| 实验名称 | MapReduce编程 | ||
| 实验性质 (必修、选修) | 必修 | 实验类型(验证、设计、创新、综合) | 综合 |
| 实验课时 | 2 | 实验日期 | 2023.10.30-2023.11.03 |
| 实验仪器设备以及实验软硬件要求 | 专业实验室(配有centos7.5系统的linux虚拟机三台) | ||
| 实验目的 | 1. 理解MapReduce编程思想。 2. 理解MapReduce作业执行流程。 3. 理解MR-App编写步骤,掌握使用MapReduce Java API进行MapReduce基本编程,熟练掌握如何在Hadoop集群上运行MR-App并查看运行结果。 5. 掌握MapReduce Shell常用命令的使用。 | ||
| 实验内容(实验原理、运用的理论知识、算法、程序、步骤和方法) 实验原理概述 一、MapReduce编程思想 MapReduce是Hadoop生态中的一款分布式计算框架,它采用“分而治之”的核心思想,将大型任务拆分为若干子任务,由独立节点处理后再汇总结果。这使得开发人员能够专注于业务逻辑,而不必深入了解分布式计算细节。 早期的MapReduce(MapReduce 1.0)采用Master/Slave结构,但存在单点故障等问题。后来,MapReduce进行了升级,采用ResourceManager、ApplicationMaster和NodeManager等进程构建MapReduce 2.0体系架构。 二、MapReduce作业执行流程 MapReduce作业执行流程包括InputFormat、Map、Shuffle、Reduce、OutputFormat五个阶段。在InputFormat阶段,数据预处理并切分为逻辑上的InputSplit;Map阶段按用户定义的映射规则输出<key, value>中间结果;Shuffle阶段对Map输出进行排序、分区、合并等操作;Reduce阶段接收<key, List(value)>中间结果,执行用户定义逻辑,输出<key, value>结果;OutputFormat阶段将Reduce结果输出到分布式文件系统。 三、MapReduce Web UI MapReduce Web UI提供管理员接口,用于查看已完成的MR-App执行过程的统计信息。地址为http://JobHistoryServerIP:19888,可查看MapReduce的历史运行情况。 四、MapReduce Shell MapReduce Shell提供用户和管理员命令,例如archive、classpath、distcp、job、pipes等。管理员命令包括historyserver和hsadmin。