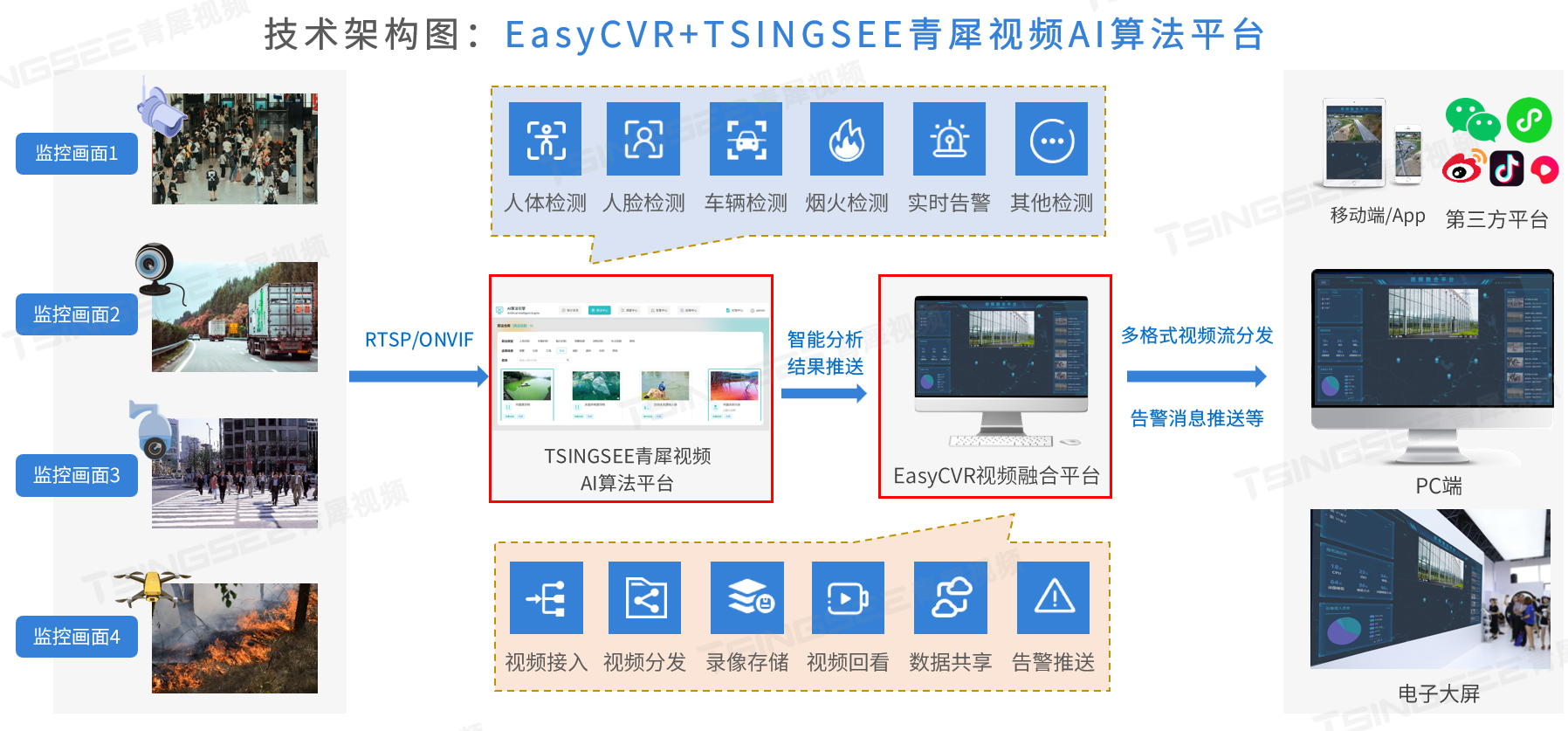
在数据存储和处理领域,HBase作为一种分布式、可扩展的NoSQL数据库,被广泛应用于大规模数据的存储和分析。然而,随着业务需求的变化和技术发展的进步,有时候我们需要将现有的HBase数据迁移到其他环境或存储系统。HBase数据迁移是一个复杂而关键的任务,它涉及到保证数据完整性、准确性和安全性,同时还需要考虑版本兼容性、网络带宽、数据量等因素。从Hbase 本身的设计架构上可以知道 hbase的表是基于 hadoop HDFS 构建,所以一般在迁移Hbase 表数据的时候需要关注到两个维度,hbase层和hdfs层,下图包含常见的一些迁移工具和手段。
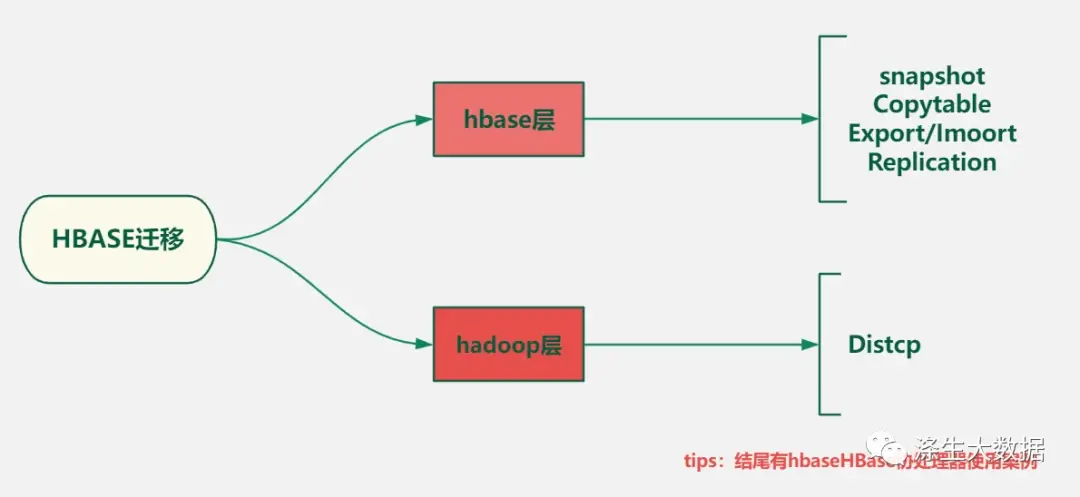
在不同的适用场景下,对于hbase 的迁移是需要采用不同的方式的,下面推荐使用基于 Snapshot 迁移和利用hive外表关联hbase迁移;
1.基于 Snapshot 迁移具体实施步骤
第一步:需要在源集群中执行创建表的快照
snapshot 'poi_geohash','snapshot_poi_geohash'
此时生成的快照是存储在hdfs上的,下面一步需要hbase 的快照同步工具,将表的快照同步到新的hbase集群中;
第二步:同步快照文件
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot snapshot_poi_geohash -copy-from hdfs://${old_namenoe_ip}:8020/hbase -copy-to hdfs://${new_namenoe_ip}:8020/hbase -mappers 30 -bandwidth 8192
参数说明:
- -org.apache.hadoop.hbase.snapshot.ExportSnapshot:HBase 提供的快照导出工具类。
- -snapshot snapshot_poi_geohash:指定要导出的快照名称。
- -copy-from hdfs://${old_namenoe_ip}:8020/hbase:指定要从哪个 HDFS 路径下的文件进行导出,${old_namenode_ip} 是旧的 NameNode IP 地址。
- -copy-to hdfs://${new_namenoe_ip}:8020/hbase:指定导出的文件将被存储到哪个 HDFS 路径下,${new_namenode_ip} 是新的 NameNode IP 地址。
- -mappers 30:指定并发执行的 Mapper 数量,即同时处理的任务数。这里设置为 30。
