并行度(Parallelism)
当要处理的数据量非常大时,我们可以把一个算子操作,“复制”多份到多个节点,数据来了之后就可以到其中任意一个执行。这样一来,一个算子任务就被拆分成了多个并行的“子任务”(subtasks),再将它们分发到不同节点,就真正实现了并行计算。
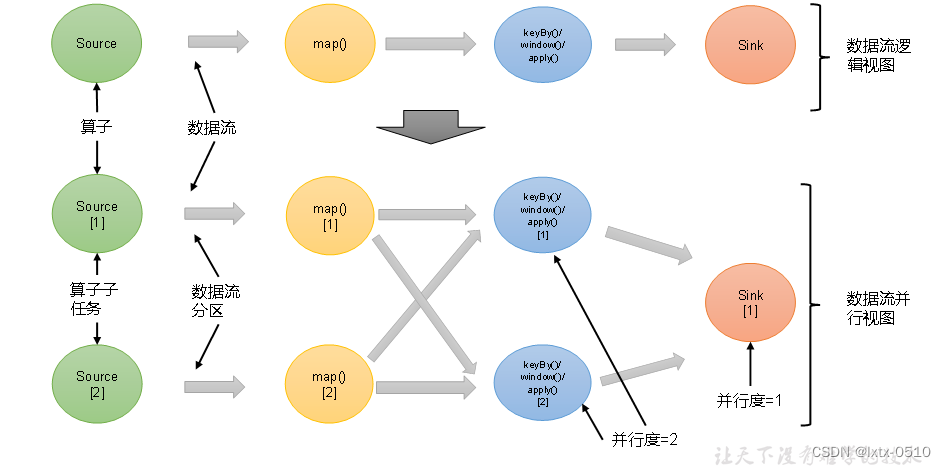
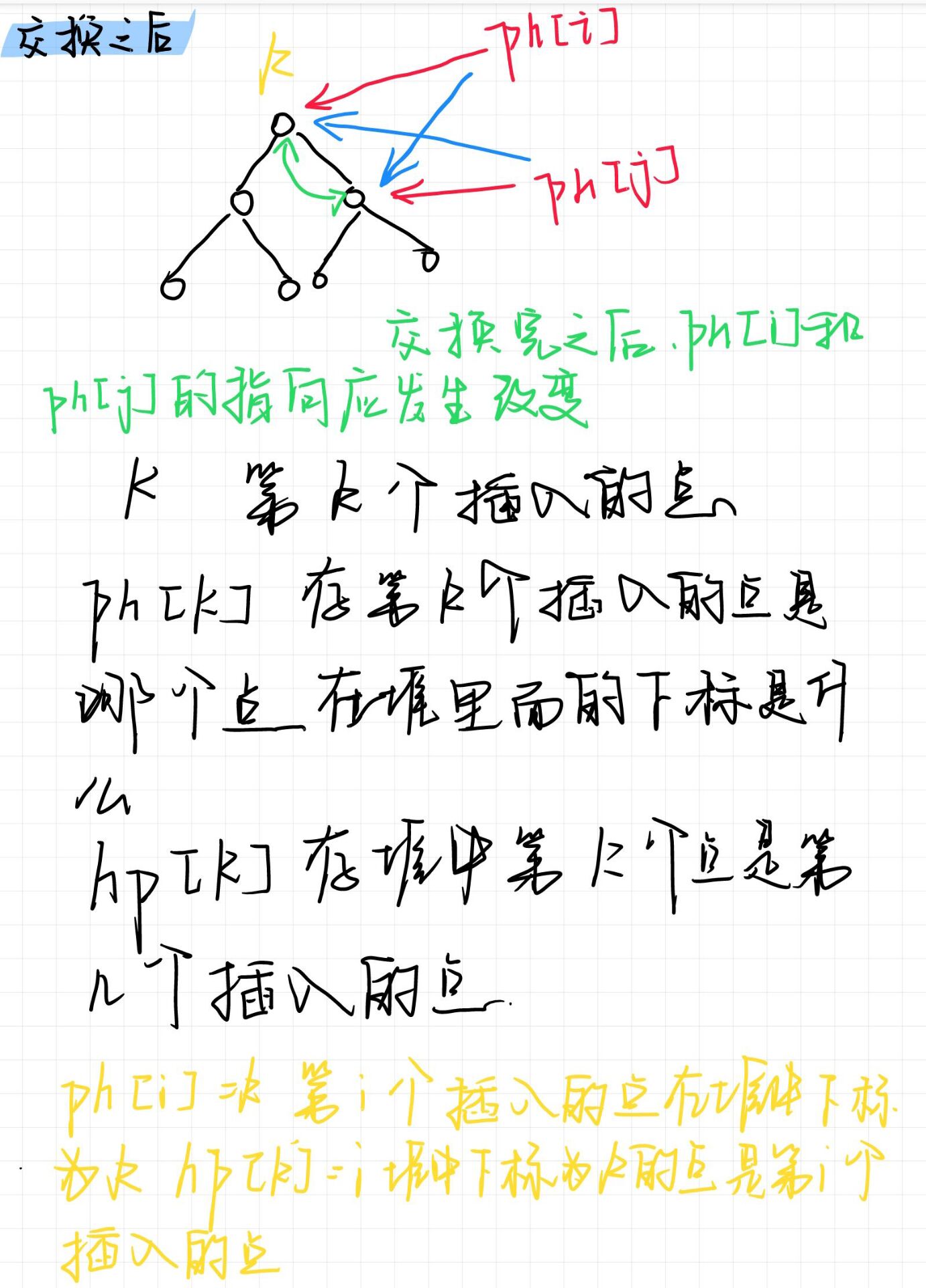
一个特定算子的子任务(subtask)的个数 被称之为其并行度(parallelism)。这样,包含并行子任务的数据流,就是并行数据流,它需要多个分区(stream partition)来分配并行任务。一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
例如:如上图所示,当前数据流中有source、map、window、sink四个算子,其中sink算子的并行度为1,其他算子的并行度都为2。所以这段流处理程序的并行度就是2。
并行度的设置
在Flink中,可以用不同的方法来设置并行度,它们的有效范围和优先级别也是不同的。
- 代码中设置
// 这种方式设置的并行度,只针对当前算子有效。
stream.map(word -> Tuple2.of(word, 1L)).setParallelism(2);
//我们也可以直接调用执行环境的setParallelism()方法,全局设定并行度
env.setParallelism(2);
我们一般不会在程序中设置全局并行度,因为如果在程序中对全局并行度进行硬编码,会导致无法动态扩容。
这里要注意的是,由于keyBy不是算子,所以无法对keyBy设置并行度。
- 提交应用时设置
# flink run命令提交应用时,增加-p参数来指定当前应用程序执行的并行度,作用类似于执行环境的全局设置
bin/flink run –p 2 –c com.atguigu.wc.SocketStreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar
- 配置文件中设置
#在集群的配置文件flink-conf.yaml中直接更改默认并行度
