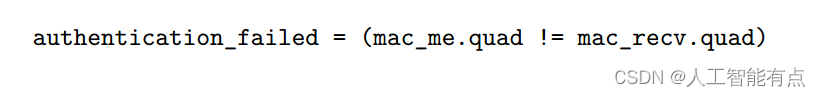检索增强生成(RAG)的整体工作流程如下:
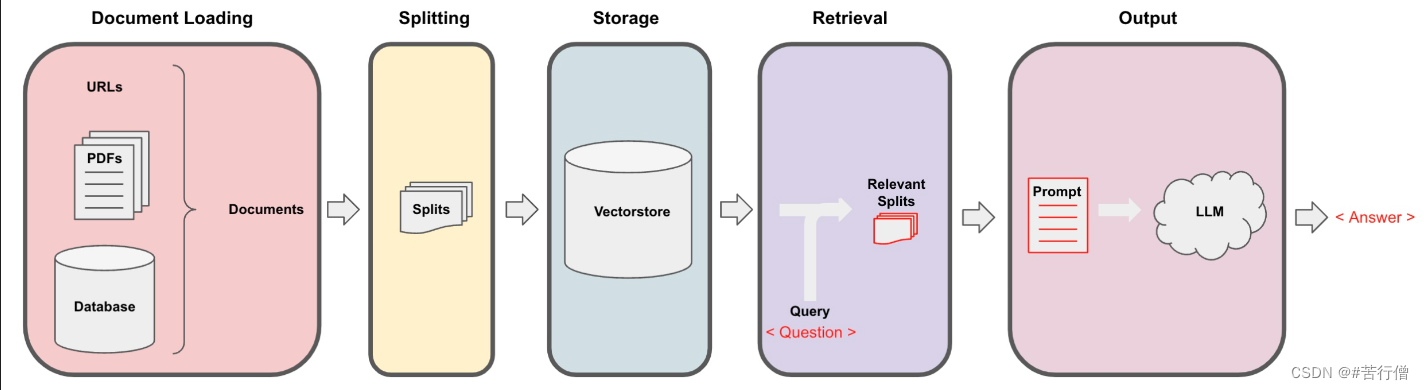
在构建检索增强生成 (RAG) 系统时,信息检索是核心环节。检索是指根据用户的问题去向量数据库中搜索与问题相关的文档内容,当我们访问和查询向量数据库时可能会运用到如下几种技术:
- 1、基本语义相似度(Basic semantic similarity)
- 2、最大边际相关性(Maximum marginal relevance,MMR)
- 2、过滤元数据
- 3、LLM辅助检索
使用基本的相似性搜索大概能解决你80%的相关检索工作,但对于那些相似性搜索失败的边缘情况该如何解决呢?如检索出重复的内容,或检索出相似但没有按我们要求的检索范围进行检索的内容(叫它检索第一章它却检索出了第二章)
这一章节我们将介绍几种检索方法,以及解决检索边缘情况的技巧,让我们一起开始学习吧!
0、初始化openai环境
from langchain.chat_models import ChatOpenAI
import os
import openai
# 运行此API配置,需要将目录中的.env中api_key替换为自己的
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
1、向量数据库检索
1.1、相似性检索(Similarity Search)
# 安装个依赖包先
!pip install -Uq lark
下面我们来实现一下语义的相似度搜索,我们把三句话存入向量数据库Chroma中,然后我们提出问题让向量数据库根据问题来搜索相关答案:
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddingsembedding = OpenAIEmbeddings()texts_chinese = ["""华为手机遥遥领先,太牛了。""","""奶牛猫真的非常可爱,但有点调皮,古灵精怪。""","""黯然叉烧饭,半肥半瘦,入口多汁细腻,配上一口白饭,一点都不腻。""","""奶牛猫非常cute,但有的贱"""
]smalldb_chinese = Chroma.from_texts(texts_chinese, embedding=embedding)
我们可以看到前两句都是描述的是一种叫“鹅膏菌”的菌类,包括它们的特征:有较大的子实体,第三句描述的是“”,一种已知的最毒的蘑菇,它的特征就是:含有剧毒。对于这个例子,我们将创建一个小数据库,我们可以作为一个示例来使用。
下面我们提出相关问题,检索出相关的答案,看是否正确:
query = '告诉我关于奶牛猫的所有信息'
smalldb_chinese.similarity_search(query, k=2)
[Document(page_content='奶牛猫真的非常可爱,但有点调皮,古灵精怪。'),Document(page_content='奶牛猫非常cute,但有的贱')]
chroma 的 similarity_search(相似性搜索) 方法可以根据问题的语义去数据库中搜索与之相关性最高的文档,也就是搜索到了第一句和第二句的文本。但这似乎还存在一些问题,因为第一句和第二句的含义非常接近,他们都是描述奶牛猫的,所以假如只返回其中的一句就足以满足要求了,如果返回两句含义非常接近的文本感觉是一种资源的浪费。下面我们来看一下 max_marginal_relevance_search 的搜索结果。
1.2、解决多样性:最大边际相关性(MMR,max_marginal_relevance_search)
最大边际相关模型 (MMR,Maximal Marginal Relevance) 是实现多样性检索的常用算法。
MMR 的基本思想是同时考量查询与文档的相关度,以及文档之间的相似度。相关度确保返回结果对查询高度相关,相似度则鼓励不同语义的文档被包含进结果集。具体来说,它计算每个候选文档与查询的相关度,并减去与已经选入结果集的文档的最大相似度。这样更不相似的文档会有更高的得分。

总之,MMR 是解决检索冗余问题、提供多样性结果的一种简单高效的算法。它平衡了相关性和多样性,适用于对多样信息需求较强的应用场景。
Langchain的内置方法max_marginal_relevance_search已经帮我们首先了该算法,在执行max_marginal_relevance_search方法时,我们需要设置fetch_k参数,用来告诉向量数据库我们最终需要k个结果,向量数据库在搜索时会获取一个和问题相关的文档集,该文档集中的文档数量大于k,然后从中过滤出k个具有相关性同时兼顾多样性的文档。
我们来看一个利用 MMR 从知识库中检索信息的示例。设置 fetch_k 参数,用来告诉向量数据库我们最终需要 k 个结果返回。fetch_k=3 ,也就是我们最初获取 3 个文档,k=2 表示返回最不同的 2 个文档。
smalldb_chinese.max_marginal_relevance_search(query, fetch_k=3, k=2)
[Document(page_content='奶牛猫真的非常可爱,但有点调皮,古灵精怪。'),Document(page_content='黯然叉烧饭,半肥半瘦,入口多汁细腻,配上一口白饭,一点都不腻。')]
可以看到MMR过滤掉了重复度比较高的 奶牛猫非常cute,但有的贱,尽管第三句与我们的问题的相关性不太高,但是这样的结果其实应该是更加的合理,因为第一句和第二句文本本来就有着相似的含义,所以只需要返回其中的一句就可以了,另外再返回一个与问题相关性弱一点的答案(第三句文本),这样似乎增强了答案的多样性,相信用户也会更加偏爱。
下面我们加载上一篇博客中生成的吴恩达机器学习的相关知识的向量数据库:
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddingspersist_directory_chinese = './data/chroma/'embedding = OpenAIEmbeddings()vectordb_chinese = Chroma(persist_directory=persist_directory_chinese,embedding_function=embedding
)print(vectordb_chinese._collection.count())# 首先我们定义一个需要检索答案的问题:
query = "MachineLearning-Lecture02讲了什么内容?" # 接着调用已加载的向量数据库根据相似性检索答案topk:
docs_chinese = vectordb_chinese.similarity_search(query, k=3)
print(len(docs_chinese))
docs_chinese
80
3
[Document(page_content='MachineLearning-Lecture01 \nInstructor (Andrew Ng): Okay...', metadata={'page': 0, 'source': './data/MachineLearning-Lecture01.pdf'}),
Document(page_content='MachineLearning-Lecture01 \nInstructor (Andrew Ng): Okay...', metadata={'page': 0, 'source': './data/MachineLearning-Lecture02.pdf'}),
Document(page_content="joys of machine learning firs thand and really try to...', metadata={'page': 10, 'source': './data/MachineLearning-Lecture02.pdf'})]
我们可以看到,docs_chinese[0]和docs_chinese[1]是一样的,但属于不同文档,MachineLearning-Lecture01.pdf 和 MachineLearning-Lecture02.pdf
下面用mmr试试,可以发现结果不一样;mmr它把搜索结果中相似度很高的文档做了过滤,所以它保留了结果的相关性又同时兼顾了结果的多样性。
docs_mmr_chinese = vectordb_chinese.max_marginal_relevance_search(query,k=3)
docs_mmr_chinese
[Document(page_content='MachineLearning-Lecture01 \nInstructor (Andrew Ng): Okay...', metadata={'page': 0, 'source': './data/MachineLearning-Lecture01.pdf'}),
Document(page_content="although they'll also be recorded and televi sed. And we'll us...', metadata={'page': 8, 'source': './data/MachineLearning-Lecture01.pdf'}),
Document(page_content="So, for example, what a learning algorithm ma y do is...', metadata={'page': 13, 'source': './data/MachineLearning-Lecture01.pdf'})]
1.3、解决特殊性:使用元数据
在失败的场景中,除了上面的重复性问题,还有就是是询问了关于文档中某一讲的问题,但得到的结果中也包括了来自其他讲的结果。这是我们所不希望看到的结果,之所以产生这样的结果是因为当我们向向量数据库提出问题时,数据库并没有很好的理解问题的语义,所以返回的结果不如预期。要解决这个问题,我们可以通过过滤元数据的方式来实现精准搜索,当前很多向量数据库都支持对元数据(metadata)的操作。
metadata为每个嵌入的块(embedded chunk)提供上下文。
从前面的学习我们可以知道,每个 docunment 由 page_content 和metadata组成,如
Document(page_content=‘xxx’, metadata={‘page’: 0, ‘source’: ‘./data/MachineLearning-Lecture01.pdf’})
所以,我们可以在检索时,手动指定一个元数据过滤器filter,让生成的结果限定在filter指定的文档来源:
# 首先我们定义一个需要检索答案的问题:
query = "MachineLearning-Lecture02讲了什么内容?" # 接着调用已加载的向量数据库根据相似性检索答案topk:
docs_chinese = vectordb_chinese.similarity_search(query, k=3,filter={"source":'./data/MachineLearning-Lecture01.pdf'})
print(len(docs_chinese))
docs_chinese
3
[Document(page_content='MachineLearning-Lecture01 \nInstructor (Andrew Ng): Okay...', metadata={'page': 0, 'source': './data/MachineLearning-Lecture01.pdf'}),
Document(page_content="joys of machine learning firs thand and really try to...', metadata={'page': 10, 'source': './data/MachineLearning-Lecture01.pdf'}),
Document(page_content="although they'll also be recorded and televi sed. And we'll us...', metadata={'page': 8, 'source': './data/MachineLearning-Lecture01.pdf'})]
1.4、解决特殊性:在元数据中使用自查询检索器 SelfQueryRetriever(LLM辅助检索)
当然,我们不能每次都采用手动的方式来解决这个问题,这会显得不够智能。这里我们将通过LLM来自动从用户问题中提取过滤信息。
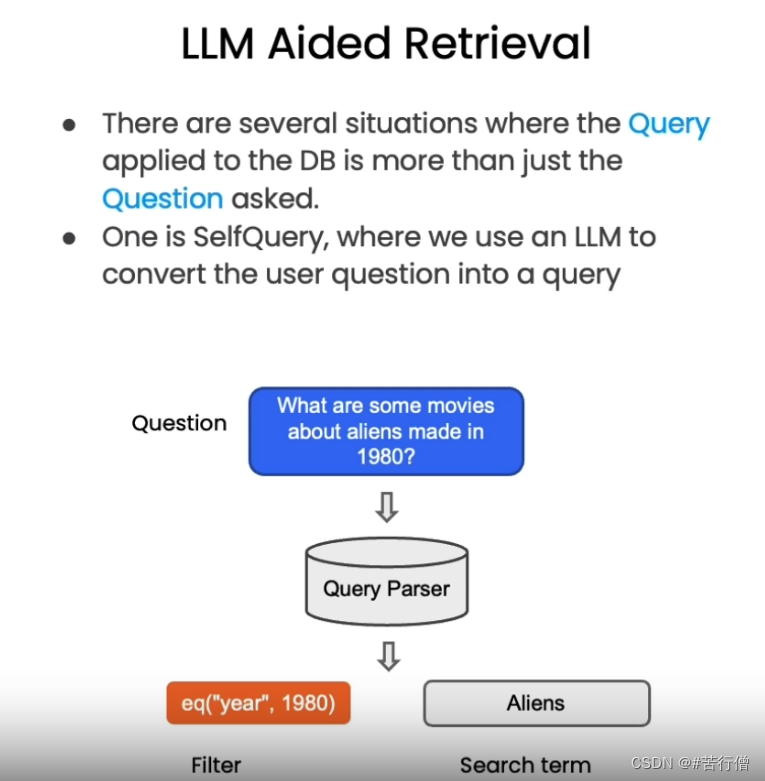
LangChain提供了SelfQueryRetriever模块,它可以通过语言模型从问题语句中分析出:
-
1、向量搜索的查询字符串(search term)
-
2、过滤文档的元数据条件(Filter)
以“除了维基百科,还有哪些健康网站”为例,SelfQueryRetriever可以推断出“除了维基百科”表示需要过滤的条件,即排除维基百科的文档。
它使用语言模型自动解析语句语义,提取过滤信息,无需手动设置。这种基于理解的元数据过滤更加智能方便,可以自动处理更复杂的过滤逻辑。
掌握利用语言模型实现自动化过滤的技巧,可以大幅降低构建针对性问答系统的难度。这种自抽取查询的方法使检索更加智能和动态。
其原理如下图所示:
下面我们就来实现一下LLM辅助检索:
这里我们首先定义了 metadata_field_info_chinese ,它包含了元数据的过滤条件 source 和 page , 其中 source 的作用是告诉 LLM 我们想要的数据来自于哪里, page 告诉 LLM 我们需要提取相关的内容在原始文档的哪一页。有了 metadata_field_info_chinese 信息后,LLM会自动从用户的问题中提取出上图中的 Filter 和 Search term 两项,然后向量数据库基于这两项去搜索相关的内容。下面我们看一下查询结果:
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfollm = OpenAI(temperature=0)metadata_field_info_chinese = [AttributeInfo(name="source",description="The lecture the chunk is from, should be one of `./data/MachineLearning-Lecture02.pdf`",type="string",),AttributeInfo(name="page",description="The page from the lecture",type="integer",),
]document_content_description_chinese = "machine learning"retriever_chinese = SelfQueryRetriever.from_llm(llm,vectorstore=vectordb_chinese,document_contents=document_content_description_chinese,metadata_field_info=metadata_field_info_chinese,verbose=True
