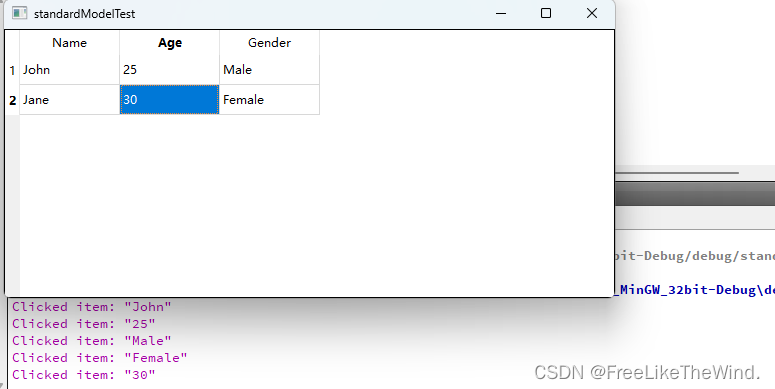
import pandas as pd
# 导入词典
df = pd.read_excel('Sentiment_dictionary\大连理工情感词汇本体\情感词汇本体.xlsx')
# 我们暂时只使用 ['词语','词性种类','词义数','词义序号','情感分类','强度','极性']
df = df[['词语', '词性种类', '词义数', '词义序号', '情感分类', '强度', '极性']]
df.head()# 按照7大情绪划分
Happy = []
Good = []
Surprise = []
Anger = []
Sad = []
Fear = []
Disgust = []
for idx, row in df.iterrows():if row['情感分类'] in ['PA', 'PE']:Happy.append(row['词语'])if row['情感分类'] in ['PD', 'PH', 'PG', 'PB', 'PK']:Good.append(row['词语']) if row['情感分类'] in ['PC']:Surprise.append(row['词语']) if row['情感分类'] in ['NA']:Anger.append(row['词语']) if row['情感分类'] in ['NB', 'NJ', 'NH', 'PF']:Sad.append(row['词语'])if row['情感分类'] in ['NI', 'NC', 'NG']:Fear.append(row['词语'])if row['情感分类'] in ['NE', 'ND', 'NN', 'NK', 'NL']:Disgust.append(row['词语'])
Positive = Happy + Good +Surprise
Negative = Anger + Sad + Fear + Disgust
print('情绪词语列表整理完成')# 计情绪计算函数
# 这里只是朴素的使用情绪词计数统计文本的情绪值
import jieba
import time
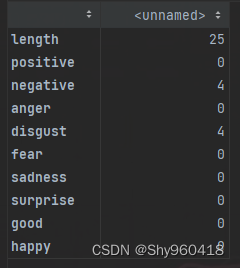
def emotion_caculate(text):positive = 0negative = 0anger = 0disgust = 0fear = 0sad = 0surprise = 0good = 0happy = 0wordlist = jieba.lcut(text)wordset = set(wordlist)wordfreq = []for word in wordset:freq = wordlist.count(word)if word in Positive:positive+=freqif word in Negative:negative+=freqif word in Anger:anger+=freqif word in Disgust:disgust+=freqif word in Fear:fear+=freqif word in Sad:sad+=freqif word in Surprise:surprise+=freqif word in Good:good+=freqif word in Happy:happy+=freqemotion_info = {'length':len(wordlist),'positive': positive,'negative': negative,'anger': anger,'disgust': disgust,'fear':fear,'good':good,'sadness':sad,'surprise':surprise,'happy':happy,}indexs = ['length', 'positive', 'negative', 'anger', 'disgust','fear','sadness','surprise', 'good', 'happy']return pd.Series(emotion_info, index=indexs)
emotion_caculate(text='这个国家再对这些制造假冒伪劣食品药品的人手软的话,那后果真的会相当糟糕。坐牢?从快判个死刑!')
输出结果: