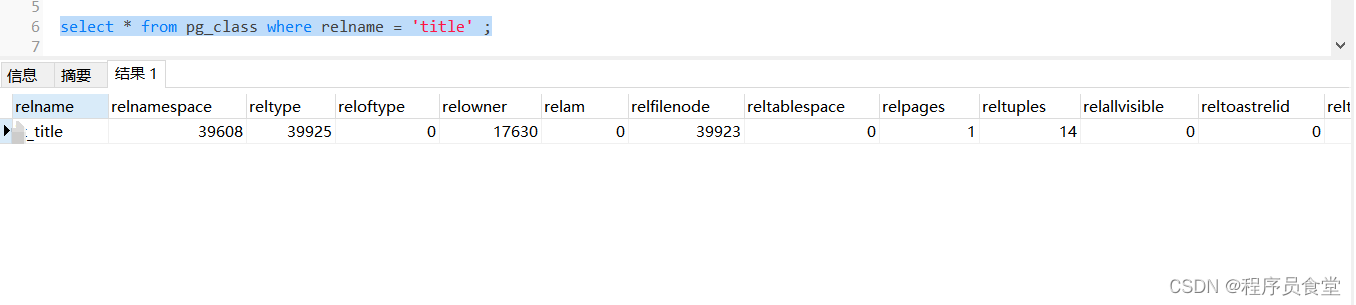
● pg_description
pg_description表可以给每个数据库对象存储一个可选的描述(注释)。 你可以用COMMENT命令操作这些描述,并且可以用psql 的\d命令查看。许多内置的系统对象的描述提供了 pg_description的初始内容。
pg_shdescription 提供了类似的功能,它记录了整个集群范围内共享对象的注释。
| 名字 | 类型 | 引用 | 描述 |
| objoid | oid | 任意 oid 属性 | 这条描述所描述的对象的 OID |
| classoid | oid | pg_class.oid | 这个对象出现的系统表的 OID |
| objsubid | int4 | 对于一个表字段的注释,它是字段号(objoid和classoid 指向表自身)。对于其它对象类型,它是零。 | |
| description | text | 作为对该对象的描述的任意文本 |
SQl
select * from pg_description
where objoid = to_regclass('screen' || '.' || 'title')::REGCLASS::OID;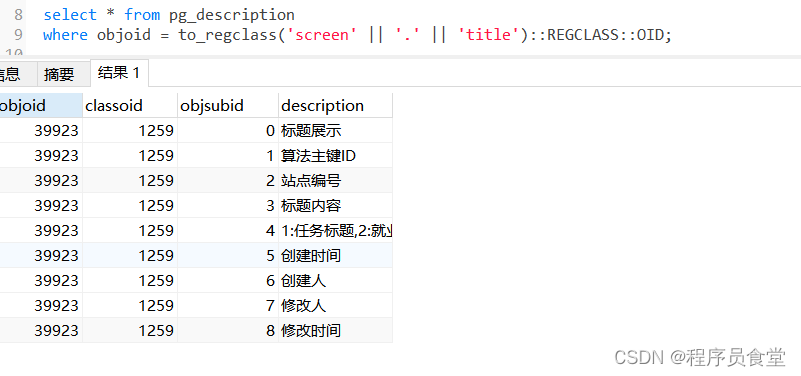
● columns
视图columns包含有关数据库中所有表字段(或者视图字段)的信息。 不包括系统字段(比如oid等)。只有那些当前用户有权访问的字段才会显示出来 (要么是所有者,要么是有些权限)。
| 名字 | 数据类型 | 描述 |
| table_catalog | sql_identifier | 包含表的数据库的名字(总是当前数据库) |
| table_schema | sql_identifier | 包含表的模式的名字 |
| table_name | sql_identifier | 表的名字 |
| column_name | sql_identifier | 字段的名字 |
| ordinal_position | cardinal_number | 字段在表中的位置序号(从 1 开始) |
| column_default | character_data | 字段的缺省表达式 |
| is_nullable | yes_or_no | 如果字段可能为空,则为YES,如果知道它不能为空,则为NO。 非空约束是我们得知字段不能为空的一个手段,但是还可能有其它的。 |
| data_type | character_data | 如果它是一个内置类型,那么为字段的数据类型,如果它是某种数组, 则为ARRAY(在这种情况下,参阅视图element_types), 否则就是USER-DEFINED(这时,类型定义在udt_name和相关的字段上)。 如果字段基于域,这个字段引用底层域类型(而域是在domain_name和相关字段里定义的)。 |
| character_maximum_length | cardinal_number | 如果data_type标识一个字符或者位串类型,那么就是声明的最大长度; 如果是其它类型或者没有定义最大长度,就是空。 |
| character_octet_length | cardinal_number | 如果data_type标识一个字符类型,就是以字节记的最大可能长度; 所有其它类型都是空。最大字节长度取决于声明的字节最大长度(见上文)和服务器编码。 |
| numeric_precision | cardinal_number | 如果data_type标识一个数值类型,这个字段包含 (声明的或隐含的)这个字段的数据类型的精度。精度表示有效小数位的长度。 它可以用十进制或者二进制来表示,这一点在numeric_precision_radix 字段里声明。对于其它数据类型,这个字段是空。 |
| numeric_precision_radix | cardinal_number | 如果data_type标识一个数值类型,这个字段标识字段 numeric_precision和numeric_scale 里的数据是多少进制的。值要么是 2 要么是 10。对于所有其它数据类型,这个字段是空。 |