- -bandwidth 8192:指定数据传输的带宽限制,单位为 KB/s。这里设置为 8192,即 8 MB/s。
任务启动的截图:
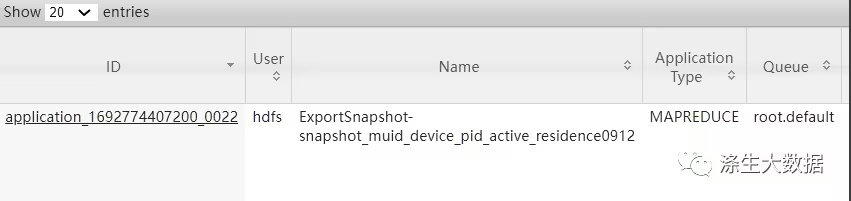
任务结束的截图:
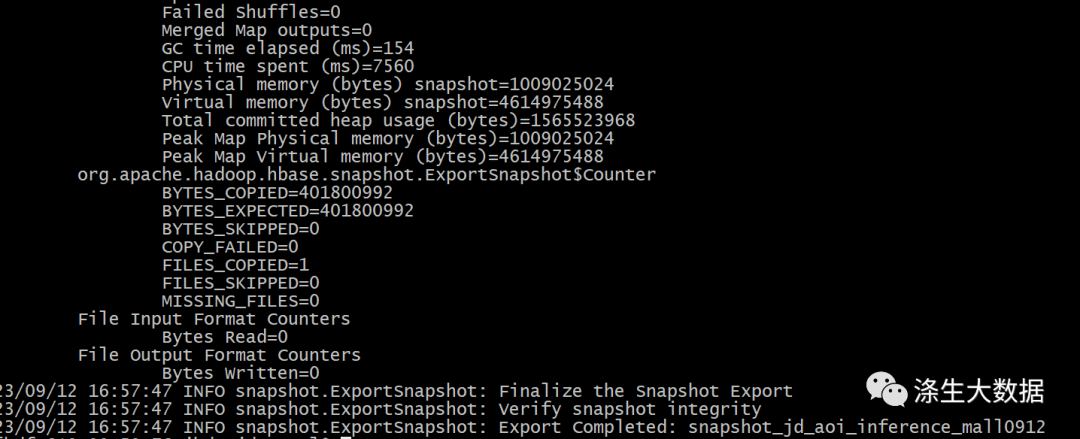
说明:在使用这个工具的使用,操作的客户端必须是Yarn集群的客户端节点,否则上面的程序默认使用本地的资源,如果数据量很大,将会同步的很慢。
注意点1:提交的任务终端,不能手动kill,否则任务虽然正常执行,但是最终的数据会同步失败。(执行上面命令时,建议配合nohup,放在后台执行)
注意点2:这里还有一个细节点需要注意,就是用来同步的用户,如果是CDH版本的,就推荐使用hbase用户,如果是其他非hbase用户,在下面第三步中恢复数据的时候就会有权限上的报错。
例如下面截图的报错,当时同步的时候是用的hdfs用户,在第三步恢复表数据的时候就会有下面的(权限报错);

如果误操作出现上面的情况,我们在执行第三步的时候,命令的状态是会一直卡着的,此时在hbase 的master web 页面上可以看到此时表是在一直上锁的。

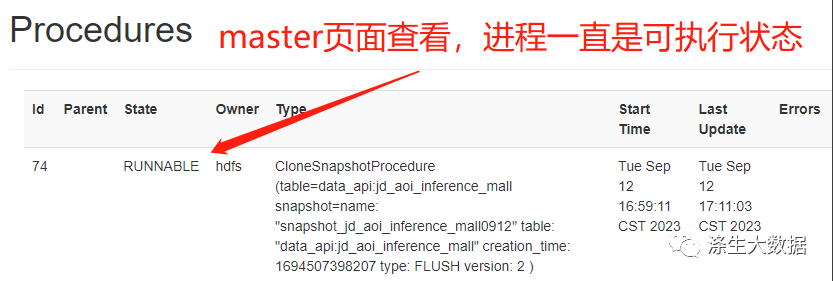
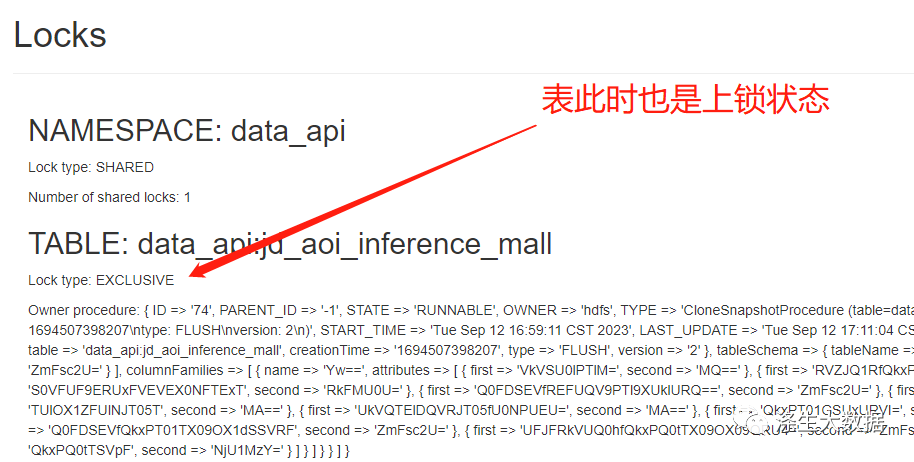
处理方式:此时因为是权限问题导致的,所以处理的方式也就很简单,只需要参考master的报错信息(上面有截图),添加对应的目录权限即可。
添加权限:
$ hdfs dfs -chown -R hbase:hbase /hbase/
这中间不要做其他操作,权限更改完成之后,重启master节点即可恢复正常。
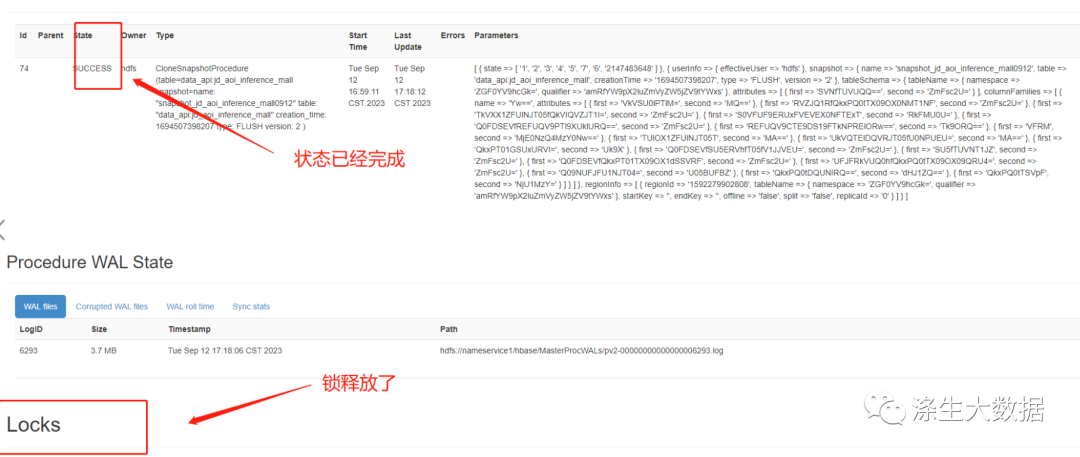
第三步:快照恢复表结构以及数据
hbase(main):001:0> clone_snapshot 'snapshot_poi_geohash','poi_geohash'
说明:这里我们测试表的namespace是默认的default,如果原表是在自定义的namespace下,此时在目标数据库还需要手动创建namespace。
参考命令:
$ hbase shell
hbase(main):013:0> create_namespace 'namespace_name'2.利用hive外表关联hbase迁移
这个是基于hive可以通过外部表(External Table)的方式来访问HBase中的数据。这种在实施的过程操作上相对比较简便。
下面给大家演示一个案例;
