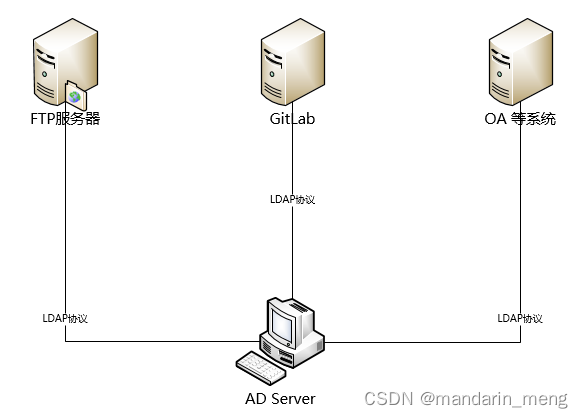
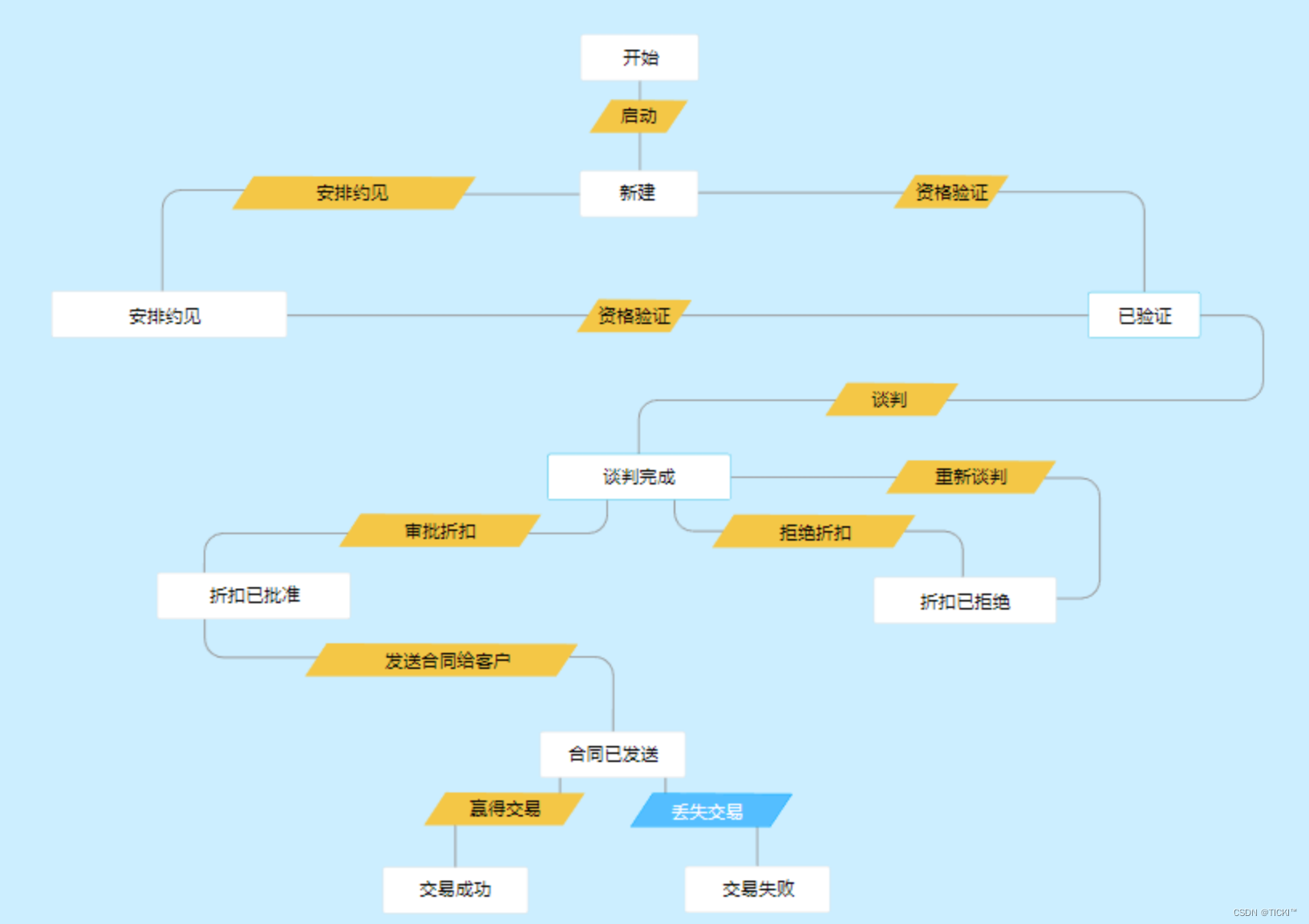
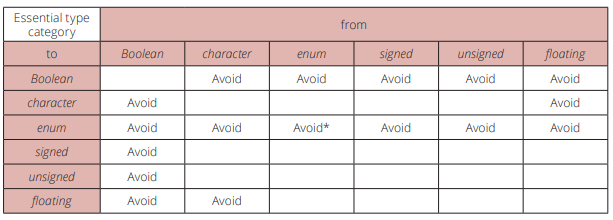
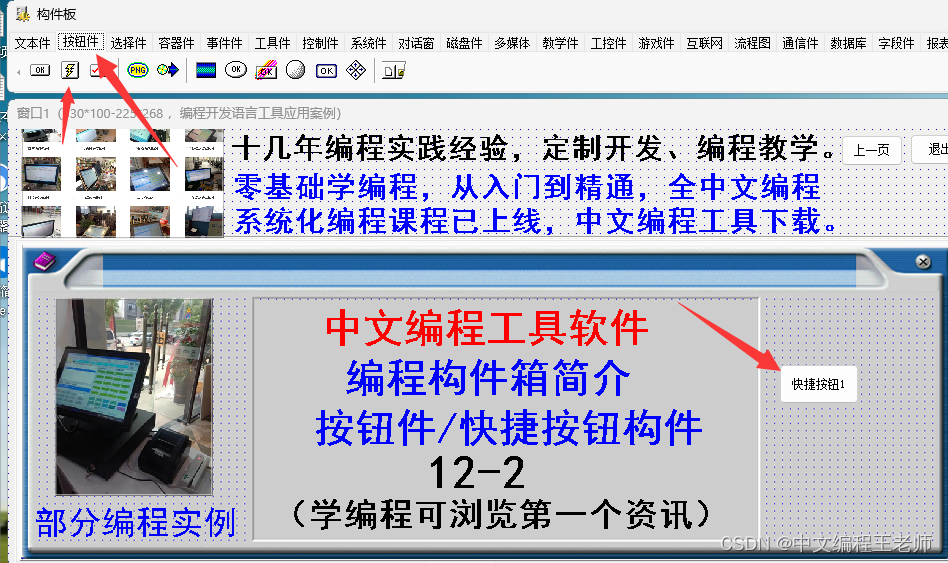
✍️作者简介:码农小北(专注于Android、Web、TCP/IP等技术方向)
🐳博客主页: 开源中国、稀土掘金、51cto博客、博客园、知乎、简书、慕课网、CSDN
🔔如果文章对您有一定的帮助请👉关注✨、点赞👍、收藏📂、评论💬。
🔥如需转载请参考【转载须知】
文章目录
- 简介
- 算法分类
- 十四种算法简介
- 算法复杂度
- 算法演示
- 冒泡排序 (Bubble Sort)
- 简介
- 算法步骤
- 图解算法
- 代码示例
- 算法分析
- 选择排序 (Selection Sort)
- 简介
- 算法步骤
- 图解算法
- 代码示例
- 算法分析
- 插入排序 (Insertion Sort)
- 简介
- 算法步骤
- 图解算法
- 代码示例
- 算法分析
- 希尔排序 (Shell Sort)
- 简介
- 算法步骤
- 图解算法
- 代码示例
- 算法分析
- 归并排序 (Merge Sort)
- 简介
- 算法步骤
- 图解算法
- 代码示例
- 算法分析
- 快速排序 (Quick Sort)
- 简介
- 算法步骤
- 图解算法
- 代码示例
- 算法分析
- 堆排序 (Heap Sort)
- 简介
- 算法步骤
- 图解算法
- 代码示例
- 算法分析
- 计数排序 (Counting Sort)
- 简介
- 算法步骤
- 图解算法
- 代码示例
- 算法分析
- 桶排序 (Bucket Sort)
- 简介
- 算法步骤
- 图解算法
- 代码示例
- 算法分析
- 基数排序 (Radix Sort)
- 简介
- 算法步骤
- 图解算法
- 代码示例
- 算法分析
简介
排序算法是计算机科学中至关重要的一部分,它通过一系列操作将一组记录按照某个或某些关键字的大小进行递增或递减排列。在数据处理领域,排序算法的选择直接影响着程序的效率和性能。为了得到符合实际需求的优秀算法,我们需要经过深入的推理和分析,考虑到数据的各种限制和规范。因此,深入探讨十大经典排序算法的原理及实现。通过这个过程,我希望为大家提供更加准确和全面的排序算法知识,助力在实际编程中更灵活地选择适合场景的排序方法,提升程序的效率和性能。
排序算法根据其基本思想可以分为比较类排序和非比较类排序。比较类排序通过比较元素的大小来决定排序顺序,而非比较类排序则不依赖元素间的比较。不同排序算法在处理不同规模和类型的数据时表现出不同的优势。接下来,我们将详细介绍这十大经典排序算法。
算法分类
比较类排序
在比较类排序中,算法通过比较元素之间的大小关系来确定它们的相对次序。这类算法主要关注元素之间的比较操作,以决定它们在排序后的顺序。
非比较类排序
非比较类排序则不直接通过比较元素的大小关系来确定它们的顺序,而是利用其他方法完成排序。
区别和应用场景
-
比较类排序更适用于元素之间有大小关系的情况,主要通过比较操作来实现排序,适用于各种数据类型。
-
非比较类排序更适用于特定范围或结构的数据,利用其他方法实现排序,适用于整数、字符串等类型。

十四种算法简介
| 序号 | 简称 | 英文 | 简介 |
|---|---|---|---|
| 1 | 二分查找法 | Binary Search | 二分查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。 |
| 2 | 冒泡排序算法 | Bubble Sort | 重复地走访过要排序的元素列,依次比较两个相邻的元素,如果顺序错误就把它们交换过来。走访元素的工作是重复地进行直到没有相邻元素需要交换,也就是说该元素列已经排序完成。 |
| 3 | 插入排序算法 | Insertion Sort | 通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应的位置并插入。 |
| 4 | 快速排序算法 | Quick Sort | 对冒泡算法的一种改进。是指通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序。整个排序过程可以递归进行,以此达到整个数据变成有序序列。 |
| 5 | 希尔排序算法 | Shell’s Sort | 希尔排序是插入排序的一种又称“缩小增量排序”,是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法 |
| 6 | 归并排序算法 | Merge Sort | 归并排序是建立在归并操作上的一种有效,稳定的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。 |
| 7 | 桶排序算法 | Bucket Sort | 桶排序也叫箱排序,工作的原理是将数组分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)。桶排序是鸽巢排序的一种归纳结果。当要被排序的数组内的数值是均匀分配的时候,桶排序使用线性时间(Θ(n))。但桶排序并不是比较排序,他不受到 O(n log n) 下限的影响。 |
| 8 | 基数排序算法 | Radix Sort | 基数排序(radix sort)属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)或bin sort,顾名思义,它是透过键值的部份资讯,将要排序的元素分配至某些“桶”中,藉以达到排序的作用,基数排序法是属于稳定性的排序,其时间复杂度为O (nlog®m),其中r为所采取的基数,而m为堆数,在某些时候,基数排序法的效率高于其它的稳定性排序法。 |
| 9 | 剪枝算法 | Pruning Algorithms | 在搜索算法中优化中,剪枝,就是通过某种判断,避免一些不必要的遍历过程,形象的说,就是剪去了搜索树中的某些“枝条”,故称剪枝。应用剪枝优化的核心问题是设计剪枝判断方法,即确定哪些枝条应当舍弃,哪些枝条应当保留的方法。 |
| 10 | 回溯算法 | Backtracking | 回溯算法实际上一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径。 |
| 11 | 最短路径算法 | Shortest Path | 从某顶点出发,沿图的边到达另一顶点所经过的路径中,各边上权值之和最小的一条路径叫做最短路径。解决最短路的问题有以下算法,Dijkstra 算法,Bellman-Ford 算法,Floyd 算法和 SPFA算法等。 |
| 12 | 最大子数组算法 | Maximum Subarray | 最大子数组问题是要在一个数组中找到一个连续的子数组,使得该子数组的元素之和最大。该问题有多种解法,其中一种常见的解法是使用分治法。 |
| 13 | 最长公共子序算法 | Longest Common Subsequence | 最长公共子序列是指在两个序列中均存在的、且相对顺序相同的元素组成的子序列。解决最长公共子序列的问题通常使用动态 |
| 14 | 最小生成树算法 | Minimum Spanning Tree | 最小生成树是一个无向连通图中生成树中边权值之和最小的生成树。解决最小生成树的问题有多种算法,其中常见的包括 Prim 算法和 Kruskal 算法,它们通过选择图中的边来构建最小生成树。这些算法在网络设计、城市规划等领域有广泛应用。 |
算法复杂度
在实际应用中,不同排序算法的性能表现受到数据规模、数据分布等多方面因素的影响。我们将通过具体的示例和图表,展示这些排序算法在时间复杂度和空间复杂度上的对比,以便读者更好地选择适合自己场景的排序算法。
算法复杂度通常通过时间复杂度和空间复杂度来表示。以下是常见排序算法的时间复杂度和空间复杂度的表格:
| 排序算法 | 平均时间复杂度 | 最坏时间复杂度 | 最好时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|---|
| 冒泡排序 (Bubble Sort) | O(n^2) | O(n^2) | O(n) | O(1) | 稳定 |
| 选择排序 (Selection Sort) | O(n^2) | O(n^2) | O(n^2) | O(1) | 不稳定 |
| 插入排序 (Insertion Sort) | O(n^2) | O(n^2) | O(n) | O(1) | 稳定 |
| 希尔排序 (Shell Sort) | O(n log^2 n) | O(n log^2 n) | O(n log n) | O(1) | 不稳定 |
| 快速排序 (Quick Sort) | O(n log n) | O(n^2) | O(n log n) | O(log n) | 不稳定 |
| 归并排序 (Merge Sort) | O(n log n) | O(n log n) | O(n log n) | O(n) | 稳定 |
| 堆排序 (Heap Sort) | O(n log n) | O(n log n) | O(n log n) | O(1) | 不稳定 |
| 计数排序 (Counting Sort) | O(n + k) | O(n + k) | O(n + k) | O(k) | 稳定 |
| 桶排序 (Bucket Sort) | O(n^2) | O(n^2) | O(n + k) | O(n + k) | 稳定 |
| 基数排序 (Radix Sort) | O(nk) | O(nk) | O(nk) | O(n + k) | 稳定 |
注解:
- 时间复杂度通常用大O表示法表示,表示算法运行时间相对于输入大小的增长率。
- 空间复杂度表示算法在运行过程中相对于输入大小所需的额外空间。
- "稳定"表示如果有两个相等的元素在排序前后的相对顺序保持不变。
- "不稳定"表示相等的元素在排序前后的相对顺序可能改变。
以上表格中的复杂度是对于典型情况而言的。实际应用中,算法性能还可能受到具体实现、硬件条件等因素的影响。
算法演示
冒泡排序 (Bubble Sort)
简介
冒泡排序是一种简单直观的排序算法,它多次遍历待排序的序列,每次遍历都比较相邻的两个元素,如果顺序不正确就交换它们。通过多次遍历,使得最大的元素逐渐移动到最后,实现整个序列的排序。冒泡排序是一种简单但效率较低的排序算法,通常不适用于大规模数据集。
算法步骤
- 从序列的第一个元素开始,对相邻的两个元素进行比较。
- 如果顺序不正确,交换这两个元素的位置。
- 遍历完整个序列后,最大的元素会沉到序列的末尾。
- 重复步骤1-3,每次遍历都将未排序部分的最大元素沉到序列的末尾。
- 重复以上步骤,直到整个序列有序。
图解算法

代码示例
/*** 冒泡排序** @param arr 待排序数组*/public static void bubbleSort(int[] arr) {int n = arr.length;// 外层循环控制比较的轮数for (int i = 0; i < n - 1; i++) {// 内层循环控制每一轮比较的次数for (int j = 0; j < n - i - 1; j++) {// 如果当前元素大于下一个元素,则交换它们的位置if (arr[j] > arr[j + 1]) {int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}}
算法分析
- 稳定性: 冒泡排序是一种稳定的排序算法,相等元素的相对位置在排序前后不会改变。
- 时间复杂度: 最佳:O(n), 最差:O(n^2), 平均:O(n^2)
- 空间复杂度: O(1)
- 排序方式: 冒泡排序是一种原地排序算法。
选择排序 (Selection Sort)
简介
选择排序是一种简单直观的排序算法,它将待排序的序列分为已排序部分和未排序部分,每次从未排序部分选择最小(或最大)的元素,放到已排序部分的末尾。通过多次选择最小(或最大)元素,完成整个序列的排序。虽然选择排序不如一些高级排序算法的性能优越,但由于其简单性,在某些场景下仍然是一个有效的选择。
算法步骤
- 从未排序部分选择最小(或最大)的元素。
- 将选中的元素与未排序部分的第一个元素交换位置,使其成为已排序部分的末尾。
- 更新分界线,将已排序部分扩大一个元素,未排序部分缩小一个元素。
- 重复步骤1-3,直到未排序部分为空。
- 完成排序。
图解算法

代码示例
/*** 选择排序** @param arr 待排序数组*/public static void selectionSort(int[] arr) {int n = arr.length;// 外层循环控制当前需要放置的位置for (int i = 0; i < n - 1; i++) {// 假设当前位置的元素是最小的int minIndex = i;// 内层循环找到未排序部分的最小元素的索引for (int j = i + 1; j < n; j++) {if (arr[j] < arr[minIndex]) {minIndex = j;}}// 将找到的最小元素与当前位置元素交换int temp = arr[minIndex];arr[minIndex] = arr[i];arr[i] = temp;}}
算法分析
- 稳定性: 选择排序是一种不稳定的排序算法,因为相等元素可能在排序过程中改变相对位置。
- 时间复杂度: 最佳:O(n^2), 最差:O(n^2), 平均:O(n^2)
- 空间复杂度: O(1)
- 排序方式: 选择排序是一种原地排序算法。
插入排序 (Insertion Sort)
简介
插入排序是一种简单直观的排序算法,它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应的位置并插入。插入排序是稳定的排序算法,适用于小型数据集。
算法步骤
- 从第一个元素开始,该元素可以认为已经被排序。
- 取出下一个元素,在已经排序的元素序列中从后向前扫描。
- 如果该元素(已排序)大于新元素,将该元素移到下一位置。
- 重复步骤3,直到找到已排序的元素小于或等于新元素的位置。
- 将新元素插入到该位置后。
- 重复步骤2~5,直到整个数组排序完成。
图解算法

代码示例
public class InsertionSort {public static void main(String[] args) {int[] array = {12, 11, 13, 5, 6};System.out.println("原始数组:");printArray(array);// 应用插入排序insertionSort(array);System.out.println("\n排序后的数组:");printArray(array);}/*** 插入排序** @param arr 待排序数组*/public static void insertionSort(int[] arr) {int n = arr.length;for (int i = 1; i < n; ++i) {int key = arr[i];int j = i - 1;// 将大于 key 的元素都向后移动while (j >= 0 && arr[j] > key) {arr[j + 1] = arr[j];j = j - 1;}// 插入 key 到正确的位置arr[j + 1] = key;}}/*** 打印数组元素** @param arr 待打印数组*/public static void printArray(int[] arr) {for (int value : arr) {System.out.print(value + " ");}System.out.println();}
}
算法分析
- 稳定性: 稳定
- 时间复杂度: 最佳:O(n),最差:O(n2),平均:O(n2)
- 空间复杂度: O(1)
希尔排序 (Shell Sort)
简介
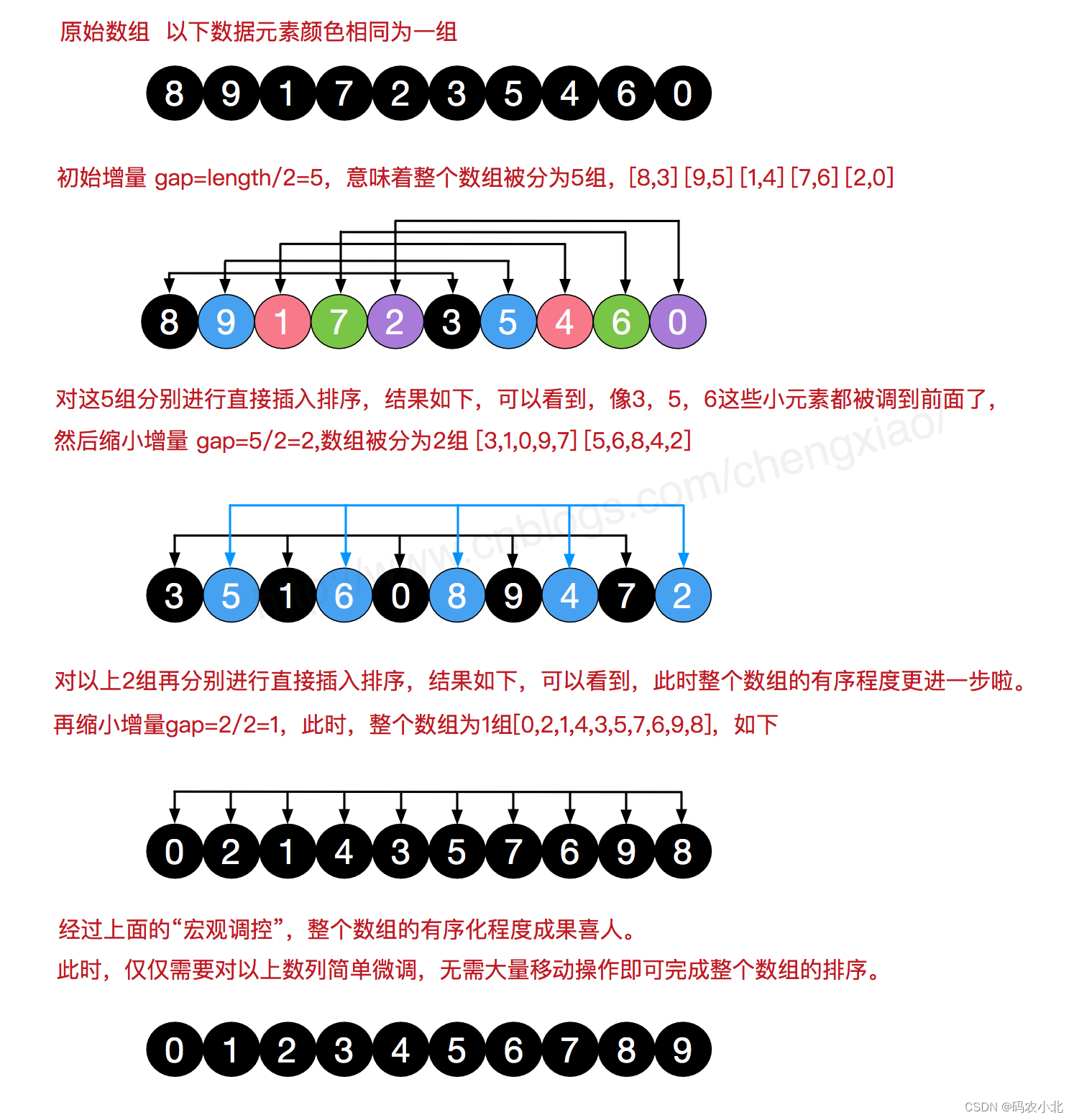
希尔排序是一种插入排序的改进版本,它通过比较一定间隔(增量)内的元素,并逐步减小这个间隔,最终完成整个序列的排序。希尔排序的核心思想是将相隔较远的元素进行比较和交换,以得到局部较为有序的序列,最后再进行插入排序。希尔排序在大规模数据集上比插入排序更加高效。
算法步骤
- 选择一个增量序列(一般是按照 Knuth 提出的序列:1, 4, 13, 40, …)。
- 根据增量序列,将序列分割成若干子序列,对每个子序列进行插入排序。
- 逐步减小增量,重复步骤2,直到增量为1,此时进行最后一次插入排序。
- 完成排序。
图解算法
代码示例
/*** 希尔排序** @param arr 待排序数组*/public static void shellSort(int[] arr) {int n = arr.length;// 初始步长设置为数组长度的一半for (int gap = n / 2; gap > 0; gap /= 2) {// 从步长位置开始进行插入排序for (int i = gap; i < n; i++) {int temp = arr[i];int j;// 在当前步长范围内,进行插入排序for (j = i; j >= gap && arr[j - gap] > temp; j -= gap) {arr[j] = arr[j - gap];}arr[j] = temp;}}}
算法分析
- 稳定性: 希尔排序是一种不稳定的排序算法,相等元素可能在排序过程中改变相对位置。
- 时间复杂度: 最佳:O(n log n), 最差:O(n^2), 平均:取决于增量序列的选择
- 空间复杂度: O(1)
- 排序方式: 希尔排序是一种原地排序算法。
归并排序 (Merge Sort)
简介
归并排序是一种基于分治思想的排序算法,它将待排序的序列分成两个子序列,对每个子序列进行递归排序,然后将已排序的子序列合并成一个有序序列。归并排序的关键在于合并操作,它保证了每个子序列在合并时都是有序的。归并排序具有稳定性和高效性,在大规模数据集上表现出色。
算法步骤
- 将待排序序列分成两个子序列,分别进行递归排序。
- 合并已排序的子序列,得到新的有序序列。
- 重复步骤1-2,直到整个序列有序。
图解算法

代码示例
/*** 归并排序** @param arr 待排序数组* @param left 左边界索引* @param right 右边界索引*/public static void mergeSort(int[] arr, int left, int right) {if (left < right) {// 找到中间索引int mid = left + (right - left) / 2;// 对左半部分进行归并排序mergeSort(arr, left, mid);// 对右半部分进行归并排序mergeSort(arr, mid + 1, right);// 合并左右两部分merge(arr, left, mid, right);}}/*** 合并两个有序数组** @param arr 待合并数组* @param left 左边界索引* @param mid 中间索引* @param right 右边界索引*/public static void merge(int[] arr, int left, int mid, int right) {int n1 = mid - left + 1;int n2 = right - mid;// 创建临时数组int[] leftArray = new int[n1];int[] rightArray = new int[n2];// 将数据复制到临时数组System.arraycopy(arr, left, leftArray, 0, n1);System.arraycopy(arr, mid + 1, rightArray, 0, n2);// 合并临时数组int i = 0, j = 0, k = left;while (i < n1 && j < n2) {if (leftArray[i] <= rightArray[j]) {arr[k++] = leftArray[i++];} else {arr[k++] = rightArray[j++];}}// 将左半部分剩余元素复制到原数组while (i < n1) {arr[k++] = leftArray[i++];}// 将右半部分剩余元素复制到原数组while (j < n2) {arr[k++] = rightArray[j++];}}
算法分析
- 稳定性: 归并排序是一种稳定的排序算法,相等元素的相对位置在排序前后不会改变。
- 时间复杂度: 最佳:O(n log n), 最差:O(n log n), 平均:O(n log n)
- 空间复杂度: O(n)
- 排序方式: 归并排序是一种非原地排序算法。
快速排序 (Quick Sort)
简介
快速排序是一种基于分治思想的排序算法,它选择一个元素作为基准值,将序列分为两个子序列,小于基准值的元素放在基准值的左边,大于基准值的元素放在右边。然后对左右子序列分别进行递归排序。快速排序是一种高效的排序算法,在大规模数据集上表现出色。
算法步骤
- 选择一个基准值。
- 将序列分为两个子序列,小于基准值的元素放在左边,大于基准值的元素放在右边。
- 对左右子序列分别进行递归排序。
- 完成排序。
图解算法

代码示例
/*** 快速排序* @param arr 待排序数组* @param low 左边界* @param high 右边界*/
public static void quickSort(int[] arr, int low, int high) {if (low < high) {// 划分数组,获取基准值的位置int pivotIndex = partition(arr, low, high);// 对左子数组进行递归排序quickSort(arr, low, pivotIndex - 1);// 对右子数组进行递归排序quickSort(arr, pivotIndex + 1, high);}
}/*** 划分数组,获取基准值的位置* @param arr 待排序数组* @param low 左边界* @param high 右边界* @return 基准值的位置*/
public static int partition(int[] arr, int low, int high) {// 选择最右边的元素作为基准值int pivot = arr[high];// i 表示小于基准值的元素的最右位置int i = low - 1;// 从左到右遍历数组for (int j = low; j < high; j++) {// 如果当前元素小于基准值,交换位置if (arr[j] < pivot) {i++;swap(arr, i, j);}}// 将基准值放在正确的位置swap(arr, i + 1, high);// 返回基准值的位置return i + 1;
}/*** 交换数组中两个元素的位置* @param arr 待排序数组* @param i 第一个元素的索引* @param j 第二个元素的索引*/
public static void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;
}
算法分析
- 稳定性: 快速排序是一种不稳定的排序算法,相等元素可能在排序过程中改变相对位置。
- 时间复杂度: 最佳:O(n log n), 最差:O(n^2), 平均:O(n log n)
- 空间复杂度: 最佳:O(log n), 最差:O(n)
- 排序方式: 快速排序是一种原地排序算法。
堆排序 (Heap Sort)
简介
堆排序是一种基于二叉堆数据结构的排序算法。它将待排序的序列构建成一个二叉堆,然后反复将堆顶元素与堆尾元素交换,将最大(或最小)元素放在已排序部分的末尾。通过反复调整堆,直到整个序列有序。堆排序具有高效的性能,并且是一种原地排序算法。
算法步骤
- 构建一个最大堆(对于升序排序)或最小堆(对于降序排序)。
- 将堆顶元素与堆尾元素交换,将最大(或最小)元素放在已排序部分的末尾。
- 调整堆,使得剩余元素仍然构成一个最大堆(或最小堆)。
- 重复步骤2-3,直到整个序列有序。
图解算法

代码示例
/*** 堆排序** @param arr 待排序数组*/public static void heapSort(int[] arr) {int n = arr.length;// 构建最大堆for (int i = n / 2 - 1; i >= 0; i--) {heapify(arr, n, i);}// 依次取出最大堆的根节点,放到数组末尾,重新调整堆结构for (int i = n - 1; i > 0; i--) {// 将堆顶元素与当前未排序部分的最后一个元素交换swap(arr, 0, i);// 调整堆,重新构建最大堆heapify(arr, i, 0);}}/*** 调整堆,使其成为最大堆** @param arr 待调整数组* @param n 堆的大小* @param i 当前节点索引*/public static void heapify(int[] arr, int n, int i) {int largest = i;int left = 2 * i + 1;int right = 2 * i + 2;// 找到左右子节点中值最大的节点索引if (left < n && arr[left] > arr[largest]) {largest = left;}if (right < n && arr[right] > arr[largest]) {largest = right;}// 如果最大值的索引不是当前节点索引,交换节点值,然后递归调整下层堆结构if (largest != i) {swap(arr, i, largest);heapify(arr, n, largest);}}/*** 交换数组中两个元素的位置** @param arr 待交换数组* @param i 第一个元素的索引* @param j 第二个元素的索引*/public static void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}
算法分析
- 稳定性: 堆排序是一种不稳定的排序算法,相等元素可能在排序过程中改变相对位置。
- 时间复杂度: 最佳:O(n log n), 最差:O(n log n), 平均:O(n log n)
- 空间复杂度: O(1)
- 排序方式: 堆排序是一种原地排序算法。
计数排序 (Counting Sort)
简介
计数排序是一种非比较性的排序算法,适用于具有一定范围的整数元素。它通过统计每个元素的出现次数,然后根据统计信息将元素排列成有序序列。计数排序的核心思想是将每个元素的出现次数记录在额外的数组中,然后根据统计信息构建有序序列。
算法步骤
- 统计每个元素的出现次数,得到计数数组。
- 根据计数数组,构建有序序列。
图解算法

代码示例
/*** 计数排序** @param arr 待排序数组*/public static void countingSort(int[] arr) {int n = arr.length;// 找到数组中的最大值,确定计数数组的大小int max = arr[0];for (int value : arr) {if (value > max) {max = value;}}// 创建计数数组,并初始化为0int[] count = new int[max + 1];for (int i = 0; i <= max; i++) {count[i] = 0;}// 统计每个元素的出现次数for (int value : arr) {count[value]++;}// 根据计数数组,重构原数组int index = 0;for (int i = 0; i <= max; i++) {while (count[i] > 0) {arr[index++] = i;count[i]--;}}}
算法分析
- 稳定性: 计数排序是一种稳定的排序算法,相等元素的相对位置在排序前后不会改变。
- 时间复杂度: 最佳:O(n + k), 最差:O(n + k), 平均:O(n + k)
- 空间复杂度: O(k),其中 k 为计数数组的大小。
- 排序方式: 计数排序是一种非原地排序算法。
桶排序 (Bucket Sort)
简介
桶排序是一种非比较性的排序算法,它将待排序元素分散到不同的桶中,然后分别对每个桶中的元素进行排序,最后将各个桶中的元素合并得到有序序列。桶排序适用于元素分布均匀的情况,可以有效提高排序的速度。
算法步骤
- 将待排序元素分散到不同的桶中。
- 对每个桶中的元素进行排序(可以使用其他排序算法或递归桶排序)。
- 将各个桶中的元素合并得到有序序列。
图解算法

代码示例
/*** 桶排序** @param arr 待排序数组*/public static void bucketSort(double[] arr) {int n = arr.length;// 创建桶ArrayList<Double>[] buckets = new ArrayList[n];for (int i = 0; i < n; i++) {buckets[i] = new ArrayList<>();}// 将元素分配到对应的桶中for (double value : arr) {int bucketIndex = (int) (value * n);buckets[bucketIndex].add(value);}// 对每个桶内的元素进行排序for (ArrayList<Double> bucket : buckets) {Collections.sort(bucket);}// 将桶中的元素合并到原数组int index = 0;for (ArrayList<Double> bucket : buckets) {for (double value : bucket) {arr[index++] = value;}}}
算法分析
- 稳定性: 桶排序是一种稳定的排序算法,相等元素的相对位置在排序前后不会改变。
- 时间复杂度: 最佳:O(n + k), 最差:O(n^2), 平均:O(n + n^2/k + k),其中 k 为桶的数量。
- 空间复杂度: O(n + k),其中 n 为待排序元素的数量,k 为桶的数量。
- 排序方式: 桶排序是一种非原地排序算法。
基数排序 (Radix Sort)
简介
基数排序是一种非比较性的排序算法,它根据元素的位数进行排序。基数排序的核心思想是将待排序元素按照低位到高位的顺序依次进行排序,每次排序使用稳定的排序算法。基数排序适用于元素的位数相同的情况,例如整数或字符串。
算法步骤
- 将待排序元素按照最低位开始,依次排序。
- 重复步骤1,直到排序到最高位。
- 合并得到有序序列。
图解算法

代码示例
import java.util.ArrayList;/*** 基数排序* @param arr 待排序数组* @return 排序后的数组*/
public static int[] radixSort(int[] arr) {// 找到数组中的最大值,确定位数int max = getMax(arr);// 进行位数的排序for (int exp = 1; max / exp > 0; exp *= 10) {countingSortByDigit(arr, exp);}return arr;
}/*** 获取数组中的最大值* @param arr 待排序数组* @return 数组中的最大值*/
private static int getMax(int[] arr) {int max = arr[0];for (int num : arr) {if (num > max) {max = num;}}return max;
}/*** 根据位数进行计数排序* @param arr 待排序数组* @param exp 当前位数,例如个位、十位、百位...*/
private static void countingSortByDigit(int[] arr, int exp) {int n = arr.length;int[] output = new int[n];int[] count = new int[10];// 统计每个数字的出现次数for (int i = 0; i < n; i++) {count[(arr[i] / exp) % 10]++;}// 计算累加次数for (int i = 1; i < 10; i++) {count[i] += count[i - 1];}// 构建输出数组for (int i = n - 1; i >= 0; i--) {output[count[(arr[i] / exp) % 10] - 1] = arr[i];count[(arr[i] / exp) % 10]--;}// 将输出数组拷贝回原数组System.arraycopy(output, 0, arr, 0, n);
}
算法分析
- 稳定性: 基数排序是一种稳定的排序算法,相等元素的相对位置在排序前后不会改变。
- 时间复杂度: 最佳:O(d * (n + k)), 最差:O(d * (n + k)), 平均:O(d * (n + k)),其中 d 为元素的位数,k 为基数。
- 空间复杂度: O(n + k),其中 n 为待排序元素的数量,k 为基数。
- 排序方式: 基数排序是一种非原地排序算法。
♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠
分享不易,原创不易!如果以上链接对您有用,可以请作者喝杯水!您的支持是我持续分享的动力,感谢!!!

无论是哪个阶段,坚持努力都是成功的关键。不要停下脚步,继续前行,即使前路崎岖,也请保持乐观和勇气。相信自己的能力,你所追求的目标定会在不久的将来实现。加油!