Cascade-MVSNet论文笔记
- 摘要
- 1 立体匹配(Stereo Matching)
- 2 多视图立体视觉(Multi-View Stereo)
- 3 立体视觉和立体视觉的高分辨率输出
- 4 代价体表达方式(Cost volume Formulation)
- 4.1 多视图立体视觉的3D代价体(3D Cost Volumes in Multi-View Stereo)
- 4.2 立体匹配的3D代价体(3D Cost Volumes in Stereo Matching)
- 5 级联代价体(Cascade Cost Volume)
- 5.1 假设范围(Hypothesis Range)
- 5.2 假设平面间隔(Hypothesis Plane Interval)
- 5.3 假设平面数(Number of Hypothesis Planes)
- 5.4 空间分辨率(Spatial Resolution)
- 5.5 翘曲操作或视图变换操作(Warping Operation)
- 6 特征金子塔(Feature Pyramid)
- 7 损失函数
- 8 实验分析
- 8.1 实验数据集
- 8.2 实验比较
X. Gu, Z. Fan, S. Zhu, Z. Dai, F. Tan and P. Tan, “Cascade Cost Volume for High-Resolution Multi-View Stereo and Stereo Matching,” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 2020, pp. 2492-2501, doi: 10.1109/CVPR42600.2020.00257.
摘要
在本文中,作者提出了一种基于三维代价体积的多视点立体匹配方法的三维立体匹配方法。
首先,所提出的代价体是建立在一个特征金字塔编码的几何形状并且背景在逐渐更精细的尺度上。
然后,通过对前一个阶段的预测来缩小每个阶段的深度(或视差)范围。
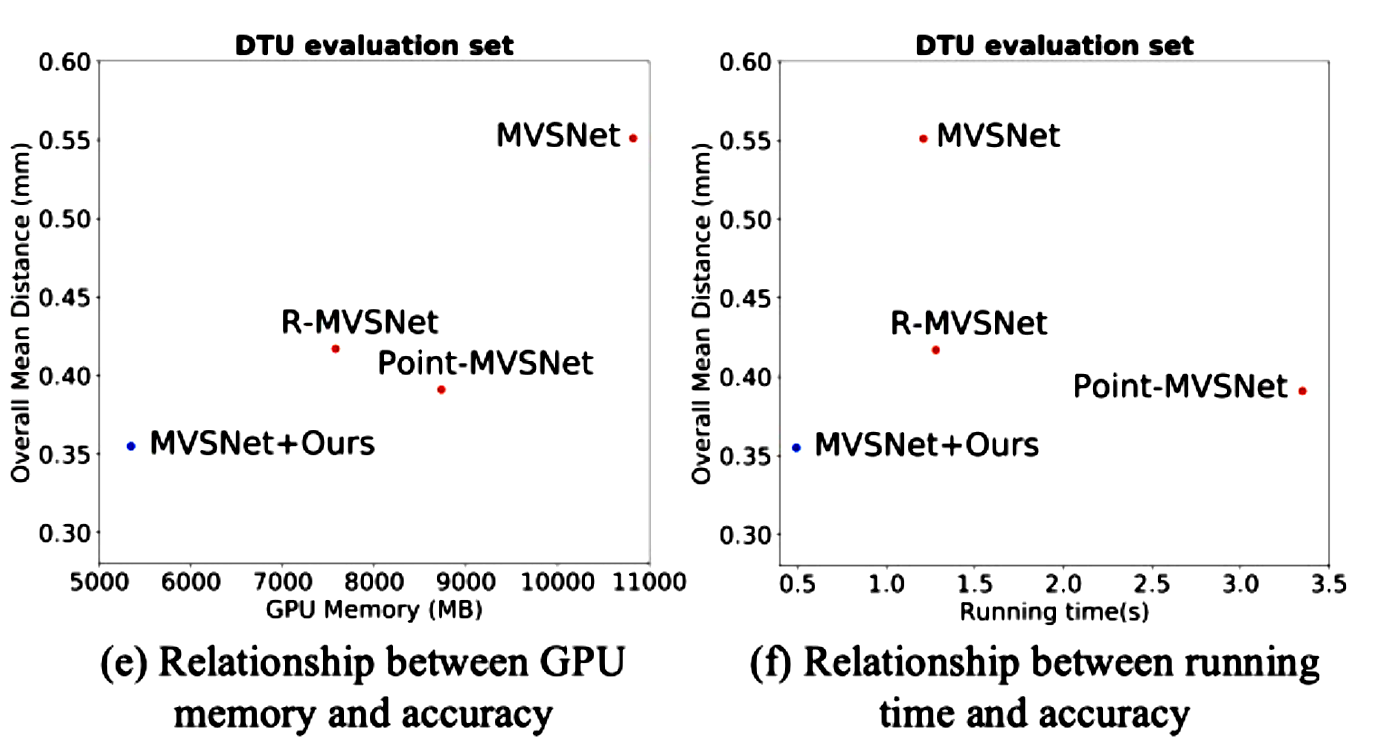
随着越来越高的代价体积分辨率和深度(或视差)间隔的自适应调整,获得由粗到精细的输出。将级联代价体应用到具有代表性的MVS-Net上,比DTU基准(第一名)提高了35.6%,GPU内存和运行时分别减少了50.6%和59.3%。
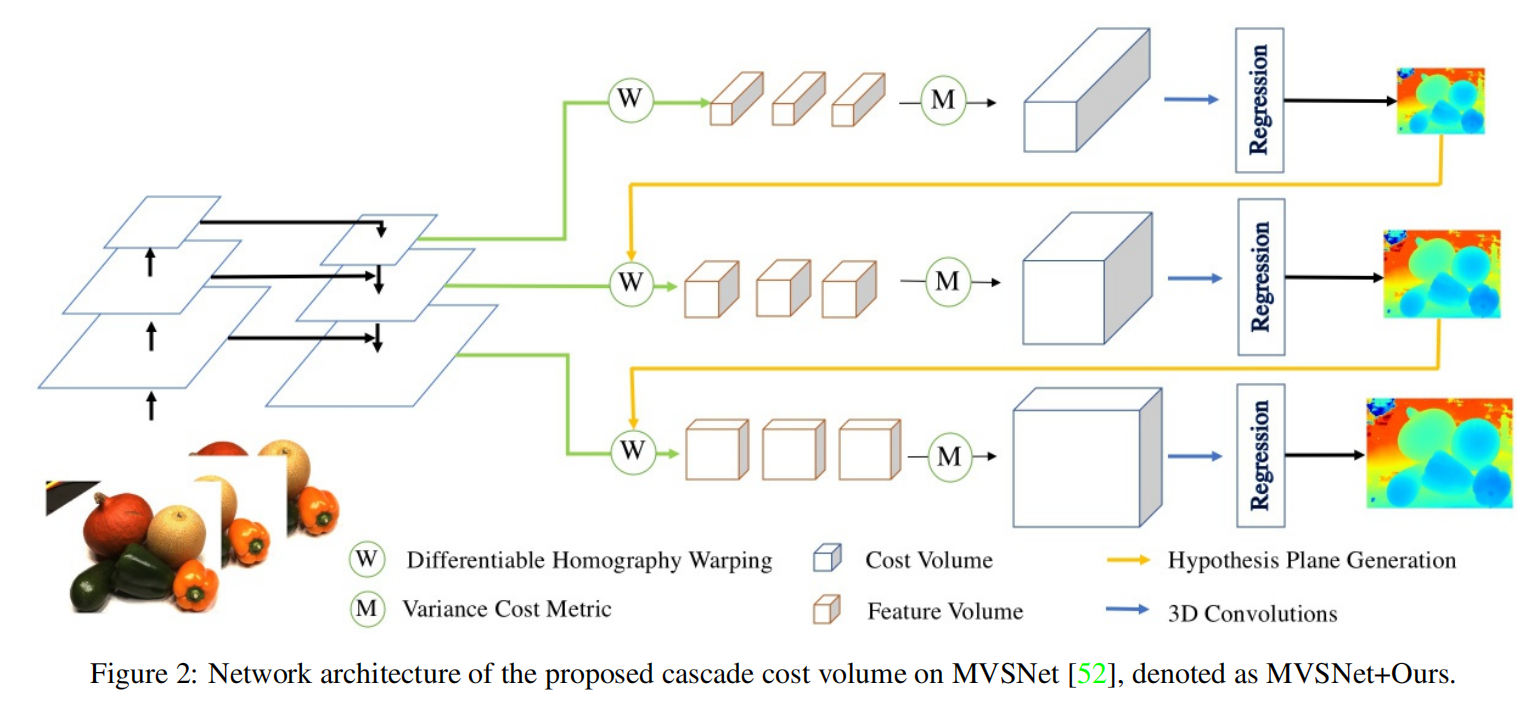
网络结构:
1 立体匹配(Stereo Matching)
一个典型的立体匹配算法包括四个步骤:匹配代价计算、匹配代价聚合、视差计算和视差细化。局部方法与相邻像素聚合匹配代价,通常利用赢家通吃策略来选择最优视差。全局方法构造一个能量函数,并试图将其最小化以找到最优视差。更进一步地方法利用信念传播和半全局匹配进行动态规划逼近全局优化。
在深度神经网络的背景下,Zbontar和LeCun首先引入了基于CNN的立体匹配方法,其中引入了卷积神经网络来学习小斑块对的相似性度量。在GCNet中首次在立体匹配中引入了广泛使用的3D代价体,其中视差回归步骤使用soft argmin操作来找出最佳匹配结果。PSMNet 进一步引入了金字塔空间池和三维沙漏网络进行代价体正则化,得到了更好的结果。GwcNet 修改了三维沙漏的结构,并引入了组间的相关性,形成了一个基于组间的3D代价体。DeepPruner是一种从粗到细的方法,它提出了一种基于可微分补丁匹配的模块来预测每个像素的剪枝搜索范围。
2 多视图立体视觉(Multi-View Stereo)
传统的多视图立体视觉大致可分为基于体素方法(估计每个体素与表面之间的关系);基于点云的方法(直接处理三维点来迭代强化结果);深度图重建方法(它只使用一个参考和少量源图像进行单深度图估计)。对于大规模的运动结构(SFM,Structure-from-Motion)中的工作使用基于分布式运动平均和全局相机共视的分布式方法。
现如今,基于学习的方法在多视图立体视觉也表现出了优越的性能。多补丁相似度引入了一个学习的代价度量。 SurfaceNet和DeepMVS将多视图图像预扭曲到三维空间,并使用深度网络进行正则化和聚合。近些年,提出了基于3D代价体的多视图立体视觉技术。基于多视图扭曲的二维图像特征构建三维代价体,并应用三维CNN进行代价正则化和深度回归。由于3D CNN需要较大的GPU内存,这些方法通常使用下采样的代价体。实现高分辨率的代价体,并进一步提高精度、计算速度和GPU内存效率,是目前研究的热点。
3 立体视觉和立体视觉的高分辨率输出
目前,有一些基于学习的方法试图减少内存需求,以产生高分辨率的输出。Point MVSNet不使用体素网格,而是使用小的代价体来生成粗深度,并使用基于点的迭代细化网络来输出全分辨率深度。相比之下,一个标准的MVSNet结合级联代价体可以比Point MVSNet 使用更少的运行时间和GPU内存,输出全分辨率深度和优越的精度。还有区分高级空间以减少内存消耗,并构建一个缺乏灵活性的固定代价体表示的方法。另外还有用2D CNN建立额外的细化模块,输出高精度的预测。
4 代价体表达方式(Cost volume Formulation)
基于学习的多视图立体视觉和立体匹配构造三维代价体来度量相应图像补丁之间的相似性,并确定它们是否匹配。在多视图立体视觉和立体匹配中构建三维代价体需要三个主要步骤。首先,确定离散假设的深度(或视差)平面。然后,将提取的每个视图的二维特征扭曲到假设平面上,构建特征体,最后将其融合在一起,构建三维代价。像素级的代价计算通常在固有的不适定区域中是模糊的,如遮挡区域、重复模式、无纹理区域和反射表面。为了解决这个问题,通常引入多尺度的3D CNN来聚合上下文信息,并正则可能的噪声污染代价体。
4.1 多视图立体视觉的3D代价体(3D Cost Volumes in Multi-View Stereo)
MVSNet 提出使用不同深度的前段到平行平面作为假设平面,深度范围一般由稀疏重建决定。坐标映射由单应性确定:
H i ( d ) = K i ⋅ R i ⋅ ( I − ( t 1 − t i ) ⋅ n 1 T d ) ⋅ R 1 T ⋅ K 1 − 1 ( 1 ) H_i(d)=K_i \cdot R_i \cdot\left(I-\frac{\left(t_1-t_i\right) \cdot n_1^T}{d}\right) \cdot R_1^T \cdot K_1^{-1} ~~~~ (1) Hi(d)=Ki⋅Ri⋅(I−d(t1−ti)⋅n1T)⋅R1T⋅K1−1 (1)
其中Hi(d)是指第i个视图的特征图与深度d的参考特征图之间的单应性,I表示参考图特征。Ki、Ri、ti分别为相机的内参、第i个视图的旋转矩阵和平移,n1为参考相机的主轴。然后利用可微单应性变换扭曲二维特征图到参考相机的假设平面,形成特征体积。为了将多个特征体汇总为一个代价体,提出基于方差的代价度量来适应任意数量输入的特征体。
4.2 立体匹配的3D代价体(3D Cost Volumes in Stereo Matching)
PSMNet使用视差分层作为假设平面,视差的范围是根据特定的场景来设计的。由于左右图像已被校正,因此坐标映射由x轴方向上的偏移量决定:
C r ( d ) = X l − d ( 2 ) C_r(d) = X_l − d ~~~~(2) Cr(d)=Xl−d (2)
其中, C r ( d ) C_r (d) Cr(d)为右视图在视差d处转换后的x轴坐标, X l X_l Xl为左视图的源x轴坐标。为了构建特征t体,使用沿x轴的平移,将右视图的特征图扭曲到左视图。有多种方法可以构建最终的代价体。GCNet 和PSMNet在不减少特征维度的情况下将左侧特征体和右特征体连接起来。还有人提出使用绝对差值的和来计算匹配代价。DispNetC计算关于左特征体和右特征体的完全相关性并为每个视差级别产生只一个单通道相关图。GwcNet 提出组间相关性,将特征分成组并计算每一组的相关图。
5 级联代价体(Cascade Cost Volume)
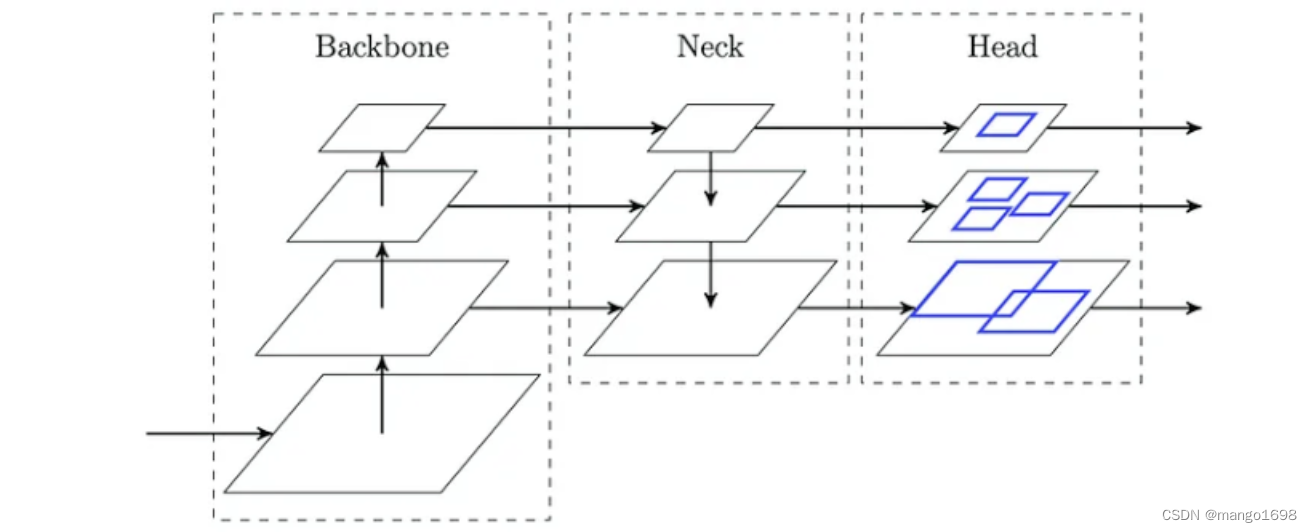
下图展示了W×H×D×F的分辨率的标准代价体,其中W×H表示空间分辨率,D是平面假设的数量,F是特征图的通道数。随着平面假设D的数量的增加,更大的空间分辨率W×H和更细的平面间隔可能提高重建精度。然而,GPU内存和运行时间随着代价体分辨率的增加而不断增长。正如R-MVSNet所示,MVSNet能够在16 GB Tesla P100 GPU上处理最大H×W×D×F=1600×1184×256×32的代价体。为了解决上述问题,Cascade MVSNet提出了一个级联代价体公式,并以粗到细的方式预测输出。

5.1 假设范围(Hypothesis Range)
如下图所示,用R1表示的第一阶段的深度(或视差)范围覆盖输入场景的整个深度(或视差)范围。在接下来的阶段中,可以基于前一个阶段的预测输出,并缩小假设范围。因此,有Rk+1 = Rk·wk,其中Rk是第k个阶段的假设范围,wk < 1是假设范围的缩小因子。

5.2 假设平面间隔(Hypothesis Plane Interval)
在第一阶段的深度(或视差)间隔为I1。与通常采用的单代价体公式相比,初始假设平面区间相对较大,可以产生一个粗糙的深度(或视差)估计。在接下来的阶段中,将应用更精细的假设平面区间来恢复更详细的输出。因此,有 Ik+1 = Ik·pk,其中Ik为第k阶段的假设平面区间,pk < 1是假设平面区间的缩小因子。
5.3 假设平面数(Number of Hypothesis Planes)
在第k阶段,给定假设范围Rk和假设平面区间Ik,相应的假设平面数Dk被确定为 Dk = Rk/Ik。当一个代价体的空间分辨率被固定,一个更大的Dk可以获得更多的假设平面和更准确的结果,同时导致增加的GPU内存和运行时间。基于级联公式,可以有效地减少假设平面的总数,因为假设范围是逐步显著减少的,同时仍然覆盖了整个输出范围。
5.4 空间分辨率(Spatial Resolution)
根据特征金字塔网络的实践,在每个阶段将代价体的空间分辨率增加一倍,并将输入特征图的空间分辨率增加一倍。将N定义为级联代价体的总阶段数,然后将第k阶段代价体的空间分辨率定义为 W / 2 N − k × H / 2 N − k W/2^{N−k}×H/2^{N−k} W/2N−k×H/2N−k。我们在多视图立体视觉任务中设置N = 3,在立体匹配任务中设置N = 2。
5.5 翘曲操作或视图变换操作(Warping Operation)
将级联代价体公式应用于多视图立体视觉,基于公式1,将(k+1)阶段的单应性变换改写为:
H i ( d k m + Δ k + 1 m ) = K i ⋅ R i ⋅ ( I − ( t 1 − t i ) ⋅ n 1 T d k m + Δ k + 1 m ) ⋅ R 1 T ⋅ K 1 − 1 ( 3 ) H_i\left(d_k^m+\Delta_{k+1}^m\right)=K_i \cdot R_i \cdot\left(I-\frac{\left(t_1-t_i\right) \cdot n_1^T}{d_k^m+\Delta_{k+1}^m}\right) \cdot R_1^T \cdot K_1^{-1}~~~~(3) Hi(dkm+Δk+1m)=Ki⋅Ri⋅(I−dkm+Δk+1m(t1−ti)⋅n1T)⋅R1T⋅K1−1 (3)
其中 d k m d_k^m dkm为第k阶段第m个像素的预测深度, ∆ k + 1 m ∆_{k+1}^m ∆k+1m为第k+阶段学习的第m个像素的深度差值。
类似地,在立体匹配中,根据级联代价体重新制定公式2。第k+1阶段的第m个像素坐标映射表示为:
C r ( d k m + Δ k + 1 m ) = X l − ( d k m + Δ k + 1 m ) ( 4 ) C_r\left(d_k^m+\Delta_{k+1}^m\right) = X_l − \left(d_k^m+\Delta_{k+1}^m\right) ~~~~(4) Cr(dkm+Δk+1m)=Xl−(dkm+Δk+1m) (4)
其中 d k m d_k^m dkm为第k阶段第m个像素的预测视差, ∆ k + 1 m ∆_{k+1}^m ∆k+1m为第k+1阶段学习的第m个像素的差值。
6 特征金子塔(Feature Pyramid)
为了获得高分辨率的深度(或视差)地图,通常使用标准代价体生成一个相对低分辨率的深度(或视差)图,然后用2D CNN进行上采样和细化。标准代价体是使用高阶段特征图构建的,该特征图包含高级的语义特征,但缺乏低级的更精细的表示。Cascade-MVSNet参考了特征金字塔网络,并采用其具有增加空间分辨率的特征图来构建更高分辨率的代价体。例如,当将级联代价体应用到MVSNet 时,从特征金字塔网络的特征映射{P1、P2、P3}中构建了三个代价体。如下图所示,它们对应的空间分辨率分别为输入图像大小的{1/16、1/4、1}。
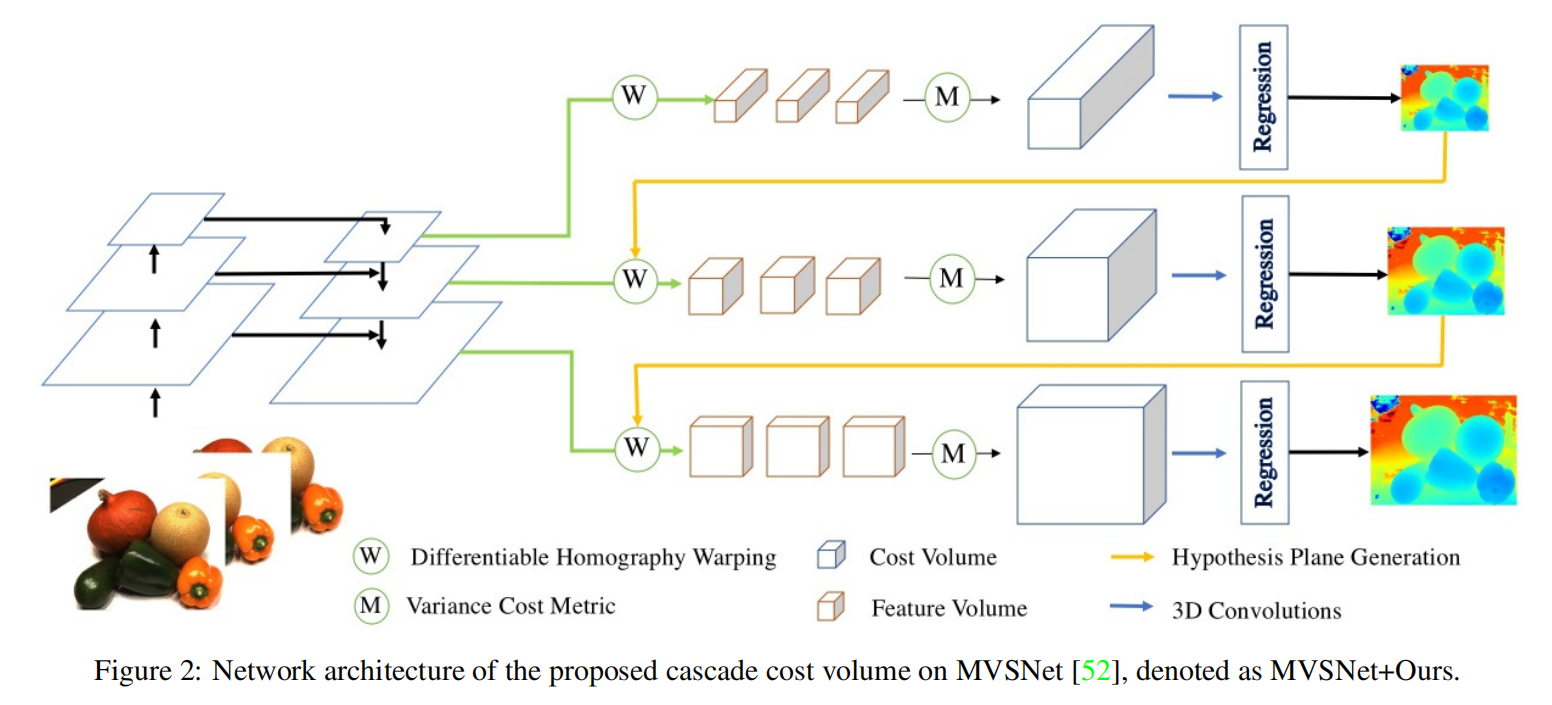
7 损失函数
N阶段的级联代价体产生N−1的中间输出和最终预测。对所有输出进行监督,总损失定义为:
Loss = ∑ k = 1 N λ k ⋅ L k ( 5 ) \text { Loss }=\sum_{k=1}^N \lambda^k \cdot L^k~~~~(5) Loss =k=1∑Nλk⋅Lk (5)
其中 L k L^k Lk为第k阶段的损失, λ k λ^k λk为对应的损失权重。在实验中采用与MVSNet相同的损失函数 L k L^k Lk。
8 实验分析
8.1 实验数据集
DTU是一个大规模的MVS数据集,由124个不同的场景组成,在7种不同的光照条件下,在49或64个位置进行扫描。坦克和寺庙数据集(Tanks and Temples dataset)包含具有小深度范围的真实场景。更具体地,它的中间场景由8个场景组成,包括家庭,弗朗西斯,马,灯塔,M60,黑豹,操场和火车。使用DTU训练集来训练Cascade-MVSNet,并在DTU评价集上进行测试。为了验证Cascade-MVSNet的泛化性,Cascade-MVSNet还在坦克和模板数据集的中间集上使用在DTU数据集上训练的不进行任何微调的模型进行测试。
8.2 实验比较
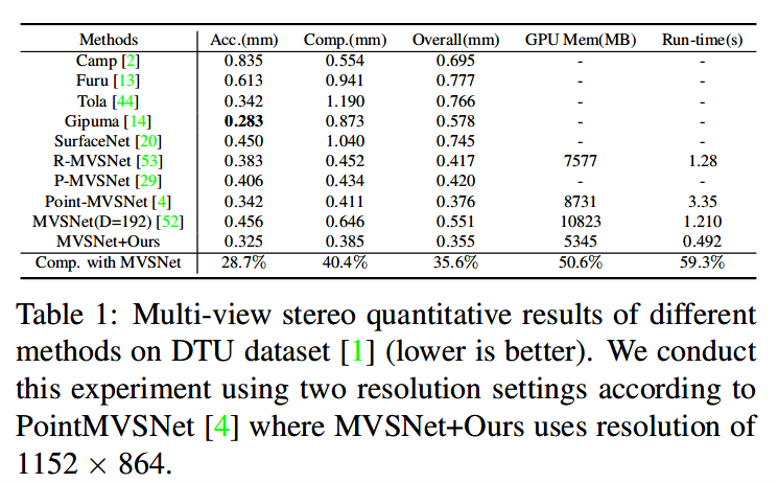
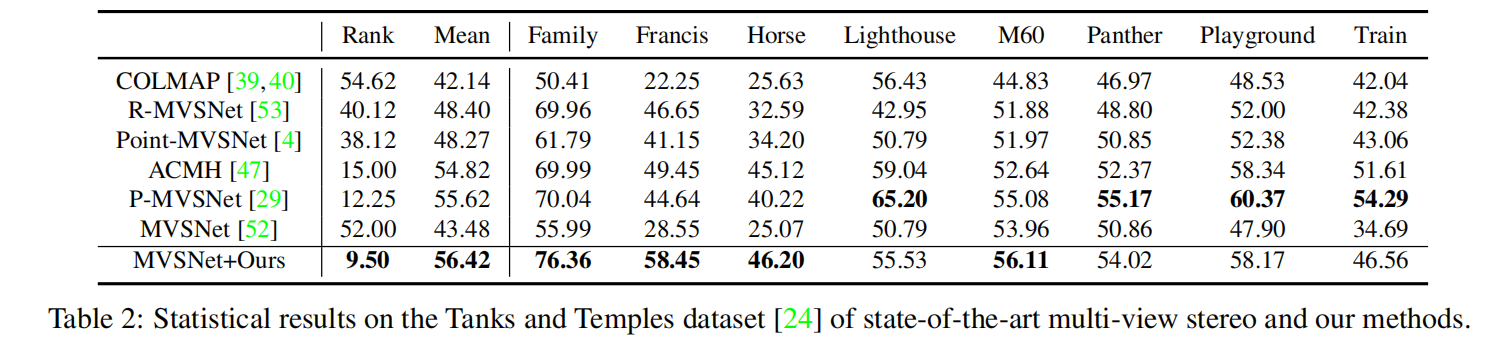
MVSNet+Ours(Cascade-MVSNet)在DTU和Tanks and Temples数据集上的表现都是最佳的。

MVSNet+Ours(Cascade-MVSNet)生成了更完整的点云与更精细的细节。除了R-MVSNet 提供了具有后处理方法的点云结果外,其它都是通过运行它们提供的预训练模型和代码来获得上述方法的结果。




![2023年中国宠物清洁用品分类、市场规模及发展特征分析[图]](https://img-blog.csdnimg.cn/img_convert/c98b948fcd445fa5c73bbadb65db6e88.png)