在目标hbase中已存在hbase表:poi_geohash

1.首先进入到hive的客户端,创建hive的外部表,关联到hbase表。
# 建立hbase外表需要指定对应的zk
set hbase.zookeeper.quorum=10.6.24.xxx:2181,10.6.24.xxx:2181,10.6.24.xxx:2181; ## 指定hbase 的zk信息CREATE EXTERNAL TABLE poi_geohash_hive1
(
rowkey string,
lat_lon_list string,
name_list string,
type_id_list string,
type_list string
)STORED BY "org.apache.hadoop.hive.hbase.HBaseStorageHandler" WITH
SERDEPROPERTIES ("hbase.columns.mapping"=":key,cf:lat_lon_list,cf:name_list,cf:type_id_list,cf:type_list") TBLPROPERTIES ("hbase.table.name" = "poi_geohash");2.查询hive表,看是否有数据来验证关联成功
select * from poi_geohash_hive;
3.将poi_geohash_hive表的数据导入到另一张hive内部表中。
CREATE TABLE poi_geohash_hive_new AS
SELECTrowkey,lat_lon_list,name_list,type_id_list,type_list
FROMpoi_geohash_hive1;4.在新的hbase中创建新的表,表特性和源hbase表一致。
代码略5.重复1的操作,进入到hive的客户端,创建hive的外部表,关联到hbase表。
# 建立hbase外表需要指定对应的zk
set hbase.zookeeper.quorum=${new_zk_ip}; ## 此时需要set 新的hbase集群的zk的信息CREATE EXTERNAL TABLE poi_geohash_hive2
(
rowkey string,
lat_lon_list string,
name_list string,
type_id_list string,
type_list string
)STORED BY "org.apache.hadoop.hive.hbase.HBaseStorageHandler" WITH