Shell命令的详细说明可参考[官方文档] 五、MapReduce Java API MapReduce Java API面向Java开发工程师,用于编写MR-App。编写步骤包括确定<key, value>对、定制输入格式、编写Mapper和Reducer类、定制输出格式。主要类有Job、Mapper、Reducer、InputFormat、OutputFormat等。详细说明可在[官方文档](https://hadoop.apache.org/docs/r2.9.2/api/index.html)查看。 实验步骤:
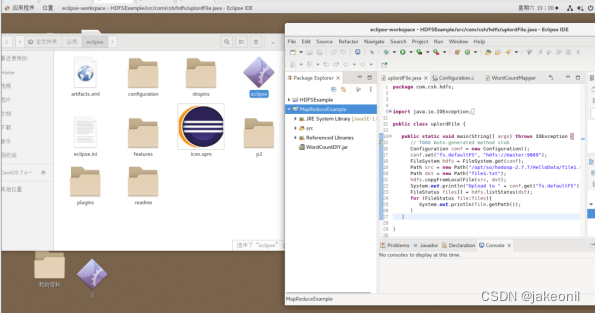
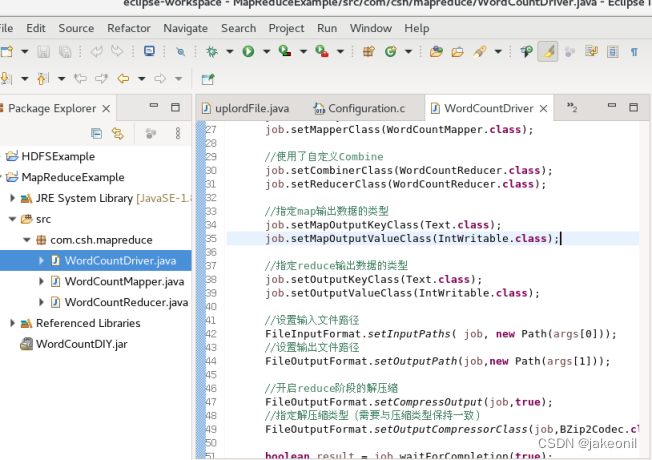
主节点: 从节点: 在Hadoop集群主节点上搭建MapReduce开发环境Eclipse。 2.查看Hadoop自带的MR-App单词计数源代码WordCount.java,在Eclipse项目MapReduceExample下建立新包com.csh.mapreduce,模仿内置的WordCount示例,自己编写一个WordCount程序,最后打包成JAR形式并在Hadoop集群上运行该MR-App,查看运行结果。
与运行hadoop-mapreduce-examples-2.9.2.jar中的wordcount程序一样,只需要执行以下命令,就能在Hadoop集群中成功运行自己编写的MapReduce程序了,命令如下所示。 hadoop jar /root/eclipse-workspace/MapReduceExampleWordCountDIY.jar com.csh.mapreduce.WordCountDriver /InputDataTest /OutputDataTest5 上述命令中,/InputDataTest表示输入目录,/OutputDataTest5表示输出目录。执行该命令前,假设HDFS的目录/InputDataTest下已存在待分析词频的3个文件,而输出目录 上述程序执行完毕后,会将结果输出到/OutputDataTest5目录中,可以使用命令“hdfs dfs -ls /OutputDataTest5”来查看。/OutputDataTest5目录下有2个文件,其中/OutputDataTest5/_SUCCESS表示Hadoop程序已执行成功,这个文件大小为0,文件名就告知了Hadoop程序的执行状态;第二个文件/OutputDataTest5/part-r-00000.bz2才是Hadoop程序的运行结果。由于输出结果进行了压缩,所以无法使用命令“hdfs dfs -cat /OutputDataTest4/part-r-00000.bz2”直接查看Hadoop程序的运行结果