| numeric_scale | cardinal_number | 如果data_type标识一个精确的数值类型, 那么这个字段包含(声明的或者隐含的)这个字段上这个类型的数值范围。 数值范围表明小数点右边的有效小数位的数目。它可以用十进制(10为基) 或者二进制(二为基)来表示,正如字段numeric_precision_radix 声明的那样。对于所有其它数据类型,这个字段是空。 |
| datetime_precision | cardinal_number | 如果data_type标识一个日期,时间,时间戳,或者间隔类型, 该字段(公开地或隐含地)包含该字段类型的小数秒精度,就是说, 小数位数保持到小数点后面。对于所有其它的数据类型,该字段是null。 |
| interval_type | character_data | 如果data_type标识一个间隔类型,这个字段包含这个字段时间间隔声明, 例如,YEAR TO MONTH, DAY TO SECOND等等。 如果没有指定字段限制(也就是,间隔接受所有字段),或对于所有其他数据类型,这个字段是null。 |
| interval_precision | cardinal_number | 用于一个PostgreSQL不可用的特性 (参阅datetime_precision获取间隔类型字段的小数秒精度) |
| character_set_catalog | sql_identifier | 用于PostgreSQL里一个不可用的特性 |
| character_set_schema | sql_identifier | 用于PostgreSQL里一个不可用的特性 |
| character_set_name | sql_identifier | 用于PostgreSQL里一个不可用的特性 |
| collation_catalog | sql_identifier | 包含该字段的排序规则的数据库的名字(总是当前数据库),缺省或者字段的数据类型不可排序时为null。 |
| collation_schema | sql_identifier | 包含该字段的排序规则的模式的名字,缺省或者字段的数据类型不可排序时为null。 |
| collation_name | sql_identifier | 字段的排序规则的名字,缺省或者字段的数据类型不可排序时为null。 |
| domain_catalog | sql_identifier | 如果字段是域类型,就是该域定义所在的数据库的名字(总是当前数据库),否则为null。 |
| domain_schema | sql_identifier | 如果字段是域类型,就是域定义所在的模式的名字,否则为null。 |
| domain_name | sql_identifier | 如果字段是域类型,就是该域的名字,否则为null。 |
| udt_catalog | sql_identifier | 这个字段数据类型(如果适用,就是底层域类型)定义所在的数据库的名字(总是当前数据库)。 |
| udt_schema | sql_identifier | 这个字段数据类型(如果适用,就是底层域类型)定义所在的模式名字。 |
| udt_name | sql_identifier | 这个字段数据类型(如果适用,就是底层域类型)的名字。 |
| scope_catalog | sql_identifier | 用于PostgreSQL里一个不可用的特性 |
| scope_schema | sql_identifier | 用于PostgreSQL里一个不可用的特性 |
| scope_name | sql_identifier | 用于PostgreSQL里一个不可用的特性 |
| maximum_cardinality | cardinal_number | 总是空,因为在PostgreSQL里数组总是有无限的最大维数 |
| dtd_identifier | sql_identifier | 一个该字段的数据类型描述符的标识符,在属于这个表中的所有的数据类型描述符中唯一。 这个字段主要用于和其它这样的标识符实例连接。 (这个标识符的确切格式没有定义并且不保证在将来的版本中保持一样。) |
| is_self_referencing | yes_or_no | 用于PostgreSQL里一个不可用的特性 |
| is_identity | yes_or_no | 用于PostgreSQL里一个不可用的特性 |
| identity_generation | character_data | 用于PostgreSQL里一个不可用的特性 |
| identity_start | character_data | 用于PostgreSQL里一个不可用的特性 |
| identity_increment | character_data | 用于PostgreSQL里一个不可用的特性 |
| identity_maximum | character_data | 用于PostgreSQL里一个不可用的特性 |
| identity_minimum | character_data | 用于PostgreSQL里一个不可用的特性 |
| identity_cycle | yes_or_no | 用于PostgreSQL里一个不可用的特性 |
| is_generated | character_data | 用于PostgreSQL里一个不可用的特性 |
| generation_expression | character_data | 用于PostgreSQL里一个不可用的特性 |
| is_updatable | yes_or_no | 如果字段为可更新则为YES,否则为NO (基表中的字段总是可以更新的,而试图中的字段则不一定) |
系统目录信息函数
| 名称 | 返回类型 | 描述 |
| format_type(type_oid, typemod) | text | 获得一个数据类型的 SQL 名字 |
| pg_get_constraintdef(constraint_oid) | text | 获得一个约束的定义 |
| pg_get_constraintdef(constraint_oid, pretty_bool) | text | 获得一个约束的定义 |
| pg_get_expr(pg_node_tree, relation_oid) | text | 反编译一个表达式的内部形式,假定其中的任何 Var 指向由第二个参数指示的关系 |
| pg_get_expr(pg_node_tree, relation_oid, pretty_bool) | text | 反编译一个表达式的内部形式,假定其中的任何 Var 指向由第二个参数指示的关系 |
| pg_get_functiondef(func_oid) | text | 获得一个函数的定义 |
| pg_get_function_arguments(func_oid) | text | 获得一个函数定义的参数列表(带有默认值) |
| pg_get_function_identity_arguments(func_oid) | text | 获得标识一个函数的参数列表(不带默认值) |
| pg_get_function_result(func_oid) | text | 获得函数的RETURNS子句 |
| pg_get_indexdef(index_oid) | text | 获得索引的CREATE INDEX命令 |
| pg_get_indexdef(index_oid, column_no, pretty_bool) | text | 获得索引的CREATE INDEX命令,或者当column_no为非零时只得到一个索引列的定义 |
| pg_get_keywords() | setof record | 获得 SQL 关键字的列表及其分类 |
| pg_get_ruledef(rule_oid) | text | 获得规则的CREATE RULE命令 |
| pg_get_ruledef(rule_oid, pretty_bool) | text | 获得规则的CREATE RULE命令 |
| pg_get_serial_sequence(table_name, column_name) | text | 获得一个serial、smallserial或bigserial列使用的序列的名称 |
| pg_get_triggerdef(trigger_oid) | text | 获得触发器的CREATE [ CONSTRAINT ] TRIGGER命令 |
| pg_get_triggerdef(trigger_oid, pretty_bool) | text | 获得触发器的CREATE [ CONSTRAINT ] TRIGGER命令 |
| pg_get_userbyid(role_oid) | name | 获得给定 OID 指定的角色名 |
