🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客
🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。
🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频
目录
1. HiveOperator配置
2. HiveOperator调度HQL案例
1. HiveOperator配置
可以通过HiveOperator直接操作Hive SQL ,HiveOperator的参数如下:
hql(str):需要执行的Hive SQL。hive_cli_conn_id(str):连接Hive的conn_id,在airflow webui connection中配置的。想要在airflow中使用HiveOperator调用Hive任务,首先需要安装以下依赖并配置Hive Metastore:
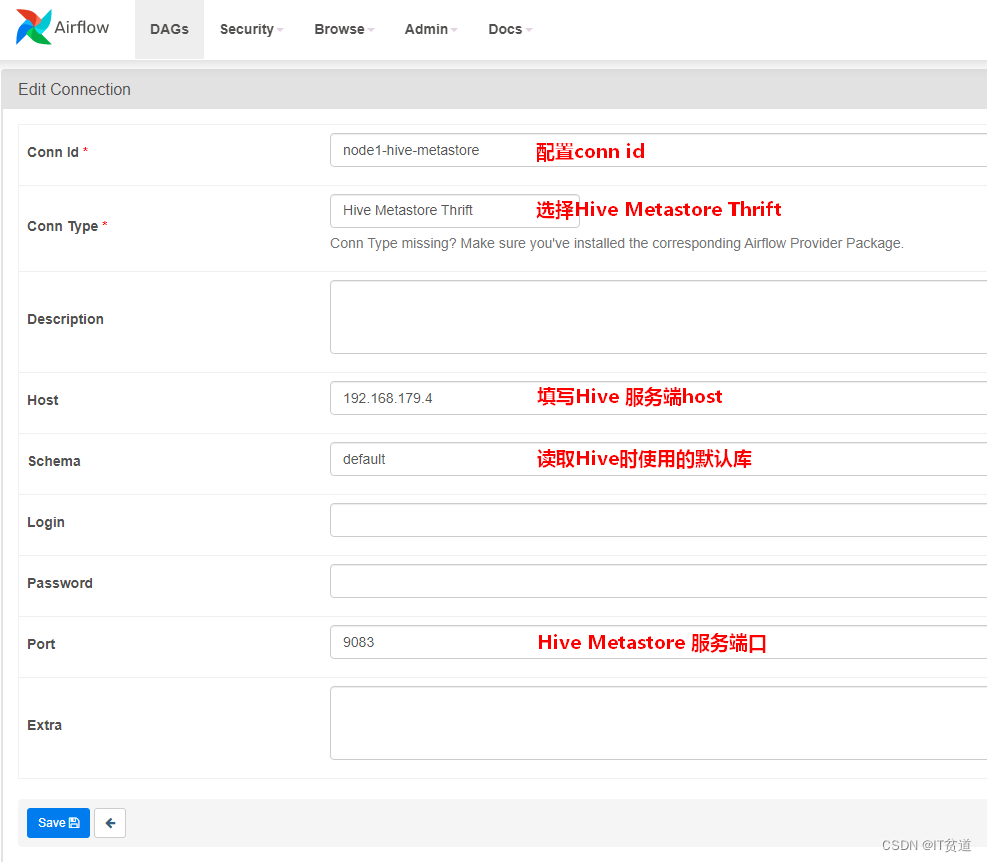
#切换Python37环境[root@node4 ~]# conda activate python37#安装hive provider package(python37) [root@node4 ~]# pip install apache-airflow-providers-apache-hive==2.0.2#启动airflow(python37) [root@node4 ~]# airflow webserver --port 8080(python37) [root@node4 ~]# airflow scheduler登录Airflow webui并设置Hive Metastore,登录后找到”Admin”->”Connections”,点击“+”新增配置:
2. HiveOperator调度HQL案例
1) 启动Hive,准备表
启动HDFS、Hive Metastore,在Hive中创建以下三张表:
create table person_info(id int,name string,age int) row format delimited fields terminated by '\t';create table score_info(id int,name string,score int) row format delimited fields terminated by '\t';向表 person_info加载如下数据:
1 zs 182 ls 193 ww 20向表score_info加载如下数据:
1 zs 1002 ls 2003 ww 3002) 在node4节点配置Hive 客户端
由于Airflow 使用HiveOperator时需要在Airflow安装节点上有Hive客户端,所以需要在node4节点上配置Hive客户端。
将Hive安装包上传至node4 “/software”下解压,并配置Hive环境变量
#在/etc/profile文件最后配置Hive环境变量export HIVE_HOME=/software/hive-1.2.1export PATH=$PATH:$HIVE_HOME/bin#使环境变量生效source /etc/profile修改HIVE_HOME/conf/hive-site.xml ,写入如下内容:
<configuration><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><property><name>hive.metastore.local</name><value>false</value></property><property><name>hive.metastore.uris</name><value>thrift://node1:9083</value></property></configuration>3) 编写DAG python配置文件
注意在本地开发工具编写python配置时,需要用到HiveOperator,需要在本地对应的python环境中安装对应的provider package。
C:\Users\wubai>d:D:\>cd d:\ProgramData\Anaconda3\envs\python37\Scriptsd:\ProgramData\Anaconda3\envs\python37\Scripts>pip install apache-airflow-providers-apache-hive==2.0.2注意:这里本地安装也有可能缺少对应的C++环境,我们也可以不安装,直接跳过也可以。Python配置文件:
from datetime import datetime, timedelta
from airflow import DAG