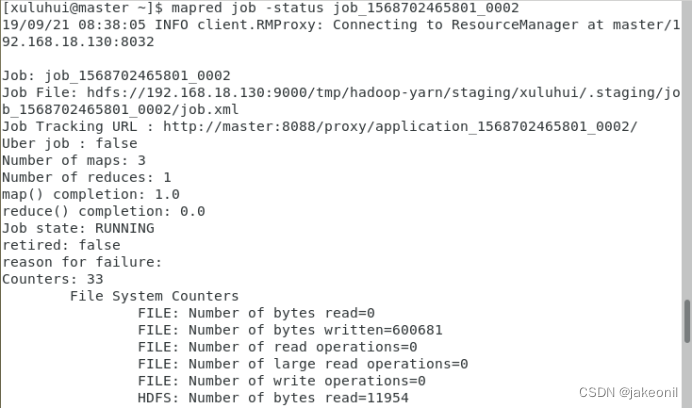
4 分别在自编MapReduce程序WordCount运行过程中和运行结束后查看MapReduce Web界面。 5.分别在自编MapReduce程序WordCount运行过程中和运行结束后练习MapReduce Shell常用命令。 分别在自编MapReduce程序WordCount运行过程中和运行结束后练习MapReduce Shell常用命令。 例如,使用如下命令查看MapReduce作业的状态信息。 mapred job -status <job-id> 如图所示,当前MapReduce作业“job_1568702465801_0002”正处于运行(RUNNING)状态。 6. 关闭Hadoop集群。 | |||
| 实验结果与分析 通过实施“MapReduce编程”实验,我们得到了以下结论: 1. 理解MapReduce编程思想:通过实验,深入理解了MapReduce编程思想,即“分而治之”的核心思想。能够将大型任务划分为独立的子任务,分布式地处理数据,最后将结果汇总。 2. 掌握MapReduce作业执行流程:熟悉了MapReduce作业的执行流程,包括InputFormat、Map、Shuffle、Reduce、OutputFormat五个阶段。能够更好地理解MapReduce作业的内部运行机制。 3. 熟练使用MapReduce Java API进行编程:通过实践掌握了MR-App编写步骤,使用MapReduce Java API进行基本编程。能够确定<key, value>对,定制输入格式,编写Mapper和Reducer类,定制输出格式,最终在Hadoop集群上运行MR-App并查看运行结果。 4. 熟练使用MapReduce Web界面:实验熟悉了MapReduce Web UI的使用,能够在页面上查看已完成的MR-App执行过程中的统计信息。可以更好地监控和理解MapReduce作业的执行情况。 5. 熟练使用MapReduce Shell常用命令:练习了MapReduce Shell常用命令,包括查看作业状态等。提供了在命令行中与MapReduce交互的能力。 6. 成功运行自编MapReduce程序WordCount: 通过在Hadoop集群上运行自己编写的MapReduce程序WordCount,验证了他们对MapReduce编程的理解和应用。通过Hadoop命令成功运行了程序,观察了结果并对运行过程中的各个阶段进行了分析。 7. 分析MapReduce Web界面和MapReduce Shell输出:在实验中通过查看MapReduce Web界面和使用Shell命令,深入了解了MapReduce作业的运行状态和输出结果。更好地理解和调试MapReduce程序提供了实际经验。 | |||