| pg_get_viewdef(view_name) | text | 获得视图或物化视图的底层SELECT命令(已废弃) |
| pg_get_viewdef(view_name, pretty_bool) | text | 获得视图或物化视图的底层SELECT命令(已废弃) |
| pg_get_viewdef(view_oid) | text | 获得视图或物化视图的底层SELECT命令 |
| pg_get_viewdef(view_oid, pretty_bool) | text | 获得视图或物化视图的底层SELECT命令 |
| pg_get_viewdef(view_oid, wrap_column_int) | text | 获得视图或物化视图的底层SELECT命令;带域的行被包装成指定的列数,并隐含了优质打印 |
| pg_options_to_table(reloptions) | setof record | 获得存储选项的名称/值对的集合 |
| pg_tablespace_databases(tablespace_oid) | setof oid | 获得在该表空间中有对象的数据库的 OID 的集合 |
| pg_tablespace_location(tablespace_oid) | text | 获得这个表空间所在的文件系统的路径 |
| pg_typeof(any) | regtype | 获得任意值的数据类型 |
| collation for (any) | text | 获得该参数的排序规则 |
| to_regclass(rel_name) | regclass | 获得命名关系的OID |
| to_regproc(func_name) | regproc | 获得命名函数的OID |
| to_regprocedure(func_name) | regprocedure | 获得命名函数的OID |
| to_regoper(operator_name) | regoper | 获得命名操作符的OID |
| to_regoperator(operator_name) | regoperator | 获得命名操作符的OID |
| to_regtype(type_name) | regtype | 获得命名类型的OID |
| to_regnamespace(schema_name) | regnamespace | 获得命名模式的OID |
| to_regrole(role_name) | regrole | 获得命名角色的OID |
查询表的注释
SELECT tb.table_name, d.description
FROM information_schema.tables tbJOIN pg_class c ON c.relname = tb.table_nameLEFT JOIN pg_description d ON d.objoid = c.oid AND d.objsubid = '0'
WHERE tb.table_schema = 'screen';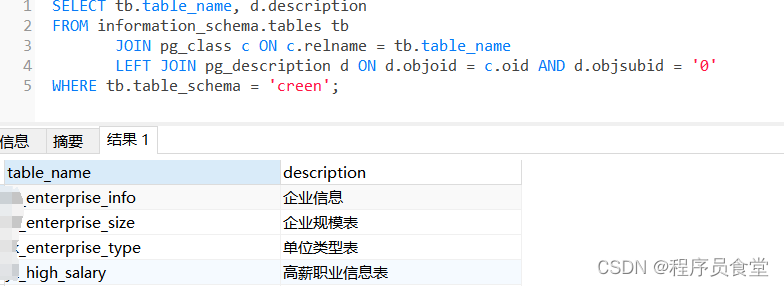
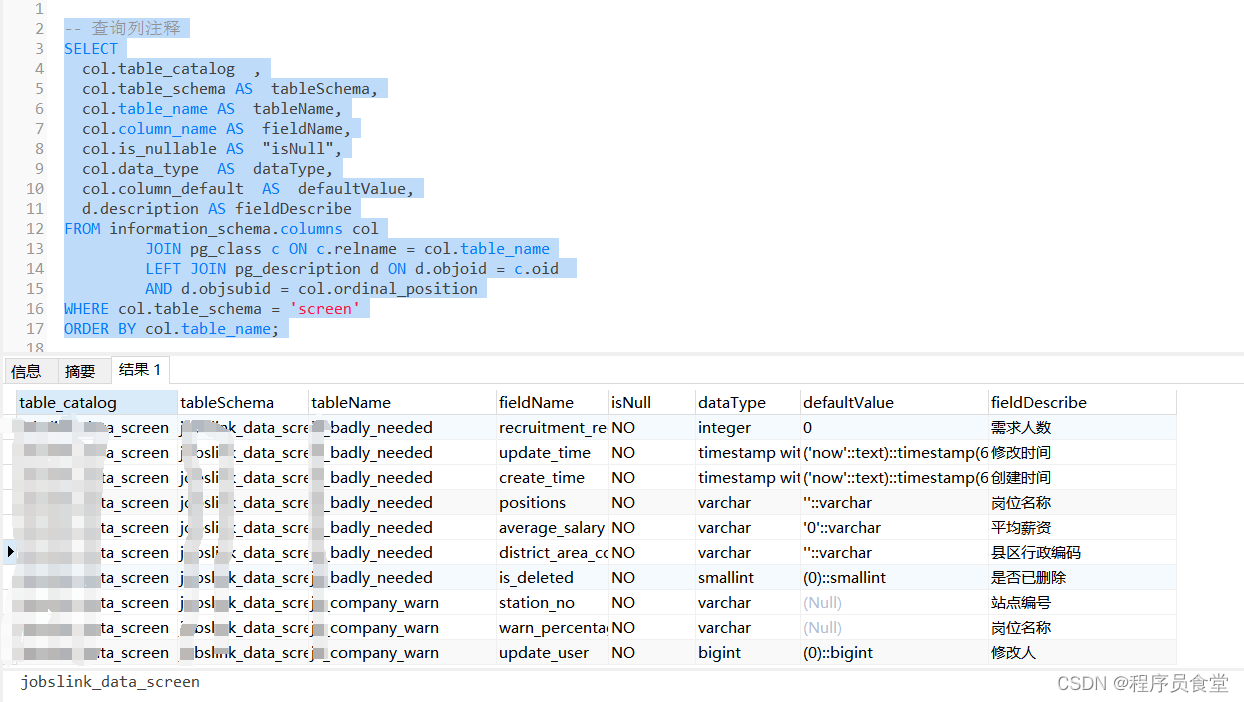
查询列注释
-- 查询列注释
SELECT col.table_catalog,col.table_schema AS tableSchema,col.table_name AS tableName,col.column_name AS fieldName,col.is_nullable AS "isNull",col.data_type AS dataType,col.column_default AS defaultValue,d.description AS fieldDescribe
FROM information_schema.columns colJOIN pg_class c ON c.relname = col.table_nameLEFT JOIN pg_description d ON d.objoid = c.oidAND d.objsubid = col.ordinal_position
WHERE col.table_schema = 'screen'
ORDER BY col.table_name;