)query = "MachineLearning-Lecture02讲了什么内容?"# 当你第一次执行下一行时,你会收到关于predict_and_parse已被弃用的警告。 这可以安全地忽略。
docs_chinese = retriever_chinese.get_relevant_documents(query)docs_chinese
从结果的metadata信息可以看到,检索到的结果都是在MachineLearning-Lecture02中。
3
[Document(page_content='MachineLearning-Lecture01 \nInstructor (Andrew Ng): Okay...', metadata={'page': 0, 'source': './data/MachineLearning-Lecture02.pdf'}),
Document(page_content="joys of machine learning firs thand and really try to...', metadata={'page': 10, 'source': './data/MachineLearning-Lecture02.pdf'}),
Document(page_content="So in this class, we've tried to convey to you a broad set of principl...', metadata={'page': 2, 'source': './data/MachineLearning-Lecture02.pdf'}),
Document(page_content="Similarly, every time you write a check, I ac tually don'...', metadata={'page': 3, 'source': './data/MachineLearning-Lecture02.pdf'})]
1.5、其他技巧:压缩
在使用向量检索获取相关文档时,直接返回整个文档片段可能带来资源浪费,因为实际相关的只是文档的一小部分。为改进这一点,LangChain提供了一种“压缩”检索机制。其工作原理是,先使用标准向量检索获得候选文档,然后基于查询语句的语义,使用语言模型压缩这些文档,只保留与问题相关的部分。 例如,对“蘑菇的营养价值”这个查询,检索可能返回整篇有关蘑菇的长文档。经压缩后,只提取文档中与“营养价值”相关的句子。
从下图中我们看到,当向量数据库返回了所有与问题相关的所有文档块的全部内容后,会有一个Compression LLM来负责对这些返回的文档块的内容进行压缩,所谓压缩是指仅从文档块中提取出和用户问题相关的内容,并舍弃掉那些不相关的内容。
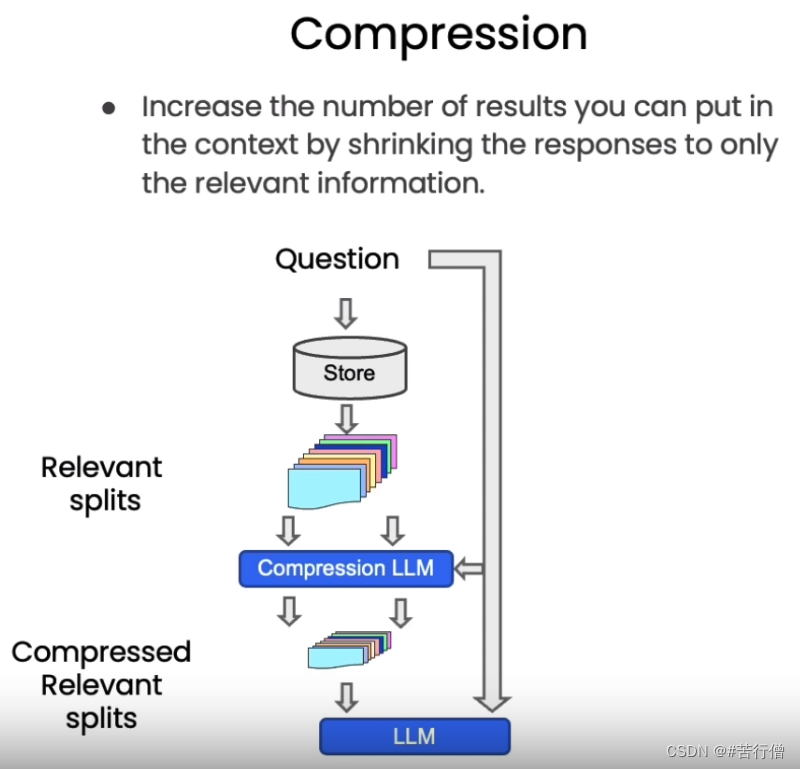
下面的代码中我们定义了一个 LLMChainExtractor ,它是一个压缩器,它负责从向量数据库返回的文档块中提取相关信息,然后我们还定义了 ContextualCompressionRetriever ,它有两个参数:base_compressor 和 base_retriever,其中 base_compressor 是我们前面定义的 LLMChainExtractor 的实例,base_retriever是早前定义的 vectordb 产生的检索器。
现在当我们提出问题后,查看结果文档,我们可以看到两件事。
- 1、它们比正常文档短很多
- 2、仍然有一些重复的东西,这是因为在底层我们使用的是语义搜索算法。
从上述例子中,我们可以发现这种压缩可以有效提升输出质量,同时节省通过长文档带来的计算资源浪费,降低成本。上下文相关的压缩检索技术,使得到的支持文档更严格匹配问题需求,是提升问答系统效率的重要手段。读者可以在实际应用中考虑这一技术。
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractordef pretty_print_docs(docs):print(f"\n{'-' * 100}\n".join([f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)]))llm = OpenAI(temperature=0)# 压缩器
compressor = LLMChainExtractor.from_llm(llm) # 带压缩的检索器
compression_retriever_chinese = ContextualCompressionRetriever(base_compressor=compressor,base_retriever=vectordb_chinese.as_retriever()
)# 对源文档进行压缩
question_chinese = "machine learning是什么?"