大数据平台/大数据技术与原理-实验报告--MapReduce编程






本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/204067.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
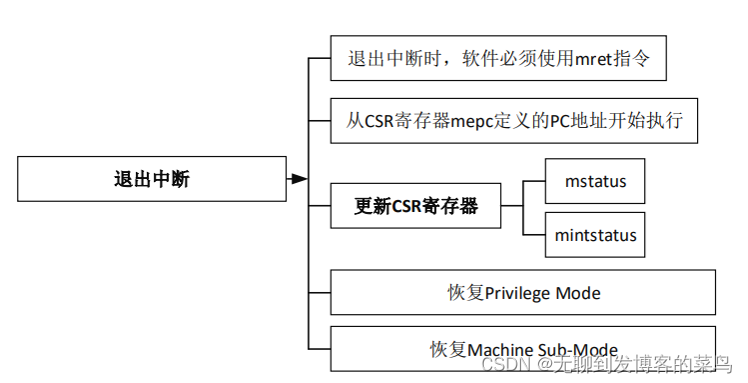
Cortex-M与RISC-V区别
环境
Cortex-M以STM32H750为代表,RISC-V以芯来为代表
RTOS版本为RT-Thread 4.1.1 寄存器 RISC-V 常用汇编
RISC-V
关于STORE x4, 4(sp)这种寄存器前面带数字的写法,其意思为将x4的值存入sp4这个地址,即前面的数字表示偏移的意思
反之LOA…

论文阅读:“Model-based teeth reconstruction”
文章目录 AbstractIntroductionTeeth Prior ModelData PreparationParametric Teeth Model Teeth FittingTeeth Boundary Extraction Reference Abstract
近年来,基于图像的人脸重建方法日趋成熟。这些方法可以捕捉整个面部或面部特定区域(如头发、眼睛…
探索H5的神秘世界:测试点解析
Html5 app实际上是Web app的一种,在测试过程中可以延续Web App测试的部分方法,同时兼顾手机端的一些特性即可,下面帮大家总结下Html5 app 相关测试方法! app内部H5测试点总结 1、业务逻辑
除基本功能测试外,需要关注的…

【微服务专题】微服务架构演进
目录 前言阅读对象阅读导航前置知识笔记正文一、系统架构的演变1.1 单体架构1.2 单体水平架构1.3 垂直架构1.4 SOA架构1.5 微服务架构 二、如何实现微服务架构2.1 微服务架构下的技术挑战2.2 微服务技术栈选型2.3 什么是Spring Cloud全家桶2.4 Spring Cloud Alibaba版本选择 学…

智慧化工~工厂设备检修和保全信息化智能化机制流程
化工厂每年需要现场检修很多机器,比如泵、压缩机、管道、塔等等,现场检查人员都是使用照相机,现场拍完很多机器后,回办公室整理乱糟糟的照片,但是经常照了之后无法分辨是哪台设备,而且现场经常漏拍…