SERDEPROPERTIES ("hbase.columns.mapping"=":key,cf:lat_lon_list,cf:name_list,cf:type_id_list,cf:type_list") TBLPROPERTIES ("hbase.table.name" = "poi_geohash");注意:这个时候通过hive关联的是需要迁移的,2.4步骤中新创建的hbase表;
任务结束,验证新hbase表中有数据且数据完整,及完成对hbase表数据的迁移;
小tips:通常在严重hbase表数据的完整性的时候,简单点的方式就是统计rowkey的数量。
常规的统计方式有 :
1.使用hbase-shell 自带count命令
2.使用hbase.RowCounter工具跑MR任务
3.使用HBase协处理器Coprocessor
但是性能上第三种(Coprocessor)是最快的,下面简单介绍下HBase协处理器统计表的一个小案例;
package com.ds;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.client.coprocessor.AggregationClient;
import org.apache.hadoop.hbase.client.coprocessor.LongColumnInterpreter;public class CoprocessorExampleHbase2 {public static void main(String[] args) {try {long start_t = System.currentTimeMillis();String zkQuorum = null;String tableName = null;for (int i = 0; i < args.length; i++) {if (args[i].equals("-zk")) {zkQuorum = args[i + 1];} else if (args[i].equals("-tb")) {tableName = args[i + 1];}}if (zkQuorum == null || tableName == null) {System.out.println("请指定正确的参数: -zk [Zookeeper Quorum] -tb [Table Name]");return;}// 初始化HBase配置Configuration customConf = new