# 这个设置对于整个集群上提交的所有作业有效,初始值为1
# 在开发环境中,没有配置文件,默认并行度就是当前机器的CPU核心数。
parallelism.default: 2
并行度的优先级:
代码:算子 > 代码:env > 提交时指定 > 配置文件
算子间的数据传输模式:
一个数据流在算子之间传输数据的形式可以是一对一(one-to-one)的直通(forwarding)模式,也可以是打乱的重分区(redistributing)模式,具体是哪一种形式,取决于算子的种类。
- 一对一(One-to-one,forwarding)
这种模式下,数据流维护着分区以及元素的顺序。比如source和map算子,source算子读取数据之后,可以直接发送给map算子做处理,它们之间不需要重新分区,也不需要调整数据的顺序。 - 重分区(Redistributing)
在这种模式下,数据流的分区会发生改变。比如图中的map和后面的keyBy/window算子之间,以及keyBy/window算子和Sink算子之间,都是这样的关系。
算子链(Operator Chain)
在Flink中,并行度相同的一对一(one to one)算子操作,可以直接链接在一起形成一个“大”的任务(task),这样原来的算子就成为了真正任务里的一部分,如下图所示。每个task会被一个线程执行。这样的技术被称为“算子链”(Operator Chain)。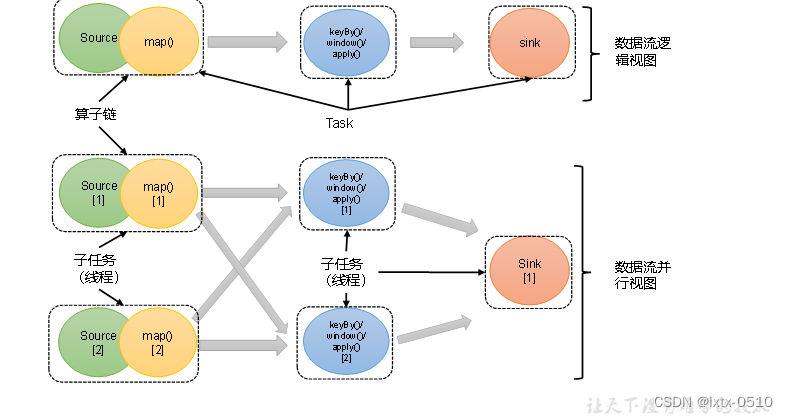
Flink默认会按照算子链的原则进行链接合并,如果我们想要禁止合并或者自行定义,也可以在代码中对算子做一些特定的设置:
// 禁用算子链
.map(word -> Tuple2.of(word, 1L)).disableChaining();// 从当前算子开始新链
.map(word -> Tuple2.of(word, 1L)).startNewChain()



![【汇编】[bx+idata]的寻址方式、SI和DI寄存器](https://img-blog.csdnimg.cn/827c3b49f26d4b7cbaa8d9cce46b092a.png)