HarmonyOS4.0系列——02、汉化插件、声明式开发范式ArkTS和类web开发范式
编辑器调整
我们在每次退出编辑器后再次打开会直接进入项目文件中,这样在新建项目用起来很是不方便,所以这里跟着设置一下就好
这样下次进入就不会直接跳转到当时的文件项目中!! 关于汉化
settings → plugins → installe…

耗时一个星期整理的APP自动化测试工具大全
在本篇文章中,将给大家推荐14款日常工作中经常用到的测试开发工具神器,涵盖了自动化测试、APP性能测试、稳定性测试、抓包工具等。
一、UI自动化测试工具
1. uiautomator2
openatx开源的ui自动化工具,支持Android和iOS。主要面向的编程语言…
西南科技大学数字电子技术实验二(SSI逻辑器件设计组合逻辑电路及FPGA实现 )预习报告
一、计算/设计过程
说明:本实验是验证性实验,计算预测验证结果。是设计性实验一定要从系统指标计算出元件参数过程,越详细越好。用公式输入法完成相关公式内容,不得贴手写图片。(注意:从抽象公式直接得出结果,不得分,页数可根据内容调整)
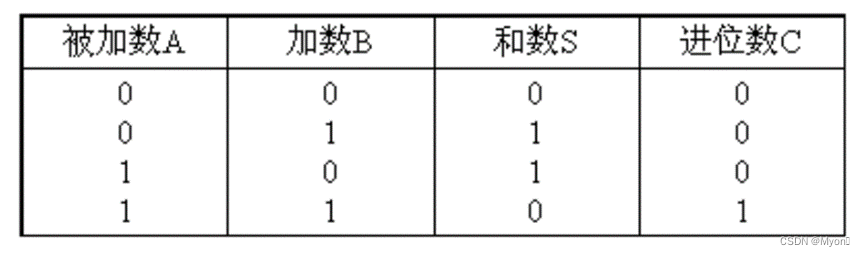
1、1位半加器
真值表: 逻…
flask 上传文件
from flask import Flask, request, render_template,redirect, url_for
from werkzeug.utils import secure_filename
import os
from flask import send_from_directory # send_from_directory可以从目录加载文件app Flask(__name__)#UPLOAD_FOLDER media # 注意ÿ…
Me-and-My-Girlfriend-1
Me-and-My-Girlfriend-1
一、主机发现和端口扫描 主机发现,靶机地址192.168.80.147 arp-scan -l端口扫描,开放了22、80端口 nmap -A -p- -sV 192.168.80.147二、信息收集 访问80端口 路径扫描 dirsearch -u "http://192.168.80.147/" -e * …
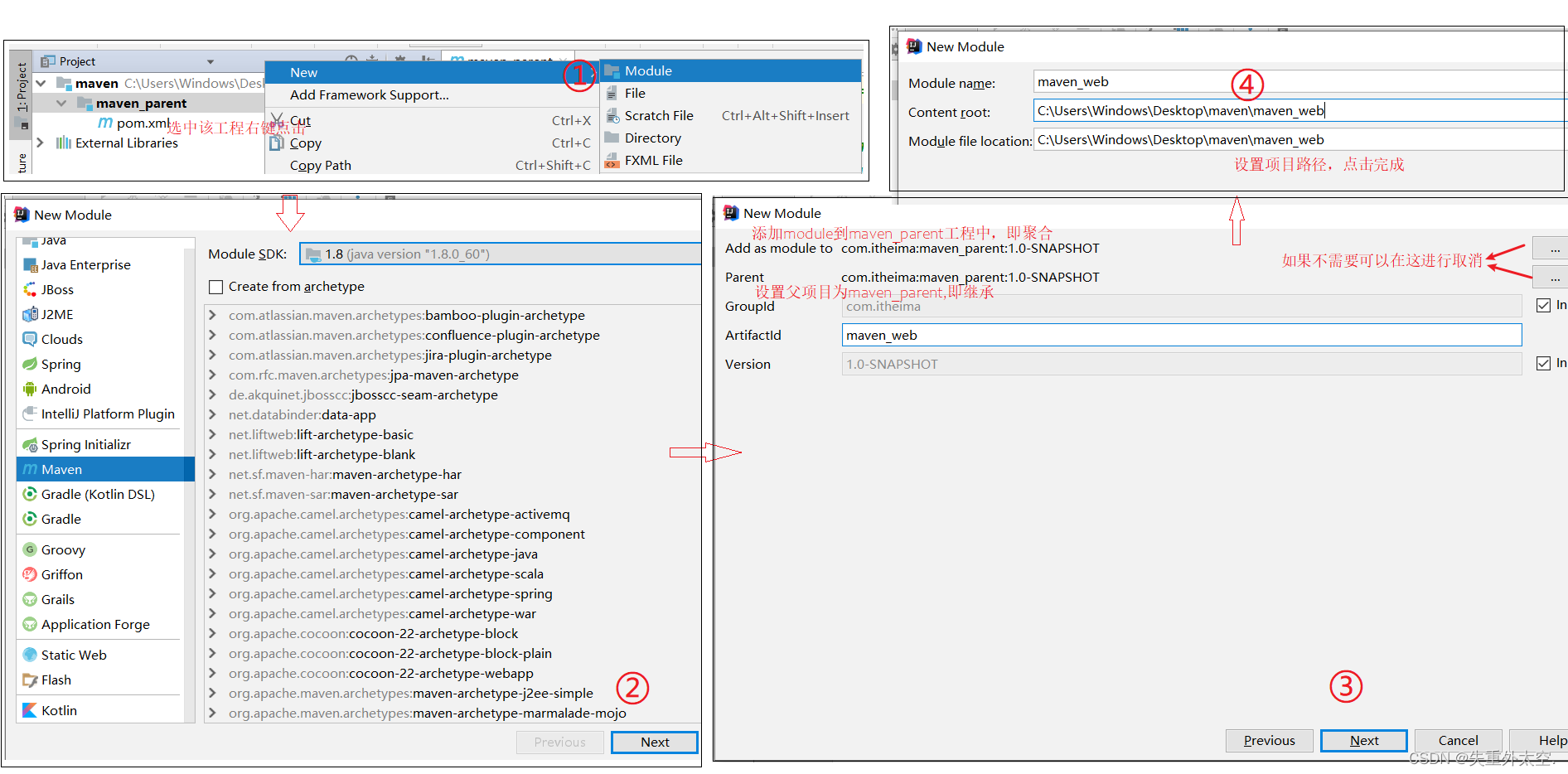
深入探索Maven:优雅构建Java项目的新方式(一)