from airflow.providers.apache.hive.operators.hive import HiveOperatordefault_args = {'owner':'wangwu','start_date':datetime(2021, 9, 23),'retries': 1, # 失败重试次数'retry_delay': timedelta(minutes=5) # 失败重试间隔
}dag = DAG(dag_id = 'execute_hive_sql',default_args=default_args,schedule_interval=timedelta(minutes=1)
)first=HiveOperator(task_id='person_info',hive_cli_conn_id="node1-hive-metastore",hql='select id,name,age from person_info',dag = dag
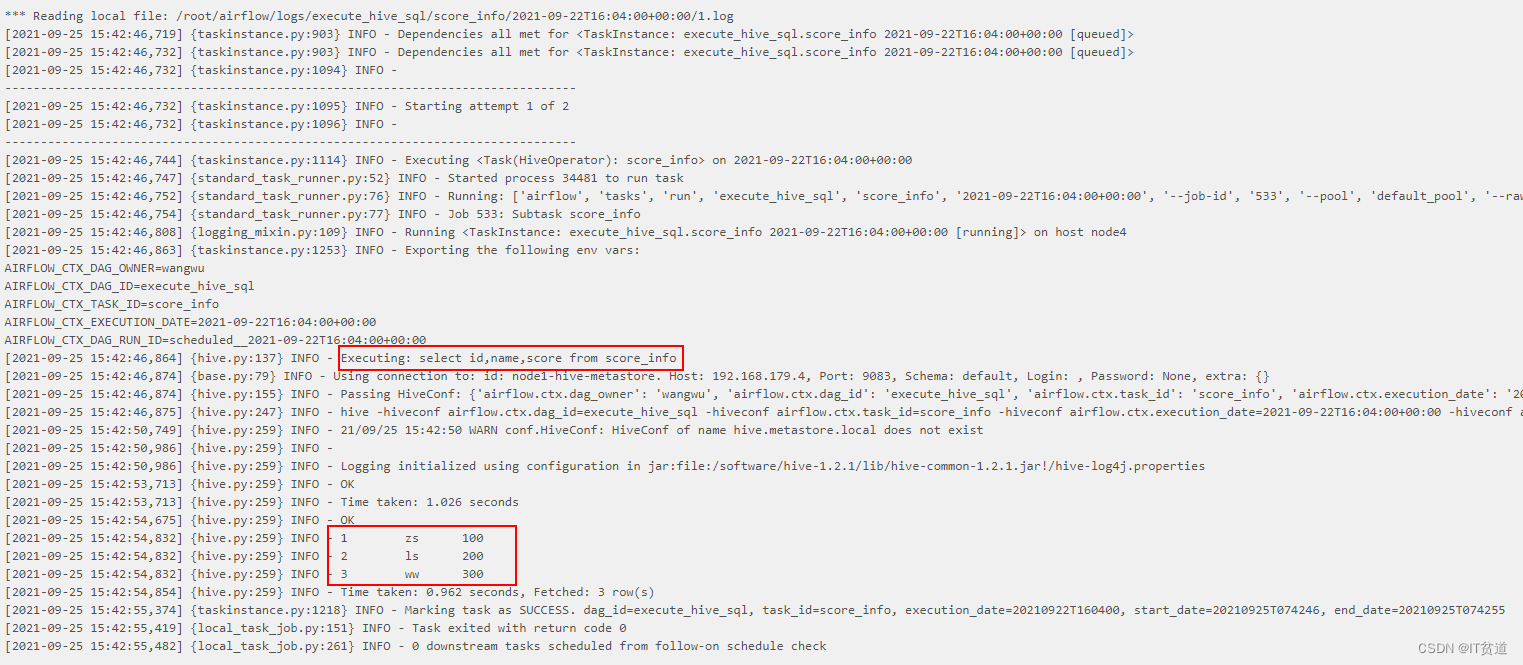
)second=HiveOperator(task_id='score_info',hive_cli_conn_id="node1-hive-metastore",hql='select id,name,score from score_info',dag=dag
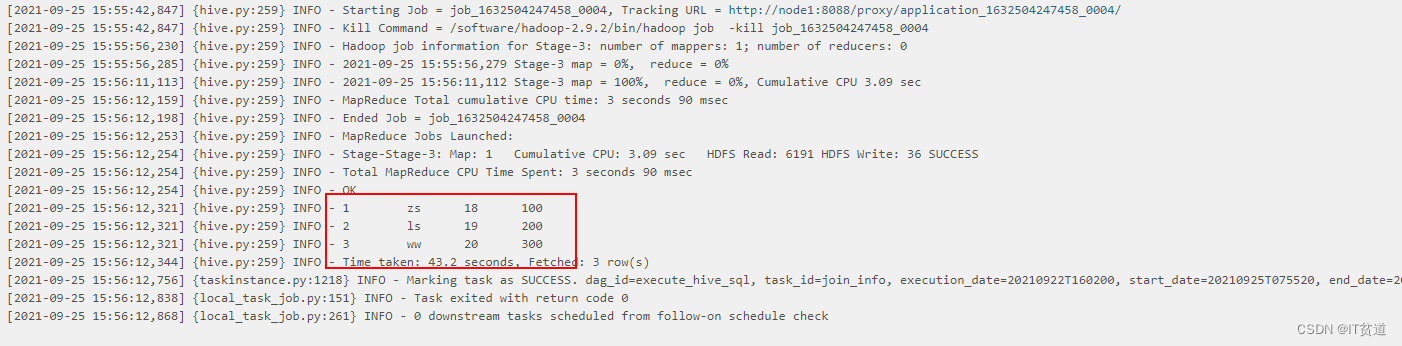
)third=HiveOperator(task_id='join_info',hive_cli_conn_id="node1-hive-metastore",hql='select a.id,a.name,a.age,b.score from person_info a join score_info b on a.id = b.id',dag=dag
)first >> second >>third4) 调度python配置脚本
将以上配置好的python文件上传至node4节点$AIRFLOW_HOME/dags下,重启Airflow websever与scheduler,登录webui,开启调度:

调度结果如下:




![[github配置] 远程访问仓库以及问题解决](https://img-blog.csdnimg.cn/083e22ef77cd4326a05791a0b41e9c51.png)