Configuration();customConf.set("hbase.rootdir", "hdfs:///hbase");customConf.set("hbase.zookeeper.property.clientPort", "2181");customConf.setStrings("hbase.zookeeper.quorum", zkQuorum.split(","));customConf.setLong("hbase.rpc.timeout", 600000);customConf.setLong("hbase.client.scanner.caching", 1000);customConf.set("zookeeper.session.timeout", "180000");Configuration configuration = HBaseConfiguration.create(customConf);AggregationClient aggregationClient = new AggregationClient(configuration);Scan scan = new Scan();long rowCount = aggregationClient.rowCount(TableName.valueOf(tableName), new LongColumnInterpreter(), scan);System.out.println("******************统计结果***********************");System.out.println("统计总耗时:" + (System.currentTimeMillis() - start_t) + "毫秒");System.out.println("表【" + tableName + "】统计总数:" + rowCount);} catch (Exception e) {e.printStackTrace();} catch (Throwable e) {e.printStackTrace();}}
}在hbase配置 hbase-site.xm 中添加如下配置,并重启hbase;
<property><name>hbase.coprocessor.user.region.classes</name><value>org.apache.hadoop.hbase.coprocessor.AggregateImplementation</value></property>使用方式,直接在hbase 的客户端节点执行:
hadoop jar hbase2-1.0-SNAPSHOT-jar-with-dependencies.jar com.ds.CoprocessorExampleHbase2 -zk zk地址 -tb hbase表名
最终的输出结果:

Hbase 迁移小结:从实践中总结出的最佳迁移策略