Maven高级 1,分模块开发1.1 分模块开发设计1.2 分模块开发实现 2,依赖管理2.1 依赖传递与冲突问题2.2 可选依赖和排除依赖方案一:可选依赖方案二:排除依赖 3,聚合和继承3.1 聚合步骤1:创建一个空的maven项目步骤2:将项目的打包方式改为pom步骤…

在Linux中对Docker中的服务设置自启动
先在Linux中安装docker,然后对docker中的服务设置自启动。
安装docker
第一步,卸载旧版本docker。
若系统中已安装旧版本docker,则需要卸载旧版本docker以及与旧版本docker相关的依赖项。
命令:yum -y remove docker docker-c…
2304. 网格中的最小路径代价 : 从「图论最短路」过渡到「O(1) 空间的原地模拟」
题目描述 这是 LeetCode 上的 「2304. 网格中的最小路径代价」 ,难度为 「中等」。 Tag : 「最短路」、「图」、「模拟」、「序列 DP」、「动态规划」 给你一个下标从 0 开始的整数矩阵 grid,矩阵大小为 m x n,由从 0 到 的不同整数组成。 你…

设计模式之十二:复合模式
模式通常被一起使用,并被组合在同一个解决方案中。
复合模式在一个解决方案中结合两个或多个模式,以解决一般或重复发生的问题。
首先重新构建鸭子模拟器:
package headfirst.designpatterns.combining.ducks;public interface Quackable …

Scala如何写一个通用的游戏数据爬虫程序
以前想要获取一些网站数据的时候,都是通过人工手动复制粘贴,这样的效率及其低下。数据少无所谓,如果需要采集大量数据,手动就显得乏力了。半夜睡不着,爬起来写一段有关游戏商品数据的爬虫通用模板,希望能帮…
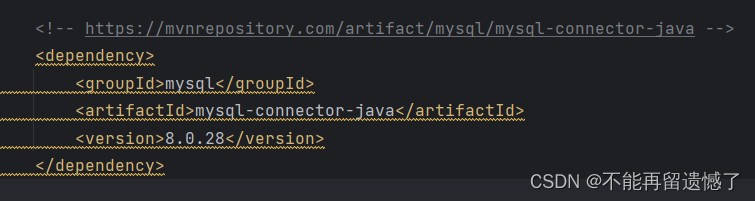
Servlet实现一个简单的表白墙网站
文章目录 前言效果展示事前准备HTML、CSS、JavaScript分别负责哪些HTML和CSS构架出页面的基本结构和样式JavaScript 实现行为和交互实现服务器端的业务代码整理pom.xmlweb.xmlmessageWall.htmlMessageServlet.java 前言
前面我们学习了 Java 中知名的 HTTP 服务器 tomcat 的安…

linux下的工具---yum
一、什么是yum
yum是Linux下的软件包管理器
二、什么是软件包管理器 1、在Linux下安装软件, 一个通常的办法是下载到程序的源代码, 并进行编译, 得到可执行程序. 2、但是这样太麻烦了, 于是有些人把一些常用的软件提前编译好, 做成软件包(可以理解成windows上的安装程序)放在…
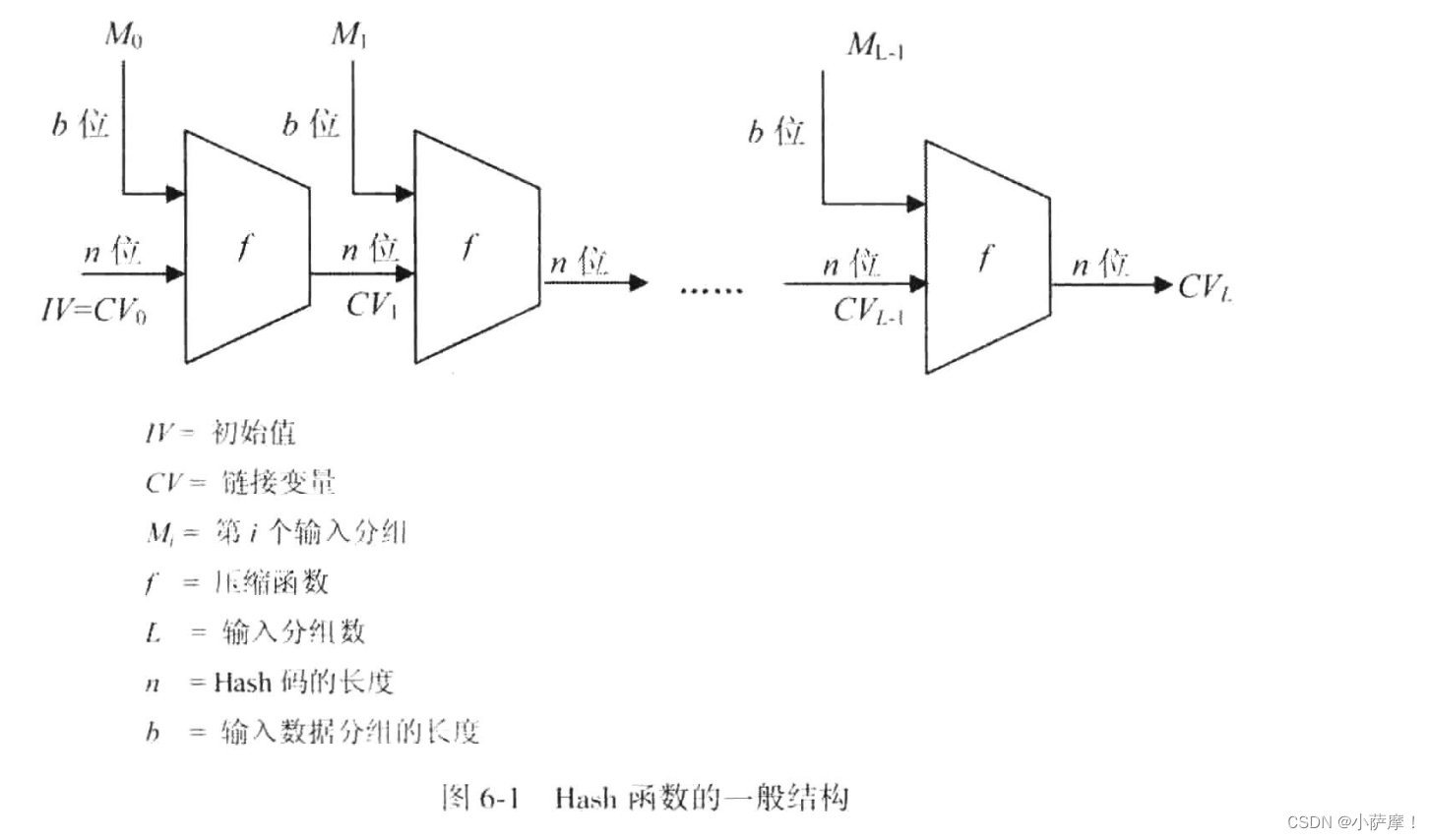
【密码学引论】Hash密码
第六章 Hash密码
md4、md5、sha系列、SM3
定义:将任意长度的消息映射成固定长度消息的函数功能:确保数据的真实性和完整性,主要用于认证和数字签名Hash函数的安全性:单向性、抗若碰撞性、抗强碰撞性生日攻击:对于生日…

保护您的IP地址:预防IP地址盗用的关键措施
随着互联网的发展,IP地址作为标识互联网设备的重要元素,成为网络通信的基石。然而,IP地址盗用威胁正不断增加,可能导致敏感信息泄露、未经授权的访问和网络攻击。本文将介绍一些有效的方法,以帮助组织和个人预防IP地址…

初学vue3与ts:路由跳转带参数
index-router
<!-- 路由跳转 -->
<template><div><div class"title-sub flex"><div>1、用router-link跳转带参数id1:</div><router-link to"./link?id1"><button>点我跳转</button>&…
最新文章
- 内蒙建设厅网站怎么查建筑电工证/网络热词2022
- 文本怎样做阅读链接网站/seo资讯
- 整容医院网站建设目的/软文推广怎么做
- php做网站架构图/人教版优化设计电子书
- 网站设计策划书 模板/网站seo快速排名
- 西部数码网站管理助手破解版/网站宣传费用
- 石岩基督教福音堂
- Mysql高级部分总结(二)
- 论文《Vertical Federated Learning: Concepts, Advances, and Challenges》阅读
- 如何用gpt来分析链接里面的内容(比如分析论文链接)和分析包含多个文件中的一块代码
- 本地部署webrtc应用怎么把http协议改成https协议?
- 面向未来的教育技术:智能成绩管理系统的开发
推荐文章
- LeetCode解法汇总1572. 矩阵对角线元素的和
- 三子棋(c语言)
- (14)Hive调优——合并小文件
- (AtCoder Beginner Contest 321)(退背包,二叉树)
- (C++进阶)boost库笔记
- (java+Seleniums3)自动化测试实战2
- (笔记)M1使用hombrew安装qemu
- (长期更新)《零基础入门 ArcGIS(ArcMap) 》实验一(下)----空间数据的编辑与处理(超超超详细!!!)
- (迭代法)145. 二叉树的后序遍历
- (二)逻辑回归与交叉熵--九五小庞
- (二)延时任务篇——通过redis的key监听,实现延迟任务实战
- (分步解释)----扑克随机洗牌