compressed_docs_chinese = compression_retriever_chinese.get_relevant_documents(question_chinese)
pretty_print_docs(compressed_docs_chinese)
Document 1:"machine learning grew out of early work in AI, early work in artificial intelligence. And over the last — I wanna say last 15 or last 20 years or so, it's been viewed as a sort of growing new capability for computers."
----------------------------------------------------------------------------------------------------
Document 2:"machine learning grew out of early work in AI, early work in artificial intelligence. And over the last — I wanna say last 15 or last 20 years or so, it's been viewed as a sort of growing new capability for computers."
----------------------------------------------------------------------------------------------------
Document 3:"machine learning是什么" and "Arthur Samuel defined machine learning informally as the [inaudible] that gives computers to learn — [inaudible] that gives computers the ability to learn without being explicitly programmed."
----------------------------------------------------------------------------------------------------
Document 4:"machine learning是什么" and "Arthur Samuel defined machine learning informally as the [inaudible] that gives computers to learn — [inaudible] that gives computers the ability to learn without being explicitly programmed."
2、结合各种技术
为了去掉结果中的重复文档,我们在从向量数据库创建检索器时,可以将搜索类型设置为 MMR 。然后我们可以重新运行这个过程,可以看到我们返回的是一个过滤过的结果集,其中不包含任何重复的信息。
compression_retriever_chinese = ContextualCompressionRetriever(base_compressor=compressor,base_retriever=vectordb_chinese.as_retriever(search_type = "mmr")
)question_chinese = "machine learning是什么?"
compressed_docs_chinese = compression_retriever_chinese.get_relevant_documents(question_chinese)
pretty_print_docs(compressed_docs_chinese)
Document 1:"machine learning grew out of early work in AI, early work in artificial intelligence. And over the last — I wanna say last 15 or last 20 years or so, it's been viewed as a sort of growing new capability for computers."
----------------------------------------------------------------------------------------------------
Document 2:"Arthur Samuel managed to write a checkers program that could play checkers much better than he personally could, and this is an instance of maybe computers learning to do things that they were not programmed explicitly to do." "Tom Mitchell, who says that a well-posed learning problem is defined as follows: He says that a computer program is set to learn from an experience E with respect to some task T and some performance measure P if its performance on T as measured by P improves with experience E."
----------------------------------------------------------------------------------------------------
Document 3:
"machine learning is the most exciting field of all the computer sciences" and "machine learning is one of those things that has and is having a large impact on many applications."
3、其他类型的检索
值得注意的是,vetordb 并不是唯一一种检索文档的工具。LangChain 还提供了其他检索文档的方式,例如:TF-IDF 或 SVM。
这里我们定义了 SVMRetriever ,和 TFIDFRetriever 两个检索器,接下来我们分别测试 TF-IDF 检索以及 SVM 检索的效果,可以看出,TF-IDF和SVM 检索的效果很差。
from langchain.retrievers import SVMRetriever
from langchain.retrievers import TFIDFRetriever
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter# 加载PDF
loader_chinese = PyPDFLoader("./data/MachineLearning-Lecture01.pdf")
pages_chinese = loader_chinese.load()
all_page_text_chinese = [p.page_content for p in pages_chinese]
joined_page_text_chinese = " ".join(all_page_text_chinese)# 分割文本
text_splitter_chinese = RecursiveCharacterTextSplitter(chunk_size = 1500,chunk_overlap = 150)
splits_chinese = text_splitter_chinese.split_text(joined_page_text_chinese)# 检索
svm_retriever = SVMRetriever.from_texts(splits_chinese, embedding)
tfidf_retriever = TFIDFRetriever.from_texts(splits_chinese)question_chinese = "这门课的主要主题是什么?"
docs_svm_chinese = svm_retriever.get_relevant_documents(question_chinese)
print(docs_svm_chinese[0])question_chinese = "machine learning是什么?"
docs_tfidf_chinese = tfidf_retriever.get_relevant_documents(question_chinese)
print(docs_tfidf_chinese[0])
page_content="let me just check what questions you have righ t now. So if there are no questions, I'll just \nclose with two reminders, which are after class today or as you start to talk with other \npeople in this class, I just encourage you again to start to form project partners, to try to \nfind project partners to do your project with. And also, this is a good time to start forming \nstudy groups, so either talk to your friends or post in the newsgroup, but we just \nencourage you to try to star t to do both of those today, okay? Form study groups, and try \nto find two other project partners. \nSo thank you. I'm looking forward to teaching this class, and I'll see you in a couple of \ndays. [End of Audio] \nDuration: 69 minutes"
page_content="MachineLearning-Lecture01 \nInstructor (Andrew Ng): Okay. Good morning. Welcome to CS229, the machine \nlearning class. So what I wanna do today is ju st spend a little time going over the logistics \nof the class, and then we'll start to talk a bit about machine learning. \nBy way of introduction, my name's Andrew Ng and I'll be instru ctor for this class. And so \nI personally work in machine learning, and I' ve worked on it for about 15 years now, and \nI actually think that machine learning is th e most exciting field of all the computer \nsciences. So I'm actually always excited about teaching this class. Sometimes I actually \nthink that machine learning is not only the most exciting thin g in computer science, but \nthe most exciting thing in all of human e ndeavor, so maybe a little bias there. \nI also want to introduce the TAs, who are all graduate students doing research in or \nrelated to the machine learni ng and all aspects of machin e learning. Paul Baumstarck \nworks in machine learning and computer vision. Catie Chang is actually a neuroscientist \nwho applies machine learning algorithms to try to understand the human brain. Tom Do \nis another PhD student, works in computa tional biology and in sort of the basic \nfundamentals of human learning. Zico Kolter is the head TA — he's head TA two years \nin a row now — works in machine learning a nd applies them to a bunch of robots. And \nDaniel Ramage is — I guess he's not here — Daniel applies l earning algorithms to"
4、总结
今天的课程涵盖了向量检索的多项新技术,让我们快速回顾关键要点:
-
1、MMR 算法可以实现兼具相关性与多样性的检索结果,避免信息冗余。
-
2、定义元数据字段可以进行针对性过滤,提升匹配准确率。
-
3、SelfQueryRetriever 模块通过语言模型自动分析语句,提取查询字符串与过滤条件,无需手动设置,使检索更智能。
-
4、ContextualCompressionRetriever 实现压缩检索,仅返回与问题相关的文档片段,可以大幅提升效率并节省计算资源。
-
5、除向量检索外,还简要介绍了基于 SVM 和 TF-IDF 的检索方法。
这些技术为我们构建可交互的语义搜索模块提供了重要支持。熟练掌握各检索算法的适用场景,将大大增强问答系统的智能水平。
Reference
- [1] 吴恩达老师的教程
- [2] DataWhale组织