本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure Storage Account】系列。
接上文 【Azure 架构师学习笔记】-Azure Storage Account(5)- Data Lake layers
前言
上一文介绍了存储帐户的概述,还有container的一些配置,在container下面存放的就是文件夹和文件,也就是数据。之所以单独一文描述是因为当一个项目考虑使用云存储时,除了一些必要的外部设置这种“硬”设计之外,还需要考虑文件结构这种“软”设计。 本文讲述的就是比较通用的“软”设计部分。
在container下面,按照业界的一些最佳实践,会定义一些列的Zone, 目录,当然还要配置安全控制,将在下一文介绍。
Zone
分开zone的其中一个原因来自于上文讲述的一些策略,如果没有把zone区分出来,那么某些允许定期删除或者不允许删除的策略就会导致数据的管理混乱。同时通过把访问控制细化,可以更好地保护一个中央存储帐户上的数据安全和可信度。
还有其他的一些好处,比如缺乏治理的数据湖,可能会变成数据“沼泽”, 或者变成数据“垃圾场”,用户会淹没在混乱的数据中。
常见的Zone有以下几个:
- Raw:数据的原始格式存储。可以作为下游系统唯一数据源。
- Staging:经过初步处理的数据,已经可共数据科学家等进行使用。
- Curated:符合数据湖标准的数据集市。经过清洗,转换,重组后的数据,可供数据交付。符合安全,治理要求。
还有一些更加细分的,可选的zone:
- Transient/Temp:对Raw data进行进一步的区分,把“新”数据从中隔离出来。也可以用于数据校验,提供低延时的数据服务。
- Master Data:用于引用的数据。
- User Drop Zone:手动生成的数据。
- Archive Zone:数据归档。
Zone的设计并不仅限于云存储,而且这是一种设计思维而不是实现方式,具体需求绝体实现。
文件夹
在各个zone下面存放的首先是文件夹。文件夹的问题在于结构的设计,你可以按时间创建父文件夹,里面是地区,系统等。也可以按照地区建父文件夹,哪一种更合适?要根据需求来定,如果为了数据分析,那么建议更多的是:
以zone为第一层,以数据源为第二层,然后再按年月日顺序创建文件夹。
这样的好处在于权限控制较为简单,ADF, Databricks等ETL 过程可以更加动态,参数化。
小结
整个存储帐户最终看起来将会是类似如下图所示:
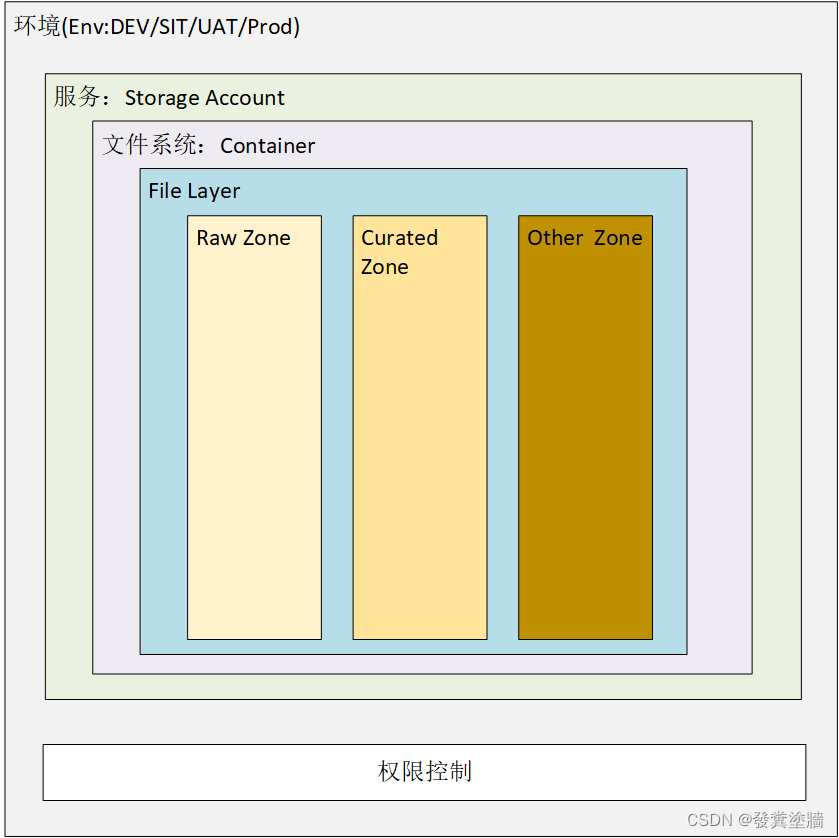
下一文将介绍一下安全方面的内容。
![(.htaccess文件特性)[MRCTF2020]你传你呢 1](https://img-blog.csdnimg.cn/img_convert/8717f5419dde81101f293e3622fe9bb1.png)